1.任务介绍
任务来源: DQN: Deep Q Learning |自动驾驶入门(?) |算法与实现
任务原始代码: self-driving car
最终效果:
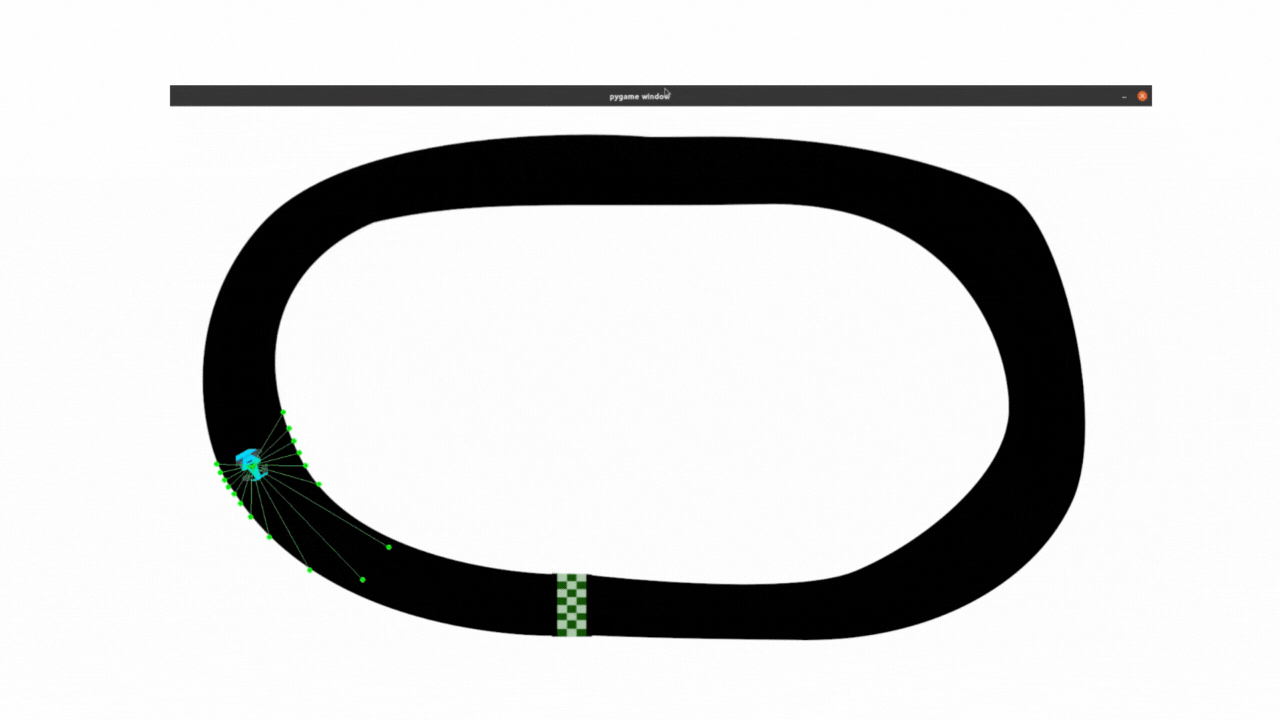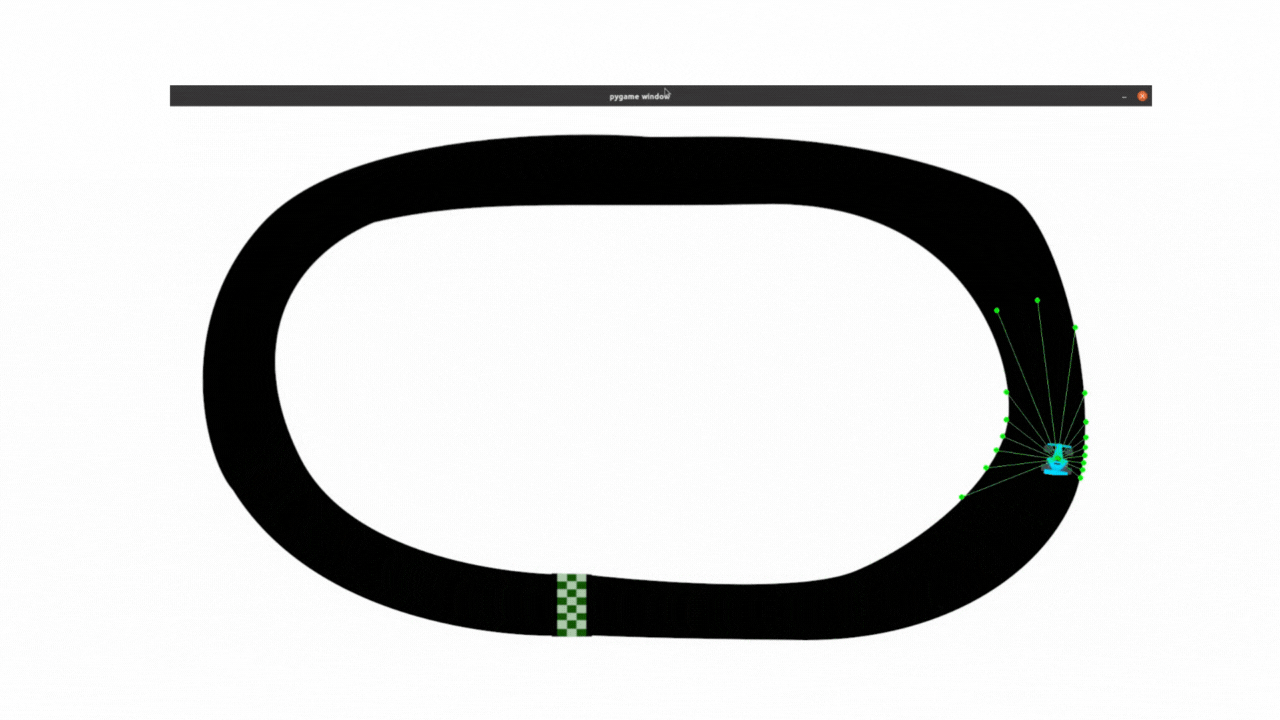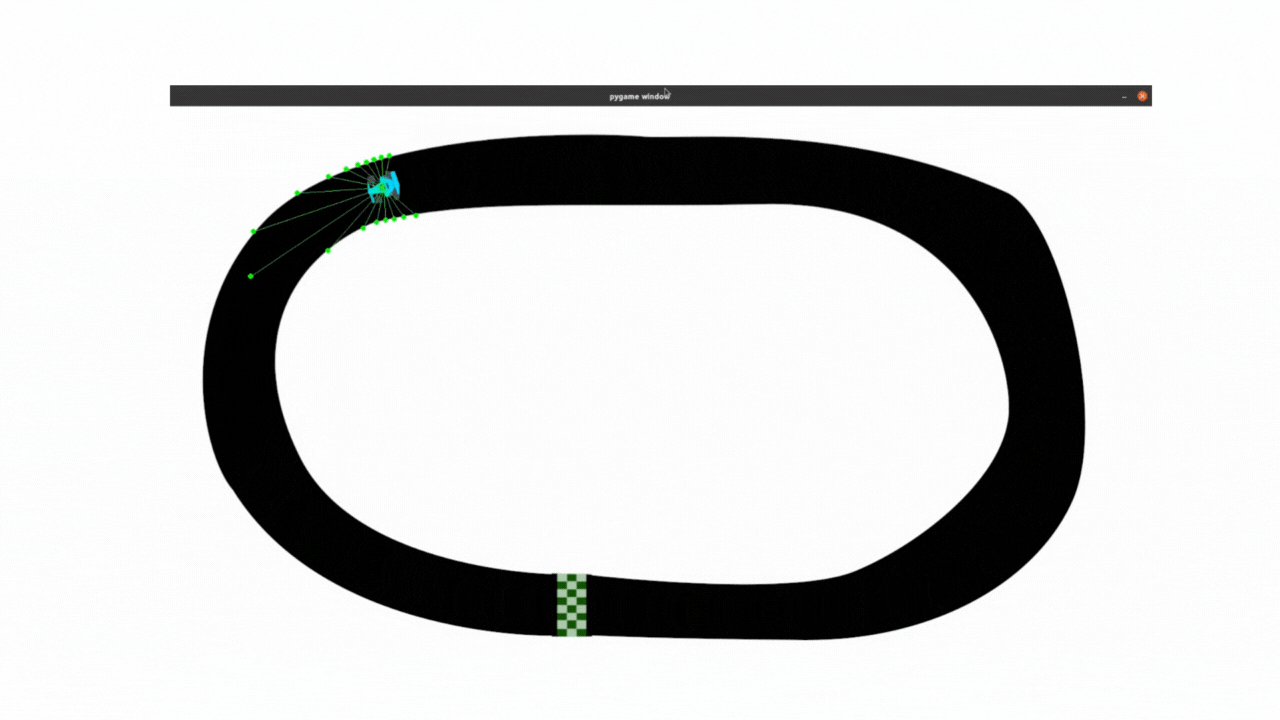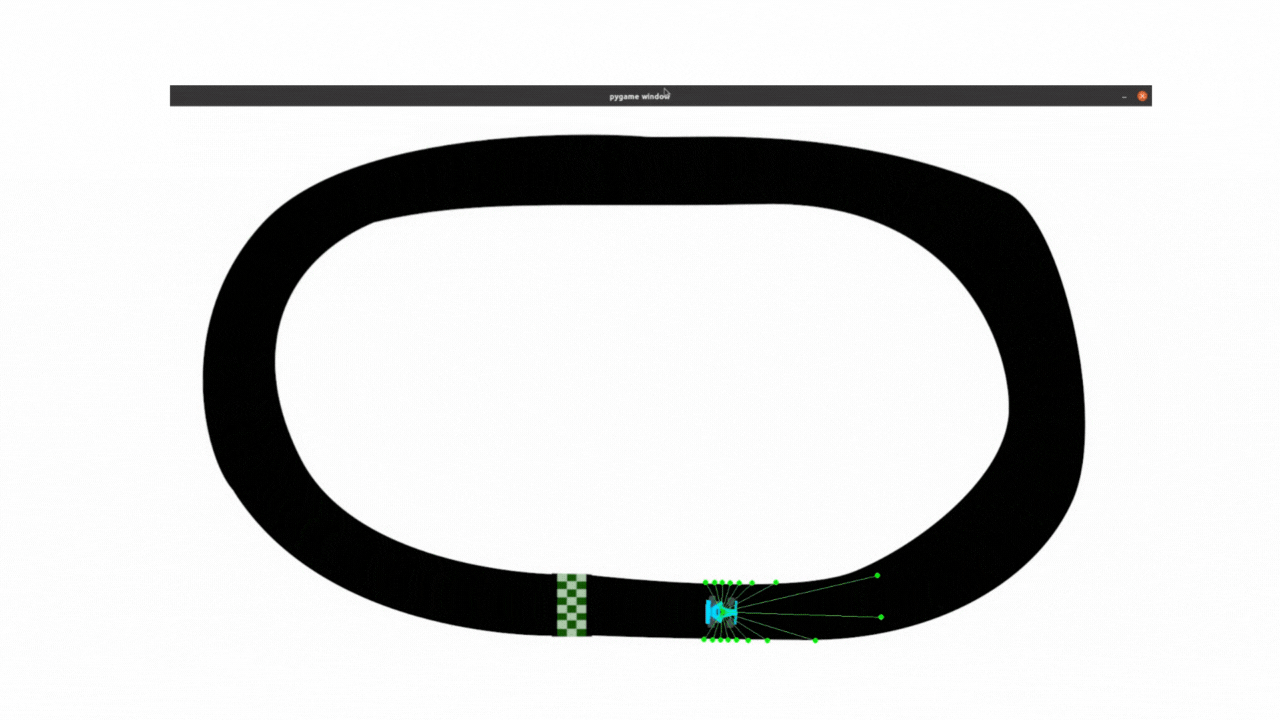
以下所有内容,都是对上面DQN代码的改进,在与deepseek的不断提问交互中学习理解代码,并且对代码做出改进,让小车能够尽可能的跑的远 。
这个DQN代码依然有很多可改进的地方,受限于个人精力,没有再继续探索下去,欢迎指正交流。
后续会更新DDPG算法和PPO算法在此任务上的应用调试记录的代码。
2.调试记录
问题:使用原始DQN代码,小车很难学习到正确的策略去绕圈,并且跑的距离也很短
2.1 更改学习率(lr)和探索率(eps_end)
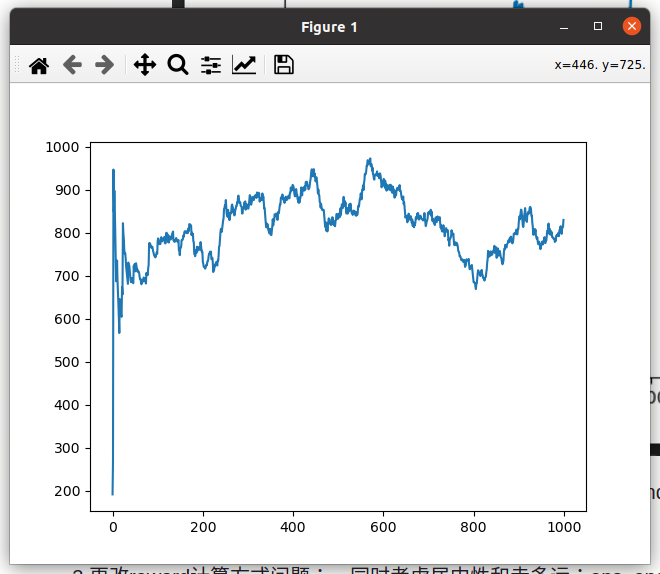
记录:图片为最初设置的average_score,增大减小都没有显著效果;
2.2 增加模型层数
记录 :模型采用三层,中间增加256*256的隐藏层;模型增加一层之后,效果显著提升,训练到400次的时候,average_score已经能够达到5.3w
原因 :模型太简单了,这样的结构可能不足以捕捉复杂的状态空间,导致训练的效果差;
现阶段问题:横向是不太稳定的,小车跑起来方向频繁抖动,且整体流畅度不够
2.3 横纵向action细化,同时更改max_mem_size=1000000
记录 :5,0,2,1,2,-1,0,1,0,0,0,-1,-2,1,-2,-1,-5,0,一共9中组合;修改完之后流畅度有较大提升,avg_score也有很大提升;
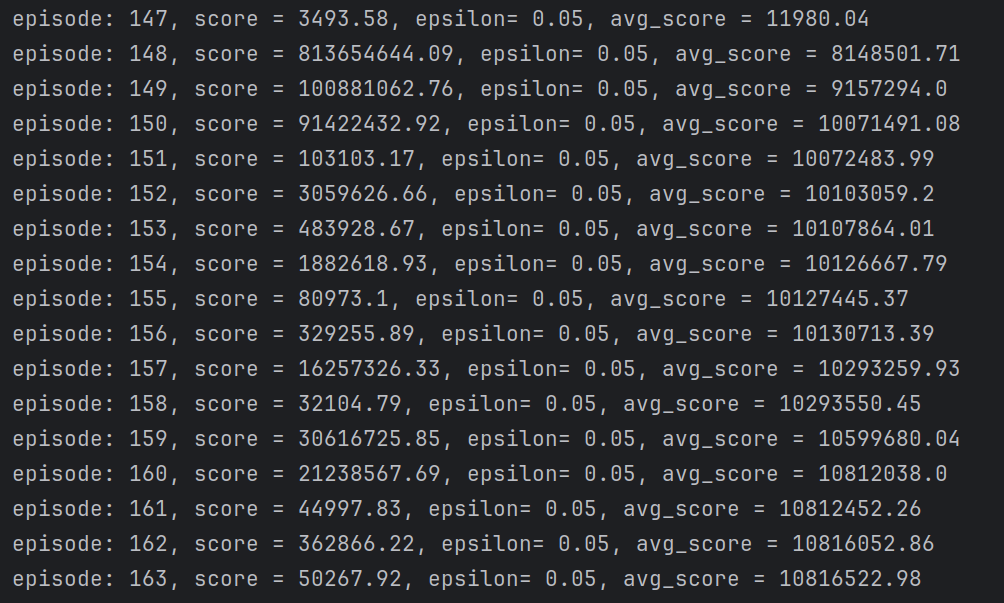
2.4 奖励函数优化
记录 :奖励函数去掉距离的概念,主要考虑居中性、速度的连续性、转角的连续性;可以看到avg_score已经可以达到非常大的值,变化趋势都是先持续增加,然后在迭代次数达到200-300次左右时震荡下降
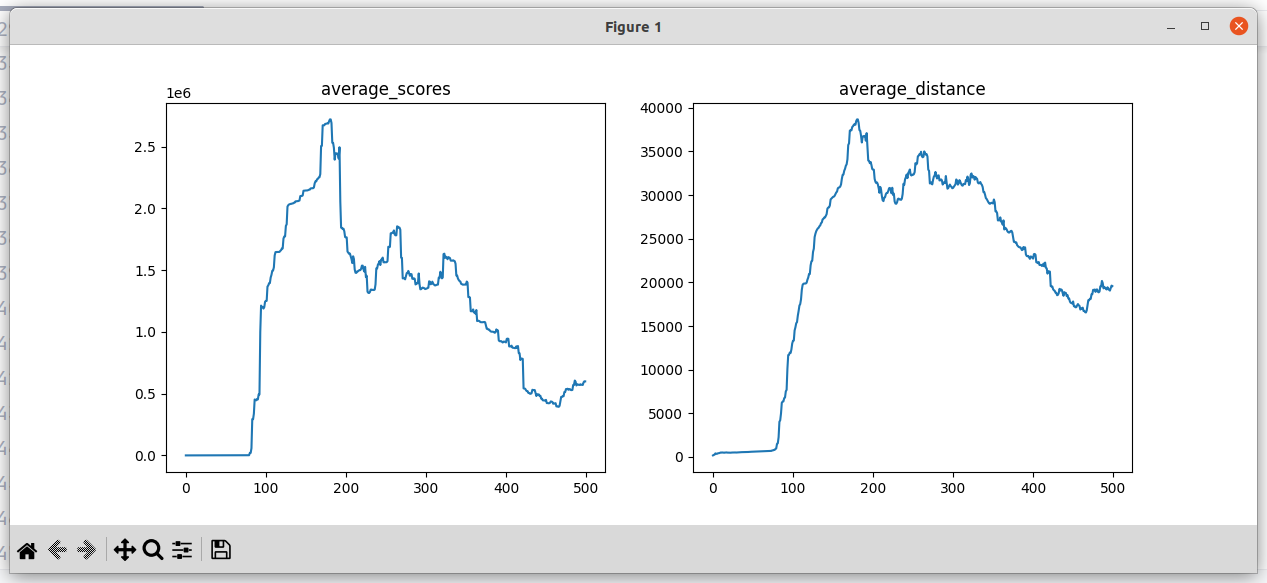
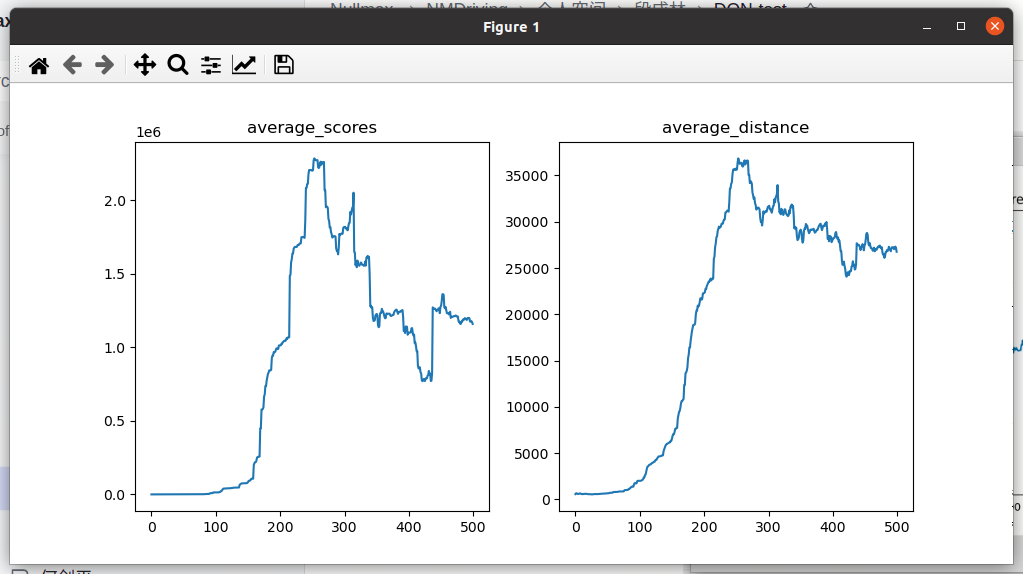
现阶段问题:avg_score变化趋势都是先持续增加,然后在迭代次数达到200-300次左右时震荡下降
2.5 增加目标网络,且目标网络更新用软更新
记录 :原始DNQ代码中是没有目标网络的,训练震荡会比较大,增加目标网络可以稳定训练; 小车在行驶过程中频繁的小幅度左右摇头的情况变少了,不过感觉纵向的加减速比较频繁,目标网络用软更新之后明显感觉在两台电脑上训练起来性能提升都很快,70次左右的时候都达到了百万级别,前期分数异常高,后期分数抖动很大
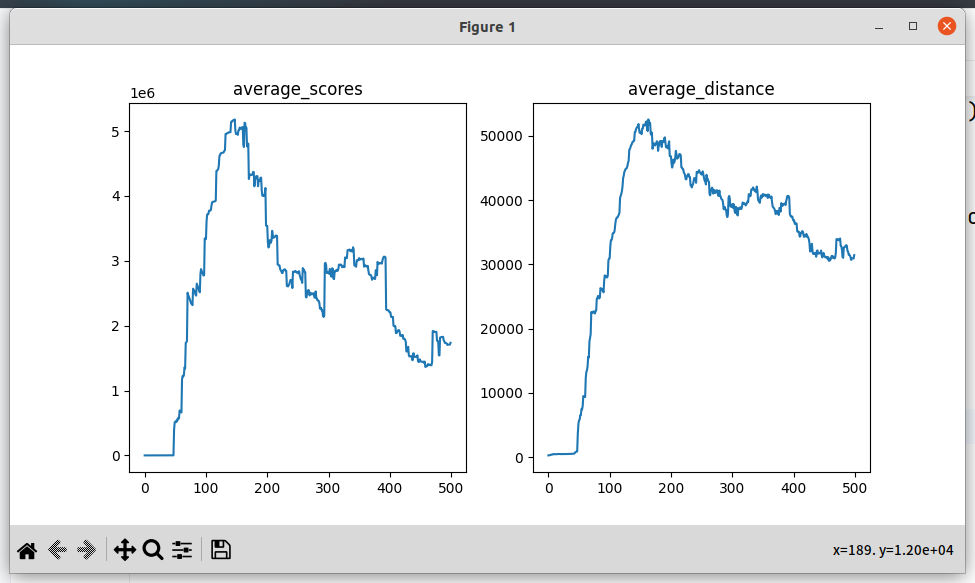
2.6 状态中增加最小距离,自车车速,自车转角,使得问题符合MDP
记录 :这一点其实早该考虑到的,原来的状态返回之后雷达距离,是缺少一些自车相关的信息
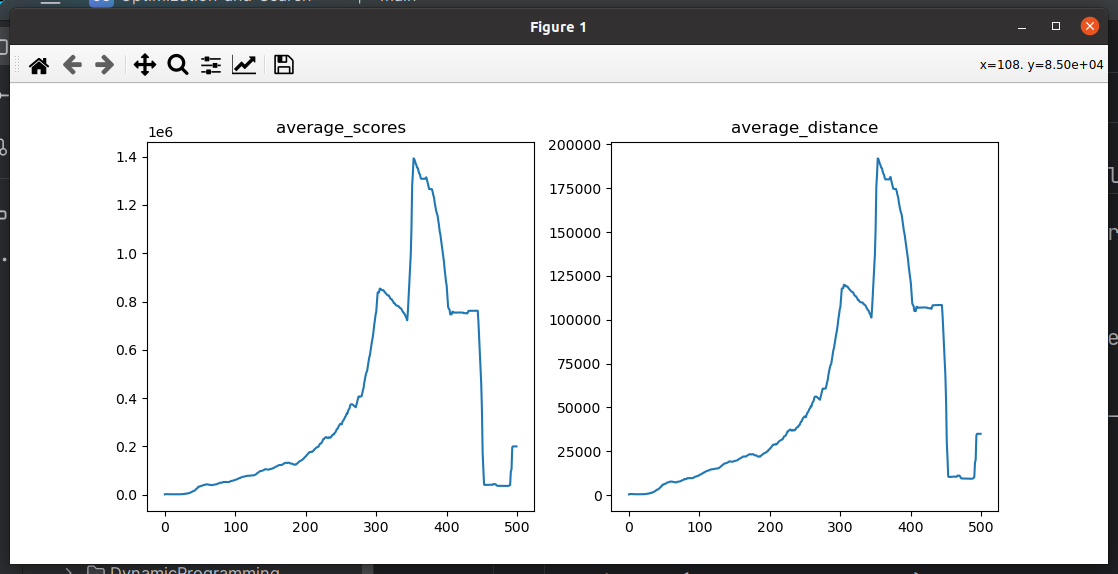
现阶段问题 :模型在290次左右的时候score达到峰值,后面越训练得分越低
原因:核心原因应该还是之前的经验被遗忘导致的,memory_size由100W改为1000W就有很大改善了
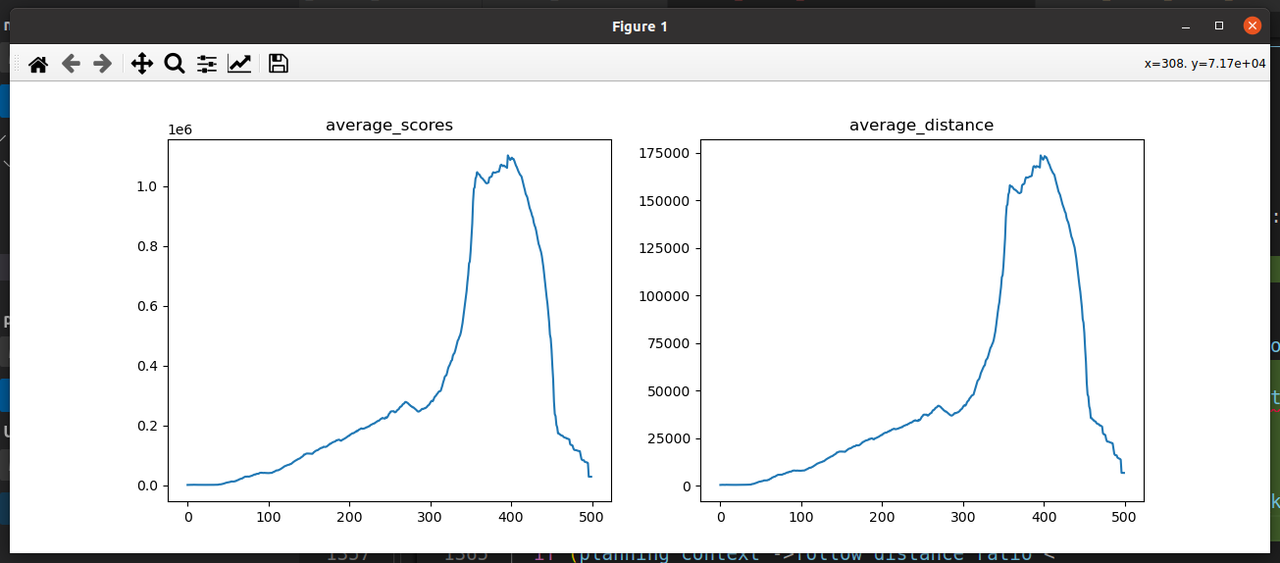
2.7 状态中雷达数据去掉强制int转换,防止丢失精度影响模型策略学习和泛化能力
记录 :最大score能到250W了,并且mem_cntr已经远远超过100W,证明有帮助,不过仍然存在越训练score越低的情况,大概在sp355次左右;在去掉雷达int的强制转换之后,训练效果有很大提升;

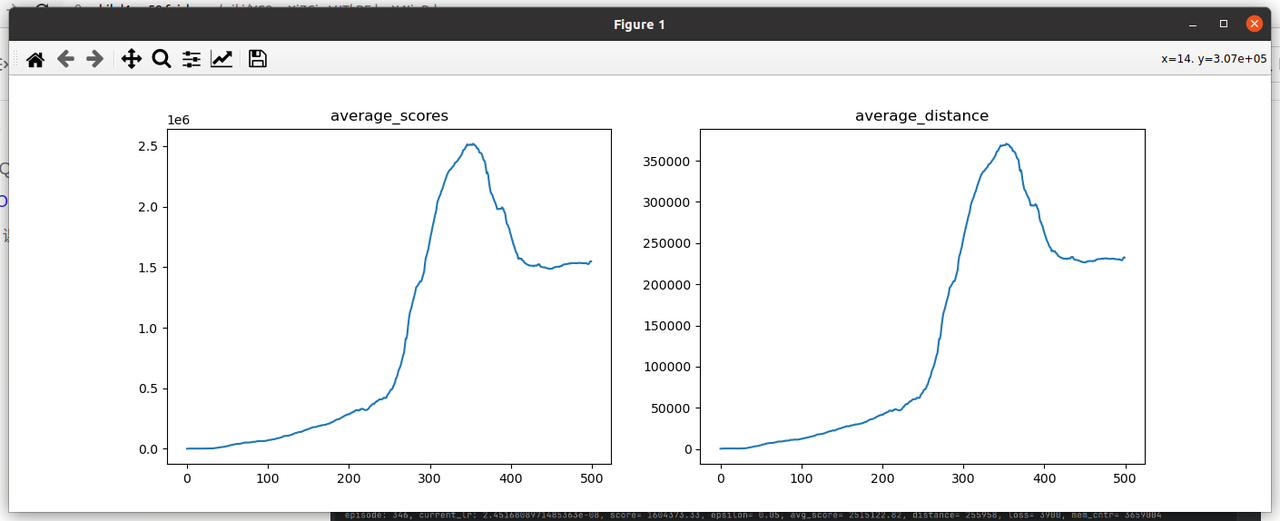
2.8 observation归一化
记录 :episode 145,单次score已经能够达到2.5亿左右,平均score达到500W
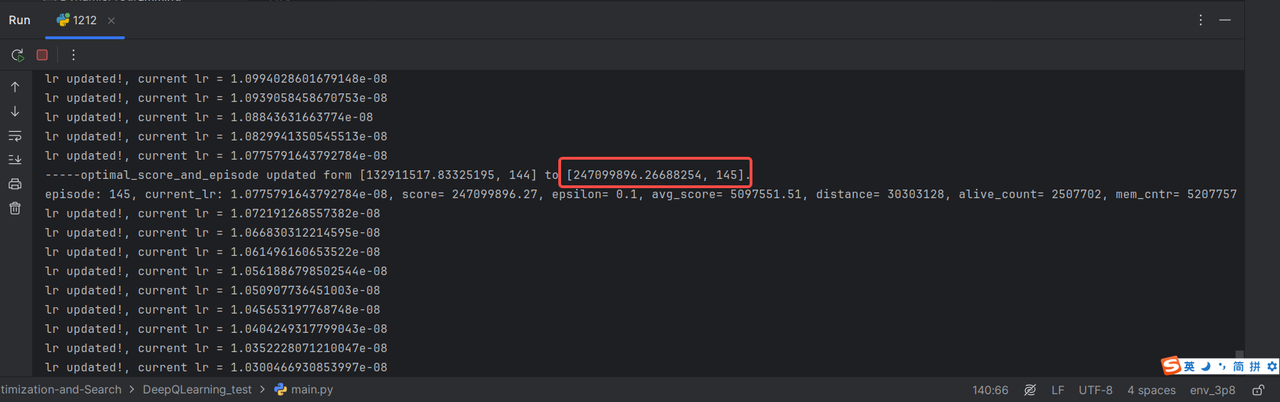
3.代码主要改进点
3.1 DeepQNetwork
1.网络增加一层;
python
class DeepQNetwork(nn.Module):
def __init__(self, lr, input_dims, n_actions):
...
# 网络增加一层
self.fc1 = nn.Linear(*input_dims, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, n_actions)
...2.网络激活函数改变;
python
class DeepQNetwork(nn.Module):
def forward(self, state):
# 激活函数也做了一定的尝试变更
x = F.relu(self.fc1(state))
x = F.tanh(self.fc2(x))
...3.输出action做对应适配;
python
class DeepQNetwork(nn.Module):
def forward(self, state):
...
# 输出action也做对应适配
actions = self.fc3(x)
return actions3.2 Agent
1.增加目标网络,用于稳定训练;
python
class Agent:
def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,
max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):
...
self.Q_eval = DeepQNetwork(lr, input_dims, n_actions)
# 增加目标网络,用于稳定训练
self.Q_target = DeepQNetwork(lr, input_dims, n_actions)
...
def learn_dqp(self, n_game):
...
# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。
Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]
# 直接调self.Q_target(new_state_batch)和self.Q_eval.forward(new_state_batch)的效果是一样的
q_next = self.Q_target(new_state_batch)
...2.增加学习率调度器(指数衰减);
python
class Agent:
def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,
max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):
...
self.lr_min = 1e-6
self.loss_value = 0
# 新增学习率调度器(指数衰减)
self.lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.Q_eval.optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
self.action_memory = np.zeros(self.mem_size, dtype=np.int32)
...
def learn_dqp(self, n_game):
...
self.Q_eval.optimizer.step()
# 学习率调整必须在参数更新之后
if self.mem_cntr % 2000 == 0:
if self.lr_scheduler.get_last_lr()[0] > self.lr_min:
self.lr_scheduler.step() # 调整学习率
print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))
...3.目标网络参数更新采用软更新;
python
class Agent:
def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,
max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):
...
self.Q_target = DeepQNetwork(lr, input_dims, n_actions)
self.update_target_freq = 1000 # 每1000步同步一次
self.tau = 0.05 # 软更新系数
...
def soft_update_target(self):
for target_param, param in zip(self.Q_target.parameters(),
self.Q_eval.parameters()):
target_param.data.copy_(
self.tau * param.data + (1 - self.tau) * target_param.data
)
def learn_dqp(self, n_game):
...
# 软更新目标网络
self.soft_update_target()
...4.增加了double-DQN的实现方式;
python
class Agent:
def learn_double_dqp(self, n_game):
# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?
# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数
if self.mem_cntr < self.batch_size:
return
self.Q_eval.optimizer.zero_grad()
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
batch_index = np.arange(self.batch_size, dtype=np.int32)
state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)
new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)
reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)
terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)
action_batch = self.action_memory[batch]
# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。
Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]
# ========== Double DQN修改部分 ==========
q_eval_next = self.Q_eval(new_state_batch)
max_actions = torch.argmax(q_eval_next, dim=1)
# 输出为[batch_size,action_size],每一行对应随机选取的state,每一列对应当前state对应的每个action估计的Q值
# print(q_eval_next)
# 输出为每个state下能够得到最大Q值的action,dim为1*batch_size
# print(max_actions)
# 输出为每个state下能够得到最大Q值的action,不过将dim转换为了batch_size*1
# print(max_actions.unsqueeze(1))
# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,dim=batch_size*1
# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)))
# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,不过将dim转换为了1*batch_size
# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1))
q_next = self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1)
q_next[terminal_batch] = 0.0
q_target = reward_batch + self.gamma * q_next
# =======================================
# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新
# 模型,所以你最大化你的value function,就是在最优化你的policy本身
loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)
self.loss_value = loss.item()
loss.backward()
# 添加梯度裁剪
# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)
self.Q_eval.optimizer.step()
# 学习率调整必须在参数更新之后
if self.mem_cntr % 2000 == 0:
if self.lr_scheduler.get_last_lr()[0] > self.lr_min:
self.lr_scheduler.step() # 调整学习率
print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))
# 软更新目标网络
self.soft_update_target()
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min3.3 Agent
1.小车返回状态优化;
状态中增加最小距离,自车车速,自车转角,使得问题符合MDP;
状态中雷达数据去掉强制int转换,防止丢失精度影响模型策略学习和泛化能力;
observation归一化;
python
class Car:
def get_data(self):
# Get Distances To Border
return_values = [0] * len(self.radars)
self.current_lateral_min_dist = 60
for i, radar in enumerate(self.radars):
return_values[i] = radar[1] / 300.0
if radar[1] < self.current_lateral_min_dist:
self.current_lateral_min_dist = radar[1]
angle_rad = np.deg2rad(self.angle)
return_values = return_values + [self.current_lateral_min_dist / 30,
np.clip(self.speed / 20.0, 0.0, 1.0),
np.sin(angle_rad), np.cos(angle_rad)]
return return_values2.奖励函数优化;
主要去掉了距离的概念,引入居中性、速度连续性、转角连续性概念,这么设计是因为只要小车始终保持居中,并且有速度,小车就可以一直跑下去;
python
class Car:
def get_reward_optimized(self, game_map, alive_count_total):
# 居中性
lateral_reward = 1.0
# print(self.current_lateral_min_dist)
if self.current_lateral_min_dist / 60 > 0.5:
lateral_reward = self.current_lateral_min_dist / 60
elif self.current_lateral_min_dist / 60 < 0.4:
lateral_reward = -0.5
else:
lateral_reward = 0.0
# 速度基础
speed_base_reward = self.speed / min(12 + alive_count_total / 100000, 20)
# 速度连续性
if len(self.speed_memory) >= 4:
self.speed_memory = self.speed_memory[1:]
self.speed_memory.append(self.speed)
speed_up_discount = 1.0
if self.speed_memory[-1] - self.speed_memory[0] >= 3 and lateral_reward > 0.0:
speed_up_discount = -0.5
elif self.speed_memory[-1] - self.speed_memory[0] >= 2 and lateral_reward > 0.0:
speed_up_discount = 0.7
# 转角连续性,写的随意了点,目的就是防止方向左右抖动
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(self.angle)
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)
return 100 * lateral_reward * speed_up_discount * angle_discount3.4 train
1.action优化;
python
def train():
...
agent = Agent(gamma=0.99, epsilson=1.0, batch_size=256, n_actions=9,
eps_end=0.1, input_dims=[num_radar + 4], lr=0.005,
max_mem_size=1000000, eps_dec=1e-4)
...
while not done:
action = agent.choose_action(observation)
# [5,0],[2,1],[2,-1],[0,1],[0,0],[0,-1],[-2,1],[-2,-1],[-5,0]
if action == 0:
car.angle += 5
car.speed += 0
elif action == 1:
car.angle += 2
if car.speed < 20:
car.speed += 1
elif action == 2:
car.angle += 2
if car.speed - 1 >= 12:
car.speed -= 1
elif action == 3:
car.angle += 0
if car.speed < 20:
car.speed += 1
elif action == 4:
car.angle += 0
car.speed += 0
elif action == 5:
car.angle += 0
if car.speed - 1 >= 12:
car.speed -= 1
elif action == 6:
car.angle -= 2
if car.speed < 20:
car.speed += 1
elif action == 7:
car.angle -= 2
if car.speed - 1 >= 12:
car.speed -= 1
else:
car.angle -= 5
car.speed += 0
...4.任务思考
1.DQN为什么不能处理连续控制性问题?
DQN的核心思想是为每个可能的动作计算Q值,并选择Q值最大的动作。在连续动作空间中,动作是无限多的,连续动作空间离散化会造成维度灾难
2.DQN总是过估计的原因?

一方面总是取max操作;另一方面用自己的估计再去估计自己,如果当前已经出现高估,那么下一轮的TD-target更会高估,相当于高估会累计
3.计算loss时,q_target对应的是每个状态下的最大Q值的动作,而Q_eval对应的却是从action_memory中随机选取的一批动作。这样是否会导致动作不匹配的问题,进而影响学习效果?
在DQN中,q_target的计算遵循目标策略(最大化Q值),而Q_eval基于行为策略(实际执行的动作)。这种分离是Q-learning的核心设计,不会导致动作不匹配问题,反而是算法收敛的关键。
Q_eval的作用:
估实际动评作的价值:即使动作是随机探索的,也需要知道这些动作的历史价值。
更新方向:
通过loss = (q_target - Q_eval)^2,将实际动作的Q值向更优的目标值调整。
q_target的作用:
引导策略优化:通过最大化下一状态的Q值,逐步将策略向最优方向推进。
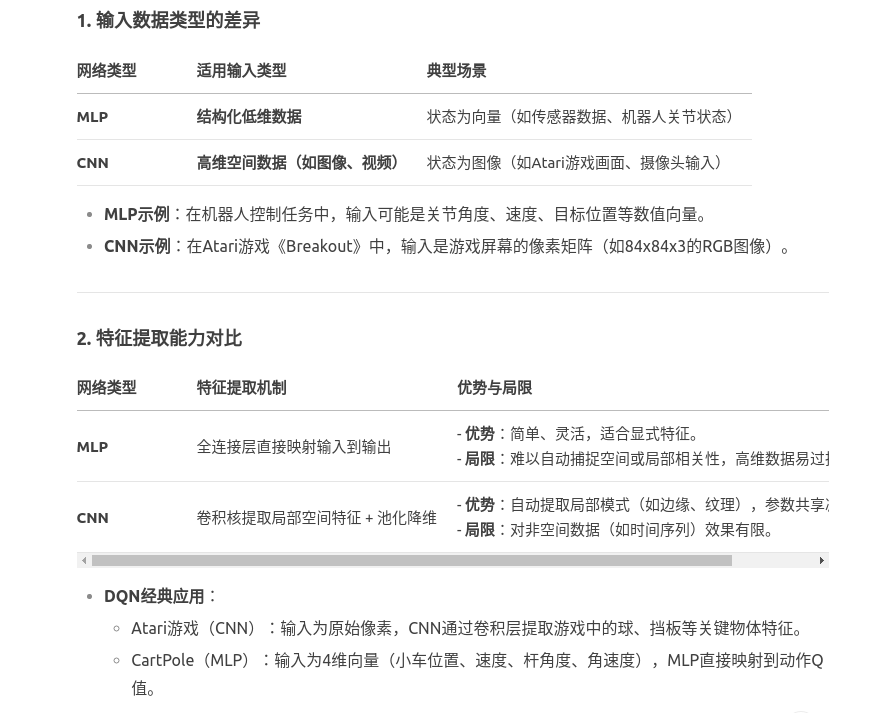
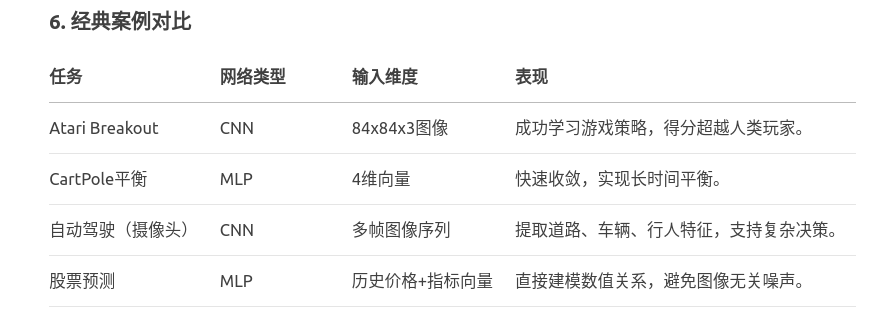
4.DQN算法的网络中,使用MLP和使用CNN会有什么差异?
总结:
MLP:适合低维结构化数据,依赖显式特征工程,计算简单但高维易过拟合。
CNN:适合高维空间数据(如图像),自动提取局部特征,参数共享提升效率。
选择关键:根据输入数据的空间属性和维度,权衡特征提取需求与计算资源。
在DQN中,合理选择网络结构是平衡性能与效率的核心。例如,Atari DQN的成功离不开CNN对图像特征的自动提取,而简单控制任务中MLP的轻量化优势则更为突出。



5.完整代码
调试过程中的一些代码保留着,以提些许思考。
python
from typing import AsyncGenerator
import pygame
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import math
import os
class DeepQNetwork(nn.Module):
def __init__(self, lr, input_dims, n_actions):
super(DeepQNetwork, self).__init__()
self.input_dims = input_dims
self.n_actions = n_actions
# 网络增加一层
self.fc1 = nn.Linear(*input_dims, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, n_actions)
self.fc = nn.Linear(*input_dims, n_actions)
self.optimizer = optim.Adam(self.parameters(), lr=lr)
self.loss = nn.MSELoss()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.to(self.device)
def forward(self, state):
# 激活函数也做了一定的尝试变更
x = F.relu(self.fc1(state))
x = F.tanh(self.fc2(x))
# 输出action也做对应适配
actions = self.fc3(x)
return actions
class Agent:
def __init__(self, gamma, epsilson, lr, input_dims, batch_size, n_actions,
max_mem_size=100000, eps_end=0.01, eps_dec=5e-4):
self.gamma = gamma
self.epsilon = epsilson
self.eps_min = eps_end
self.eps_dec = eps_dec
self.lr = lr
self.action_space = [i for i in range(n_actions)]
self.mem_size = max_mem_size # memory size
self.batch_size = batch_size
self.mem_cntr = 0 # memory current
self.input_dims = input_dims
self.n_actions = n_actions
self.Q_eval = DeepQNetwork(lr, input_dims, n_actions)
self.Q_target = DeepQNetwork(lr, input_dims, n_actions)
self.update_target_freq = 1000 # 每1000步同步一次
self.tau = 0.05 # 软更新系数
self.lr_min = 1e-6
self.state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
self.new_state_memory = np.zeros((self.mem_size, *input_dims), dtype=np.float32)
self.loss_value = 0
# 新增学习率调度器(指数衰减)
self.lr_scheduler = optim.lr_scheduler.ExponentialLR(
self.Q_eval.optimizer,
gamma=0.995 # 每episode学习率衰减0.5%
)
self.action_memory = np.zeros(self.mem_size, dtype=np.int32)
self.reward_memory = np.zeros(self.mem_size, dtype=np.float32)
self.terminal_memory = np.zeros(self.mem_size, dtype=bool)
def store_transition(self, state_old, action, reward, state_new, done):
index = self.mem_cntr % self.mem_size
self.state_memory[index] = state_old
self.new_state_memory[index] = state_new
self.reward_memory[index] = reward
self.action_memory[index] = action
self.terminal_memory[index] = done
self.mem_cntr += 1
def choose_action(self, observation):
if np.random.random() > self.epsilon:
state = torch.tensor([observation], dtype=torch.float32).to(self.Q_eval.device)
actions = self.Q_eval.forward(state)
action = torch.argmax(actions).item()
else:
action = np.random.choice(self.action_space)
return action
def soft_update_target(self):
for target_param, param in zip(self.Q_target.parameters(),
self.Q_eval.parameters()):
target_param.data.copy_(
self.tau * param.data + (1 - self.tau) * target_param.data
)
def learn_dqp(self, n_game):
# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?
# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数
if self.mem_cntr < self.batch_size:
return
self.Q_eval.optimizer.zero_grad()
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
batch_index = np.arange(self.batch_size, dtype=np.int32)
state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)
new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)
reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)
terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)
action_batch = self.action_memory[batch]
# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。
Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]
# 直接调self.Q_target(new_state_batch)和self.Q_eval.forward(new_state_batch)的效果是一样的
q_next = self.Q_target(new_state_batch)
# 终止状态(Terminal State):如果当前状态转移后进入终止状态(例如游戏结束、任务完成或失败),
# 则没有下一个状态s′,因此未来累积奖励的期望值为0。
q_next[terminal_batch] = 0.0
# 目标网络对每个state对应能够得到的最大Q值的action
# print(torch.max(q_next, dim=1))
# 目标网络对每个state对应能够得到的最大Q值
# print(torch.max(q_next, dim=1)[0])
q_target = reward_batch + self.gamma * torch.max(q_next, dim=1)[0]
# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新
# 模型,所以你最大化你的value function,就是在最优化你的policy本身
loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)
self.loss_value = loss.item()
loss.backward()
# 添加梯度裁剪
# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)
self.Q_eval.optimizer.step()
# 学习率调整必须在参数更新之后
if self.mem_cntr % 2000 == 0:
if self.lr_scheduler.get_last_lr()[0] > self.lr_min:
self.lr_scheduler.step() # 调整学习率
print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))
# 软更新目标网络
self.soft_update_target()
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
def learn_double_dqp(self, n_game):
# TODO: 看一下这一块是不是论文中提到的每间几千步更新一下?
# 这一块他设定了一个batch_size=64,即每64个为一批,然后通过模型更新一下参数
if self.mem_cntr < self.batch_size:
return
self.Q_eval.optimizer.zero_grad()
max_mem = min(self.mem_cntr, self.mem_size)
batch = np.random.choice(max_mem, self.batch_size, replace=False)
batch_index = np.arange(self.batch_size, dtype=np.int32)
state_batch = torch.tensor(self.state_memory[batch]).to(self.Q_eval.device)
new_state_batch = torch.tensor(self.new_state_memory[batch]).to(self.Q_eval.device)
reward_batch = torch.tensor(self.reward_memory[batch]).to(self.Q_eval.device)
terminal_batch = torch.tensor(self.terminal_memory[batch]).to(self.Q_eval.device)
action_batch = self.action_memory[batch]
# TODO: 确认下为什么要用[batch_index, action_batch]----其目的是为每个样本选择实际执行动作的Q值。
Q_eval = self.Q_eval.forward(state_batch)[batch_index, action_batch]
# ========== Double DQN修改部分 ==========
q_eval_next = self.Q_eval(new_state_batch)
max_actions = torch.argmax(q_eval_next, dim=1)
# 输出为[batch_size,action_size],每一行对应随机选取的state,每一列对应当前state对应的每个action估计的Q值
# print(q_eval_next)
# 输出为每个state下能够得到最大Q值的action,dim为1*batch_size
# print(max_actions)
# 输出为每个state下能够得到最大Q值的action,不过将dim转换为了batch_size*1
# print(max_actions.unsqueeze(1))
# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,dim=batch_size*1
# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)))
# 输出为,之前得到的每个state下对应的最优action,在当前网络中对应的Q值,不过将dim转换为了1*batch_size
# print(self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1))
q_next = self.Q_target(new_state_batch).gather(1, max_actions.unsqueeze(1)).squeeze(1)
q_next[terminal_batch] = 0.0
q_target = reward_batch + self.gamma * q_next
# =======================================
# 估计Q值,因为Q值本来就是未来的预期奖励,我们通过估计未来的预期奖励和当前实际过得的预期奖励的差值,来更新
# 模型,所以你最大化你的value function,就是在最优化你的policy本身
loss = self.Q_eval.loss(q_target, Q_eval).to(self.Q_eval.device)
self.loss_value = loss.item()
loss.backward()
# 添加梯度裁剪
# torch.nn.utils.clip_grad_norm_(self.Q_eval.parameters(), max_norm=1.0)
self.Q_eval.optimizer.step()
# 学习率调整必须在参数更新之后
if self.mem_cntr % 2000 == 0:
if self.lr_scheduler.get_last_lr()[0] > self.lr_min:
self.lr_scheduler.step() # 调整学习率
print("lr updated!, current lr = {}".format(self.lr_scheduler.get_last_lr()[0]))
# 软更新目标网络
self.soft_update_target()
self.epsilon = self.epsilon - self.eps_dec if self.epsilon > self.eps_min else self.eps_min
WIDTH = 1920
HEIGHT = 1080
CAR_SIZE_X = 60
CAR_SIZE_Y = 60
BORDER_COLOR = (255, 255, 255, 255) # Color To Crash on Hit
current_generation = 0 # Generation counter
class Car:
def __init__(self, boundary_x, boundary_y, num_radar):
# Load Car Sprite and Rotate
self.sprite = pygame.image.load('car.png').convert() # Convert Speeds Up A Lot
self.sprite = pygame.transform.scale(self.sprite, (CAR_SIZE_X, CAR_SIZE_Y))
self.rotated_sprite = self.sprite
# self.position = [690, 740] # Starting Position
self.position = [830, 920] # Starting Position
self.angle = 0
self.angle_memory = []
self.speed = 0
self.speed_memory = []
self.speed_set = False # Flag For Default Speed Later on
self.center = [self.position[0] + CAR_SIZE_X / 2, self.position[1] + CAR_SIZE_Y / 2] # Calculate Center
self.radars = [[(0, 0), 60]] * num_radar # List For Sensors / Radars
self.drawing_radars = [] # Radars To Be Drawn
self.current_lateral_min_dist = 60
self.alive = True # Boolean To Check If Car is Crashed
self.distance = 0 # Distance Driven
self.time = 0 # Time Passed
self.width = 0
self.height = 0
self.boundary_x = boundary_x
self.boundary_y = boundary_y
def draw(self, screen):
screen.blit(self.rotated_sprite, self.position) # Draw Sprite
self.draw_radar(screen) # OPTIONAL FOR SENSORS
def draw_radar(self, screen):
# Optionally Draw All Sensors / Radars
for radar in self.radars:
position = radar[0]
pygame.draw.line(screen, (0, 255, 0), self.center, position, 1)
pygame.draw.circle(screen, (0, 255, 0), position, 5)
def check_collision(self, game_map):
self.alive = True
for point in self.corners:
# If Any Corner Touches Border Color -> Crash
# Assumes Rectangle
if game_map.get_at((int(point[0]), int(point[1]))) == BORDER_COLOR:
self.alive = False
break
def check_radar(self, degree, game_map):
length = 0
x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)
y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)
# While We Don't Hit BORDER_COLOR AND length < 300 (just a max) -> go further and further
while not game_map.get_at((x, y)) == BORDER_COLOR and length < 300:
length = length + 1
x = int(self.center[0] + math.cos(math.radians(360 - (self.angle + degree))) * length)
y = int(self.center[1] + math.sin(math.radians(360 - (self.angle + degree))) * length)
# Calculate Distance To Border And Append To Radars List TODO: update dist calculate
dist = int(math.sqrt(math.pow(x - self.center[0], 2) + math.pow(y - self.center[1], 2)))
self.radars.append([(x, y), dist])
def update(self, game_map):
# Set The Speed To 20 For The First Time
# Only When Having 4 Output Nodes With Speed Up and Down
if not self.speed_set:
self.speed = 10
self.speed_set = True
self.width, self.height = game_map.get_size()
# Get Rotated Sprite And Move Into The Right X-Direction
# Don't Let The Car Go Closer Than 20px To The Edge
self.rotated_sprite = self.rotate_center(self.sprite, self.angle)
self.position[0] += math.cos(math.radians(360 - self.angle)) * self.speed
self.position[0] = max(self.position[0], 20)
self.position[0] = min(self.position[0], WIDTH - 120)
# Increase Distance and Time
self.distance += self.speed
self.time += 1
# Same For Y-Position
self.position[1] += math.sin(math.radians(360 - self.angle)) * self.speed
self.position[1] = max(self.position[1], 20)
self.position[1] = min(self.position[1], WIDTH - 120)
# Calculate New Center
self.center = [int(self.position[0]) + CAR_SIZE_X / 2, int(self.position[1]) + CAR_SIZE_Y / 2]
# print("center: {}".format(self.center))
# Calculate Four Corners
# Length Is Half The Side
length = 0.5 * CAR_SIZE_X
left_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 30))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 30))) * length]
right_top = [self.center[0] + math.cos(math.radians(360 - (self.angle + 150))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 150))) * length]
left_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 210))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 210))) * length]
right_bottom = [self.center[0] + math.cos(math.radians(360 - (self.angle + 330))) * length,
self.center[1] + math.sin(math.radians(360 - (self.angle + 330))) * length]
self.corners = [left_top, right_top, left_bottom, right_bottom]
# Check Collisions And Clear Radars
self.check_collision(game_map)
self.radars.clear()
# From -90 To 120 With Step-Size 45 Check Radar
for d in range(-120, 126, 15): # -90,-45,0,45,90z
self.check_radar(d, game_map)
def get_data(self):
# Get Distances To Border
return_values = [0] * len(self.radars)
self.current_lateral_min_dist = 60
for i, radar in enumerate(self.radars):
return_values[i] = radar[1] / 300.0
if radar[1] < self.current_lateral_min_dist:
self.current_lateral_min_dist = radar[1]
angle_rad = np.deg2rad(self.angle)
return_values = return_values + [self.current_lateral_min_dist / 30,
np.clip(self.speed / 20.0, 0.0, 1.0),
np.sin(angle_rad), np.cos(angle_rad)]
return return_values
def is_alive(self):
# Basic Alive Function
return self.alive
def get_reward_optimized(self, game_map, alive_count_total):
# 居中性
lateral_reward = 1.0
# print(self.current_lateral_min_dist)
if self.current_lateral_min_dist / 60 > 0.5:
lateral_reward = self.current_lateral_min_dist / 60
elif self.current_lateral_min_dist / 60 < 0.4:
lateral_reward = -0.5
else:
lateral_reward = 0.0
# 速度基础
speed_base_reward = self.speed / min(12 + alive_count_total / 100000, 20)
# 速度连续性
if len(self.speed_memory) >= 4:
self.speed_memory = self.speed_memory[1:]
self.speed_memory.append(self.speed)
speed_up_discount = 1.0
if self.speed_memory[-1] - self.speed_memory[0] >= 3 and lateral_reward > 0.0:
speed_up_discount = -0.5
elif self.speed_memory[-1] - self.speed_memory[0] >= 2 and lateral_reward > 0.0:
speed_up_discount = 0.7
# 转角连续性
angle_discount = 1.0
if len(self.angle_memory) >= 5:
self.angle_memory = self.angle_memory[1:]
self.angle_memory.append(self.angle)
aaa = [0] * 4
if len(self.angle_memory) >= 5:
for i in range(1, 5):
aaa[i-1] = self.angle_memory[i] - self.angle_memory[i-1]
bbb = [0] * 3
for j in range(1, 4):
bbb[j-1] = 1 if aaa[j-1] * aaa[j] < 0 else 0
if sum(bbb) >= 3 and lateral_reward > 0.0:
angle_discount = 0.8
# print(lateral_reward, speed_up_discount, angle_discount, " ====== ", self.speed_memory)
return 100 * lateral_reward * speed_up_discount * angle_discount
def rotate_center(self, image, angle):
# Rotate The Rectangle
rectangle = image.get_rect()
rotated_image = pygame.transform.rotate(image, angle)
rotated_rectangle = rectangle.copy()
rotated_rectangle.center = rotated_image.get_rect().center
rotated_image = rotated_image.subsurface(rotated_rectangle).copy()
return rotated_image
def train():
pygame.init()
screen = pygame.display.set_mode((WIDTH, HEIGHT))
game_map = pygame.image.load('map.png').convert() # Convert Speeds Up A Lot
clock = pygame.time.Clock()
num_radar = 17
agent = Agent(gamma=0.99, epsilson=1.0, batch_size=256, n_actions=9,
eps_end=0.1, input_dims=[num_radar + 4], lr=0.005,
max_mem_size=1000000, eps_dec=1e-4)
scores, eps_history = [], []
average_scores = []
distance = []
average_distance = []
alive_counts = []
average_alive_counts = []
n_games = 500
optimal_score_and_episode = [0, 0]
for i in range(n_games):
car = Car([], [], num_radar)
done = False
score = 0
observation = car.get_data()
alive_count = 0
while not done:
action = agent.choose_action(observation)
# [5,0],[2,1],[2,-1],[0,1],[0,0],[0,-1],[-2,1],[-2,-1],[-5,0]
if action == 0:
car.angle += 5
car.speed += 0
elif action == 1:
car.angle += 2
if car.speed < 20:
car.speed += 1
elif action == 2:
car.angle += 2
if car.speed - 1 >= 12:
car.speed -= 1
elif action == 3:
car.angle += 0
if car.speed < 20:
car.speed += 1
elif action == 4:
car.angle += 0
car.speed += 0
elif action == 5:
car.angle += 0
if car.speed - 1 >= 12:
car.speed -= 1
elif action == 6:
car.angle -= 2
if car.speed < 20:
car.speed += 1
elif action == 7:
car.angle -= 2
if car.speed - 1 >= 12:
car.speed -= 1
else:
car.angle -= 5
car.speed += 0
screen.blit(game_map, (0, 0))
car.update(game_map)
car.draw(screen)
pygame.display.flip()
clock.tick(60)
observation_, reward, done = car.get_data(), car.get_reward_optimized(game_map,
agent.mem_cntr), not car.is_alive()
score += reward
agent.store_transition(observation, action, reward, observation_, done)
agent.learn_double_dqp(i)
observation = observation_
alive_count += 1
if score > optimal_score_and_episode[0]:
print("-----optimal_score_and_episode updated form {} to {}.".format(optimal_score_and_episode,
[score, i]))
optimal_score_and_episode = [score, i]
state = {
'eval_state': agent.Q_eval.state_dict(),
'target_state': agent.Q_target.state_dict(),
'eval_optimizer_state': agent.Q_eval.optimizer.state_dict(),
'target_optimizer_state': agent.Q_target.optimizer.state_dict(),
'optimal_score_and_episode': optimal_score_and_episode
}
torch.save(state, f'./dqn_eval.pth')
# TODO:待改进,加载模型创建临时环境让小车随即初始化位置跑若干次,并且跑的时候保留最低的探索率,
# 取score平均值,平均值大的模型保存下来
scores.append(score)
eps_history.append(agent.epsilon)
avg_score = np.mean(scores[-100:])
average_scores.append(avg_score)
distance.append(car.distance)
avg_distance = np.mean(distance[-100:])
average_distance.append(avg_distance)
alive_counts.append(alive_count)
avg_alive_count = np.mean(alive_counts[-100:])
average_alive_counts.append(avg_alive_count)
# 打印当前学习率(调试用)
current_lr = agent.lr_scheduler.get_last_lr()[0]
print(
f'episode: {i}, current_lr: {current_lr}, score= {round(score, 2)}, epsilon= {round(agent.epsilon, 3)},'
f' avg_score= {round(avg_score, 2)}, distance= {round(car.distance)}, loss= {round(agent.loss_value)}, '
f'alive_count= {round(alive_count)}, mem_cntr= {agent.mem_cntr}')
plt.subplot(1, 2, 1)
plt.plot([i for i in range(0, n_games)], average_scores)
plt.title("average_scores")
plt.subplot(1, 2, 2)
plt.plot([i for i in range(0, n_games)], average_distance)
plt.title("average_distance")
plt.show()
if __name__ == '__main__':
train()