一、概述
LightGBM 由微软公司开发,是基于梯度提升框架的高效机器学习算法,属于集成学习中提升树家族的一员。它以决策树为基学习器,通过迭代地训练一系列决策树,不断纠正前一棵树的预测误差,逐步提升模型的预测精度,最终将这些决策树的结果进行整合,输出最终的预测结果。
二、算法原理
1.训练过程
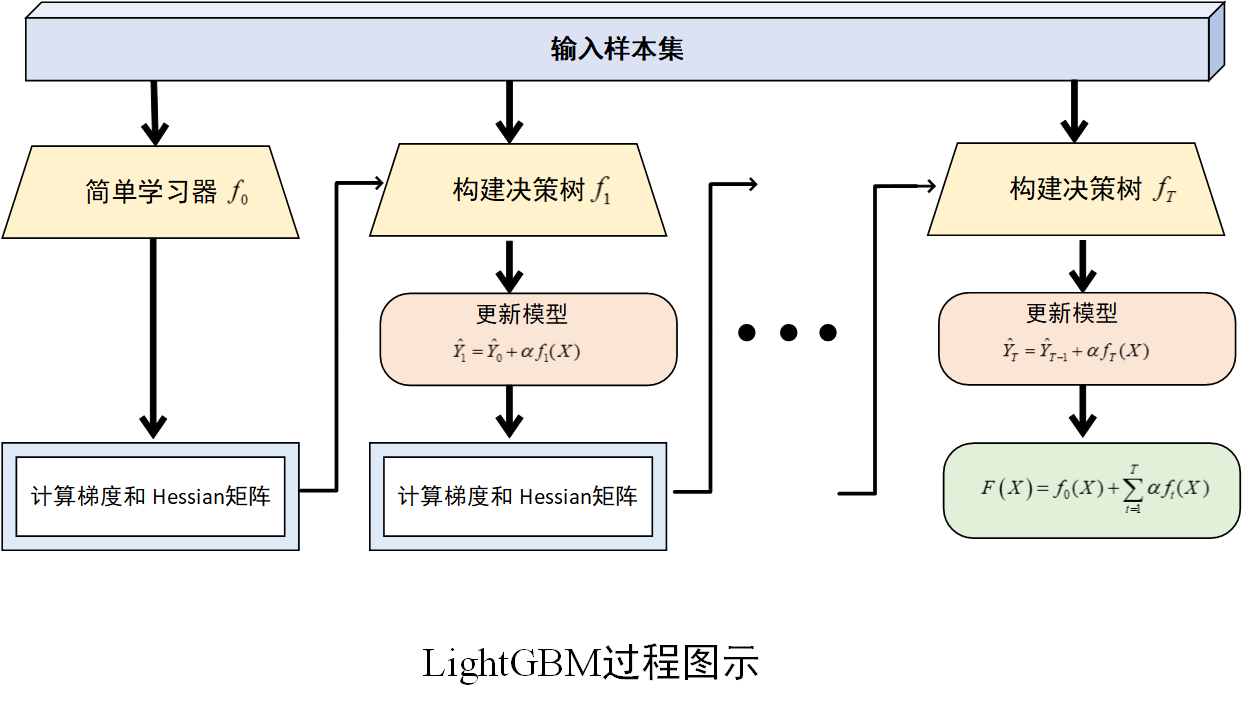
(1) 初始化模型
首先,初始化一个简单的模型,通常是一个常数模型,记为\(f_0(X)\),其预测值为所有样本真实值的均值(回归任务)或多数类(分类任务),记为\(\hat y_0\)。此时,模型的预测结果与真实值之间存在误差。
(2) 计算梯度和 Hessian矩阵
对于每个样本,计算损失函数关于当前模型预测值的梯度和 Hessian 矩阵(二阶导数),用以确定模型需要调整的方向和幅度。例如,在均方误差损失函数下,梯度就是预测值与真实值之间的差值。
(3) 构建决策树
基于计算得到的梯度和 Hessian,构建一棵新的决策树,使用直方图算法等优化技术来加速决策树的构建过程。分裂节点的依据是最大化信息增益或最小化损失函数的减少量。同时,为了防止过拟合,应用一些剪枝策略,如限制树的深度、叶子节点的最小样本数等。
(4) 更新模型
根据新训练的决策树,更新当前模型。更新公式为
\\\hat Y_1 = \\hat Y_0 + \\alpha f_1(X) \\
,也就是将新决策树的输出乘以学习率,加到当前模型的预测值上。其中学习率 (也称为步长),用于控制每棵树对模型更新的贡献程度。学习率较小可以使模型训练更加稳定,但需要更多的迭代次数;学习率较大则可能导致模型收敛过快,甚至无法收敛。
(5) 重复迭代
重复步骤 (2)--(4)步,不断训练新的决策树并更新模型,直到达到预设的迭代次数、损失函数收敛到一定程度或满足其他停止条件为止。最终,LightGBM 模型由多棵决策树组成,其预测结果是所有决策树预测结果的累加。
算法过程图示
2. 直方图算法
LightGBM 采用了直方图算法来加速决策树的构建过程。传统的决策树算法在寻找最佳分裂点时,需要遍历所有的特征值,计算量巨大。而 LightGBM 将连续的特征值离散化成 k 个桶(bin),构建一个宽度为 k 的直方图。在寻找最佳分裂点时,只需遍历直方图中的 k 个值,大大减少了计算量,提高了算法的训练速度。
3. 单边梯度采样(GOSS)
数据集中存在大量梯度较小的样本,这些样本对模型的提升作用较小,但在计算梯度时却占用了大量的计算资源。单边梯度采样(GOSS)根据样本的梯度大小对样本进行采样,保留梯度较大的样本,并对梯度较小的样本进行随机采样,在不影响模型精度的前提下,减少了训练数据量,提高了训练效率。
4. 互斥特征捆绑(EFB)
在实际数据中,许多特征是相互关联的,存在大量的稀疏特征。互斥特征捆绑(EFB)算法将互斥的特征捆绑在一起,形成一个新的特征,从而减少特征的数量。这样在构建决策树时,就可以减少计算量,提高算法的运行效率。
三、算法优势
1.训练速度快
得益于直方图算法、GOSS 和 EFB 等技术,LightGBM 在处理大规模数据时,训练速度相比传统的梯度提升算法有显著提升。无论是处理小数据集还是大数据集,都能在较短时间内完成模型训练。
2.内存占用少
通过直方图算法和特征捆绑等技术,LightGBM 有效减少了数据存储和计算过程中的内存占用。这使得它可以在资源有限的环境下运行,如在个人计算机上处理大规模数据,或者在内存受限的服务器上同时运行多个模型训练任务。
3.可扩展性强
LightGBM 支持分布式训练,可以充分利用多台计算机的计算资源,加快训练速度。它还支持并行学习,能够同时处理多个特征,进一步提高训练效率。这种强大的可扩展性使得它能够适应各种规模和复杂度的机器学习任务。
4.准确率高
尽管 LightGBM 在训练过程中采用了多种优化技术来提高效率,但它并没有牺牲模型的准确率。在许多实际应用和机器学习竞赛中,LightGBM 都能取得与其他先进算法相当甚至更优的预测结果。
5.支持多种数据类型和任务
LightGBM 不仅支持常见的数值型和类别型数据,还能处理稀疏数据。同时,它广泛应用于回归、分类、排序等多种机器学习任务,具有很强的通用性。
四、Python实现
(Python 3.11,scikit-learn 1.6.1)
分类情形
python
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
import lightgbm as lgbm
from sklearn import metrics
# 生成数据集
X, y = make_classification(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建lightGBM分类模型
clf = lgbm.LGBMClassifier(verbosity=-1)
# 训练模型
rclf = clf.fit(X_train, y_train)
# 预测
y_pre = rclf.predict(X_test)
# 性能评价
accuracy = metrics.accuracy_score(y_test,y_pre)
print('预测结果为:',y_pre)
print('准确率为:',accuracy)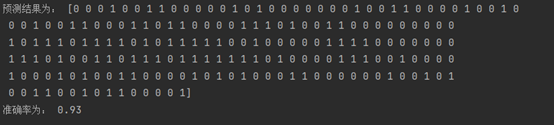
回归情形
python
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
import lightgbm as lgbm
from sklearn.metrics import mean_squared_error
# 生成回归数据集
X, y = make_regression(n_samples = 1000, n_features = 6, random_state = 42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
# 创建lightGBM回归模型
model = lgbm.LGBMRegressor(verbosity=-1)
# 训练模型
model.fit(X_train, y_train)
# 进行预测
y_pred = model.predict(X_test)
# 计算均方误差评估模型性能
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse}")
End.