论文标题
Reward-SQL: Boosting Text-to-SQL via Stepwise Reasoning and Process-Supervised Rewards
论文地址
https://arxiv.org/pdf/2505.04671
代码地址
https://github.com/ruc-datalab/RewardSQL
作者背景
中国人民大学,香港科技大学广州,阿里云,清华大学
前言
CTE是大部分数据库系统都支持的SQL表达模式,这种模式恰好能作为过程奖励模型的构建依据,从而显著减轻了在Text-to-SQL任务上应用PRMs的标注难度
动机
在Text-to-SQL任务中,模型的推理能力至关重要,但实践中经常发现"推理链条越长,模型产生幻觉的风险就越高",即在复杂查询场景中引入无关或错误的步骤,会显著降低查询准确率。于是我们希望使用强化学习来来评估和监督生成结果,以提高推理准确性。
过程奖励模型(PRMs)能为训练过程提供细粒度的奖励信号,识别推理过程中的关键错误,或许能有效缓解上述问题。然而,在Text-to-SQL任务中有效利用PRMs并非易事,一方面需要构建适合Text-to-SQL任务的中间推理步骤,并设计能准确评估这些步骤的PRM;另一方面,要探索如何将PRM最优地整合到训练和推理流程中,以最大化其指导效果,同时确保模型能发展出真正的SQL推理能力,而不是仅仅优化奖励信号
于是作者设计了一套应用于Text-to-SQL任务的PRMs方法,并探索了多种训练与推理范式
本文方法
本文提出REWARD-SQL框架,其核心在于引入链式公共表表达式(Chain-of-CTEs, COCTE)作为中间推理步骤,并设计相应的PRM来评估这些步骤。
一、COCTE介绍
COCTE将复杂的SQL查询分解为一系列公共表表达式(CTEs),每个CTE代表一个独立的推理步骤,最终通过这些CTE构建出完整的SQL查询。CTE是SQL查询中定义的临时命名结果集,使复杂查询更易于管理和阅读。COCTE的优势在于提供可解释性和灵活性,每个CTE产生一个具体的、可执行的中间结果,并且COCTE形成一个有向无环图,每个步骤可以引用任何前面的步骤
简单来说就是要求生成的SQL都按照以下形式书写:
sql
WITH step1 AS (
-- 第一步的查询逻辑
),
step2 AS (
-- 基于step1结果的第二步查询逻辑
),
step3 AS (
-- 基于step2的第三步查询逻辑
)
SELECT*FROM step3;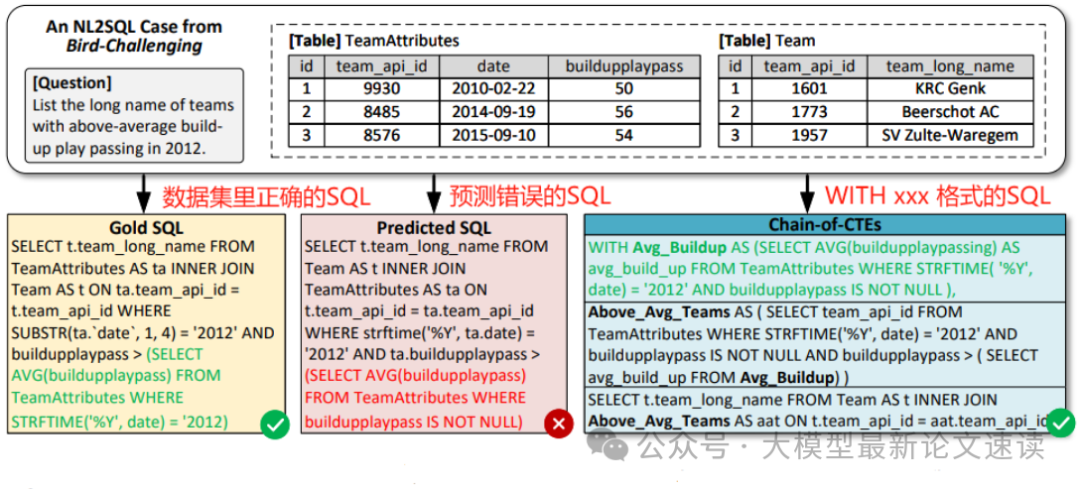
二、模型初始化
- 策略模型冷启动
在BIRD训练集上,手动编写一些COCTEs示例,提示强模型将其他SQL语句转换为COCTEs;然后执行这些COCTEs并保留与原始SQL结果一致的样本;此外还使用SQL语法树编辑距离过滤语义相似的样本,确保数据多样性。然后通过SFT训练开源模型,使之具备基本的SQL能力 - 过程奖励模型训练
通过蒙特卡洛树搜索(MCTS)算法探索多样化的推理路径,并标记每个步骤的正确性。使用二元交叉熵损失函数训练PRM,使其能够准确评估每个CTE步骤的正确性

三、优化策略
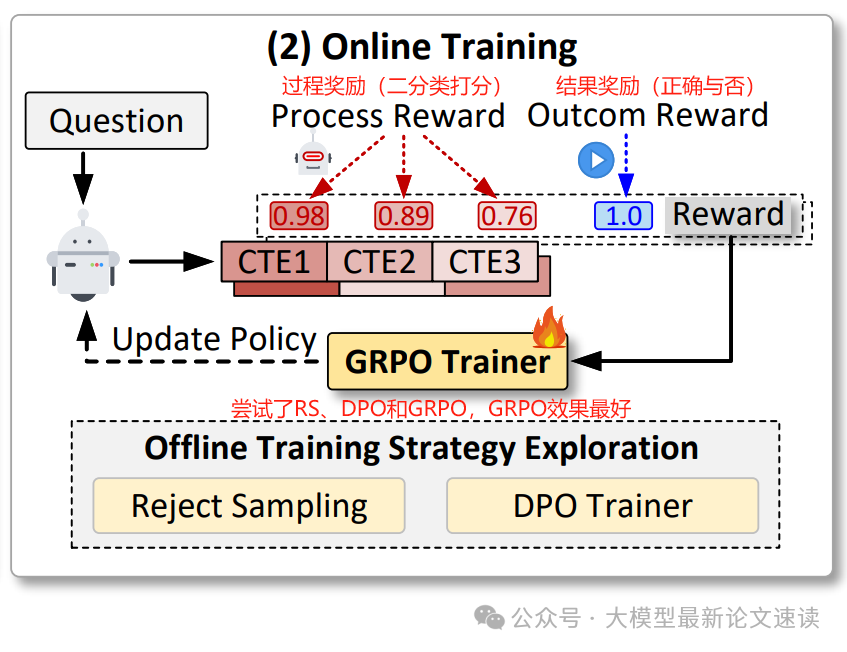
- 奖励设计: 训练时同时使用过程奖励和结果奖励
- 离线训练方法:
- 拒绝采样(RS): 生成多个COCTEs,根据PR和OR分数过滤,保留高分样本进行微调
- 直接偏好优化(DPO): 利用样本之间的比较信息,通过Bradley-Terry偏好模型优化策略
- 在线训练方法 : 分组相对策略优化(GRPO)在线更新策略模型,利用PRM的步骤级分数指导策略更新,通过分组相对优势减少方差和计算负担
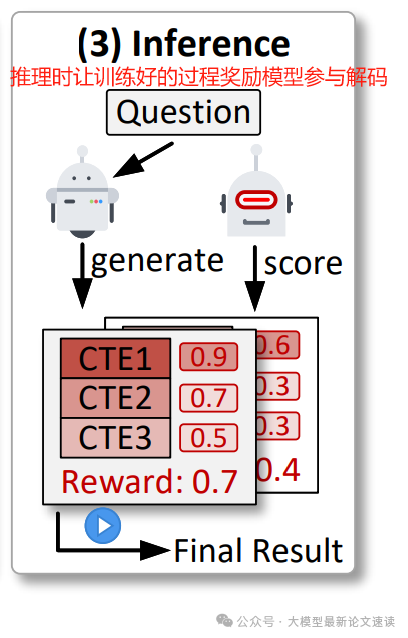
- 推理时奖励辅助 : 在推理过程中也让奖励模型参与决策:让模型生成多个候选COCTEs,使用PRM选择得分最高的候选作为最终输出
上述RS、DPO、GRPO以及推理时奖励辅助刚好对应了四种典型的奖励信号处理方式,如下图所示:
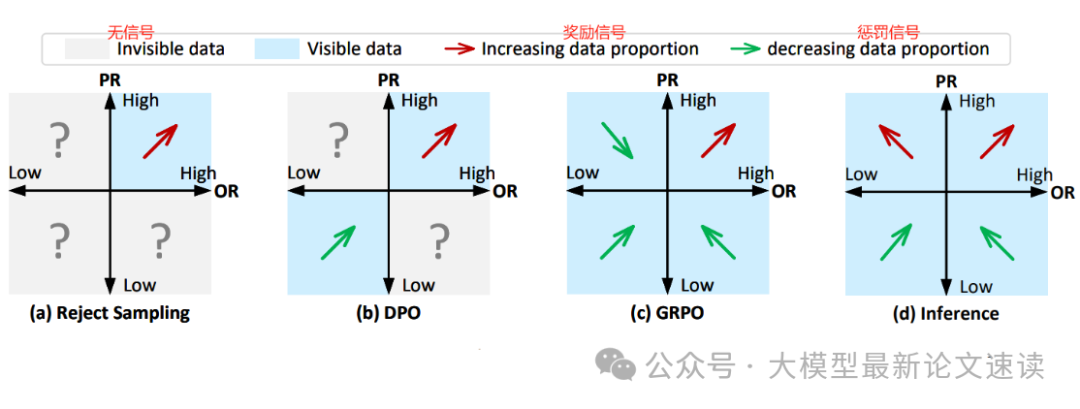
- RS:仅针对过程正确且结果正确的样本进行奖励
- DPO:奖励过程、结果都正确的样本,惩罚过程、结果都错误的样本
- GRPO:奖励过程、结果都正确的样本,惩罚其他所有样本。其中,【过程正确但结果错误】表明推理链条中存在隐蔽的逻辑缺陷,为了提高大模型推理能力所以需要惩罚;【过程错误但结果正确】表明模型可能依靠巧合,或者数据集偏差蒙对了答案,需要进行较严厉的惩罚
- 推理时奖励辅助:与GRPO训练策略不同,推理时模型已经学习完毕,不用再惩罚【过程正确但结果错误】,但为了提高输出质量,发生这种情况时应当酌情奖励
实验结果
一、各优化策略对比
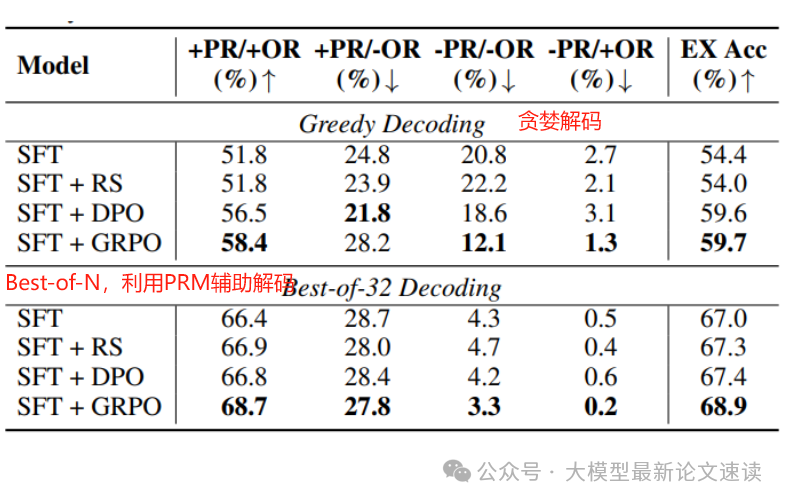
表中的SFT表示仅经过冷启动阶段训练的开源模型。作者表示也尝试了将后续RL阶段所使用的数据加入训练,但效果很差;
实验结果表明通过GRPO能够实现最好的性能,并且在解码阶段引入过程奖励模型从Best-of-N中进行挑选,效果能再提升近10个点
二、与各SOTA模型对比
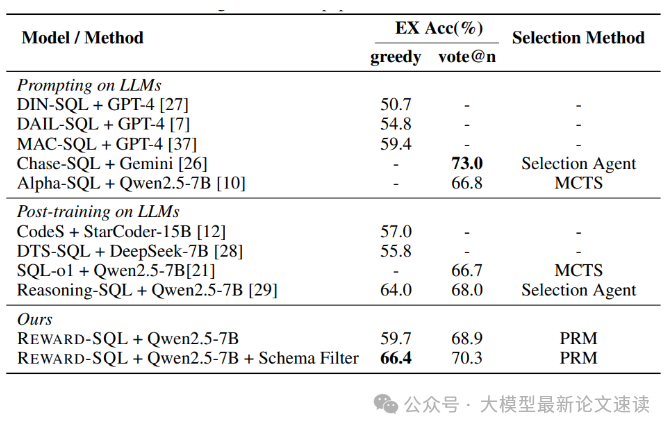
在贪婪解码下,REWARD-SQL优于多个基于更大模型(如GPT-4)的基线方法;在投票解码下,REWARD-SQL进一步超越了所有基线方法,包括Reasoning-SQL,即使在不使用模式过滤器的情况下,REWARD-SQL的表现依然出色;结合模式过滤器后,REWARD-SQL在贪婪解码和投票解码下的执行准确率又得到了进一步提升
模式过滤(Schema Filter)是一种精简上下文,提高模型的专注度和效率的方法
实现过程:
类似于RAG,首先分析用户query,然后计算各种数据库Schema表述与query之间的相似度,只保留与query相关的放入上下文