一、模型评估
-
准确率(Accuracy):这是最基本的评估指标之一,表示模型在测试集上正确 分类样本的比例。对于分类任务而言,准确率是衡量模型性能的直观标准。
-
损失函数值(Loss):观察模型在测试集上的损失函数值,可以帮助了解模型的 泛化能力。低损失值表明模型在未见过的数据上的表现较好。
-
精确度(Precision):精确度是指所有被模型预测为正类的样本中实际为正类 的比例。它关注的是预测为正类的准确性。
-
召回率(Recall):召回率是指所有实际为正类的样本中被模型正确识别为正类 的比例。它反映了模型识别出所有正类的能力。
-
F1分数(F1 Score):F1分数是精确度和召回率的调和平均值,适用于需要同时 考虑精确度和召回率的情况,特别是在类别分布不均衡时更为有用。
-
混淆矩阵(Confusion Matrix):这是一个表格,展示了分类模型预测结果与 真实标签之间的比较,可以从中计算出精确度、召回率等指标。
-
ROC曲线和AUC值(Receiver Operating Characteristic Curve and Area Under the Curve):ROC曲线通过描绘不同阈值下的真正率(True Positive Rate, TPR)与假正率(False Positive Rate, FPR),来评估二分类模型的性能。 AUC(曲线下面积)是ROC曲线下的面积,其值范围从0到1,AUC值越接近1, 表示模型的分类性能越好。
-
Top-k精度:在多分类任务中,有时会考虑模型预测的前k个最可能类别中是否包 含正确答案,这种情况下会用到Top-k精度作为评估指标。
二、准确率(Accuracy)
这是最基本的评估指标之一,表示模型在测试集上正确分类样本的比例。对于分类任 务而言,准确率是衡量模型性能的直观标准。

特点:
- 直观但受类别不平衡影响大
三、损失函数值(Loss)
模型预测结果与真实标签的差异量化值


四、精确度(Precision)
预测为正类的样本中实际为正类的比例

五、召回率(Recall)
实际为正类的样本中被正确预测的比例

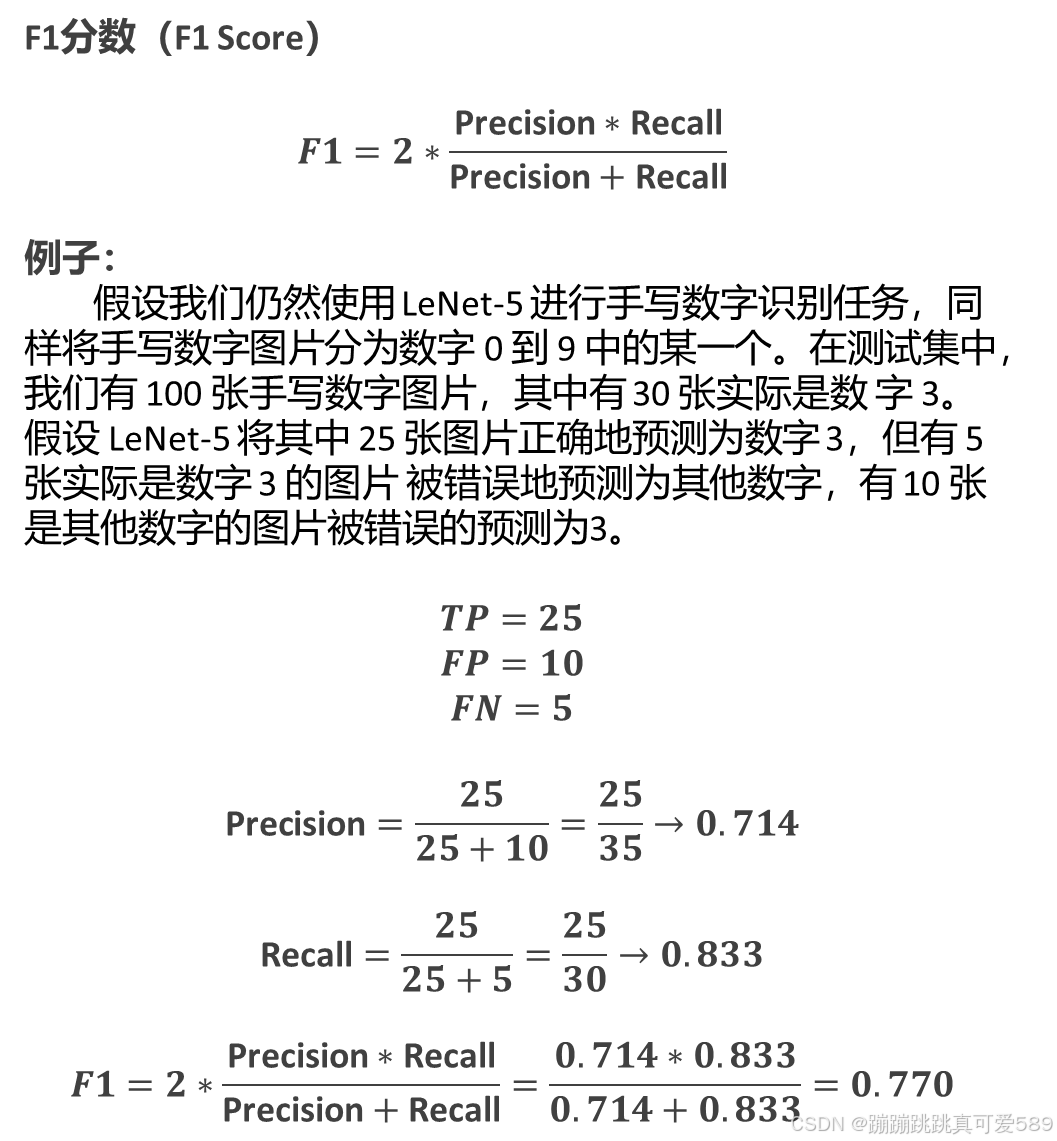
六、F1分数(F1 Score)
F1 分数是精确度(Precision)和召回率(Recall)的调和平均数,它综合考虑了模 型的预测精度和覆盖率。
七、混淆矩阵(Confusion Matrix)
是一个表格,展示了分类模型预测结果与真实标签之间的比较,可以从中计算出精 确度、召回率等指标。
| | 预测类别1 | 预测类别2 |
| 真实类别1 | TP | FN |
| 真实类别2 | FP | TN |
|---|
八、ROC曲线和AUC值
ROC曲线通过描绘不同阈值下的真正率(True Positive Rate, TPR)与假正率(False Positive Rate, FPR),来评估二分类模型的性能。AUC(曲线下面积)是ROC曲线 下的面积,其值范围从0到1,AUC值越接近1,表示模型的分类性能越好。
8.1、ROC曲线
以假正率(FPR)为横轴,真正率(TPR)为纵轴的曲线
8.2、AUC值
ROC曲线下的面积

九、Top-k精度
模型预测概率前k高的类别中包含真实标签的比例

| 指标 | 优点 | 局限性 | 适用场景 |
|---|---|---|---|
| 准确率 | 直观易理解 | 类别不平衡时失效 | 平衡数据集 |
| F1分数 | 平衡精确度与召回率 | 仅关注单一类别(二分类) | 不均衡数据、二分类任务 |
| AUC | 不受阈值影响 | 仅适用于二分类 | 类别不平衡的二分类任务 |
| Top-k精度 | 容错性强 | 计算复杂度高 | 细粒度分类任务 |
python
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, roc_auc_score, top_k_accuracy_score
# 真实标签与预测结果
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
y_proba = [[0.7, 0.2, 0.1],
[0.1, 0.3, 0.6],
[0.3, 0.4, 0.3],
[0.8, 0.1, 0.1],
[0.6, 0.2, 0.2],
[0.2, 0.5, 0.3]]
# 计算各项指标
print("准确率:", accuracy_score(y_true, y_pred))
print("精确度(宏平均):", precision_score(y_true, y_pred, average='macro'))
print("召回率(宏平均):", recall_score(y_true, y_pred, average='macro'))
print("F1分数(宏平均):", f1_score(y_true, y_pred, average='macro'))
print("混淆矩阵:\n", confusion_matrix(y_true, y_pred))
print("Top-2精度:", top_k_accuracy_score(y_true, y_proba, k=2))
# 二分类场景下的AUC计算示例
y_true_binary = [0, 1, 1, 0]
y_proba_binary = [0.1, 0.9, 0.8, 0.3]
print("AUC值:", roc_auc_score(y_true_binary, y_proba_binary))