论文名称:SvANet: A Scale-variant Attention-based Network for Small Medical Object Segmentation
论文原文 (Paper) :https://arxiv.org/abs/2407.07720
代码 (code) :https://github.com/anthonyweidai/SvANet
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
- [3. 主要贡献点](#3. 主要贡献点)
- [4. 方法细节](#4. 方法细节)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验结果与分析 (Experiments & Analysis)](#6. 实验结果与分析 (Experiments & Analysis))
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
-
1. 核心思想
本文提出了一种名为 SvANet (Scale-variant Attention-based Network) 的新型网络,专门用于解决小尺寸医学对象 (Small Medical Object)的精确分割难题。其核心思想是,传统 CNN 在逐层下采样时会丢失小目标的细节信息(即"压缩缺陷")。SvANet 通过一套新颖的多尺度注意力机制 来对抗这种信息损失。它引入了 MCAttn(蒙特卡洛注意力) ,在一个模块内随机采样多尺度特征;并利用**SvAttn(尺度变化注意力)和跨尺度指导(Cross-scale Guidance)**来融合深层和浅层的特征。最后,它使用 **AssemFormer(一个 Conv-ViT 混合模块)**来结合局部空间层次和全局 inter-patch 表示,从而在多尺度上精确保留和增强小目标的特征。
2. 背景与动机
-
在临床诊断中,疾病的早期发现至关重要,而这通常表现为图像中的微小病变区域 (例如小于10mm的息肉或早期肿瘤)。然而,基于深度学习的分割算法,尤其是依赖卷积和池化操作的 CNN 架构(如 U-Net),在处理这类小尺寸对象 时面临一个根本性难题:信息丢失与压缩缺陷。
随着网络层数加深,特征图的分辨率不断降低,小目标所携带的本就稀少的像素和纹理信息很容易被"压缩"乃至完全"丢失",导致后续层无法识别或精确定位它们。现有的解决方案,如简单地放大输入图像(耗时)、调整损失函数或使用纯 ViT(缺乏归纳偏置),都不能完美解决这个问题。
因此,本文的动机是设计一个专门 的网络架构,其核心目标是在整个特征提取和解码过程中,主动地、持续地保护、增强和融合 那些极易丢失的小目标特征。
-
动机图解分析(Figure 2 & 3):
-
图表 A (Figure 2):揭示标准注意力的"语义鸿沟"问题
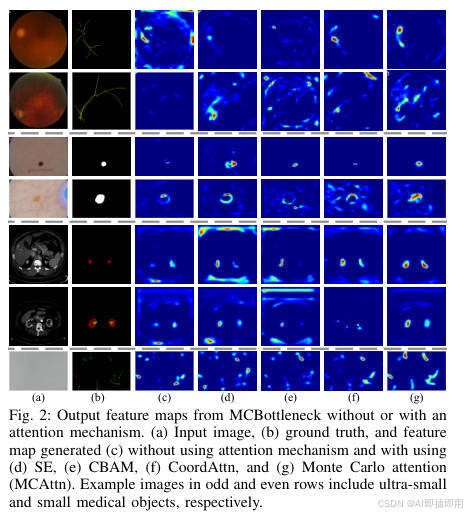
- "看图说话": 这张图展示了 SvANet 中
MCBottleneck模块的输出特征图,并对比了不使用注意力、使用标准注意力(SE, CBAM, CoordAttn)与使用本文MCAttn时的效果。 - 分析:
- © 不使用注意力: 特征图非常弥散,只能大致定位到高对比度区域,完全无法识别超小目标(如第一行的视网膜血管、第三行的皮肤病变、第七行的精子)。
- (d, e, f) 标准注意力 (SE, CBAM, CoordAttn): 它们表现稍好,能定位到"一般小"的目标(如第六行的肾脏肿瘤)。但是,对于"超小"或"稀疏"的目标(如第一行的血管、第七行的精子),它们同样失效了。它们倾向于关注目标的"簇",而不是稀疏的个体。
- (g) MCAttn (Ours): 效果立竿见影。特征图变得极其锐利和聚焦 。它不仅定位了肾脏,还精确地高亮了第一行的精细血管 、第三行的病变中心 以及第七行的单个精子。
- 结论: Figure 2 雄辩地证明了现有注意力机制在处理"超小"和"稀疏"目标时存在**"语义鸿沟"。它们擅长增强"区域"特征,却会 忽略**"个体"特征。而
MCAttn通过其多尺度随机池化,能同时捕捉到不同尺度的特征,从而解决了这个鸿沟。
- "看图说话": 这张图展示了 SvANet 中
-
图表 B (Figure 3):揭示特征融合的"效率瓶颈"问题
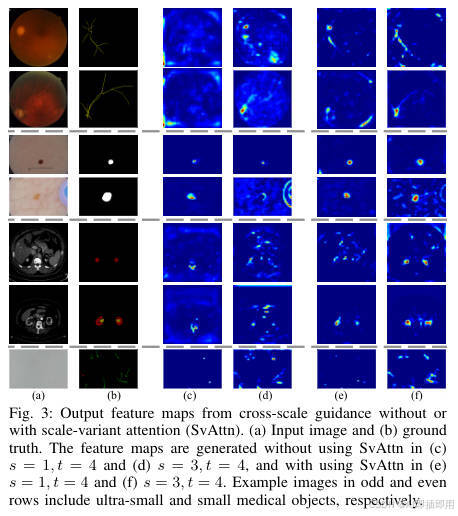
- "看图说话": 这张图展示了"跨尺度指导"(Cross-scale Guidance)模块在有无
SvAttn(尺度变化注意力)调节下的效果。 - 分析:
- (c, d) 不使用 SvAttn: 这代表了简单的特征融合(例如直接相加或拼接)。虽然高分辨率特征(来自浅层 s=1, s=3)被传递到了深层(t=4),但结果依然很糟糕。对于超小目标(奇数行),特征图几乎是全黑的 ,意味着信息丢失。
- (e, f) 使用 SvAttn: 在完全相同的设置下,仅加入了
SvAttn进行调节,特征图被瞬间"点亮"。第一行的血管、第三行的病变、第五行的肿瘤全部被清晰地识别出来。
- 结论: Figure 3 证明,简单的跨尺度特征"相加"是无效的 ,因为来自浅层的有用特征(小目标)被深层的无用特征(背景)所"淹没"。
SvAttn充当了一个智能"阀门" ,它在融合前对跨尺度特征进行动态加权 ,放大了来自浅层的小目标信号,抑制了噪声,从而解决了跨尺度融合的"效率瓶颈"问题。
- "看图说话": 这张图展示了"跨尺度指导"(Cross-scale Guidance)模块在有无
-
3. 主要贡献点
- 提出 SvANet 框架: 提出了一个专为分割超小 (<1% 图像面积)和小(<10% 图像面积)医学对象而设计的 U 型网络架构。该研究首次跨越 7 种不同的医学图像模态,系统性地解决了小目标分割问题。
- 发明 MCAttn (蒙特卡洛注意力): 创新地提出了一种随机注意力机制。与标准注意力(如 SE)使用固定的 1 × 1 1 \times 1 1×1 全局平均池化不同,MCAttn 在一个池化尺寸集合(如 1 × 1 , 2 × 2 , 3 × 3 1 \times 1, 2 \times 2, 3 \times 3 1×1,2×2,3×3)中随机采样一个尺寸来生成注意力图。这种"尺度不可知"的随机性迫使网络学习更鲁棒的特征,能同时捕捉到局部细节和全局上下文。
- 发明 SvAttn (尺度变化注意力): 提出了一种用于跨尺度特征融合 的新型注意力。当浅层(高分辨率)特征被传递到深层(低分辨率)时,SvAttn 会基于所有 可用尺度的特征图来动态计算融合权重,确保来自浅层的小目标高频信息能在深层被有效保留和利用。
- 提出 AssemFormer 模块: 设计了一个 CNN 和 ViT 的混合模块。它通过"堆叠"(Stacking)操作将 2D 特征图转换为 ViT 兼容的 1D 序列(Patches),利用 Transformer 捕捉全局长程依赖,然后再"解堆叠"(Unstacking)回 2D 图像特征。这使得模型能同时利用 CNN 的局部归纳偏置和 ViT 的全局视野。
4. 方法细节
-
整体网络架构(Figure 1):
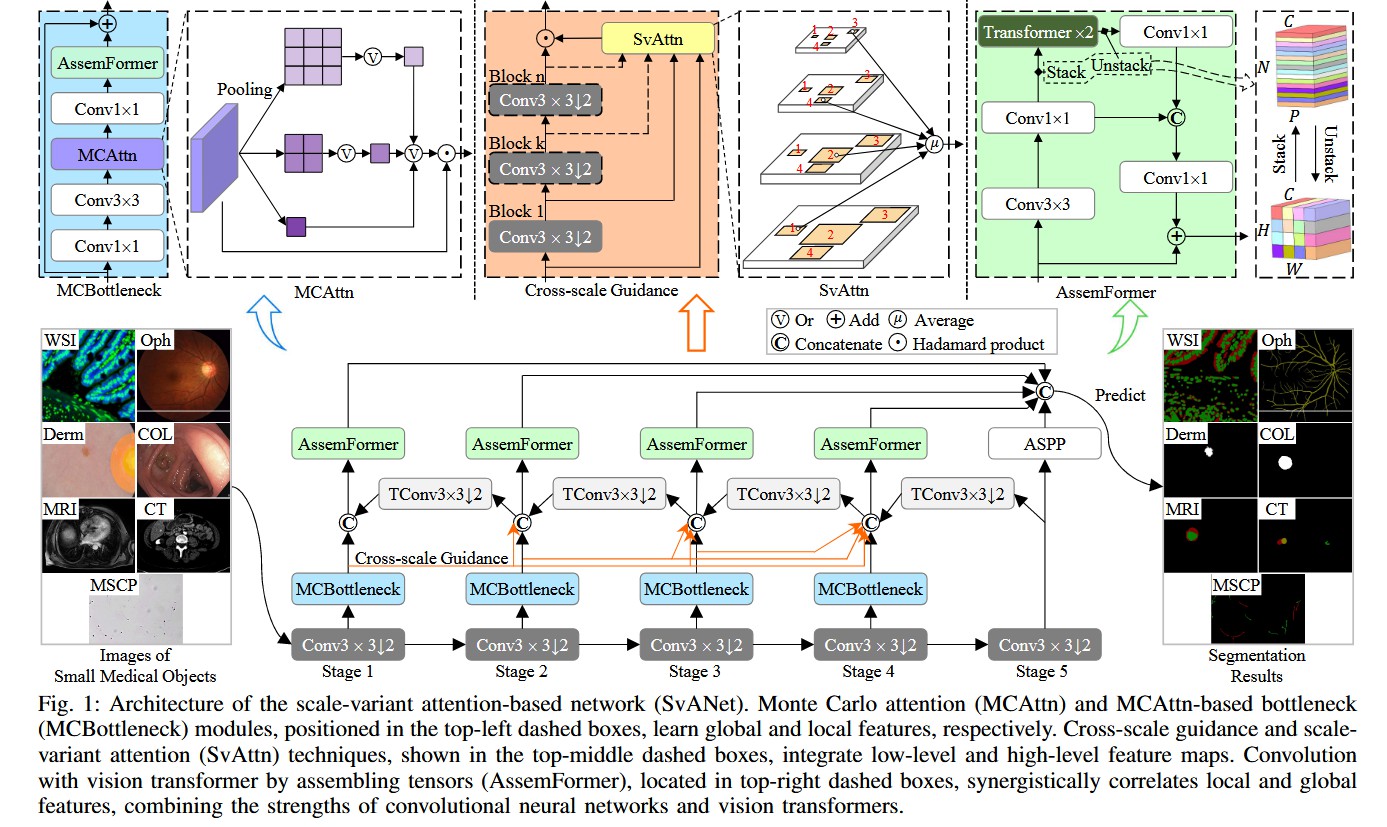
- 模型名称: SvANet
- 数据流: 这是一个高度定制化的 U-Net (编码器-解码器) 架构,其核心是多条、多层次的特征融合路径。
- 编码器 (Encoder Path): 位于图的最下层 (Stage 1 至 Stage 5)。它是一个 CNN 主干,由
Conv3x3(带步幅 2 的下采样卷积)和MCBottleneck模块(蓝色)串联组成。 - 解码器 (Decoder Path): 位于图的最上层 。它由
TConv3x3(转置卷积,用于上采样)和AssemFormer模块(绿色)串联组成。 - 主要跳跃连接 (Skip Connection): 解码器(上层)的每个
AssemFormer模块都会接收来自编码器(下层)对应阶段 的MCBottleneck模块的输出(通过灰色弯曲箭头),实现 U-Net 经典的长跳跃连接。 - 跨尺度指导 (Cross-scale Guidance Path): 这是第二条 特征路径,由橙色箭头 表示。它将浅层编码器 (如 Stage 1, 2, 3)的输出,通过一系列下采样(
Conv3x3块),直接"指导"深层解码器(如 Stage 4)的融合点。 - ASPP 模块: 在解码器的末端和最终预测(Predict)层之前,使用了一个 ASPP(Atrous Spatial Pyramid Pooling)模块,以在最终输出前再次捕获多尺度上下文。
- 输入/输出:
Images of Small Medical Objects→ \rightarrow →SvANet→ \rightarrow →Segmentation Results。
-
核心创新模块详解(Figure 1 顶部放大图):
-
对于 模块 A:MCAttn (蒙特卡洛注意力)
- 理念: 解决标准全局池化( 1 × 1 1 \times 1 1×1)丢失过多细节的问题。通过引入随机性,使注意力"尺度不可知"。
- 内部结构: 位于
MCBottleneck模块(蓝色虚线框)内部。 - 数据流(结合文本 Sec III-B):
- 输入特征图 x x x 进入
MCAttn模块(紫色虚线框)。 - 模块内部有 n n n 个(本文 n = 3 n=3 n=3)并行的平均池化(Average Pooling)层,它们具有不同的输出尺寸 (例如 3 × 3 , 2 × 2 , 1 × 1 3 \times 3, 2 \times 2, 1 \times 1 3×3,2×2,1×1)。
- 在每次前向传播 中(训练时),
MCAttn会随机选择(Monte Carlo sampling)其中一个 池化尺寸(例如 2 × 2 2 \times 2 2×2)来生成该次的注意力图。 - 这种随机性(如公式 1 所述, P 1 ( x , i ) P_1(x,i) P1(x,i) 概率保证一次只有一个 i i i 被选中)迫使网络不能依赖任何单一的固定尺度,必须学会在各种尺度下都能工作的鲁棒特征,这对尺寸多变的小目标至关重要。
- 输入特征图 x x x 进入
- 设计目的: 用随机多尺度池化 取代固定单尺度池化,极大增强了网络对不同尺寸(尤其是小尺寸)物体的特征捕捉能力。
-
对于 模块 B:SvAttn (尺度变化注意力) 与 跨尺度指导
- 理念: 解决深层网络丢失浅层高分辨率信息的问题。
- 内部结构: 位于"跨尺度指导"路径(橙色箭头)上,如黄色虚线框所示。
- 数据流(结合文本 Sec III-C, III-D):
Cross-scale Guidance(橙色箭头)是一个"特征传输管道"。它将浅层编码器(如 Stage 1)的输出 x s x_s xs,通过 t − s t-s t−s 次Conv3x3步进卷积(橙色小方块),下采样到与深层目标 t t t(如 Stage 4)相同的分辨率。SvAttn模块(黄色虚线框)收集所有被传输过来的浅层特征(来自 Stage 1, 2, 3)。- 它为这些不同尺度的特征动态地学习一个权重 (如公式 4 所述, P 2 ( x s , j ) P_2(x_{s,j}) P2(xs,j))。
- 最后,它输出这些特征的加权平均值 (如公式 6),并将其融合(
Concatenate或Add)到解码器的对应层。
- 设计目的:
SvAttn充当了一个智能的"特征调度员"。它让深层解码器(如 Stage 4)能够"回顾"所有浅层特征,并动态决定:"对于当前这个像素,来自 Stage 1 的高分辨率边缘信息最重要",从而精确地将小目标的细节信息从浅层"拉"到深层,防止其丢失。
-
对于 模块 C:AssemFormer (组装 Transformer)
- 理念: 结合 CNN 的局部特征提取能力和 ViT 的全局依赖建模能力。
- 内部结构: 位于解码器路径上,如绿色虚线框所示。
- 数据流:
- 输入特征(来自上采样和跳跃连接的融合)兵分两路。
- ViT 分支(上): 特征首先经过
Conv3x3和Conv1x1(CNN 编码) → \rightarrow →Stack操作(将 H × W × C H \times W \times C H×W×C 的特征图"堆叠"成 N × D N \times D N×D 的 Patches 序列) → \rightarrow → 经过 2 个Transformer块(捕捉全局关系) → \rightarrow →Unstack操作(将序列"解堆叠"回 H × W × C H \times W \times C H×W×C 特征图) → \rightarrow →Conv1x1。 - CNN 分支(下): 特征经过一个并行的
Conv1x1路径(作为残差连接)。 - 两个分支的输出通过
Unstack后的Conv1x1进行融合(图中显示为Conv1x1→ \rightarrow →Stack→ \rightarrow →Unstack→ \rightarrow →Conv1x1,然后与主Conv1x1融合)。
- 设计目的: 在解码器的每一步都同时使用 CNN 和 ViT。CNN 分支保留了精确的局部空间信息(对分割边界很重要),而 ViT 分支则负责理解图像的全局上下文(例如,识别出"这是一个肾脏"),两者结合实现了更鲁棒的分割。
-
-
理念与机制总结:
- SvANet 的核心哲学是通过多层次、多维度的特征冗余来对抗信息丢失。它认识到小目标特征是"脆弱的",因此设计了三重保护机制:
MCAttn(随机尺度注意力): 在编码器的每个阶段内部,通过随机池化保留特征。SvAttn(跨尺度注意力): 在编码器和解码器之间,通过加权融合,将浅层特征"护送"到深层。AssemFormer(混合注意力): 在解码器的每个阶段内部,通过 CNN 和 ViT 结合,同时处理局部和全局信息。
- 这种"三重保险"设计确保了无论小目标多么微小或稀疏,其特征信号都能在网络的多个路径中被捕捉、放大和传递,最终在输出端被精确重建。
-
图解总结:
- Figure 2 和 3 共同展示了问题 :标准注意力和标准跨尺度融合在面对超小目标时,其输出的特征图(c, d, e, f)是模糊、错误或完全空白的,导致信息丢失。
- Figure 1 展示了解决方案 :
MCAttn(图 2g)通过随机尺度采样,生成了清晰聚焦的局部特征图。SvAttn(图 3e, f)通过跨尺度加权,成功地将浅层特征传递到深层,解决了信息丢失问题。AssemFormer(图 1 右上角)则在解码时同时利用局部(CNN)和全局(ViT)信息,对这些特征进行最终的精炼。
- 整个 SvANet 架构(图 1 底部)就是将这三个创新的"保护模块"协同地部署在一个 U-Net 框架中,以实现对小目标的终极分割性能。
5. 即插即用模块的作用
-
本文的三个核心创新
MCAttn、SvAttn和AssemFormer均可作为即插即用的模块或模式。 -
MCAttn (蒙特卡洛注意力):
- 作用: 这是一个注意力模块 ,可直接替代 任何网络中的标准注意力块(如 SE、CBAM、CoordAttn)。
- 适用场景: 尤其适用于特征尺度变化巨大 或包含大量小目标 的任务(如遥感、医学影像)。当标准 1 × 1 1 \times 1 1×1 全局平均池化(GAP)会丢失过多信息时,MCAttn 的随机多尺度池化是更鲁棒的选择。
- 具体应用: 可将其插入到任何 CNN 架构(如 ResNet, EfficientNet, U-Net)的瓶颈层(Bottleneck)中,如本文的
MCBottleneck所示。
-
AssemFormer (组装 Transformer):
- 作用: 这是一个混合特征提取块 ,可替代 标准的
Transformer Block或CNN Block。 - 适用场景: 需要在同一网络层中同时利用 CNN 的局部归纳偏置和 ViT 的全局感受野的任务。
- 具体应用: 可用于替换 U-Net 解码器中的标准卷积块(如本文所示),或替换 ViT 架构中的标准 Transformer 层,为其补充强大的 CNN 局部特征提取能力。
- 作用: 这是一个混合特征提取块 ,可替代 标准的
-
SvAttn (尺度变化注意力) 与 跨尺度指导:
- 作用: 这是一种特征融合架构模式 ,用于改进多尺度网络(如 U-Net, FPN)。
- 适用场景: 任何深层网络中**深层特征(语义强但分辨率低)需要浅层特征(语义弱但分辨率高)**来辅助的任务,尤其是小目标检测和分割。
- 具体应用: 可将其应用于任何 U-Net 架构中,在标准的"长跳跃连接"之外,增加这种"跨尺度指导"路径,并使用
SvAttn模块来智能地融合这些跨尺度特征,防止深层特征"淹没"浅层细节。
6. 实验结果与分析 (Experiments & Analysis)
-
6.1 数据集与评估指标 为了验证SvANet的有效性,作者在 7个基准数据集(FIVES, ISIC 2018, PolypGen, ATLAS, KiTS23, TissueNet, SpermHealth)上进行了广泛测试 。这些数据集涵盖了眼底、皮肤镜、结肠镜、MRI、CT等多种模态,且重点关注面积占比小于1%(极小目标)和小于10%(小目标)的医学对象 。
-
6.2 定量对比:全面SOTA SvANet在所有测试数据集上均取得了最优性能,显著优于UNet、HRNet、TransNetR等7种现有SOTA方法 极小目标表现: 在极具挑战性的 SpermHealth(精子) 数据集(目标均<1%)上,SvANet达到了 72.58% 的mDice,比第二名高出 36.66% 。
鲁棒性: 在ATLAS(肝脏肿瘤)数据集中,SvANet在分割极小目标时取得了 89.79% 的mDice,展现了极强的微小特征捕捉能力 。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。