1 线性表
1.1 顺序表(Sequential List)
顺序表并不难理解,主要是知道顺序表是在内存中连续存储的一段数据,知道这个后,相应的算法也就非常简单了。
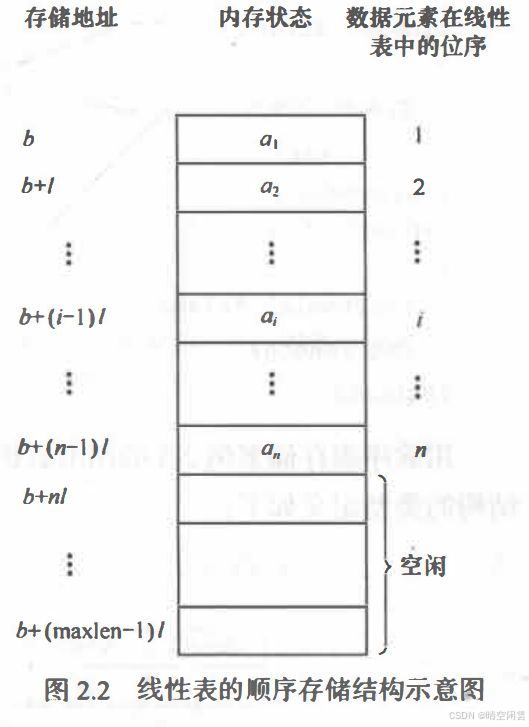
线性表的顺序表示指的是用一组地址连续的存储单元依次存储线性表的数据元素, 这种表示也称作线性表的顺序存储结构或顺序映像。通常, 称这种存储结构的线性表为顺序表(Sequential List)。其特点是,逻辑上相邻的数据元素, 其物理次序也是相邻的。
假设线性表的每个元素需占用 l 个存储单元,第 i + 1 个数据元素的存储位置和第 i 个元素存储的位置关系如下:
L O C ( a i + 1 ) = L O C ( a i ) + l LOC(a_{i+1}) = LOC(a_{i})+l LOC(ai+1)=LOC(ai)+l
第 i 个数据元素 a_i 的存储位置为:
L O C ( a i ) = L O C ( a 1 ) + ( i − 1 ) ∗ l LOC(a_{i}) = LOC(a_{1})+(i-1)*l LOC(ai)=LOC(a1)+(i−1)∗l
参考示意图:
线性表的基本操作在王卓老师教程和书籍的基础上进行了增加了,如下总计有11个。
c
InitList(&L) // 初始化操作,建立一个空的线性表L
DestroyList(&L) // 销毁已存在的线性表L
ClearList(&L) // 将线性表清空
ListInsert(&L, i, &e) // 在线性表L中第i个位置插入新元素e
ListDelete(&L, i, &e) // 删除线性表L中第i个位置元素,用e返回
ListEmpty(&L) // 若线性表为空,返回1,否则0
ListLength(&L) // 返回线性表L的元素个数
GetElem(&L, i, &e) // 将线性表L中的第i个位置元素返回给e
LocateElem(&L, &e) // L中查找与给定值e相等的元素,若成功返回该元素在表中的序号,否则返回0
PriorElem(&L, &cur_e, &pre_e) // 返回线性表cur_e的前驱元素,如果cur_e是第一个元素,则pre_e无定义
NextElem(&L, &cur_e, &next_e) // 返回线性表cur_e的后继元素,如果cur_e是最后一个元素,则next_e无定义在实现每个方法之前需要先定义顺序表的存储结构:
c
// 声明 ElemType 的结构,这里为了简单方便,存储一个整数
typedef struct
{
int x;
} ElemType;
// 声明一个顺序表
typedef struct
{
ElemType *elem;
int length;
} SqList;为了方便后续编写,声明一些常量:
c
// 声明一些常量
#define OK 1
#define ERROR 0
#define OVERFLOW -2
#define TRUE 1
#define FALSE 0
// Status 是函数返回值类型, 其值是函数结果状态代码。
typedef int Status;
// Boolean 定义布尔型,值就是 TRUE 和 FALSE。
typedef int Boolean;
// 顺序表的元素最大为100个
#define MAXSIZE 100这里我使用了C语言进行编写,后续代码实现我均采用C语言。
1.1.1 初始化
顺序表的初始化操作就是构造一个空的顺序表。
【算法步骤】
- 为顺序表
L动态分配一个预定义大小的数组空间,使elem指向这段空间的基地址。 - 将表的当前长度设为0。
【代码实现】
c
// 初始化顺序表
Status InitList(SqList *L)
{
L->elem = (ElemType *)malloc(MAXSIZE * sizeof(ElemType)); // 分配初始空间
if (L->elem == NULL)
{
return OVERFLOW;
}
L->length = 0;
return OK;
}【算法分析】
非常容易看出,顺序表初始化算法的时间复杂度为 O(1) 。
1.1.2 销毁
销毁就是删除一个顺序表占用的内存空间。
【算法步骤】
- 检测顺序表
L的元素是否占用了内存空间,如果有则释放内存空间。 - 将表的当前长度设为0。
【代码实现】
c
// 销毁顺序表
Status DestroyList(SqList *L)
{
if (L->elem != NULL) // 检查元素是否存在,存储在需要
{
free(L->elem); // 释放内存
L->elem = NULL; // 防止悬空指针
}
L->length = 0; // 重置长度
return OK;
}【算法分析】
显然,顺序表销毁算法的时间复杂度为 O(1) 。
1.1.3 清空
清空和销毁不同,销毁需要回收一个顺序表元素占用的内存空间,清空只需要将顺序表长度置为0即可。
【算法步骤】
- 将表的当前长度设为0。
【代码实现】
c
// 清空顺序表
Status ClearList(SqList *L)
{
L->length = 0; // 重置长度
}【算法分析】
顺序表清空算法的时间复杂度为 O(1) 。
1.1.4 插入
在顺序表的第 i 个位置插入元素。
【算法步骤】
- 判断插入位置
i是否合法(i值的合法范围是1 ≤ i ≤ n+1),若不合法则返回ERROR。 - 判断顺序表的存储空间是否已满,若满则返回
ERROR。 - 将第
n个至第i个位置的元素依次向后移动一个位置,空出第i个位置(i = n + 1时无需移动 )。 - 将要插入的新元素
e放入第i个位置。 - 表长加 1。
【代码实现】
c
// 在顺序表 L 中第 i 个位置之前插入新的元素 e, i 值的合法范围是 1 ≤ i ≤ L.length + 1
Status ListInsert(SqList *L, int i, ElemType e)
{
if (i < 1 && i > L->length) // i 值不合法
return ERROR;
if (L->length == MAXSIZE) // 存储空间已满
return ERROR;
for (int j = L->length - 1; j >= i - 1; j--) // 插入位置及之后的元素后移
{
L->elem[j + 1] = L->elem[j];
}
L->elem[i - 1] = e; // 将新元素放入第 i 个位置
L->length++; // 表长加 1
return OK;
}【算法分析】
当在顺序表中某个位置上插入一个数据元素时,其时间主要耗费在移动元素上,而移动元素的个数取决于插入元素的位置。
假设 p i p_i pi 是在第i个元素之前插入一个元素的概率, E i n s E_{ins} Eins 为在长度为 n 的线性表中插入一个元素时所需移动元素次数的期望值(平均次数),则有:
E i n s = ∑ i = 1 n + 1 p i ( n − i + 1 ) E_{ins} = \sum_{i=1}^{n+1}p_i(n-i+1) Eins=i=1∑n+1pi(n−i+1)
公式解析:
i=1:表示插入在第 1 个位置,第 1 ~ n 个元素都需要向后移动1格,总移动次数为n = n - (i -1);i=2:表示插入在第 2 个位置,第 2 ~ n 个元素都需要向后移动1格,总移动次数为n - 1 = n - (i -1);i=3:表示插入在第 3 个位置,第 3 ~ n 个元素都需要向后移动1格,总移动次数为n - 2 = n - (i -1);- ...
i=n:表示插入在第 n 个位置,第 n 个元素都需要向后移动1格,总移动次数为1 = n - (i -1);i=n+1:表示插入在最后一个位置,元素无需移动,总移动次数为0 = n - (i -1);
假定在线性表的任何位置上插入元素都是等概率的,即:
P i = 1 n + 1 P_i=\frac{1}{n+1} Pi=n+11
则前面计算平均次数的公式可以转换为:
E i n s = 1 n + 1 ∑ i = 1 n + 1 ( n − i + 1 ) = 1 n + 1 ∗ n ( n + 1 ) 2 = n 2 E_{ins} = \frac{1}{n+1}\sum_{i=1}^{n+1}(n-i+1) = \frac{1}{n+1} * \frac{n(n+1)}{2} = \frac{n}{2} Eins=n+11i=1∑n+1(n−i+1)=n+11∗2n(n+1)=2n
过程解析:求和公式实际上就是 n + (n-1) + ... + 0 ,等差数列求和。
顺序表插入算法的平均时间复杂度为 O(n) 。
1.1.5 删除
删除顺序表中第 i 个位置的元素。
【算法步骤】
- 判断插入位置
i是否合法(i值的合法范围是1 ≤ i ≤ n+1),若不合法则返回ERROR。 - 将第
i + 1个至第n个的元素依次向前移动一个位置(i=n时无需移动,即删除最后一个 )。 - 表长减 1。
【代码实现】
c
// 在顺序表 L 中删除第 i 个元素, i 值的合法范围是 1 ≤ i ≤ L.length + 1
Status ListDelete(SqList *L, int i)
{
if (i < 1 && i > L->length) // i 值不合法
return ERROR;
for (int j = i; j <= L->length - 1; j++) // 被删除元素之后的元素前移
{
L->elem[j - 1] = L->elem[j];
}
--L->length; // 表长减 1
return OK;
}【算法分析】
当在顺序表中某个位置上删除一个数据元素时,其时间主要耗费在移动元素上,而移动元素的个数取决于删除元素的位置。
假设 p i p_i pi 是删除第 i 个元素的概率, E d e l E_{del} Edel 为在长度为 n 的线性表中删除一个元素时所需移动元素次数的期望值(平均次数 ),则有
E d e l = ∑ i = 1 n p i ( n − i ) E_{del} = \sum_{i=1}^{n}p_i(n-i) Edel=i=1∑npi(n−i)
假定在线性表的任何位置上删除元素都是等概率的,即:
P i = 1 n P_i=\frac{1}{n} Pi=n1
则前面计算平均次数的公式可以转换为:
E d e l = 1 n ∑ i = 1 n ( n − i ) = 1 n ∗ n ( n − 1 ) 2 = n − 1 2 E_{del} = \frac{1}{n}\sum_{i=1}^{n}(n-i) = \frac{1}{n} * \frac{n(n-1)}{2} = \frac{n-1}{2} Edel=n1i=1∑n(n−i)=n1∗2n(n−1)=2n−1
顺序表删除算法的平均时间复杂度为 O(n) 。
1.1.6 判断是否为空
【算法步骤】
- 检测顺序表的长度是否为0,为0则返回1。
【代码实现】
c
// 判断顺序表是否为空
Boolean IsEmpty(SqList *L)
{
if (L->length == 0) return TRUE;
return FALSE;
}【算法分析】
时间复杂度为 O(1) 。
1.1.7 获取线性表的元素个数
【算法步骤】
- 线性表中的 length 通过线性表结构中的 length 属性既可获得。
【代码实现】
c
// 返回顺序表的长度
int ListLength(SqList *L)
{
return L->length;
}【算法分析】
时间复杂度为 O(1) 。
1.1.8 取值
根据位置 i 获取该位置的元素。
【算法步骤】
- 判断指定的位置序号
i值是否合理 (1 <= i <= L.length),若不合理,则返回ERROR。 - 若
i值合理,则将第i个数据元素L.elem[i-1]赋给参数e, 通过e返回第i个数据元素的传值。
【代码实现】
c
// 获取一个元素,L使用值传递的方式。
// 备注:如果 L 是按值传递,会拷贝整个 SqList 结构体,这在结构体较大时会浪费内存和时间。
Status GetElem(SqList *L, int i, ElemType *e)
{
if (i < 1 || i > L->length)
return ERROR;
*e = L->elem[i - 1];
return OK;
}【算法分析】
直接通过 i-1 进行获取,时间复杂度为 O(1) 。
1.1.9 查找
【算法步骤】
- 从第一个元素起,依次和
e相比较,若找到与e相等的元素L.elem[i],则查找成功,返回该元素的序号i+1。 - 若查遍整个顺序表都没有找到,则查找失败, 返回0。
【代码实现】
c
// 在顺序表中查找元素e的位置
int LocateELem(SqList *L, ElemType *e)
{
int i = 0;
for (i = 0; i < L->length; i++)
{
if (L->elem[i].x == e->x)
{
return i + 1;
}
}
return 0;
}【算法分析】
A S L = ∑ i = 1 n p i C i ASL = \sum_{i=1}^np_iC_i ASL=i=1∑npiCi
- ASL(Average Search Length):平均查找长度。
- p i p_i pi :表示查找第
i个元素的概率。 - C i C_i Ci :表示为找到表中其关键字与给定值相等的第
i个记录时,和给定值已进行过比较的关键字个数。
假设每个元素的查找概率相同,即 p i = 1 / n p_i=1/n pi=1/n ;另外 C i C_i Ci 取决于所查元素在表中的位置,在顺序表中 C i = i C_i=i Ci=i 。则上面公式可以化简为:
A S L = 1 n ∑ i = 1 n i = 1 n ∗ n ( n + 1 ) 2 = n + 1 2 ASL = \frac{1}{n}\sum_{i=1}^ni = \frac{1}{n}*\frac{n(n+1)}{2} = \frac{n+1}{2} ASL=n1i=1∑ni=n1∗2n(n+1)=2n+1
因此顺序表按值查找算法的平均时间复杂度为 O(n)。
1.1.10 查找前驱
【算法步骤】
- 调用 查找 算法,得到所查找的元素所在位置
i; - 判断位置
i是否合法(i值的合法范围是2 ≤ i ≤ L.length,第一个元素没有前驱元素),若不合法则返回0。 - 如果
i合法,则L.elem[i-2]即为要查找的上一个元素,保存在返回的pre_e中。 - 返回前驱元素的位置
i-1。
【代码实现】
c
// 查找前驱元素,cur_e表示要查找的元素,返回的结果存放在pre_e
int PriorElem(SqList *L, ElemType *cur_e, ElemType *pre_e)
{
int i = LocateELem(L, cur_e);
if (i < 2 || i > L->length) // i 值不合法,第1个元素没有前驱
return 0;
*pre_e = L->elem[i - 2]; // 下标从0开始计算
return i - 1;
}【算法分析】
该算法依赖 查找 算法,查找算法的平均时间复杂度为 O(n),查找后的代码运行时间复杂度是常量阶 O(1),所以整体的时间复杂度是 O(n)。
1.1.11 查找后继
【算法步骤】
- 调用 查找 算法,得到所查找的元素所在位置
i; - 判断位置
i是否合法(i值的合法范围是1 ≤ i ≤ L.length-1,最后一个没有后继元素 ),若不合法则返回0。 - 如果
i合法,则L.elem[i]即为要查找的下一个元素,保存在返回的next_e中。 - 返回后继元素的位置
i + 1。
【代码实现】
c
// 查找后继元素,cur_e表示要查找的元素,返回的结果存放在next_e
int NextElem(SqList *L, ElemType *cur_e, ElemType *next_e)
{
int i = LocateELem(L, cur_e);
if (i < 1 || i > L->length - 1) // i 值不合法,最后一个元素没有后继
return 0;
*next_e = L->elem[i];
return i + 1;
}【算法分析】
该算法依赖 查找 算法,查找算法的平均时间复杂度为 O(n),查找后的代码运行时间复杂度是常量阶 O(1),所以整体的时间复杂度是 O(n)。