在近年来,深度学习尤其在计算机视觉领域取得了巨大的进展,而 Vision Transformer(ViT)作为一种新的视觉模型,它的表现甚至在许多任务中超过了传统的卷积神经网络(CNN),如
ResNet。在这篇博客中,我们将详细介绍 Vision Transformer 的工作原理,并解释它如何在各种公开数据集上超越最好的 ResNet,尤其是在大数据集上的预训练过程中,ViT 展现出的优势。
什么是 Vision Transformer (ViT)?
1. 背景与起源
Vision Transformer(ViT)是从 Transformer 模型发展而来的,最初的 Transformer 模型主要应用于自然语言处理(NLP)任务,尤其是机器翻译。在 NLP 中,Transformer 展现出了其强大的序列建模能力,能够捕捉长距离的依赖关系。
在计算机视觉领域,传统的卷积神经网络(CNN)一直是图像分类、目标检测等任务的主力。然而,ViT 在提出后,尤其是在大型数据集上进行预训练时,凭借其在长距离依赖建模上的优势,迅速展示了其强大的能力。ViT 把 Transformer 模型应用于图像数据,并通过某些创新技巧,解决了传统卷积神经网络的局限性。
2. ViT 的基本原理
ViT 将图像输入视为一系列小的图像块(patch),而不是传统的像素级输入。通过这种方法,ViT 将图像的局部信息转换为序列数据,使得 Transformer 可以通过自注意力机制对图像进行处理。下面我们将详细介绍 ViT 的工作流程。
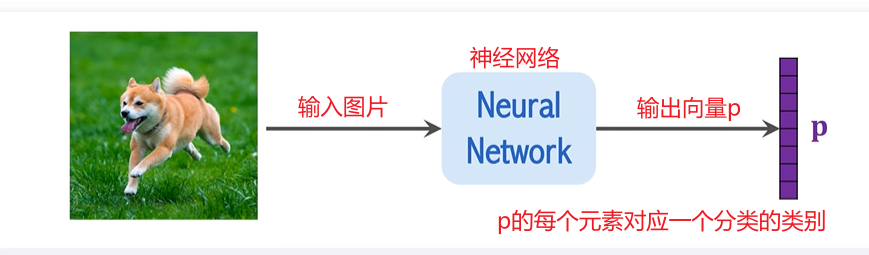
ViT 的工作流程
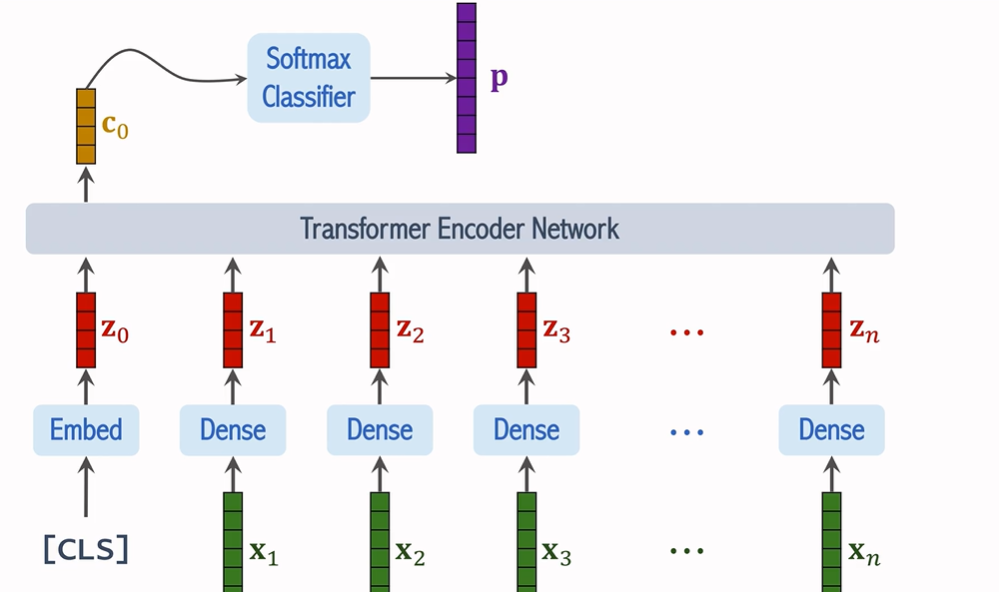
1. 图像分块(Patch Splitting)
首先,将输入图像划分为固定大小的块(patch),每个块的尺寸通常为 16x16 或更大,具体取决于模型的设计。在处理过程中,每个图像块被视为一个独立的单元,这与自然语言处理中的"单词"相似。
假设原图的尺寸为 224x224 像素,ViT 将其划分为 14x14 个 16x16 的小块。这样,原始图像就被转化为 196 个图像块(14 * 14 = 196),每个块有 3 个通道(RGB)。

2. 向量化(Flattening)
每个小块通过 Flatten 操作(拉伸)变成一个向量。例如,一个 16x16 大小的 RGB 图像块经过拉伸后将变为一个 768 维的向量(16x16x3 = 768)。这些向量作为 Transformer 的输入。

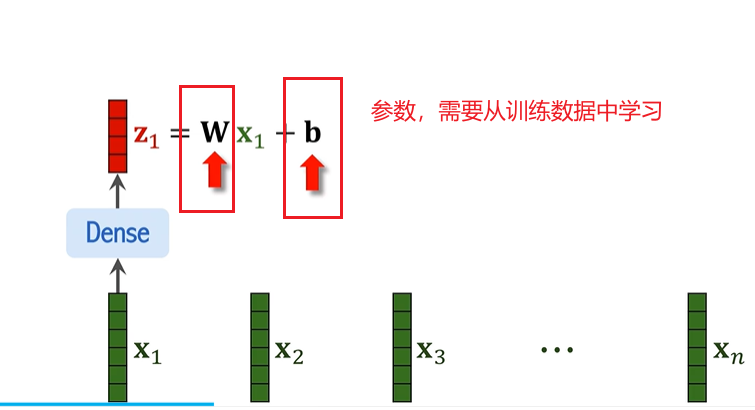
3. 线性变换(Linear Transformation)
每个图像块向量通过一个线性变换,映射到一个新的维度,这个操作通常由一个全连接层完成。此时,所有块的特征空间被转换到新的表示空间中,得到新的表示向量 z_i。
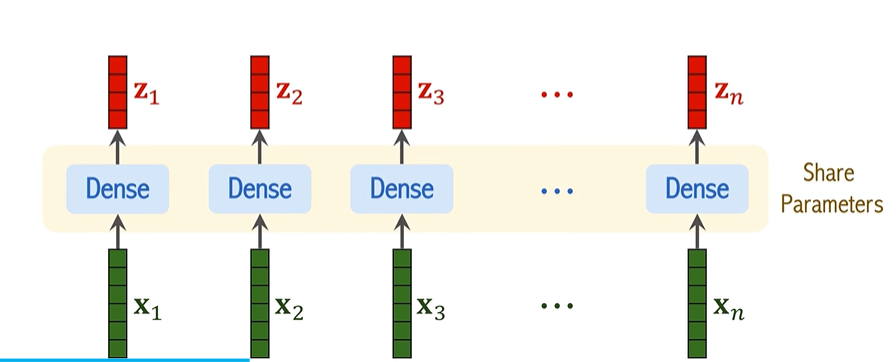
4. 添加位置编码(Positional Encoding)
由于 Transformer 本身并不具备处理序列中元素位置的能力,ViT 通过添加位置编码来保留位置信息。每个图像块的向量 z_i 会加上相应的位置信息,这样每个块的表示就不仅包含了图像内容的信息,还包含了该块在图像中的位置信息。
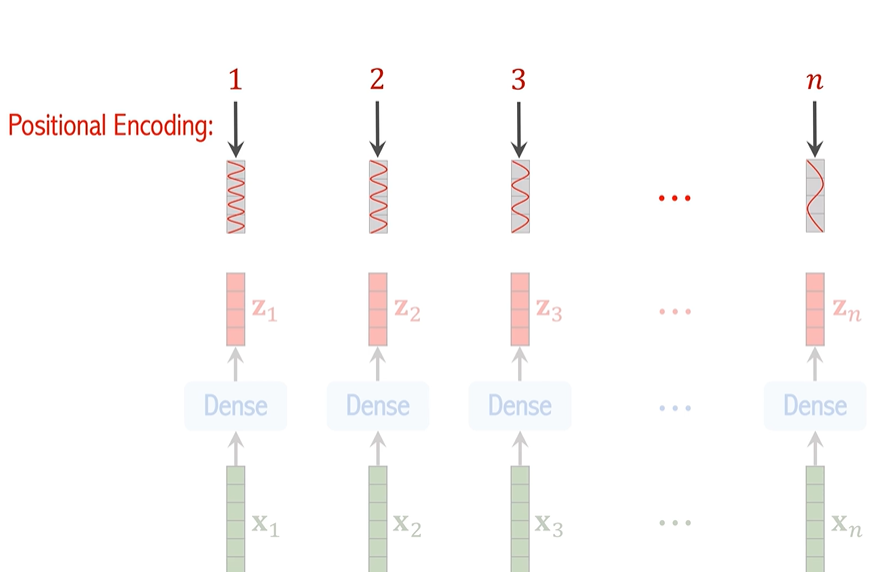
如果不包含位置信息,那么左右两张图对transformer眼里是一样的,所有要给图片位置做编号


x1-xn是图片中n个小块向量化后得到的结果,把他们做线性变换并且得到位置信息得到向量z1-zn,(既包含内容信息又包含位置信息)
5. CLS Token 和最终的输入
为了最终的图像分类,ViT 引入了一个特殊的分类标记(CLS Token)。该标记是一个额外的向量,通常初始化为零,并与图像块的表示一起作为输入送入 Transformer。最终,CLS Token 会作为图像的整体表示,进行分类任务。
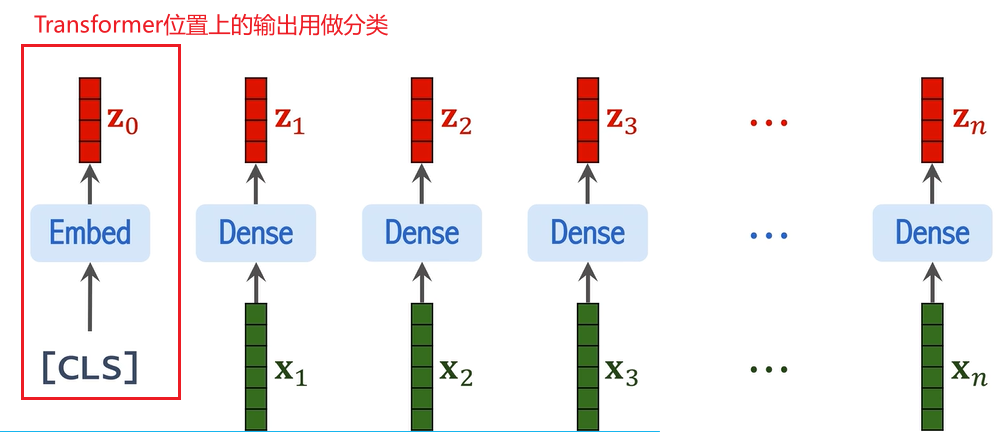
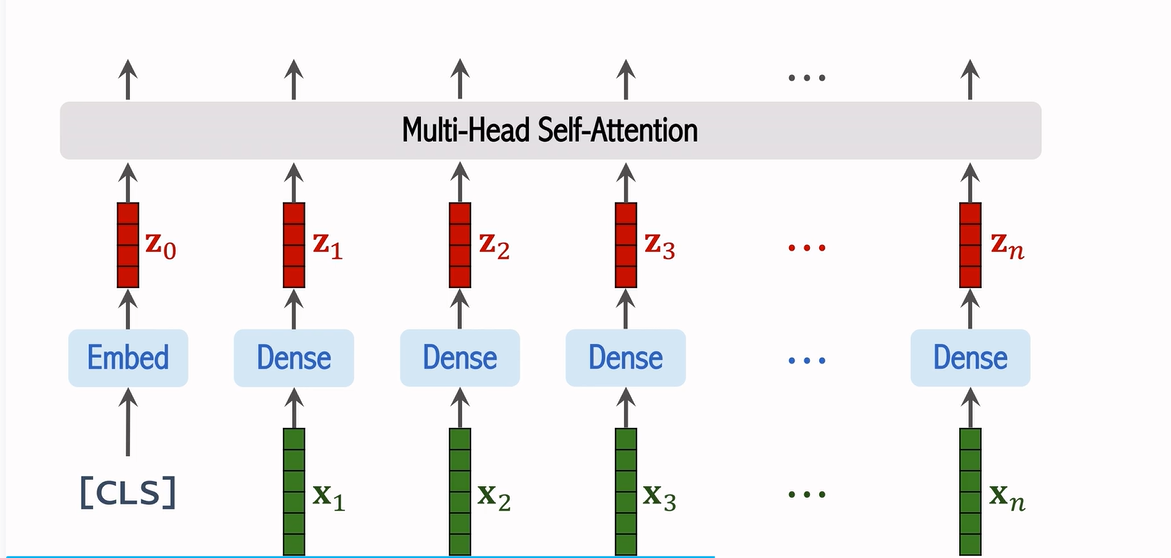
6. Transformer 编码器(Encoder)
输入经过位置编码和 CLS Token 的处理后,所有的图像块向量会被送入 Transformer 编码器。ViT 使用多层的自注意力机制(Self-Attention)来处理这些向量。每一层的输出都会被送入下一层,直到所有的信息被充分聚合。
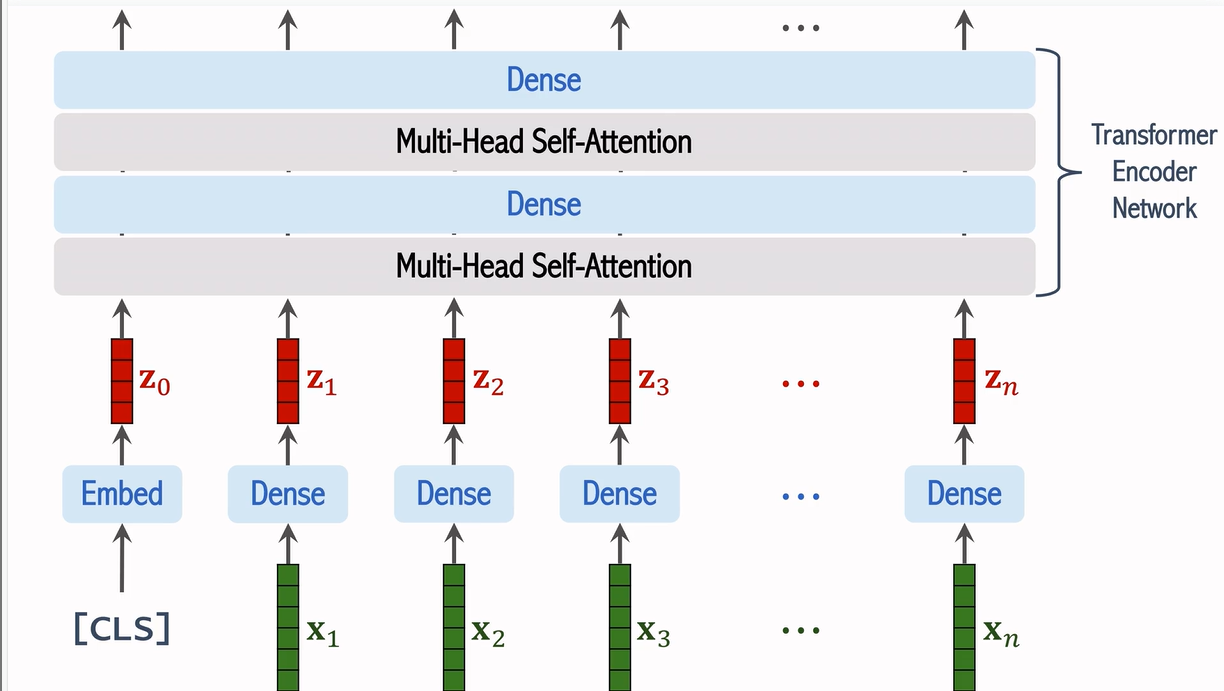
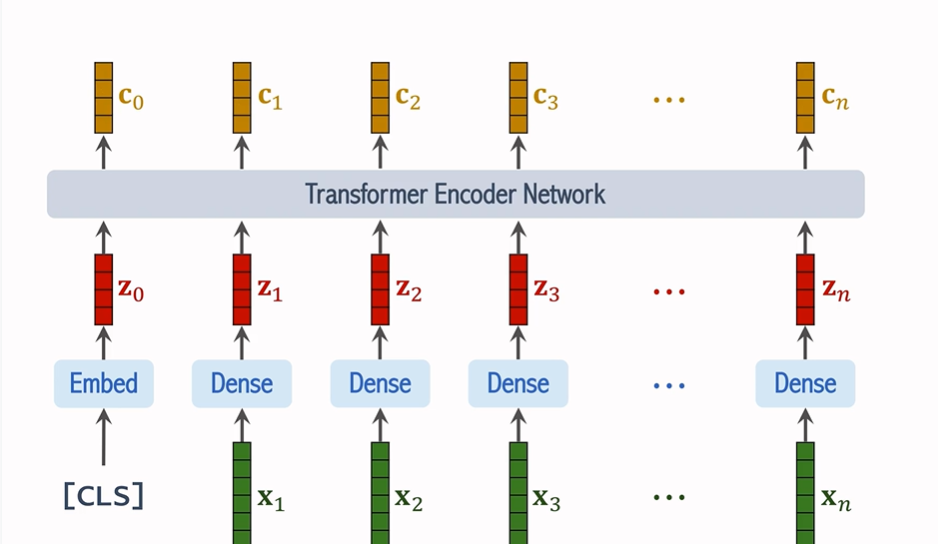
7. 分类与输出
经过多次的自注意力处理后,最终的 CLS Token 会被送入一个全连接层,该层输出一个包含所有类别概率的向量 p。通过与真实标签进行比较,ViT 利用交叉熵损失函数来计算误差,并通过梯度下降优化网络参数。
8. 训练过程:预训练与微调
ViT 的训练过程可以分为两个阶段:预训练和微调。
预训练(Pretraining)
预训练阶段是在一个大规模的数据集上进行的,通常会使用像 ImageNet 或 JFT-300M 这样的庞大数据集。这一阶段的目标是让模型学习到通用的视觉特征。通常,预训练时使用的模型参数是随机初始化的,随着训练的进行,模型不断优化,学习到有用的图像特征。
微调(Fine-tuning)
预训练完成后,模型会在较小的任务特定数据集(如 CIFAR-10、ADE20K 等)上进行微调。通过在这些特定任务上继续训练,模型能够调整参数,以适应特定的应用场景。
ViT 与 ResNet 的比较
传统的卷积神经网络,如 ResNet,依靠卷积层通过局部感受野捕捉图像特征。而 ViT 的核心优势在于 Transformer 的自注意力机制。自注意力机制允许模型在处理每个图像块时,能够关注到其他位置的信息,因此能够捕捉更远距离的图像依赖。
当在大规模数据集上预训练时,ViT 展现出比 ResNet 更好的性能,尤其是在较大的数据集上。随着数据集规模的扩大,ViT 的优势变得更加明显。
为什么 ViT 在大数据集上效果更好?
-
全局依赖建模: ViT 的自注意力机制允许它同时关注整个图像,而不像 CNN 那样依赖局部卷积操作。这样,ViT 可以捕捉到更多的全局信息,对于大数据集的图像分析更具优势。
-
更强的表示能力: 由于 ViT 处理的是图像块的向量表示,因此它的表示能力比 CNN 更强,特别是在任务复杂或者图像间关系较远的场景下。
-
更好的扩展性: Transformer 的设计使得它能够轻松地扩展到更大的数据集和更复杂的任务上,尤其是当计算资源足够时。
总结
Vision Transformer(ViT)是计算机视觉领域的一项创新,它将 Transformer 模型从自然语言处理应用扩展到了图像处理任务。通过将图像分块、向量化、加位置编码,再通过 Transformer 编码器进行处理,ViT 能够有效地提取图像中的全局特征,并在大规模数据集上展现出超越传统卷积神经网络(如 ResNet)的性能。
尽管 ViT 在计算上要求较高,尤其是需要大量数据来训练,但在预训练后,它在图像分类、目标检测等任务中提供了显著的提升。随着大数据集和计算能力的不断提升,ViT 很可能成为未来计算机视觉领域的主流方法之一。