在MapReduce框架中,分区器(Partitioner)是一个关键组件,其主要作用是决定由一个maptask生成的键值,最终是生成在哪个文件中的。
默认的分区器是HashPartitioner,它会根据键的哈希值将数据均匀分配到各个Reducer中。如果键的分布较为均匀,这种方式可以实现较好的负载均衡。
自定义分区器:如果使用自定义分区器,可以根据特定的逻辑(如键的首字母、键的范围等)将数据分配到不同的Reducer中。
1.定义一个分区类。继承Partitioner类。
2.重写getPartition方法,它会返回一个整型的结果。结果相同的key对应的数据就会放在一个文件中。

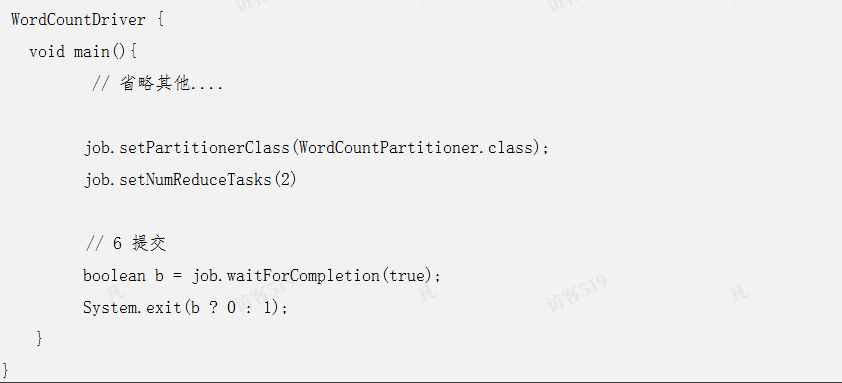
上一步我们定义了分区器,接下来,我们在job中使用它。需要改动的代码就是在Driver类中,添加一句setPartitionerClass,代码如下: