在人工智能的浪潮中,大模型无疑是最耀眼的明星之一。而大模型的正常运行离不开各种不同类型的文件,这些文件就像是大模型的"零部件",各自发挥着重要的作用。了解大模型涉及的文件类型,不仅有助于我们更好地理解大模型的工作原理,在相关的面试中也能让我们脱颖而出。

今天,我们就来深入探讨一下大模型的文件类型,并通过一些面试题来检验大家的掌握程度。
大模型文件类型介绍
大模型的文件类型主要分为模型文件和数据文件,下面我们分别来详细了解一下。
模型文件
1. 模型权重文件
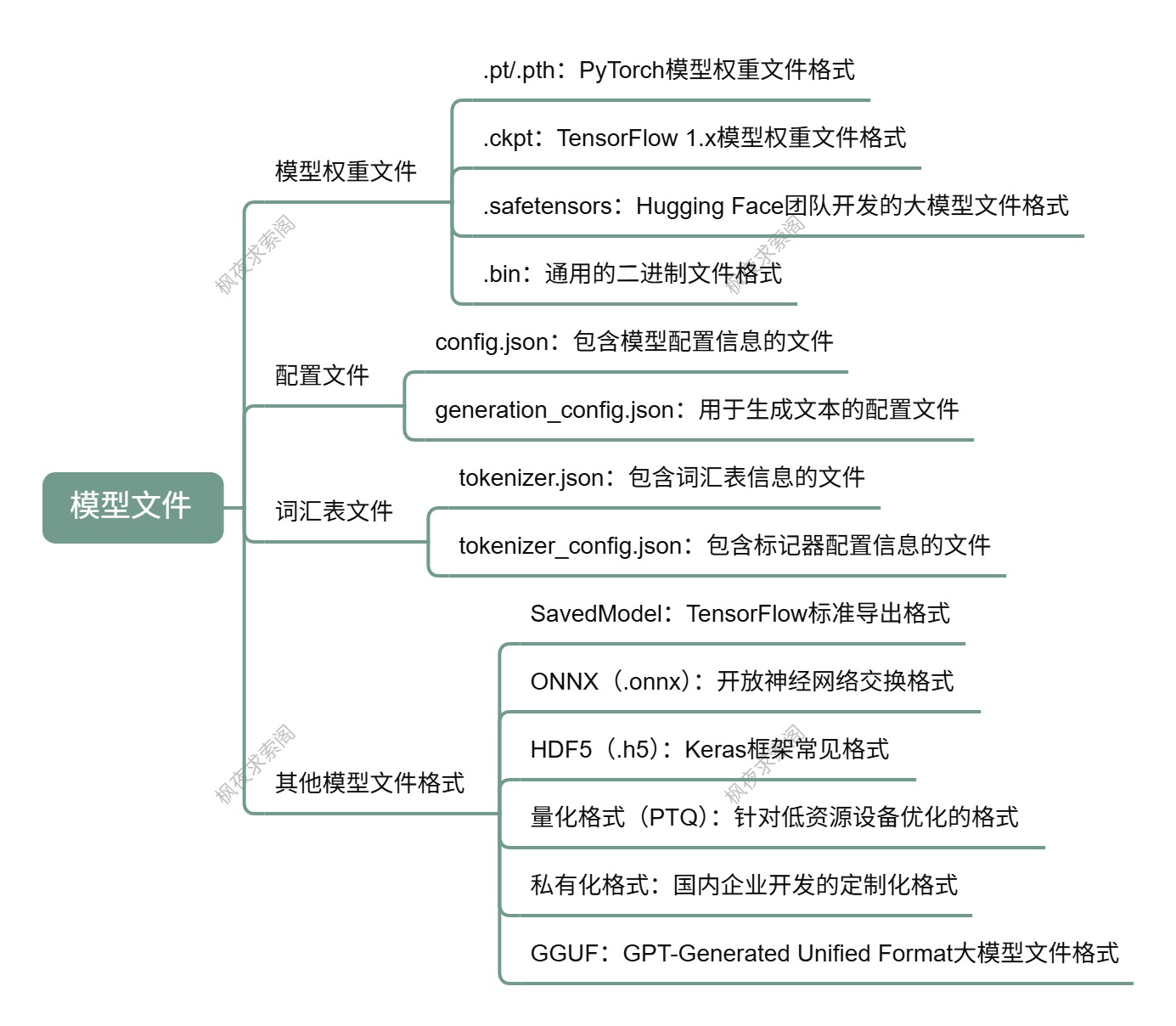
模型权重文件用于存储训练好的模型参数,是模型推理和微调的基础。不同的深度学习框架有不同的模型权重文件格式,以下是一些常见的格式:
- .pt/.pth :这是 PyTorch 中用于保存模型状态的标准格式。它可以保存模型的
state_dict(包含所有可学习参数)或整个模型(包括结构和参数)。其特点是灵活性高,可以轻松保存和加载模型的参数,支持在不同设备之间迁移模型;与 PyTorch 框架高度兼容,加载时使用torch.load()函数,保存时使用torch.save()函数。适用于 PyTorch 框架下的模型保存和加载,特别是在需要频繁迁移模型参数的情况下,例如通义千问(Qwen)和混元(HunYuan)等模型均采用此格式。 - .ckpt :TensorFlow 1.x 中用于保存模型参数和优化器状态的文件格式。采用 TensorFlow 的自定义序列化格式,不能直接用于其他框架,可以使用 TensorFlow 的
tf.train.Saver类来加载和保存.ckpt文件。适用于 TensorFlow 1.x 框架下的模型保存和加载,特别是在需要保存优化器状态的情况下。TensorFlow 2.x 仍支持检查点保存(通过<font style="color:rgb(44, 44, 54);">tf.train.Checkpoint</font>),但更推荐使用<font style="color:rgb(44, 44, 54);">SavedModel</font>格式。 - .safetensors :由 Hugging Face 团队开发,专为存储和加载大型张量而设计的格式。具有安全性高的特点,采用了加密和校验机制,防止模型文件被篡改或注入恶意代码;支持加密存储,保护模型的隐私;通过优化的二进制格式和支持内存映射,显著提高大模型文件的加载速度;有多种深度学习框架的兼容性,便于在不同环境中使用。在
.safetensors中,大模型可被分为多个部分,格式类似 modelname-0001.safetensors、modelname-0002.safetensors,model.safetensors.index.json 是索引文件,记录了模型的各个部分的位置和大小信息。该格式适用于需要高安全性和快速加载的大模型,特别是在 Hugging Face 的 Transformers 库中广泛使用。 - .bin :一种通用的二进制文件格式,可以用于保存模型参数和优化器状态,但不同框架的
<font style="color:rgb(44, 44, 54);">.bin</font>文件用途不同。其通用性强,可以被多种框架所使用,例如 TensorFlow、PyTorch 和 ONNX 等:- PyTorch :典型
<font style="color:rgb(44, 44, 54);">.bin</font>文件(如<font style="color:rgb(44, 44, 54);">pytorch_model.bin</font>)存储模型权重的<font style="color:rgb(44, 44, 54);">state_dict</font>,需配合<font style="color:rgb(44, 44, 54);">config.json</font>使用。 - TensorFlow :一般不直接使用
<font style="color:rgb(44, 44, 54);">.bin</font>,而是通过<font style="color:rgb(44, 44, 54);">.h5</font>或<font style="color:rgb(44, 44, 54);">SavedModel</font>保存权重。 - Hugging Face :
<font style="color:rgb(44, 44, 54);">.bin</font>文件通常包含预训练模型权重(如 Qwen),需通过<font style="color:rgb(44, 44, 54);">AutoModel.from_pretrained()</font>加载。
- PyTorch :典型
2. 配置文件
配置文件确保模型架构的一致性,使得权重文件能够正确加载。常见的配置文件如下:
- config.json :包含模型的配置信息,如模型架构、参数设置等,可能包含隐藏层的数量、每层的神经元数、注意力头的数量等。例如,
architectures字段指定了模型的架构,hidden_act字段指定了隐藏层的激活函数,hidden_size字段指定了隐藏层的神经元数,num_attention_heads字段指定了注意力头的数量,max_position_embeddings字段指定了模型能处理的最大输入长度等。 - generation_config.json :用于生成文本的配置文件,包含了生成文本时的参数设置,如
max_length(生成文本的最大长度)、temperature(用于控制生成文本的随机性)、top_k等。例如,bos_token_id字段指定了开始标记的 ID,eos_token_id字段指定了结束标记的 ID,do_sample字段指定了是否使用采样。
3. 词汇表文件
词汇表文件保证输入输出的一致性,是自然语言处理模型理解和生成文本的基础。常见格式如下:
- tokenizer.json :包含了模型使用的词汇表信息,如词汇表的大小、特殊标记的 ID 等。其中
truncation是定义截断策略,用于限制输入长度;padding定义了填充策略。 - tokenizer_config.json :包含标记器的配置信息,辅助
tokenizer.json完成文本的分词和编码工作。
4. 其他模型文件格式
- SavedModel:TensorFlow 的标准导出格式,适合云服务和跨平台部署,如百度文心一言和 Google PaLM。它包含了模型的计算图和权重,能够在不同的环境中进行部署和推理。
- ONNX(.onnx):开放神经网络交换格式,支持跨框架互操作性。打破了框架之间的壁垒,使得模型可以在不同的深度学习框架之间进行转换和部署,支持多种深度学习框架,如 PyTorch、TensorFlow、Keras 等。被阿里云、腾讯和商汤科技等公司用于高性能推理和边缘计算,适用于需要在不同框架之间转换和部署的模型,特别是在跨框架的模型优化和推理中。
- HDF5(.h5):常见于 Keras 框架,适用于传统深度学习任务,便于快速原型设计。包含了模型的权重、结构和配置信息,与 Keras 框架高度兼容,支持在不同设备之间迁移模型。
- 量化格式(PTQ):针对低资源设备优化,通过减少模型大小和推理时间提升效率。科大讯飞和百川智能等公司在边缘计算中广泛应用。
- 私有化格式:国内企业(如科大讯飞和商汤科技)针对企业级用户开发定制化格式,满足私有化部署需求,保障企业数据的安全性和隐私性。
- GGUF :GPT-Generated Unified Format,是由 Georgi Gerganov(著名开源项目 llama.cpp 的创始人)定义发布的一种大模型文件格式,继承自其前身 GGML。GGUF 是一种二进制格式文件的规范,原始的大模型预训练结果经过转换后变成 GGUF 格式可以更快地被载入使用,也会消耗更低的资源。其具有单文件部署、可扩展性、
mmap兼容性、易于使用、信息完整等特性。目前 Huggingface Transformers 已经支持了 GGUF 格式,像谷歌的 Gemma、阿里的 Qwen 等模型默认已经提供了 GGUF 格式文件。
数据文件
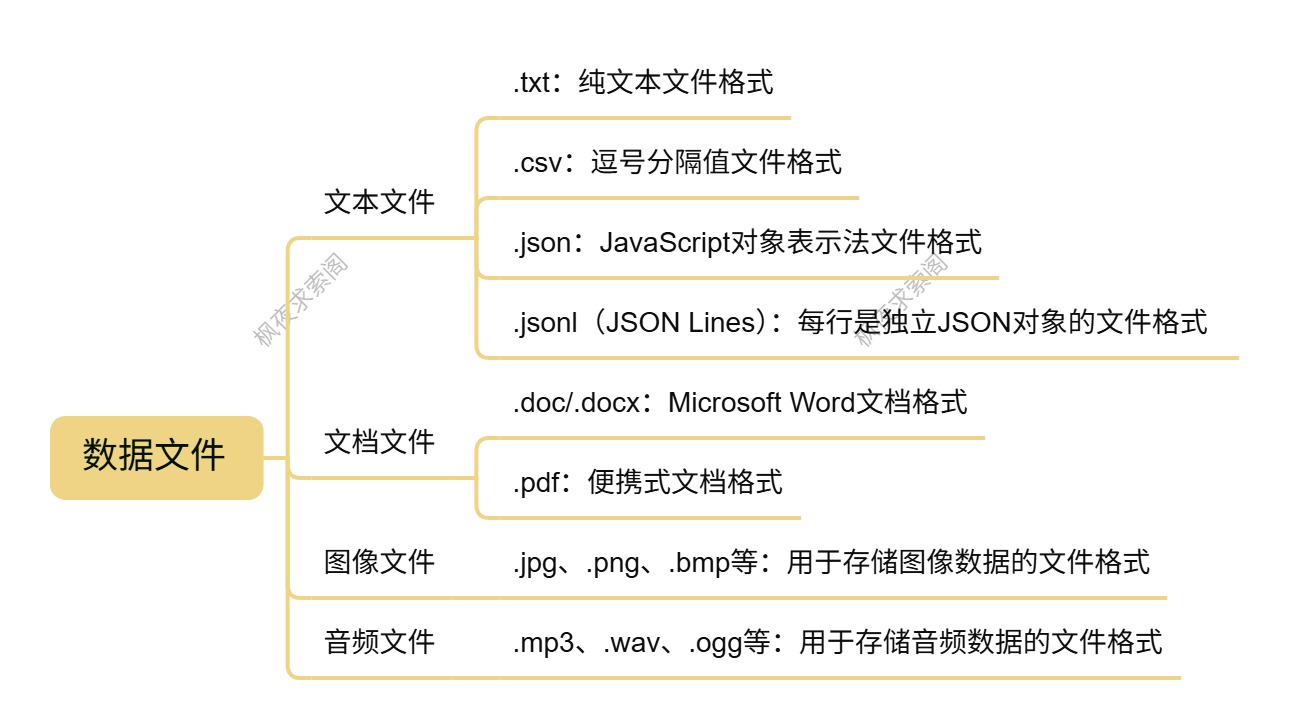
在大模型训练中,数据文件是训练的基础,不同类型的数据文件适用于不同的场景和任务。常见的数据文件类型及处理方式如下:
- 文本文件(.txt、.csv、.json等)
- .txt:纯文本文件,常用于存储简单的文本数据,如小说、新闻文章等。其优点是格式简单,易于处理和读取;缺点是缺乏结构化信息,不利于大规模数据的管理和分析。
- .csv:逗号分隔值文件,以表格形式存储数据,每行代表一条记录,每列代表一个字段。适合存储结构化的文本数据,如数据集的标注信息、实验结果等。可以使用 Pandas 库进行高效的读取和处理。
- .json:JavaScript 对象表示法文件,以键值对的形式存储数据,支持嵌套结构,能够很好地表示复杂的数据关系。常用于存储半结构化的数据,如网页爬虫数据、API 响应数据等。
<font style="color:rgb(44, 44, 54);">.jsonl</font>(JSON Lines)格式:常用于大模型训练,每行是一个独立的 JSON 对象,支持高效流式读取(如 OpenWebText 数据集)。
- 文档文件(.doc、.docx、.pdf等)
- .doc/.docx :Microsoft Word 文档格式,常用于存储正式的文档、报告等。可以使用
python-docx库提取文本内容,但对于复杂的格式和图表处理较为困难。 - .pdf :便携式文档格式,具有良好的跨平台性和格式稳定性。可以使用
pdftotext命令提取文本,但对于扫描版的 PDF 文件,需要使用 OCR 技术进行文字识别。
- .doc/.docx :Microsoft Word 文档格式,常用于存储正式的文档、报告等。可以使用
- 图像文件(.jpg、.png、.bmp等) :用于存储图像数据,在计算机视觉任务中广泛使用。不同的图像格式具有不同的压缩算法和特点,如
.jpg是一种有损压缩格式,适合存储照片;.png是一种无损压缩格式,适合存储图标、透明图像等。 - 音频文件(.mp3、.wav、.ogg等) :用于存储音频数据,在语音识别、语音合成等任务中使用。不同的音频格式具有不同的编码方式和音质,如
.mp3是一种有损压缩格式,广泛应用于音乐播放;.wav是一种无损音频格式,音质较好,但文件体积较大。
大模型文件类型面试题及解析
枫夜求索阁 点击查看具体的面试题及解析。
总结
通过以上的介绍和面试题解析,相信大家对大模型涉及的文件类型有了更深入的了解。不同的文件类型在大模型的训练、推理、部署等环节都发挥着重要的作用。

在实际应用中,我们需要根据具体的任务和需求选择合适的文件类型,并对数据进行预处理和清洗,以提高模型的训练效果和性能。希望大家通过这些内容的学习,能够更好地应对大模型相关的面试和实际工作。
