中科院开源:多智能体 + 知识图谱,自动生成高质量医学数据
- 论文大纲
- 理解
- [问1:m-KAILIN 方法的总体目标是什么?](#问1:m-KAILIN 方法的总体目标是什么?)
- 问2:为什么要自动生成训练数据,而不是直接用公开的生物医学数据集?
- 问3:它是怎么拆分任务来完成数据生成的?
- [问4:先看看「问题生成智能体」(QG Agent),它具体做什么?](#问4:先看看「问题生成智能体」(QG Agent),它具体做什么?)
- 问5:生成了问题后,如何找到合适的上下文来回答这些问题?
- 问6:那如果对于同一篇文献,模型可能生成好几个问题,怎么判断谁好谁差?
- [问7:具体怎么用 MeSH 来判断质量?](#问7:具体怎么用 MeSH 来判断质量?)
- [问8:选出了最优 (问题, 上下文) 后,答案怎么来?](#问8:选出了最优 (问题, 上下文) 后,答案怎么来?)
- 问9:这样就能得到成千上万的"问答对"了吗?
- 问10:最后用这些自动生成的数据去训练大模型,效果如何?
- 全流程
- 解法拆解:聚焦"方法"与"特征"对应
- [子解法 A:多智能体协作机制](#子解法 A:多智能体协作机制)
- [1. 之所以用"多智能体协作",是因为:](#1. 之所以用“多智能体协作”,是因为:)
- [2. 方法原理与思路:](#2. 方法原理与思路:)
- [3. 与同类算法的主要区别:](#3. 与同类算法的主要区别:)
- [子解法 B:基于医学知识层次(如 MeSH)的评估策略](#子解法 B:基于医学知识层次(如 MeSH)的评估策略)
- [1. 之所以用"知识层次评估",是因为:](#1. 之所以用“知识层次评估”,是因为:)
- [2. 方法原理与思路:](#2. 方法原理与思路:)
- [3. 与同类算法的主要区别:](#3. 与同类算法的主要区别:)
- [子解法 C:自动化偏好学习/质量提升](#子解法 C:自动化偏好学习/质量提升)
- [1. 之所以用"偏好学习(DPO等)"来优化质量,是因为:](#1. 之所以用“偏好学习(DPO等)”来优化质量,是因为:)
- [2. 方法原理与思路:](#2. 方法原理与思路:)
- [3. 与同类算法的主要区别:](#3. 与同类算法的主要区别:)
- [子解法 D:检索与语料构建的领域适配](#子解法 D:检索与语料构建的领域适配)
- [1. 之所以"检索+构建大规模语料"特别强调领域适配,是因为:](#1. 之所以“检索+构建大规模语料”特别强调领域适配,是因为:)
- [2. 方法原理与思路:](#2. 方法原理与思路:)
- [3. 与同类算法的主要区别:](#3. 与同类算法的主要区别:)
- 子解法之间的组合关系
- 是否存在隐性方法或特征?
- 提问
- [1. 为什么"多Agent协同"比"单Agent"更可取?](#1. 为什么“多Agent协同”比“单Agent”更可取?)
- [2. 若仅靠一个强大的大模型(如GPT-4)生成生物医学QA数据,为什么还需要 MeSH 规则来"评估"?](#2. 若仅靠一个强大的大模型(如GPT-4)生成生物医学QA数据,为什么还需要 MeSH 规则来“评估”?)
- [3. 论文中的"冷启动规则"是如何保证自身的可信度?毕竟它也需要人为设计?](#3. 论文中的“冷启动规则”是如何保证自身的可信度?毕竟它也需要人为设计?)
- [4. 在多Agent的体系下,若各Agent产生冲突,如何处理不同Agent之间的决策不一致?](#4. 在多Agent的体系下,若各Agent产生冲突,如何处理不同Agent之间的决策不一致?)
- [5. 对于 PubMed 文献规模庞大(数千万篇)而言,Context Retrieval Agent 的检索效率会不会成为瓶颈?](#5. 对于 PubMed 文献规模庞大(数千万篇)而言,Context Retrieval Agent 的检索效率会不会成为瓶颈?)
- [6. 论文提及"规模越大"意味着性能越好,但数据噪声也会相应上升;如何平衡数据规模和噪声?](#6. 论文提及“规模越大”意味着性能越好,但数据噪声也会相应上升;如何平衡数据规模和噪声?)
- [7. 假设问题极度复杂(如临床诊断需要图像、基因组信息等多模态),m-KAILIN 的文本范式能否兼容?](#7. 假设问题极度复杂(如临床诊断需要图像、基因组信息等多模态),m-KAILIN 的文本范式能否兼容?)
- [8. Evaluation Agent 为什么要先用"基于 MeSH 的冷启动规则"再训练"LLM 评估器"?能不能直接让 LLM 来打分?](#8. Evaluation Agent 为什么要先用“基于 MeSH 的冷启动规则”再训练“LLM 评估器”?能不能直接让 LLM 来打分?)
- [9. 训练生成Agent时,为何还要引入 DPO(Direct Preference Optimization) 这种偏好学习方式?](#9. 训练生成Agent时,为何还要引入 DPO(Direct Preference Optimization) 这种偏好学习方式?)
- [10. 如果把所有文献都扔给模型让它自己生成问答,再由 Evaluation Agent去评判,和当前的多步骤有什么不同?](#10. 如果把所有文献都扔给模型让它自己生成问答,再由 Evaluation Agent去评判,和当前的多步骤有什么不同?)
- [11. m-KAILIN 中为什么不直接将 BioASQ(或其他已有 QA 数据)全部并入最终的大规模数据,而要"再生"问题?](#11. m-KAILIN 中为什么不直接将 BioASQ(或其他已有 QA 数据)全部并入最终的大规模数据,而要“再生”问题?)
- [12. 如果同一篇文献多Agent各自生成的问题之间非常相似,是否会出现重复数据?](#12. 如果同一篇文献多Agent各自生成的问题之间非常相似,是否会出现重复数据?)
- [13. m-KAILIN 主要评测基准集中在 PubMedQA,为什么不使用更多的临床或放射学等更具挑战的数据集?](#13. m-KAILIN 主要评测基准集中在 PubMedQA,为什么不使用更多的临床或放射学等更具挑战的数据集?)
- [14. 多Agent体系是否会带来累计误差?例如检索Agent选错文献,上层Agent就白忙了?](#14. 多Agent体系是否会带来累计误差?例如检索Agent选错文献,上层Agent就白忙了?)
- [15. 为什么仅用信息含量(IC)和 LCA 计算方式来衡量 MeSH 术语相似度?这会不会太过简化?](#15. 为什么仅用信息含量(IC)和 LCA 计算方式来衡量 MeSH 术语相似度?这会不会太过简化?)
- [16. 如果问句本身是错误假设或带有误导,比如问"维生素C能治愈所有癌症吗"?多Agent会怎样处理?](#16. 如果问句本身是错误假设或带有误导,比如问“维生素C能治愈所有癌症吗”?多Agent会怎样处理?)
- [17. 与 KAILIN 相比,m-KAILIN 声称"多Agent",那是否意味着计算资源需求更高?](#17. 与 KAILIN 相比,m-KAILIN 声称“多Agent”,那是否意味着计算资源需求更高?)
- [18. DPO(Direct Preference Optimization) 使用的温度参数 β 是如何确定的?过高或过低会怎样?](#18. DPO(Direct Preference Optimization) 使用的温度参数 β 是如何确定的?过高或过低会怎样?)
- [19. 为什么论文要做"时间维度"和"子学科维度"的鲁棒性测试?](#19. 为什么论文要做“时间维度”和“子学科维度”的鲁棒性测试?)
- [20. 若去除了 MeSH 评估或去除了域向量检索,最终性能为何显著下降?是哪些细节环节导致的?](#20. 若去除了 MeSH 评估或去除了域向量检索,最终性能为何显著下降?是哪些细节环节导致的?)
论文大纲
c
├── 1 引言【阐述研究动机与背景】
│ ├── 大型语言模型在生物医学领域的应用潜力【背景介绍】
│ ├── 现存开源生物医学数据规模和质量不足【问题描述】
│ └── 研究目标:提出多Agent的知识驱动语料萃取框架【研究目标】
│
├── 2 相关工作【文献与方法综述】
│ ├── 现有生物医学语料构建方法【方法回顾】
│ │ ├── 规则驱动的数据清洗【局限:可扩展性不足】
│ │ ├── 知识图谱构建【局限:依赖人工校对】
│ │ └── 合成数据生成【局限:缺乏多视角与协同】
│ └── m-KAILIN与现有方法的区别【差异性说明】
│ ├── 多Agent协同且自动化程度更高【创新点】
│ └── 基于MeSH层次结构进行知识约束与评估【创新点】
│
├── 3 m-KAILIN方法【核心框架与技术路径】
│ ├── 多Agent知识驱动架构【整体框架】
│ │ ├── Question Generation Agent【负责:从文本生成问题】
│ │ │ ├── 在BioASQ上微调以适应生物医学问句风格【技术细节】
│ │ │ └── 与域模型/通用模型结合以提升多样性【关键策略】
│ │ ├── Context Retrieval Agent【负责:检索相关文献上下文】
│ │ │ ├── 基于Dense Passage Retrieval进行向量检索【方法介绍】
│ │ │ └── 采用领域词向量模型以提升检索精准度【Domain Adaptation】
│ │ ├── Question Evaluation Agent【负责:对候选问句进行优选】
│ │ │ ├── 以MeSH层级知识为约束,进行冷启动规则打分【规则基础】
│ │ │ └── 训练LLM作为自动评估器,预测问句偏好【自动化评估】
│ │ └── Answer Generation Agent【负责:回答问句】
│ │ └── 利用GPT-4或其他大模型,生成高质量回答【答案生成】
│ │
│ └── 多Agent协同与数据构建【协作机制】
│ ├── 建立偏好数据集与理想数据集【数据类型】
│ │ ├── 偏好数据集:同一文献生成的两种问句对比【q+与q-】
│ │ └── 理想数据集:最终最佳问句+上下文+答案【三元组】
│ ├── 直接偏好优化 (DPO)微调问句生成Agent【优化问句质量】
│ └── 分阶段训练目标模型:继续预训练(CPT)再监督微调(SFT)【目标模型增强】
│
├── 4 实验与结果【定量评估与分析】
│ ├── 不同规模模型在PubMedQA上的性能表现【主要实验】
│ │ ├── 小规模模型(<13B参数)与大规模模型(≥70B参数)结果【横向比较】
│ │ └── 在QA准确率方面优于已有开源与商用生物医学LLM【核心结论】
│ ├── 数据规模对性能的影响【Scaling Law】
│ │ └── 更大规模的自动萃取语料可进一步提高模型表现【发现】
│ ├── 组件消融研究【组件贡献度】
│ │ ├── 去除MeSH知识评估后性能下降【验证知识层级重要性】
│ │ └── 去除域向量检索后上下文匹配度变差【验证检索适配度】
│ └── 鲜例分析和鲁棒性测试【实验细节】
│ ├── 不同时间段文献的适应性【时序鲁棒性】
│ └── 不同子领域(子学科)文献的适应性【子领域鲁棒性】
│
└── 5 结论与未来展望【总结与展望】
├── m-KAILIN显著提高生物医学LLM的训练效率与质量【研究贡献】
├── 多Agent协同和层级知识约束是关键【核心启示】
└── 未来工作:扩展更多生物医学子领域、多语种及更大规模验证【后续研究方向】核心方法:
c
├── 1 核心方法概览【整体框架】
│ ├── 输入:大规模生物医学文献(如PubMed)+有限开源QA数据(如BioASQ)+MeSH层次结构【数据来源】
│ ├── 处理过程:多Agent协同,包括问题生成、检索、评估、答案生成四大Agent【方法总览】
│ └── 输出:面向生物医学QA任务的高质量"问题-上下文-答案"语料【主要产出】
│
├── 2 Question Generation Agent【Agent1:生成问题】
│ ├── 步骤A:在BioASQ等开源QA数据上微调【Fine-tuning技术】
│ │ ├── 输入:预训练LLM(如BioMistral或LLaMA等)+ BioASQ训练集【训练数据】
│ │ ├── 方法/技术:最小化交叉熵损失,学到从文档到问句的映射【监督微调】
│ │ └── 输出:可生成生物医学领域问题的模型 θ【特化模型】
│ └── 步骤B:对大规模生物医学文档生成候选问题【推理阶段】
│ ├── 输入:大规模领域文献 & 已微调的模型 θ【推理输入】
│ ├── 方法/技术:令模型对每篇文献输出问题q=argmax Pθ(q|d)【语言模型解码】
│ └── 输出:候选问题集【后续Agent使用】
│
├── 3 Context Retrieval Agent【Agent2:检索上下文】
│ ├── 输入:候选问题(来自Question Generation Agent)【需求触发】
│ ├── 方法/技术:Dense Passage Retrieval (DPR),基于BiomedBERT向量检索【RAG范式】
│ │ ├── 把问题与文献切片做向量化匹配【Embedding匹配】
│ │ └── 筛选Top-k最相关文献片段作为上下文【Top-k检索】
│ └── 输出:候选问题-上下文对(q, c)【后续Agent评估】
│
├── 4 Question Evaluation Agent【Agent3:评估问句质量与选择】
│ ├── 步骤A:基于MeSH的规则冷启动【知识引导打分】
│ │ ├── 输入:文献d + 来自不同问句生成器的(q1, c1)和(q2, c2)【对比评估场景】
│ │ ├── 方法/技术:计算与MeSH层级的相似度,自动打分确定偏好yi【冷启动标注】
│ │ └── 输出:大规模偏好标签数据集【为后续自动评估器训练提供监督】
│ ├── 步骤B:训练LLM作为自动评估器【偏好学习】
│ │ ├── 输入:上一步输出的偏好标签数据集 + 预训练LLM【训练数据】
│ │ ├── 方法/技术:最小化负对数似然损失,令模型预测正确偏好【Preference Learning】
│ │ └── 输出:Evaluation Agent ϕ,可自动判断哪对(q,c)更优【自动评估模型】
│ └── 输出:针对同一文献的多个(q,c)对,择优输出最优问题-上下文组合【优选结果】
│
├── 5 Answer Generation Agent【Agent4:生成答案】
│ ├── 输入:经评估选出的(q*, c*)【最佳问题-上下文】
│ ├── 方法/技术:GPT-4或其它高级LLM推理【答案生成】
│ └── 输出:最终三元组(q, c, a)【构建高质量QA样本】
│
├── 6 Multi-Agent Collaborative Framework【多Agent协同管线】
│ ├── 步骤1:初始化两种不同的Question Generation Agent【Distinct vs. Same】
│ │ ├── 输入:通用LLM & 域LLM,各自在QA数据上微调【多样化问句来源】
│ │ └── 目的:提升问句多样性和覆盖面【协同增益】
│ ├── 步骤2:构建偏好数据集P【Preference Dataset】
│ │ ├── 输入:对同一文献生成的q+和q-,由Evaluation Agent判断优劣【数据收集】
│ │ └── 输出:包含(q+, q-)的偏好样本,用于后续优化【偏好监督】
│ ├── 步骤3:直接偏好优化(DPO)【问句生成Agent再精调】
│ │ ├── 输入:偏好数据集P + 通用LLM【目标微调对象】
│ │ ├── 方法/技术:DPO公式,最大化生成q+的概率并最小化q-【倾向优选问句】
│ │ └── 输出:优化后的生成Agent θ*【持续改进问句质量】
│ ├── 步骤4:构建理想数据集【最终训练语料】
│ │ ├── 连续预训练(CPT)用:只含(q, c)对【强化上下文理解】
│ │ └── 监督微调(SFT)用:含(q, c, a)三元组【问答明确】
│ └── 输出:可供目标LLM使用的AI-Ready生物医学QA语料【核心产物】
│
└── 7 Training for Downstream Tasks【面向生物医学QA的最终训练】
├── 连续预训练(基于Icpt)【CPT阶段】
│ ├── 输入:大规模(q, c)对【模型适配领域问句风格】
│ └── 输出:掌握更多领域上下文知识的目标模型【语言建模强化】
└── 监督微调(基于Isft)【SFT阶段】
├── 输入:融合(q, c, a)三元组【明确定义QA目标】
└── 输出:面向生物医学QA最终模型【提供准确答案能力】理解
问1:m-KAILIN 方法的总体目标是什么?
论文提出目前的生物医学开源数据集(如 BioASQ、PubMedQA)数量和覆盖度不足,难以支持大型语言模型的全面训练。
大量文献(如 PubMed 超过 2300 万篇)却没有现成的问答标注,无法直接用来训练问答模型。
作者的思维过程(观察 / 思考方式):
-
作者关注到了"不足"和"剩余"的对比:有限标注数据 vs. 丰富的原始文献。
-
他们敏锐地发现,缺乏"问答对"是瓶颈,但文献资源极其丰富。
这背后体现了一个典型的"变量"对比思路:人力标注无法大规模扩张,而文献海量。
若能把后者转换成有用的数据,即可突破瓶颈。
多个Agent从不同角度(生成/检索/评价)互相校正和筛选,能比单一大模型更能覆盖多样化专业概念,并减少噪音。
所有的Agent设计、偏好优化等,都是为了解决生物医学文本生成中"无人工标注却要质量可靠"这个最根本矛盾;多Agent只是实现路径之一,真正核心是自动且有效的质控。
问2:为什么要自动生成训练数据,而不是直接用公开的生物医学数据集?
答2 :公开的数据集(如BioASQ、PubMedQA)虽然质量高,但规模和覆盖面都比较有限;而真实生物医学文献海量却缺乏直接的"问答"标注。
m-KAILIN 通过自动生成问答数据,可以大幅扩充规模并覆盖更多医学子领域。
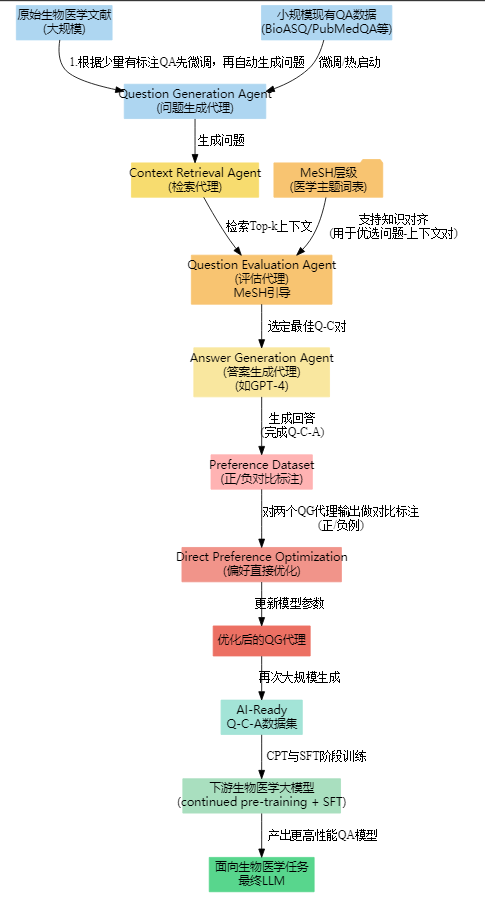
问3:它是怎么拆分任务来完成数据生成的?
答3 :m-KAILIN 使用了一个 多智能体(multi-agent) 的协作框架,大致分为四个核心智能体(Agent):
- 问题生成智能体 (Question Generation Agent)
- 文本检索智能体 (Context Retrieval Agent)
- 问题质量评估智能体 (Question Evaluation Agent)
- 答案生成智能体 (Answer Generation Agent)
它们各司其职,互相配合,一步一步地把文献"变"成问答形式的数据。
问4:先看看「问题生成智能体」(QG Agent),它具体做什么?
答4:
- 先拿到一个初始"小数据集"(如 BioASQ 的标注问答),微调出一个能"提出医学问题"的模型。
- 这个微调后的 QG Agent 会对海量生物医学文献逐篇生成候选问题。
- 类似"从论文/摘要中自动生成一个可能的研究问题",形成「(问题, 原文)」对。
这样就初步把原始文献"转"成了"带问题的文档"。
问5:生成了问题后,如何找到合适的上下文来回答这些问题?
答5:
- m-KAILIN 设计了文本检索智能体 (Context Retrieval Agent)。
- 它用一个"密集向量检索"工具(Dense Passage Retrieval, DPR),先把问题向量化,再把大规模文献也向量化,选出与问题最相关的文档或段落(Top-k)。
- 这样,就拿到「(生成的问题, 对应检索到的上下文)」------确保后面回答时有可参照的文献依据。
问6:那如果对于同一篇文献,模型可能生成好几个问题,怎么判断谁好谁差?
答6:
- 这就是**问题质量评估智能体 (Question Evaluation Agent)**的功能。
- 它会"比较"同一个来源文献生成的多个 (问题 + 上下文) 组合,根据MeSH 医学主题词层次结构的匹配度、信息覆盖度等标准,给出偏好选择:哪个问题更贴近文献主旨、更符合医学领域知识。
- 最后只保留评价更高的 (问题, 上下文)。
问7:具体怎么用 MeSH 来判断质量?
答7:
- MeSH(Medical Subject Headings)是一个多层级的医学主题词体系。
- 评估智能体会把文献和问题、上下文里的医学概念映射到 MeSH 结构中,比较它们的相似度和层级关系(比如共同祖先节点)。
- 分数更高者就是被 MeSH 视为"更符合该文献主题、或在医学概念上更一致"的 (问题, 上下文) 组合。
问8:选出了最优 (问题, 上下文) 后,答案怎么来?
答8:
- 会调用一个答案生成智能体 (Answer Generation Agent),常用的是 GPT-4 或其他强大 LLM,输入就是"问题 + 上下文"。
- 这个智能体会输出一个比较靠谱的医学回答,形成「(问题, 上下文, 答案)」。
问9:这样就能得到成千上万的"问答对"了吗?
答9:对。流程概括:
- QG Agent:给文献生成问题
- Retrieval Agent:检索相关段落
- Evaluation Agent:比较质量、保留最优
- Answer Agent:用大模型作答
最终得到大量高质量「问题-上下文-答案」三元组,堆起来就成了训练/微调用的大规模问答数据集。
问10:最后用这些自动生成的数据去训练大模型,效果如何?
答10:
- 论文实验证明,用 m-KAILIN 生成的数据给生物医学大模型做连续预训练 (CPT) 或监督微调 (SFT),模型在各种医学 QA 任务上精度显著提升。
- 甚至在一些场景下,小参数模型也能和更大规模的商用模型接近或超越。
总结 :
m-KAILIN 的 核心思路 是:
- 把海量医学文献先"提取+转换"成问答格式(QG + Retrieval + Evaluation),
- 再用先进 LLM 去"填"答案,
- 最终持续迭代生成一个规模庞大、质量高的生物医学问答训练集。
通过多智能体协作,尤其借助 MeSH 层次结构来评估问题质量,m-KAILIN 能 大幅减少人工标注,且保证"问答数据"在专业性和覆盖度上的优良表现。这样就实现了论文中所说的高质量数据生成流程。
全流程
解法拆解:聚焦"方法"与"特征"对应
- 子解法 A:多智能体协作机制
- 子解法 B:基于医学知识层次(如 MeSH)的评估策略
- 子解法 C:自动化偏好学习/质量提升
- 子解法 D:检索与语料构建的领域适配
子解法 A:多智能体协作机制
1. 之所以用"多智能体协作",是因为:
-
特征:生物医学问答生成包含多个截然不同的任务环节(生成问题、检索文献、评估质量、生成答案),每个环节需要不同能力或专业性。
-
难点:如果只用一个"大而全"的模型来处理所有环节,会导致关注点分散、难以保证高质量;更何况,每个任务环节的需求不尽相同。
2. 方法原理与思路:
- 将任务拆分给多个专职智能体 ,每个智能体都有自己的微调模型或规则:
- 例如,一个智能体专门"生成问题"、另一个"评估问题质量"、另一个"回答"等。
- 这些智能体通过数据接口 或提示(prompt) 进行信息流转,形成一个协作网络/体系。
3. 与同类算法的主要区别:
- 有些 做法会将"问答生成"看成一个单一端到端的大模型流程,但 m-KAILIN 刻意拆分成多智能体;
- 好处:可针对各环节做单独优化(如问题生成专门用 BioASQ 微调),并且如果其中一个Agent失效,整体可替换或升级,而不影响其他部分。
子解法 B:基于医学知识层次(如 MeSH)的评估策略
1. 之所以用"知识层次评估",是因为:
- 特征 :医学领域概念庞大且层级化(如 MeSH 结构),文本里常包含专业术语;一个"好问题"必须与文献核心主题相匹配。
- 难点:简单的关键词或语义相似,难以区分"是否真正契合医学主题"。
2. 方法原理与思路:
- 通过 MeSH 结构 (或类似医学本体)的层级关系,来判断问题和文献上下文在专业概念上的一致度。
- 如果某个问题偏离文献主题或只是在表面相似,则在知识层次上匹配度低;如果恰好落在文献核心概念所在的层级,则被视为高质量。
3. 与同类算法的主要区别:
- 一般的问答系统可能只做 embedding 相似度 ,不一定会将医学知识本体显式引入对比。
- 这样就使 m-KAILIN 更具"医疗专业性",而非仅仅依靠语言表层相似度。
子解法 C:自动化偏好学习/质量提升
1. 之所以用"偏好学习(DPO等)"来优化质量,是因为:
- 特征 :即使有了多智能体和 MeSH,模型仍会产生许多质量不一的问题和答案;光靠离线规则挑选还不够。
- 难点:大规模数据自动生成时,需要持续改进生成质量,不可能依赖人工逐例纠正。
2. 方法原理与思路:
- 通过对比好的问答与差的问答,模型学会**"哪个更优"**。
- 或者把评估代理判定的"好/坏"结果**反馈回"问题生成"**或"答案生成"阶段,形成一种"人类偏好"风格的自动优化流程(如 DPO:Direct Preference Optimization)。
3. 与同类算法的主要区别:
- 一些问答生成方法不做二次回馈,只是一锤子买卖:先生成,后评估就完了;
- m-KAILIN 则希望评估结果能反哺到生成流程,进而逐步提升整体数据质量。
子解法 D:检索与语料构建的领域适配
1. 之所以"检索+构建大规模语料"特别强调领域适配,是因为:
- 特征:生物医学文献庞大(数千万篇),检索环节若不做专业适配(术语、同义词),很可能检索不到关键段落或检索噪声很高。
- 难点:通用检索方法往往只识别常用词语,而缺少对医学专业术语、缩写、别名的深度解析。
2. 方法原理与思路:
- 典型做法:微调或设定"医学专门版"检索模型(如专门针对 PubMed 数据优化的向量检索),并在检索前进行文献分段、去重、同义词融合等处理。
- 让检索出的段落更贴合医学背景,再与问题配对生成高质量上下文。
3. 与同类算法的主要区别:
- 一般性的问答系统只用通用搜索引擎或通用向量模型;
- m-KAILIN 特别关注领域化(可能使用生物医学专属预训练embedding/语料),更能匹配科学论文的风格与术语。
子解法之间的组合关系
- 多智能体协作(A) 是一种顶层架构,把其它子解法整合进来,每个子解法可能由一个 Agent 来执行。
- 知识层次评估(B) 通常在评估 Agent 中使用,但也能指导问题生成或检索的过滤环节。
- 偏好学习© 则是不断对"生成问题或回答"的质量进行反馈回路,与 (A) 的多智能体互相配合。
- 检索领域化(D) 多是与 (B) 或 (A) 相配合,保证上下文文献的可靠来源。
可以把它们想象成:
- (A) 多智能体 协作 = "组织结构"
- (B) 知识层次评估 = "专业评估准则"
- © 偏好学习 = "动态改进机制"
- (D) 领域化检索 = "数据获取支撑"
它们相互支撑,构成了 m-KAILIN 的方法体系。
是否存在隐性方法或特征?
- 文献分段策略
- 不同方式切分文献(按句子、按段落、或按主题)会极大影响检索效果,但论文可能只简单提到,这往往是个"隐性关键点"。
- 多语言或跨领域适配
- 如果 PubMed 文献中有其他语言或跨学科的文本,需要额外的分词与处理。论文可能没大篇幅说明,但在实际实现中不可或缺。
- 评估Agent如何具体落地
- 论文中通常只说"利用 MeSH 评估",但背后可能还有一系列对术语的解析、打分策略以及与大语言模型对答案正确性对比,这部分常被含糊处理,也属于隐性关键步骤。
这些点都可能需要在真正的系统里额外定义或实现,属于"论文未大书特书但非常影响效果"的地方。
提问
1. 为什么"多Agent协同"比"单Agent"更可取?
回答:
单Agent模式在生成生物医学问答数据时存在视角单一、难以涵盖多样化文献观点等问题。
而多Agent则将不同专业侧重(如通用模型 vs. 域模型)、不同功能(问题生成、检索、评估、回答)拆分开,使各Agent从不同角度进行互补和交叉校验。
这样的协同有助于提高生成数据的覆盖度和质量,从而更有效地满足生物医学问答需求。
2. 若仅靠一个强大的大模型(如GPT-4)生成生物医学QA数据,为什么还需要 MeSH 规则来"评估"?
回答:
GPT-4 等强大模型虽具备通用语言理解与生成能力,但对专业领域的"精确性"与"层次性"未必达到最佳;
MeSH(医学主题词)能从领域知识结构出发,对问答对齐度进行专业度评估。
即便是强模型,也可能在专业细节上产生错误或不合逻辑的内容;
MeSH 规则为自动筛选和打分提供了精确的"生物医学坐标系",减少了盲目依赖模型自身的风险。
3. 论文中的"冷启动规则"是如何保证自身的可信度?毕竟它也需要人为设计?
回答:
"冷启动规则"以 MeSH 层级结构和信息含量(IC)为基础,结合最低公共祖先(LCA)等计算方法进行自动打分。
它从文献与候选问句的重叠度、层级关联度等方面量化相似性。
虽然最初确实需人工定义评分公式,但一旦规则确定,针对大规模文献的自动化评估就不再依赖主观人工判断,可在不依赖人工标签的情况下持续打分。
对于同领域常用的知识体系(MeSH)来说,这种规则具有较强稳定性。
4. 在多Agent的体系下,若各Agent产生冲突,如何处理不同Agent之间的决策不一致?
回答:
冲突主要体现在"同一文献下产生了多种问句"或"检索到的上下文不一致"时。
论文里给出的做法是通过"Question Evaluation Agent"来对比多个候选问句或上下文的优劣,从而"择优存留",不一致时择分最高者。
这相当于引入了投票/评分机制,最终保证多Agent在冲突时能做出一致的胜出决策,而非简单地合并所有候选输出。
5. 对于 PubMed 文献规模庞大(数千万篇)而言,Context Retrieval Agent 的检索效率会不会成为瓶颈?
回答:
确实存在效率挑战。
论文中使用 Dense Passage Retrieval (DPR) 等检索方案,通过向量化索引来加速相似度计算。
此外,也可在工程上运用大规模分布式检索框架(例如基于Faiss或向量数据库)来提高检索速度。
虽然不能彻底消除瓶颈,但这种方案较传统全文搜索仍更高效,可在数千万篇规模上运行------当然也需要强大的算力支持。
6. 论文提及"规模越大"意味着性能越好,但数据噪声也会相应上升;如何平衡数据规模和噪声?
回答:
论文的策略是利用多Agent协同与自动化评估来控制噪声,让"高置信度"的问答对得以保留。
虽然数据规模扩大时噪声可能上升,但只要评估Agent性能足够强,评估过程能有效过滤掉与文献主题匹配度差、逻辑错误或缺乏领域一致性的问答对,从而在较大规模上仍保持较好数据纯度。
这种方法本质是"以量取胜"的前提下,强化"质"的把关。
7. 假设问题极度复杂(如临床诊断需要图像、基因组信息等多模态),m-KAILIN 的文本范式能否兼容?
回答:
论文主要关注文本语料的生成和评估;对于需要多模态(图像、基因测序数据)的信息,m-KAILIN 并未直接提供多模态融合机制。
在拓展层面,可以将额外模态信息先转化或关联到文本描述,再让 m-KAILIN 做文字层面的 QA 数据生成。
但在图像、结构数据等多模态的直接处理上,该框架尚无原生支持,需要后续研究做跨模态扩展。
8. Evaluation Agent 为什么要先用"基于 MeSH 的冷启动规则"再训练"LLM 评估器"?能不能直接让 LLM 来打分?
回答:
直接用 LLM 打分,需要大量人工标注的数据来指导 LLM 评估"正确"标准;
生物医学领域人工标注尤其昂贵。
论文提出的解决方案是先用 MeSH 规则自动生成大批"偏好标签",再训一个评估LLM,减少人工投入。
如此结合了知识图谱 / 医学本体和 LLM 的优势。
若完全跳过冷启动规则,评估器缺乏可靠的大规模训练信号。
9. 训练生成Agent时,为何还要引入 DPO(Direct Preference Optimization) 这种偏好学习方式?
回答:
一般的语言模型微调仅基于标准交叉熵损失,无法直接对比"好问题"和"坏问题"之间的差异。
DPO让模型在每次更新时"倾向"生成优选过的问句,等价于在生成Agent内部嵌入了对偏好数据的对比学习。
这样做可显著拉开优质问句与劣质问句的概率差异,令生成Agent更"服从"自动评估Agent的偏好信号。
10. 如果把所有文献都扔给模型让它自己生成问答,再由 Evaluation Agent去评判,和当前的多步骤有什么不同?
回答:
直接"让模型自己生成然后自动评估"的思路可能在表面上类似,但缺点在于生成-检索-评估无法解耦;
文本检索需要精准检索器,文本生成需要特化问句的Agent,评价需要独立偏好学习。
多Agent设计使每个环节都可独立优化。
例如检索Agent可采用专门的 DPR 或领域检索模型,而不是交给通用语言模型。
这种模块化更透明、更可控,且每个Agent能单独升级或替换。
11. m-KAILIN 中为什么不直接将 BioASQ(或其他已有 QA 数据)全部并入最终的大规模数据,而要"再生"问题?
回答:
已有 QA 数据(如 BioASQ)规模有限且主题集中,无法覆盖生物医学文献的多样化需求。
m-KAILIN 把这些 QA 数据当作"引导模型学习提问风格"的参考,而后让生成Agent在大规模 PubMed 文献上产生新的问题,再利用评估Agent进行筛选。
这能显著增加数据覆盖度,避免过度局限于已有数据的模板或主题。
12. 如果同一篇文献多Agent各自生成的问题之间非常相似,是否会出现重复数据?
回答:
有可能出现重复或近似问句,但 Evaluation Agent 会根据与文献内容、MeSH分级等进行排序、优选,保留分数更高的问句-上下文对。
某些相似问题若表达、侧重点略有差异,亦可视为补充;
如果实质雷同,后续数据清理(基于文本相似度或重复检测)也可做进一步去重。
所以,框架整体会倾向于去除无意义的重复。
13. m-KAILIN 主要评测基准集中在 PubMedQA,为什么不使用更多的临床或放射学等更具挑战的数据集?
回答:
PubMedQA 是一个公共可获取、内容相对广泛的生物医学问答基准,适合作为基线评测。
更多专科如放射学、基因组学等尚缺乏统一、公开的大规模 QA 数据,且存在隐私或专业壁垒。
m-KAILIN 的核心技术思路同样可迁移到其他子领域,但在论文中初步以 PubMedQA 证明可行性。
未来或需在更具挑战性的临床专科数据集上做验证。
14. 多Agent体系是否会带来累计误差?例如检索Agent选错文献,上层Agent就白忙了?
回答:
确实存在累计误差的风险,这也是多步操作可能带来的问题。
但作者通过嵌套评估和再筛选(Question Evaluation Agent、偏好优化)来减小误差。
当检索Agent选取文献不理想,Evaluation Agent 很可能给出较低偏好评分,从而不被纳入最终训练数据;
因此系统能在一定程度上"自我纠偏",而非简单地链式传递错误。
15. 为什么仅用信息含量(IC)和 LCA 计算方式来衡量 MeSH 术语相似度?这会不会太过简化?
回答:
IC + LCA(Lowest Common Ancestor)的方法是常见的层次化本体测度,简单且高效;
它对医学知识库规模化应用有较好兼容性。
但它也有一定局限,如难以捕捉词汇的上下文用法或复杂语义关系。
若需要更精细的语义理解,可以引入更高级的本体度量方法、或结合上下文语义向量,但会牺牲一定速度和部署便利性。
作者在论文中选择了这条较易落地的技术路径。
16. 如果问句本身是错误假设或带有误导,比如问"维生素C能治愈所有癌症吗"?多Agent会怎样处理?
回答:
Evaluation Agent 在此会检查问句与文献内容的关联程度,以及"答案生成"最终表现;
如果上下文无法支持该问句或显然与文献知识相悖,评分会较低,不会被选为优质三元组。
即便这种"极端"问句通过检索Agent找到某些相关文献片段,Answer Generation Agent 也会根据文本进行回答(多半是负向或不确定)。
总之,多Agent不会盲目肯定错误假设,而是看文献是否提供足够证据。
17. 与 KAILIN 相比,m-KAILIN 声称"多Agent",那是否意味着计算资源需求更高?
回答:
一定程度上是的。多Agent管线中,需要对文献多次编码(用于检索、用于问题生成、用于评估等),以及多个模型的微调和推理会增加开销。
论文并没有否认这种资源成本上升,但指出"自动化+高质量"能减少人力依赖,总体更划算。
此外,作者也建议在实际部署中可使用分布式环境、云端API等方式,权衡多Agent的收益和算力成本。
18. DPO(Direct Preference Optimization) 使用的温度参数 β 是如何确定的?过高或过低会怎样?
回答:
论文提到温度系数 β 用于放大或缩小偏好打分的差异。通常会在小范围内调参(如 1~5),通过验证集来观察问句质量和回答准确率。
如果 β 太大,会过度放大正/负样本差距,导致问句生成模式单一;
若 β 太小,又难以区分优质与劣质问句,模型的偏好效果衰减。
这是一种需实验调优的超参。
19. 为什么论文要做"时间维度"和"子学科维度"的鲁棒性测试?
回答:
生物医学文献的内容和关注点会随着时间更新,子学科也存在巨大的术语与主题差异。
若仅在统一数据集上测试,通过率高并不代表模型能迁移到其它年代或其它领域。
时间维度测试可检验模型对老旧文献 vs. 新文献的兼容度;
子学科维度可检验模型在不同 MeSH 主题下的一致表现。
只有在这些方面都取得好成绩,才能说明框架具有通用性与可扩展性。
20. 若去除了 MeSH 评估或去除了域向量检索,最终性能为何显著下降?是哪些细节环节导致的?
回答:
- 去除 MeSH 评估:模型在缺乏专业领域约束时,很容易生成或保留与文献主题不匹配的问句;质量筛选难以精确,也就导致训练数据噪声高。
- 去除域向量检索:通用检索模型可能无法抓住生物医学专有词汇、药物名称、疾病概念等细微差异,选出来的上下文与实际问题相关度会下降。
因此,这两个环节皆是控制噪声和保证专业度的关键。缺了任何一个,效果都会显著下滑。