1.什么是蒸馏 ?
知识蒸馏(Knowledge Distillation)最早由Hinton等人在2015年提出,主要用于压缩模型。
本质上也是微调的一种类型。传统微调是为了让大模型获取一些私域知识,比如股票、医疗等等,这是让大模型的知识面增加了,但没有改变大模型的能力。而蒸馏不一样,蒸馏不光教知识,还要教能力。所谓授之以鱼,不如授之以渔,蒸馏就是要让被训练的模型能够学会教师模型的能力。
教师模型 :参数量大、性能强,但计算成本高(比如:DeepSeek R1 满血版本)。
学生模型:结构更简单、参数量少,目标是尽可能复现教师模型的输出(比如:有思维链的小模型 )。
2.适用于哪些场景 ?
- 降低部署成本:将千亿参数模型压缩到十亿甚至更小,适用于移动端、边缘设备。
- 加速推理:小模型响应更快,适合实时应用(如聊天机器人)。
- 减少能耗:适合资源受限的环境(如物联网设备)。
- 领域适配:通过蒸馏将通用大模型的能力迁移到垂直领域的小模型。
3.示例:新闻分类
整体流程
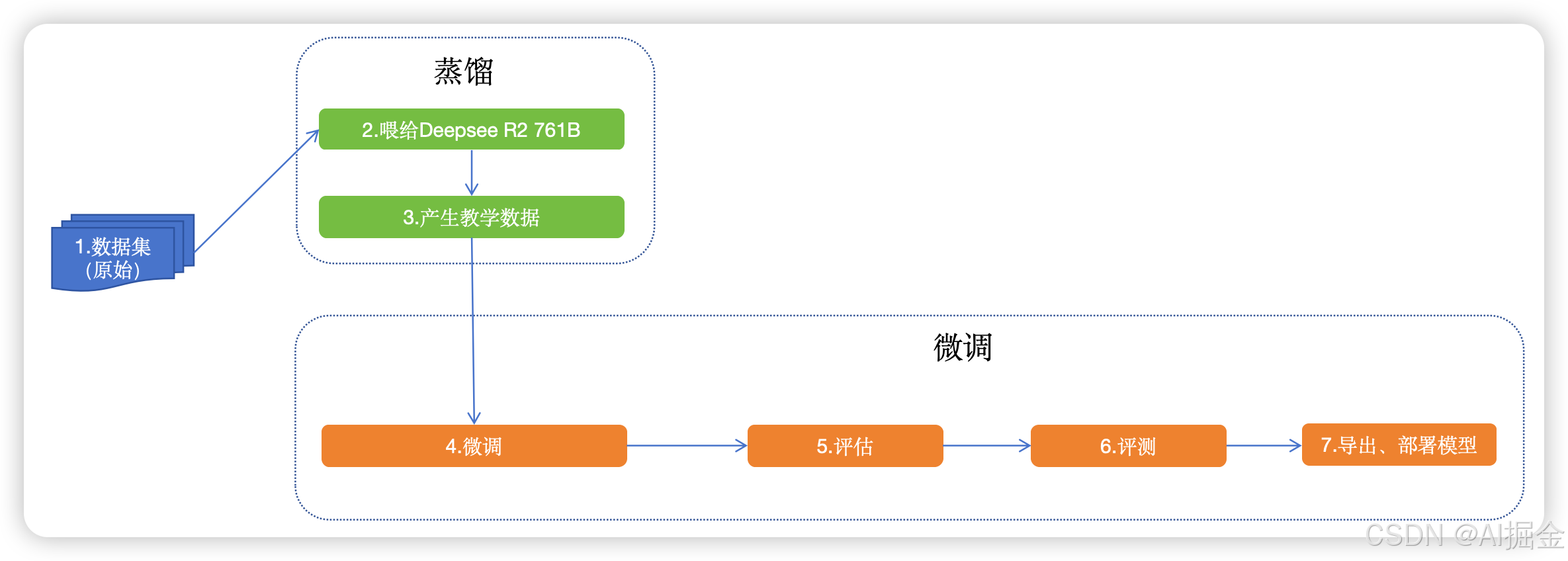
1)第一步:准备原始数据
python
新闻分类:《美国队长4》被调侃为《关云长4:周仓传》
新闻分类:特朗普与泽连斯基在白宫举行会谈时爆发激烈争吵
....2)第二步:写prompt,让DeepSeek R1 将思考过程及结果都打印出来
python
system = """
你是一个新闻分类器,擅长根据新闻标题识别新闻的类型,新闻种类包括:政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会。用户会在需要进行分类的新闻标题前加入"新闻分类:"字样,你需要给出该新闻的种类。要求包含思考过程和最终答案。
#要求格式:
<think>
思考过程(分步骤解释如何从给定信息中推导出答案)
</think>
答案(政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会中的某一种)
#示例1:
human: 新闻分类:给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!
gpt:
<think>
首先,我需要分析给出的新闻标题:"给力!中国两次出手,美到手的订单黄了,该国从此只认中国制造!"
接下来,根据标题内容进行分类。标题中提到了中国两次行动导致美国订单出现问题,并且其他国家开始依赖中国制造,说明这涉及国家之间的经济合作和社会影响。
结合新闻种类,考虑到涉及国际贸易和经济合作,最合适的分类是"经济"。所以,这条新闻应该归类到"经济"类别中。
</think>
经济
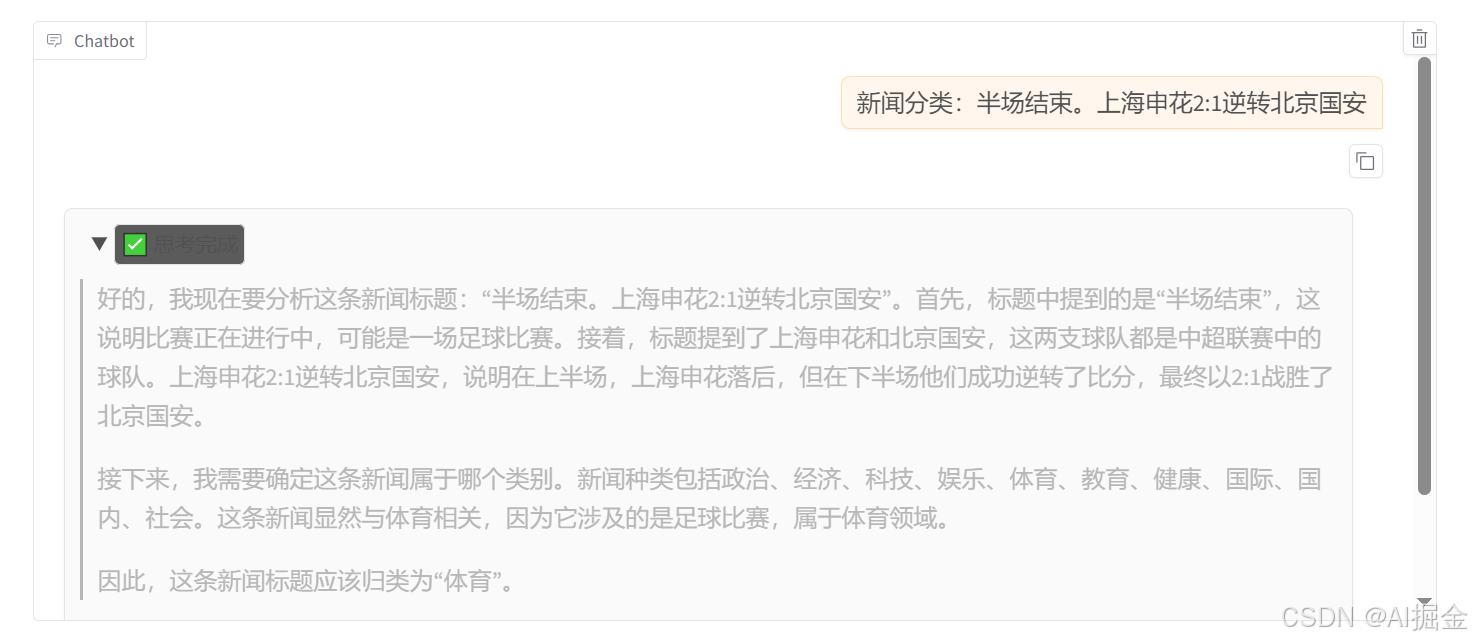
"""3)第三步:写代码将 原始数据喂给 DeepSeek R1 ,并获取到思考过程及结果
python
completion = client.chat.completions.create(
model="deepseek-r1",
messages=[
{'role': 'system', 'content': system},
{'role': 'user', 'content': '新闻分类:《美国队长4》被调侃为《关云长4:周仓传》'},
]
)
# 通过reasoning_content字段打印思考过程
print("<think>")
print(completion.choices[0].message.reasoning_content)
print("</think>")
# 通过content字段打印最终答案
print(completion.choices[0].message.content)结果示例:
python
<think>
首先,我需要分析用户提供的新闻标题:"《美国队长4》被调侃为《关云长4:周仓传》"。标题中提到了《美国队长4》,这是一部著名的超级英雄电影,属于娱乐产业的内容。此外,标题提到该电影被调侃为《关云长4:周仓传》,后者可能涉及对中国传统故事或影视作品的戏仿,这种调侃通常出现在娱乐新闻
中,用于吸引观众注意或制造话题。
接下来,考虑新闻分类的选项:政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会。这里的关键词是电影名称和调侃,明显与影视娱乐相关,没有涉及其他如经济、政治或科技的元素。因此,最合适的分类应为"娱乐"。
</think>
娱乐4)第四步:生成教学数据,只需要再将这条教学数据包装成问答对的形式即可。格式如下:
python
[
{
"conversations": [
{
"from": "human",
"value": "新闻分类:《美国队长4》被调侃为《关云长4:周仓传》"
},
{
"from": "gpt",
"value": "<think>\n首先,我需要分析用户提供的新闻标题:"《美国队长4》被调侃为《关云长4:周仓传》"。标题中提到了《美国队长4》,这是一部著名的超级英雄电影,属于娱乐产业的内容。此外,标题提到该电影被调侃为《关云长4:周仓传》,后者可能涉及对中国传统故事或影视作品的戏仿,这种调侃通常出现在娱乐新闻中,用于吸引观众注意或制造话题。\n\n接下来,考虑新闻分类的选项:政治、经济、科技、娱乐、体育、教育、健康、国际、国内、社会。这里的关键词是电影名称和调侃,明显与影视娱乐相关,没有涉及其他如经济、政治或科技的元素。因此,最合适的分类应为"娱乐"\n</think>\n\n娱乐"
}
]
}
]5)第五步:微调与测试
微调的方式,可以爬楼看一下,我以往教程
微调后,小模型也有了思维链、推理过程: