目录
[1 Hive与Spark SQL概述](#1 Hive与Spark SQL概述)
[1.1 Hive简介](#1.1 Hive简介)
[1.2 Spark SQL简介](#1.2 Spark SQL简介)
[2 Hive与Spark SQL集成架构](#2 Hive与Spark SQL集成架构)
[2.1 集成原理](#2.1 集成原理)
[2.2 配置集成环境](#2.2 配置集成环境)
[3 混合计算使用场景](#3 混合计算使用场景)
[3.1 场景一:Hive表与Spark DataFrame互操作](#3.1 场景一:Hive表与Spark DataFrame互操作)
[3.2 场景二:Hive UDF与Spark SQL结合使用](#3.2 场景二:Hive UDF与Spark SQL结合使用)
[3.3 场景三:Hive批处理与Spark流处理结合](#3.3 场景三:Hive批处理与Spark流处理结合)
[4 性能优化策略](#4 性能优化策略)
[4.1 数据格式选择](#4.1 数据格式选择)
[4.2 分区与分桶策略优化](#4.2 分区与分桶策略优化)
[4.3 执行引擎调优](#4.3 执行引擎调优)
[5 常见问题与解决方案](#5 常见问题与解决方案)
[5.1 元数据同步问题](#5.1 元数据同步问题)
[5.2 数据类型兼容性问题](#5.2 数据类型兼容性问题)
[5.3 权限与安全配置](#5.3 权限与安全配置)
[6 实践总结](#6 实践总结)
引言
在大数据生态系统中,Hive和Spark SQL都是非常重要的数据处理工具。Hive作为基于Hadoop的数据仓库工具,提供了类SQL的查询能力;而Spark SQL则是Spark生态系统中的结构化数据处理模块,以其高性能的内存计算能力著称。将两者集成使用,可以充分发挥各自的优势,实现更高效的数据处理和分析。
1 Hive与Spark SQL概述
1.1 Hive简介
Hive是一个构建在Hadoop之上的数据仓库框架,它提供了:
- 类SQL查询语言(HiveQL)
- 数据ETL(提取、转换、加载)功能
- 大规模数据集的管理和查询能力
Hive的核心架构包括:- 元数据存储(Metastore):存储表结构、分区信息等
- 查询处理器:将HiveQL转换为MapReduce/Tez/Spark作业
- 执行引擎:执行生成的作业

1.2 Spark SQL简介
Spark SQL是Apache Spark中用于结构化数据处理的模块,主要特点包括:
- 兼容SQL标准
- 支持DataFrame和DataSet API
- 与Spark生态系统无缝集成
- 内存计算带来的高性能
Spark SQL的核心组件:- Catalyst优化器:逻辑和物理查询优化
- Tungsten引擎:内存管理和二进制处理
- 数据源API:统一的数据访问接口

2 Hive与Spark SQL集成架构
2.1 集成原理
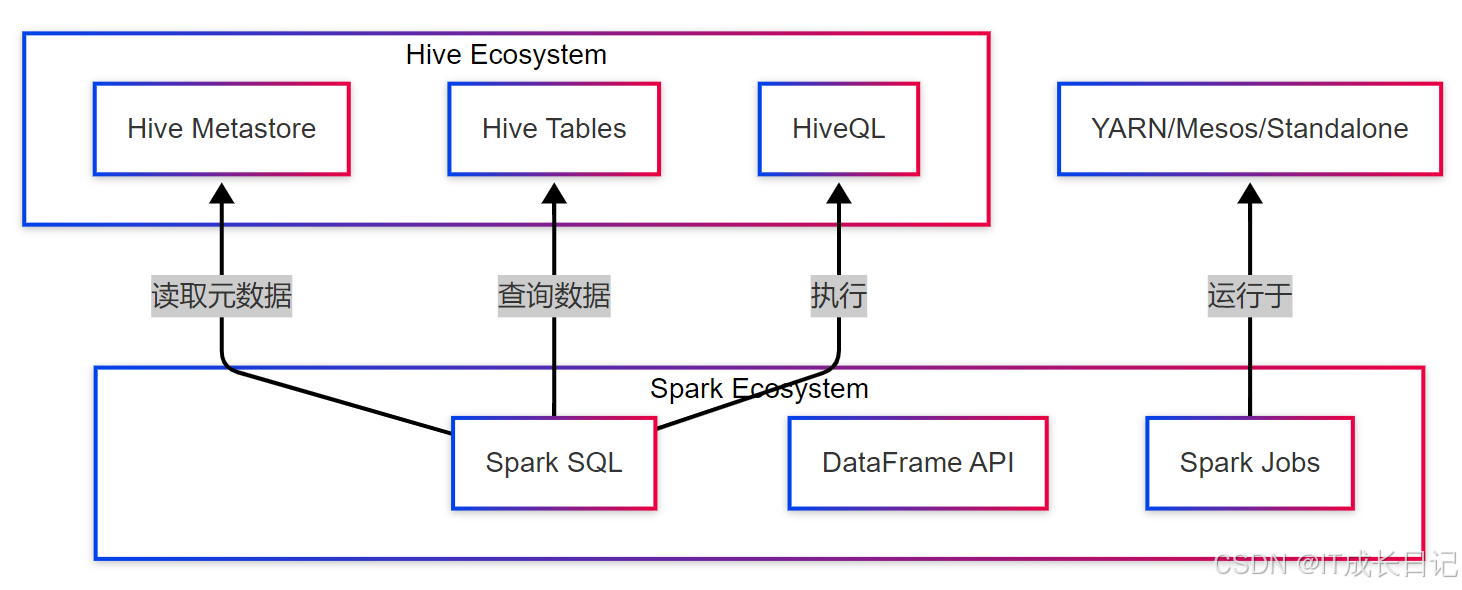
Hive与Spark SQL的集成主要通过以下几个关键点实现:
- 共享Hive Metastore:Spark SQL可以直接访问Hive的元数据
- 兼容HiveQL语法:Spark SQL可以解析和执行大多数Hive查询
- 统一的数据存储:两者都支持HDFS、S3等存储系统
2.2 配置集成环境
要使Spark SQL与Hive集成,需要进行以下配置:
-
配置Hive Metastore访问:在Spark的conf/spark-defaults.conf中添加:
spark.sql.catalogImplementation=hive
spark.hadoop.hive.metastore.uris=thrift://metastore-host:9083 -
添加依赖库:确保Spark classpath中包含Hive的相关JAR包
-
权限配置:设置适当的HDFS和Hive Metastore访问权限
3 混合计算使用场景
3.1 场景一:Hive表与Spark DataFrame互操作
- 使用Hive创建和管理表结构
- 通过Spark SQL读取Hive表数据
- 使用Spark DataFrame API进行复杂转换和分析
-
将结果写回Hive表

-
示例:
// 创建SparkSession并启用Hive支持
val spark = SparkSession.builder()
.appName("HiveSparkIntegration")
.config("spark.sql.warehouse.dir", "/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()// 读取Hive表
val hiveDF = spark.sql("SELECT * FROM hive_db.sales_table")// 使用Spark DataFrame API处理
val processedDF = hiveDF.filter($"amount" > 1000)
.groupBy("region")
.agg(sum("amount").alias("total_sales"))// 写回Hive
processedDF.write.mode("overwrite").saveAsTable("hive_db.sales_summary")
3.2 场景二:Hive UDF与Spark SQL结合使用
- 在Hive中创建自定义函数(UDF)
- 在Spark SQL中注册Hive UDF
-
在Spark SQL查询中使用这些UDF

-
示例:
// 注册Hive UDF到Spark
spark.sql("CREATE TEMPORARY FUNCTION my_hive_udf AS 'com.example.hive.udf.MyHiveUDF'")// 在Spark SQL中使用
val result = spark.sql("""
SELECT
product_id,
my_hive_udf(product_name) AS processed_name
FROM hive_db.products
""")
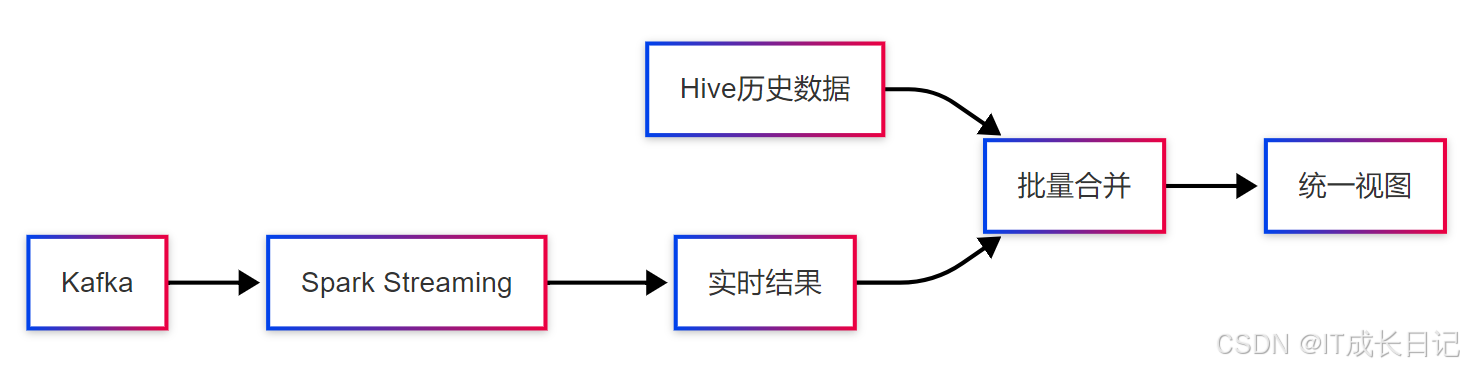
3.3 场景三:Hive批处理与Spark流处理结合
- 使用Hive管理历史数据
- 使用Spark Streaming处理实时数据
-
定期将流处理结果与Hive历史数据合并
-
示例:
// 流处理部分
val streamingDF = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "kafka-server:9092")
.option("subscribe", "sales-topic")
.load()// 批处理部分
val historicalDF = spark.sql("SELECT * FROM hive_db.sales_history")// 流批合并
val mergedDF = streamingDF.union(historicalDF)// 写入Hive
mergedDF.writeStream
.outputMode("append")
.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.mode("append").saveAsTable("hive_db.combined_sales")
}
.start()
4 性能优化策略
4.1 数据格式选择
|--------------|------|------|-----|------------|
| 格式 | 读取性能 | 写入性能 | 压缩率 | 适用场景 |
| TextFile | 低 | 高 | 低 | 兼容性要求高 |
| SequenceFile | 中 | 中 | 中 | 中间结果存储 |
| ORC | 高 | 中 | 高 | Hive为主的查询 |
| Parquet | 高 | 高 | 高 | Spark为主的查询 |
建议:在Hive和Spark混合环境中,Parquet格式通常是首选。
4.2 分区与分桶策略优化
-
分区剪枝示例:
-- Hive和Spark SQL都支持的分区剪枝
SELECT * FROM sales WHERE dt = '2023-01-01' AND region = 'east' -
分桶优化:
-- 创建分桶表
CREATE TABLE bucketed_sales (
id INT,
product STRING,
amount DOUBLE
) CLUSTERED BY (id) INTO 32 BUCKETS
STORED AS PARQUET;-- 分桶表连接可以提高性能
SELECT a., b.
FROM bucketed_sales a JOIN bucketed_customers b
ON a.customer_id = b.id
4.3 执行引擎调优
-
Spark SQL配置参数:
内存设置
spark.executor.memory=8G
spark.executor.memoryOverhead=2G并行度
spark.sql.shuffle.partitions=200
动态分区
spark.sql.sources.partitionOverwriteMode=dynamic
5 常见问题与解决方案
5.1 元数据同步问题
问题现象:
-
在Spark中创建的表Hive看不到
-
Hive中的表结构变更Spark不感知
解决方案: -
确保使用外部表(external table)而非内部表
-
设置自动刷新元数据:
spark.sql("REFRESH TABLE hive_db.sales_table")
-
配置统一的元数据版本:
spark.sql.hive.metastore.version=3.1.2
spark.sql.hive.metastore.jars=builtin
5.2 数据类型兼容性问题
|-----------|---------------|---------|
| Hive类型 | Spark SQL类型 | 注意事项 |
| TINYINT | ByteType | 无 |
| SMALLINT | ShortType | 无 |
| INT | IntegerType | 无 |
| BIGINT | LongType | 无 |
| FLOAT | FloatType | 精度可能不同 |
| DOUBLE | DoubleType | 无 |
| DECIMAL | DecimalType | 需指定精度 |
| STRING | StringType | 无 |
| VARCHAR | StringType | 长度可能截断 |
| TIMESTAMP | TimestampType | 时区处理需注意 |
| DATE | DateType | 无 |
| ARRAY | ArrayType | 元素类型需兼容 |
| MAP | MapType | 键值类型需兼容 |
| STRUCT | StructType | 字段需一一对应 |
5.3 权限与安全配置
-
Kerberos认证:
spark.yarn.principal=user@REALM
spark.yarn.keytab=/path/to/keytab
spark.hadoop.hive.metastore.sasl.enabled=true -
**Ranger/Sentry集成:**配置统一的权限策略,确保Spark和Hive使用相同的权限管理服务
-
HDFS ACL:
hdfs dfs -setfacl -m user:spark:r-x /user/hive/warehouse
6 实践总结
统一元数据管理:
- 使用外部Hive Metastore服务
- 避免在Spark和Hive中重复创建相同表
数据格式选择:- 优先使用Parquet或ORC格式
- 保持Spark和Hive侧的格式一致
资源隔离:- 为Hive和Spark配置独立的资源队列
- 使用YARN的队列管理功能
监控与调优:- 监控Spark UI和Hive查询日志
- 定期分析执行计划并进行优化
版本兼容性:- 保持Spark和Hive版本的兼容
- 测试主要功能在升级前后的表现

在实际项目中,应根据具体需求和环境选择合适的集成方案,并持续优化以获得最佳性能。混合计算架构能够充分发挥两种技术的优势,为大数据处理提供更加灵活高效的解决方案。