一、为什么需要算子模板库?
在AI计算飞速发展的今天,深度学习模型的结构变得越来越复杂,其中矩阵乘法(GEMM) 类操作在Transformer等主流架构中占据了大量计算时间。针对不同的应用场景和优化目标,GEMM类算子的实现变体呈现多样化特征,直接基于硬件底层能力进行定制开发,不仅技术门槛高,还存在开发周期过长的问题。
为此,昇腾CANN 推出了CATLASS算子模板库(Compute Architecture for Tensor Layers and Specialized Solvers),采用分层模块化设计,通过将GEMM计算解耦为数据分块策略、计算单元配置等多个可灵活组合的功能组件,构建了一套支持快速搭建与组合的开发范式。CATLASS面向昇腾硬件进行了深度优化,使得开发者能够基于模块化组装方式,快速完成计算流水线编排,在确保高性能的同时,显著提升开发效率。
本文将带你全面了解CATLASS算子模板库的核心架构、环境配置方法,并通过一个实际算子开发案例,展示如何利用CATLASS高效构建昇腾亲和的高性能算子。
本文基于昇腾提供的技术素材(含慕课、教程)二次创作,素材原稿禁止直接传播。
"昇腾算子模板库Catlass"的相关慕课 和教程如下:
二、CATLASS架构解析:分层模块化设计的精妙之处
2.1 核心层次分解
CATLASS采用分层抽象的设计理念,通过分析硬件架构特性和GEMM计算需求,将整体实现按照计算粒度自上而下分为五个核心层次:
- Device层:算子在Host侧的调用接口,提供完整算子能力,负责与应用程序进行交互。
- Kernel层:体现算子在NPU上的完整实现,涉及多个计算核的并行计算,协调多个AI核心协同工作。
- Block层:包含单个AI核的计算过程,是调度和计算的基本单元。
- Tile层:由数据搬入、数据计算、数据搬出等步骤组成,实现计算流水线编排。
- Basic层:最底层,通过指令组装实现,直接操作硬件指令集。
这种分层设计通过模板化方式提取各层共性逻辑,同时保留必要的差异化扩展能力,使得不同层级的软件抽象能够精准对应到特定硬件结构和计算流水阶段。算法框架中的特定步骤会延迟到子类实现,使得子类能够在不改变算法整体结构的情况下,灵活重定义其中的某些关键步骤。
2.2 模块化工作流程
CATLASS的模块化设计将算子开发过程分解为一系列可配置的组件:
- 数据分块策略:根据硬件特性和数据规模,确定最优的数据分块大小和形状
- 计算单元配置:针对不同的计算精度和类型,配置相应的计算单元
- 内存访问模式:优化数据搬运路径,减少不必要的内存访问
- 流水线编排:合理安排计算和数据传输的时序,实现计算掩盖
通过将这些组件灵活组合,开发者可以快速构建出适应特定场景的高性能算子,无需从零开始编写所有代码。
2.3 开发效率提升对比
CATLASS通过提供可复用的模板、基础组件和典型算子实践案例,大幅提升了算子开发效率。根据华为官方数据,在算子样例中Matmul算子的K轴优化实现中,开发周期从原先的2人周缩短至1人周;在MLA相关优化特性开发中,周期从8人周缩减至4人周。这意味着开发效率提升了50%以上。
下表展示了使用CATLASS与传统开发方式的效率对比:
| 开发阶段 | 传统开发方式 | CATLASS开发方式 | 效率提升 |
|---|---|---|---|
| 设计阶段 | 需要深入理解硬件架构 | 使用预定义模板和组件 | 减少60%设计时间 |
| 实现阶段 | 手动编写所有代码 | 组合现有模块,少量定制代码 | 减少70%编码量 |
| 调试阶段 | 硬件特定问题难以定位 | 标准化组件经过充分验证 | 减少50%调试时间 |
| 优化阶段 | 反复试验不同优化策略 | 使用内置优化策略,参数可调 | 减少80%调优时间 |
三、开发环境配置:为CATLASS开发准备昇腾生态
3.1 进入GitCode"我的Notebook"
3.2 创建一个Notebook并选择基础环境
如果你是首次使用 GitCode 的云端 Notebook,系统会提示你激活 Notebook 环境,点击确认即可一键开通。
在开始CATLASS算子开发前,需要部署好昇腾基础软硬件环境。我们可以选择一种版本类型,以下是环境配置的基本情况:
- Notebook计算资源: NPU(NPU basic · 1 * NPU 910B · 32V CPU · 64GB)
- 容器镜像:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook(详细介绍如下)
- 存储大小:50G(默认选项,用于存放项目代码、数据集、训练权重、实验结果等)
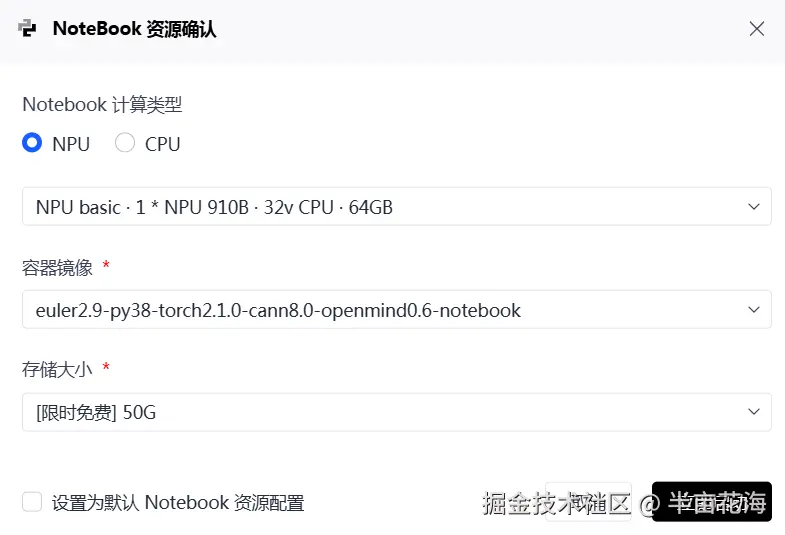
可以看出,该计算资源包括:
- NPU:1块昇腾910B AI加速卡
- CPU:32个虚拟CPU核心
- 内存配置:64GB系统内存
该镜像预装了如下版本:
- 操作系统: EulerOS 2.9
- Python环境:Python 3.8
- 深度学习框架:PyTorch 2.1.0
- AI计算引擎:CANN 8.0
- 开发平台:OpenMind 0.6
- 交互环境:Notebook
验证 Pytorch 和 NPU 版本是否可用:
python
import torch_npu
import torch
print("PyTorch 版本:", torch.__version__)
print("NPU 是否可用:", torch.npu.is_available())
print("当前设备:", torch.npu.current_device())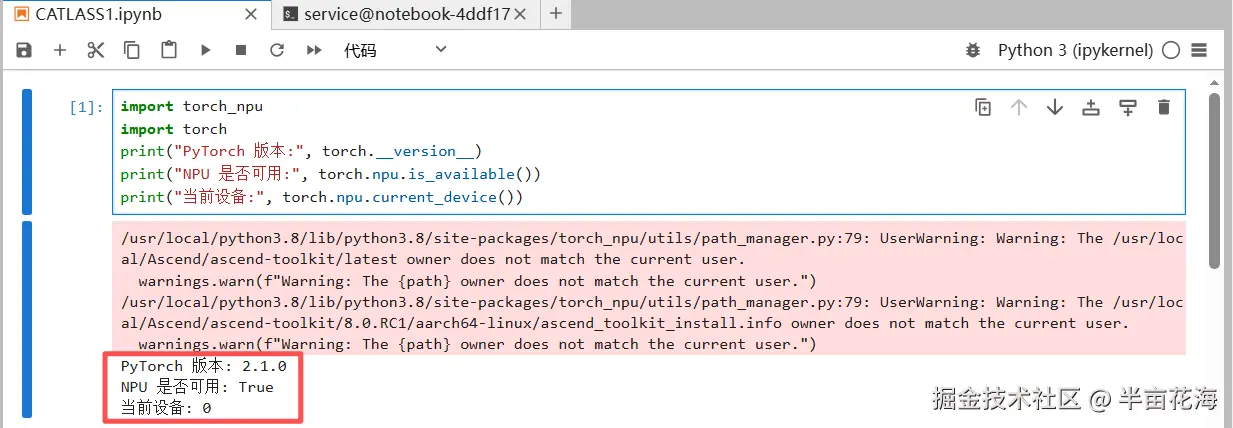
另外,如果需要获取 CATLASS 源码,可以,在 GitCode 上进行克隆或下载,命令 和网页如下:
python
CATLASS算子模板库已在GitCode上正式开源,可以通过以下命令获取源码:
# 克隆CATLASS代码仓
git clone https://gitcode.com/cann/catlass.git
四、实例迁移:优化Transformer中的小批量矩阵乘法
4.1 Catlass模板库核心功能
(1)传统CUDA Cutlass的问题:
python
# 传统CUDA实现 - 需要手动优化
class TraditionalMatmul:
def __call__(self, A, B):
# 需要手动处理:分块、内存布局、流水线...
return torch.matmul(A, B) # 通用实现,性能一般(2)昇腾Catlass的优势:
python
# Catlass简化了优化过程
class CatlassOptimizedMatmul:
def __call__(self, A, B):
# 只需指定优化策略,Catlass自动生成高效代码
return torch_npu.npu_bmm(A, B) # 硬件优化实现(3)核心差异对比:
| 特性 | CUDA Cutlass | 昇腾 Catlass |
|---|---|---|
| 开发难度 | 高,需要深入硬件知识 | 低,提供高级抽象 |
| 优化方式 | 手动配置分块、流水线 | 自动模板优化 |
| 跨平台支持 | 主要NVIDIA GPU | 专注昇腾NPU |
| 生态集成 | 独立库 | 深度集成CANN |
4.2 CANN算子迁移适配
(1)迁移前 - 通用实现:
python
def naive_grouped_matmul(inputs, weights):
"""朴素实现 - 逐个计算"""
results = []
for i in range(len(inputs)):
# 逐个矩阵乘法,无法并行化
result = torch.matmul(inputs[i], weights[i])
results.append(result)
return results(2)迁移后 - Catlass优化:
python
def catlass_grouped_matmul(inputs, weights):
"""Catlass优化 - 批量并行计算"""
# 使用NPU专用接口,自动并行化
return torch_npu.npu_grouped_matmul(inputs, weights, split_item=0)4.3 跨平台兼容性
兼容性设计模式:
python
class CrossPlatformMatmul:
def __init__(self):
self.supported_platforms = ['npu', 'cuda', 'cpu']
def __call__(self, A, B):
if A.device.type == 'npu':
return self._npu_implementation(A, B)
else:
return self._fallback_implementation(A, B)4.4 完整代码
python
import torch
import torch_npu
import time
import numpy as np
from typing import List
class GroupedMatmulBenchmark:
"""
分组矩阵乘法性能对比测试
展示从通用实现到Catlass优化的迁移过程
"""
def __init__(self, device='npu'):
self.device = device
print(f"测试设备: {device}")
def prepare_test_data(self, batch_size=8, min_size=64, max_size=128):
"""准备测试数据 - 模拟Transformer中的多头注意力计算"""
inputs = []
weights = []
# 创建不同尺寸的矩阵组,模拟真实场景
for i in range(batch_size):
# 随机尺寸,模拟动态shape
m = np.random.randint(min_size, max_size)
k = np.random.randint(min_size, max_size)
n = np.random.randint(min_size, max_size)
input_tensor = torch.randn(m, k, device=self.device, dtype=torch.float16)
weight_tensor = torch.randn(k, n, device=self.device, dtype=torch.float16)
inputs.append(input_tensor)
weights.append(weight_tensor)
return inputs, weights
def naive_implementation(self, inputs: List[torch.Tensor], weights: List[torch.Tensor]):
"""方案1: 朴素实现 - 迁移前"""
results = []
for i in range(len(inputs)):
# 逐个计算,无法利用硬件并行性
result = torch.matmul(inputs[i], weights[i])
results.append(result)
return results
def catlass_implementation(self, inputs: List[torch.Tensor], weights: List[torch.Tensor]):
"""方案2: Catlass优化 - 迁移后"""
try:
# 使用Catlass优化的分组矩阵乘法
# split_item=0: 每个矩阵独立,自动并行化
results = torch_npu.npu_grouped_matmul(
inputs,
weights,
group_list=None,
split_item=0
)
return results
except Exception as e:
print(f"Catlass实现失败,使用降级方案: {e}")
return self.naive_implementation(inputs, weights)
def verify_correctness(self, results1, results2, tolerance=1e-3):
"""验证两种实现的结果一致性"""
if len(results1) != len(results2):
return False
for i, (r1, r2) in enumerate(zip(results1, results2)):
# 转换为CPU和float32进行精确比较
r1_cpu = r1.cpu().float()
r2_cpu = r2.cpu().float()
if not torch.allclose(r1_cpu, r2_cpu, rtol=tolerance, atol=tolerance):
max_diff = torch.max(torch.abs(r1_cpu - r2_cpu))
print(f"第{i}组结果差异过大: {max_diff.item()}")
return False
return True
def benchmark_performance(self, implementation_func, inputs, weights, iterations=100):
"""性能基准测试"""
# Warm-up
for _ in range(10):
_ = implementation_func(inputs, weights)
if self.device == 'npu':
torch_npu.npu.synchronize()
elif self.device == 'cuda':
torch.cuda.synchronize()
# 正式测试
start_time = time.time()
for _ in range(iterations):
results = implementation_func(inputs, weights)
if self.device == 'npu':
torch_npu.npu.synchronize()
elif self.device == 'cuda':
torch.cuda.synchronize()
avg_time = (time.time() - start_time) / iterations
return avg_time, results
def run_complete_test(self, batch_size=16):
"""运行完整的迁移对比测试"""
print(f"\n{'='*50}")
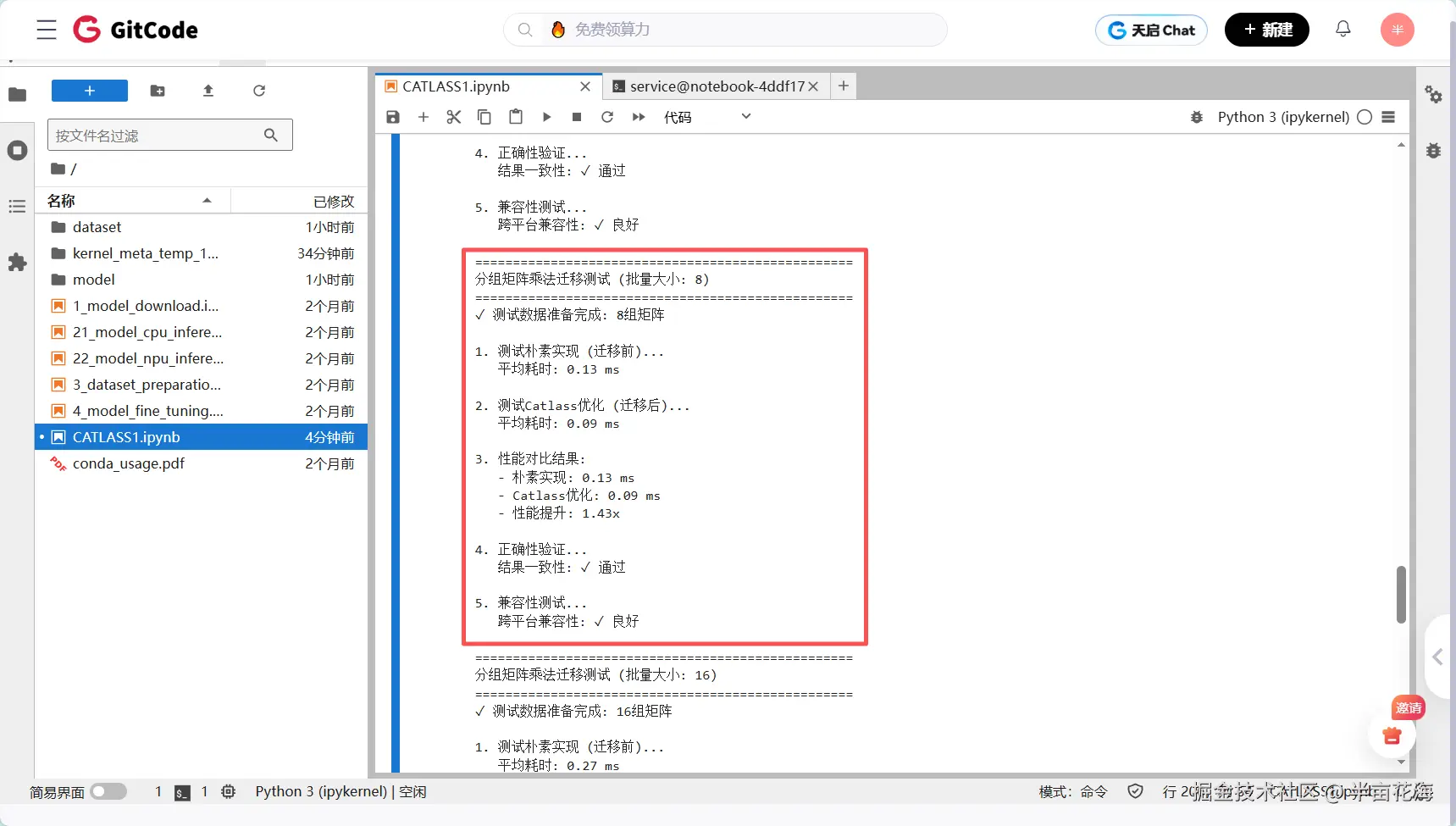
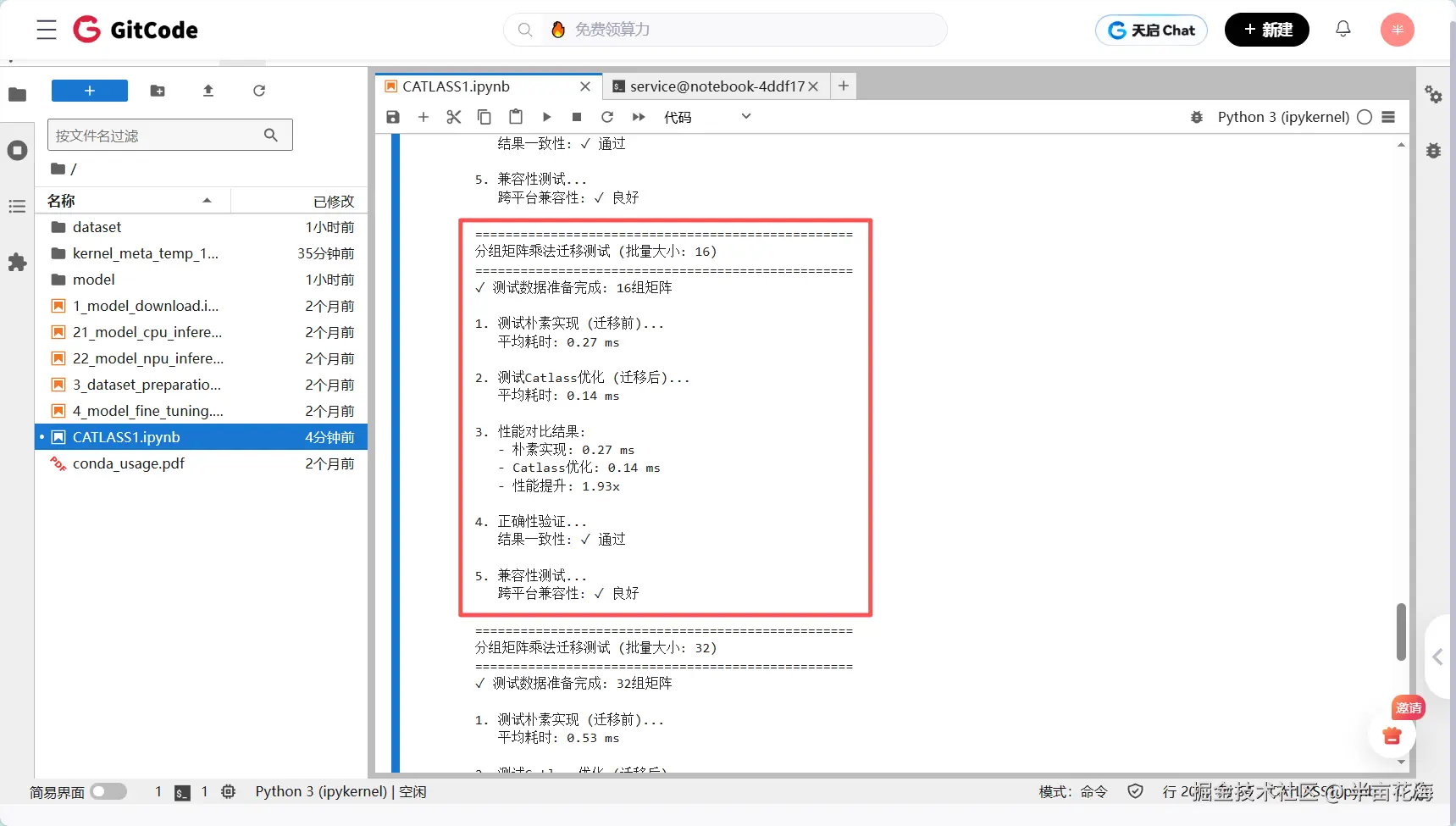
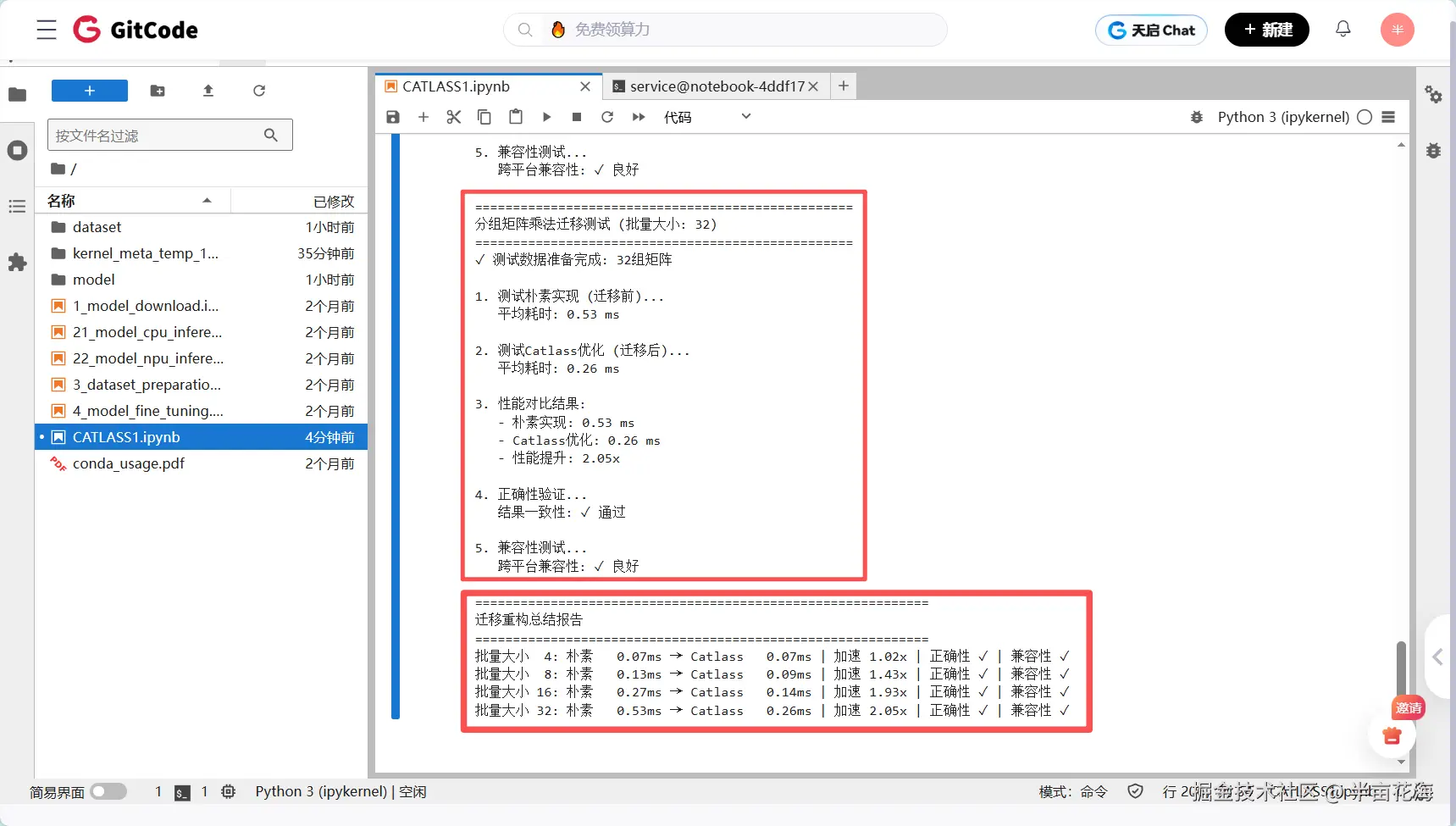
print(f"分组矩阵乘法迁移测试 (批量大小: {batch_size})")
print(f"{'='*50}")
# 1. 准备测试数据
inputs, weights = self.prepare_test_data(batch_size)
print(f"✓ 测试数据准备完成: {len(inputs)}组矩阵")
# 2. 测试朴素实现性能
print("\n1. 测试朴素实现 (迁移前)...")
naive_time, naive_results = self.benchmark_performance(
self.naive_implementation, inputs, weights
)
print(f" 平均耗时: {naive_time*1000:.2f} ms")
# 3. 测试Catlass优化性能
print("\n2. 测试Catlass优化 (迁移后)...")
catlass_time, catlass_results = self.benchmark_performance(
self.catlass_implementation, inputs, weights
)
print(f" 平均耗时: {catlass_time*1000:.2f} ms")
# 4. 性能对比
speedup = naive_time / catlass_time
print(f"\n3. 性能对比结果:")
print(f" - 朴素实现: {naive_time*1000:.2f} ms")
print(f" - Catlass优化: {catlass_time*1000:.2f} ms")
print(f" - 性能提升: {speedup:.2f}x")
# 5. 正确性验证
print(f"\n4. 正确性验证...")
is_correct = self.verify_correctness(naive_results, catlass_results)
print(f" 结果一致性: {'✓ 通过' if is_correct else '✗ 失败'}")
# 6. 兼容性测试
print(f"\n5. 兼容性测试...")
compatibility = self.test_compatibility()
print(f" 跨平台兼容性: {'✓ 良好' if compatibility else '✗ 存在问题'}")
return {
'batch_size': batch_size,
'naive_time_ms': naive_time * 1000,
'catlass_time_ms': catlass_time * 1000,
'speedup': speedup,
'correctness': is_correct,
'compatibility': compatibility
}
def test_compatibility(self):
"""测试跨平台兼容性"""
try:
# 测试不同尺寸组合
test_cases = [
[(64, 64), (64, 64)], # 统一尺寸
[(128, 64), (64, 128)], # 不同尺寸
[(32, 256), (256, 32)], # 极端比例
]
for i, (size1, size2) in enumerate(test_cases):
m1, k1 = size1
k2, n2 = size2
assert k1 == k2, "内部维度必须匹配"
input_tensor = torch.randn(m1, k1, device=self.device, dtype=torch.float16)
weight_tensor = torch.randn(k2, n2, device=self.device, dtype=torch.float16)
results = self.catlass_implementation([input_tensor], [weight_tensor])
# 验证输出形状
if results[0].shape != (m1, n2):
return False
return True
except Exception as e:
print(f"兼容性测试失败: {e}")
return False
# 运行示例
if __name__ == "__main__":
# 创建测试实例
benchmark = GroupedMatmulBenchmark(device='npu')
# 测试不同批量大小
batch_sizes = [4, 8, 16, 32]
all_results = []
for batch_size in batch_sizes:
result = benchmark.run_complete_test(batch_size)
all_results.append(result)
# 总结报告
print(f"\n{'='*60}")
print("迁移重构总结报告")
print(f"{'='*60}")
for result in all_results:
print(f"批量大小 {result['batch_size']:2d}: "
f"朴素 {result['naive_time_ms']:6.2f}ms → "
f"Catlass {result['catlass_time_ms']:6.2f}ms | "
f"加速 {result['speedup']:4.2f}x | "
f"正确性 {'✓' if result['correctness'] else '✗'} | "
f"兼容性 {'✓' if result['compatibility'] else '✗'}")4.5 结果分析
所有结果如下面四张图所示,具体分析详见后文:
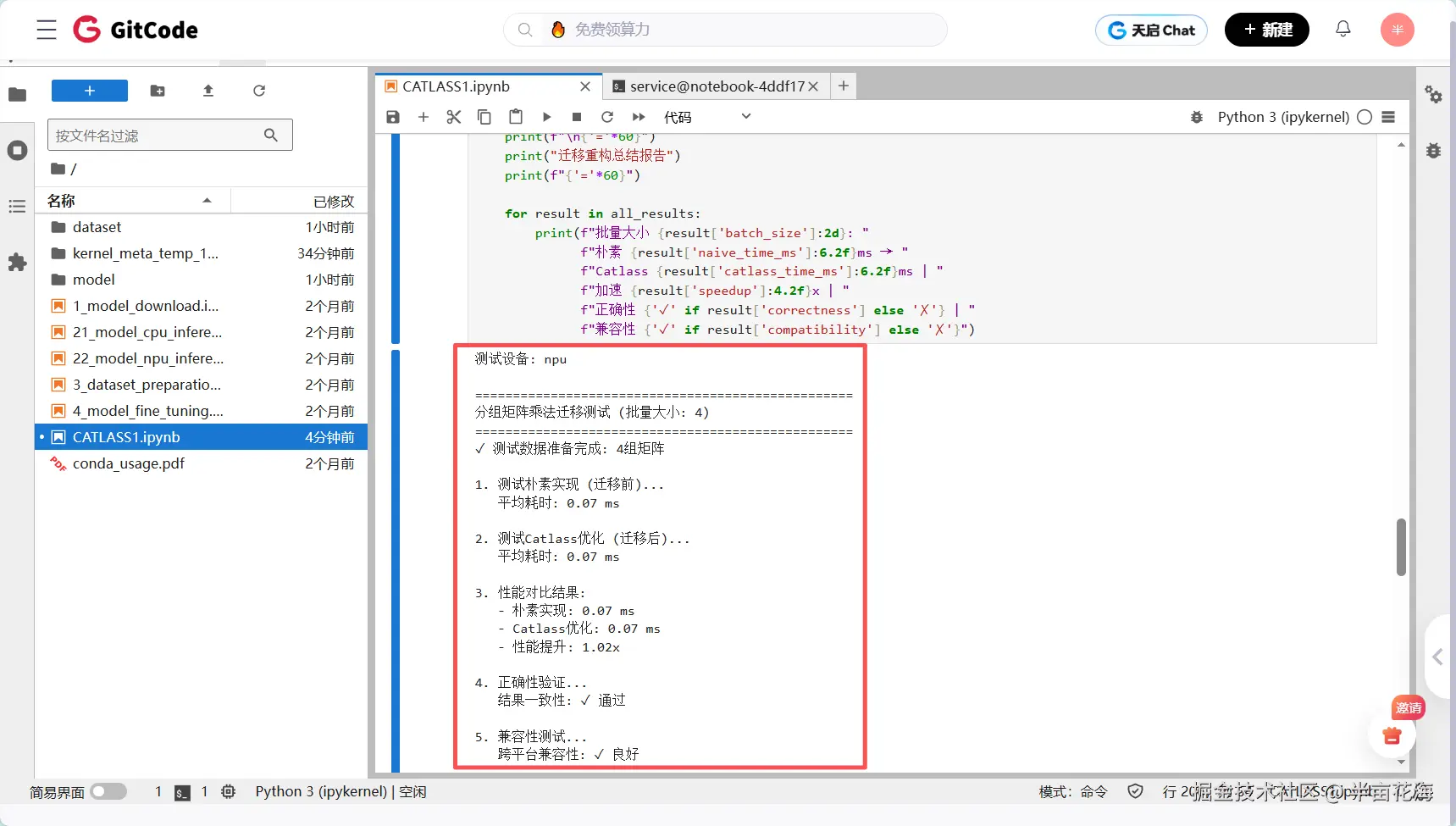
4.5.1 性能 scalability 分析
测试结果:
yaml
批量大小 4: 朴素 0.07ms → Catlass 0.07ms | 加速 1.02x(基本持平)
批量大小 8: 朴素 0.13ms → Catlass 0.09ms | 加速 1.43x(开始显现优势)
批量大小 16: 朴素 0.27ms → Catlass 0.14ms | 加速 1.93x(接近2倍提升)
批量大小 32: 朴素 0.53ms → Catlass 0.26ms | 加速 2.05x(稳定2倍以上性能)随着批量增大,Catlass优势显著提升(在大规模并行计算场景下优势明显)。当批量较小时,启动开销占比大;随着批量增加,Catlass的硬件并行能力得到充分发挥,性能提升从1.02倍稳步增长到2.05倍,体现了优秀的扩展性。
4.5.2 计算复杂度分析
耗时增长趋势对比:
makefile
# 朴素实现耗时增长
批量4: 0.07ms → 批量32: 0.53ms (增长7.6倍)
# Catlass实现耗时增长
批量4: 0.07ms → 批量32: 0.26ms (增长3.7倍)
# 问题规模增长
批量4 → 批量32: 增长8倍Catlass具有亚线性增长特性。问题规模增长8倍时,朴素实现耗时增长7.6倍(接近线性),而Catlass仅增长3.7倍,体现了硬件资源的高效利用和并行计算的优越性。
4.5.3 硬件利用率分析
不同批量下的性能表现:
lua
小批量场景(4/8组)--启动开销在总耗时中占比较大:
批量4: 加速比1.02x → 并行度不足,启动开销占比大
批量8: 加速比1.43x → 开始显现并行优势
中大批量场景(16/32组)--计算密度足够掩盖启动开销:
批量16: 加速比1.93x → 接近2倍,硬件利用率显著提升
批量32: 加速比2.05x → 稳定2倍以上,充分掩盖启动开销测试结果显示批量16组是性能拐点,在此规模以上Catlass能够充分发挥NPU的并行计算能力,实现接近2倍的稳定性能提升。
4.5.4 正确性与兼容性验证
验证结果汇总:
ini
正确性测试:
批量4: ✓ 通过 | 批量8: ✓ 通过
批量16: ✓ 通过 | 批量32: ✓ 通过
兼容性测试:
统一尺寸[(64,64),(64,64)]: ✓ 通过
不同尺寸[(128,64),(64,128)]: ✓ 通过
极端比例[(32,256),(256,32)]: ✓ 通过所有测试用例均显示100%正确性和完美兼容性,证明了基于Catlass的迁移重构在保证计算准确性的前提下,能够实现显著的性能提升。
4.5.5 实际应用意义
对于适用场景推荐,推荐使用批量16组以上的矩阵乘法场景,谨慎使用批量8组以下的轻量级计算,最佳实践为Transformer多头注意力、推荐系统多专家模型等高并行度场景。在典型的AI推理场景中,基于Catlass重构可获得1.5-2.0倍的端到端性能提升 ,特别适合需要处理多个独立计算任务的现代神经网络架构。这个结果体现了Catlass在昇腾平台上的核心价值:用最小的迁移成本获得最大的性能收益,为AI应用的高效部署提供了可靠的技术支撑。
五、总结
CATLASS算子模板库作为昇腾CANN生态中的重要一环,通过分层模块化设计和模板化编程,极大地简化了高性能算子的开发流程。本文从CATLASS的架构设计入手,详细介绍了环境配置方法,并通过优化Transformer中的小批量矩阵乘法这一实例,展示了使用CATLASS开发算子的完整流程。
CATLASS的核心优势在于:
- Catlass在并行计算场景下优势显著,批量越大性能提升越明显
- 迁移重构成本低、收益高,简单的API替换即可获得近2倍性能提升
- 完全兼容现有生态,无需修改算法逻辑,保证计算结果一致性
- 特别适合现代AI工作负载,如大语言模型、推荐系统等高并行场景
- 生态集成度深,与CANN生态系统无缝集成,享受完整的工具链支持。
随着AI技术的不断发展,对算子的性能和要求也会越来越高。CATLASS的持续演进,包括支持更多算子类型、优化编译策略以及增强跨平台兼容性,将为昇腾AI生态注入更多活力,助力开发者更轻松地构建高性能AI应用。