机器学习(Machine Learning)
简要声明
基于吴恩达教授(Andrew Ng)课程视频
BiliBili课程资源
文章目录
- [机器学习(Machine Learning)](#机器学习(Machine Learning))
- 解决过拟合问题
解决过拟合问题
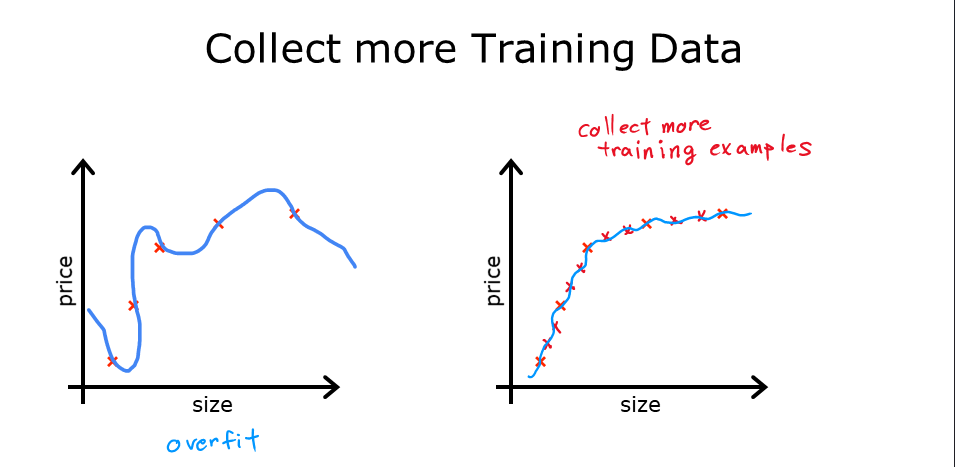
一、收集更多训练数据
增加训练数据量是解决过拟合的一种有效方法。更多的数据可以帮助模型学习到更通用的模式,减少过拟合的风险。
- 原理:更多的训练样本可以提供更全面的信息,使模型更好地泛化。
- 示例:如果模型在有限的房屋价格数据上过拟合,增加更多不同大小、价格的房屋数据可以使模型更准确地预测新数据。
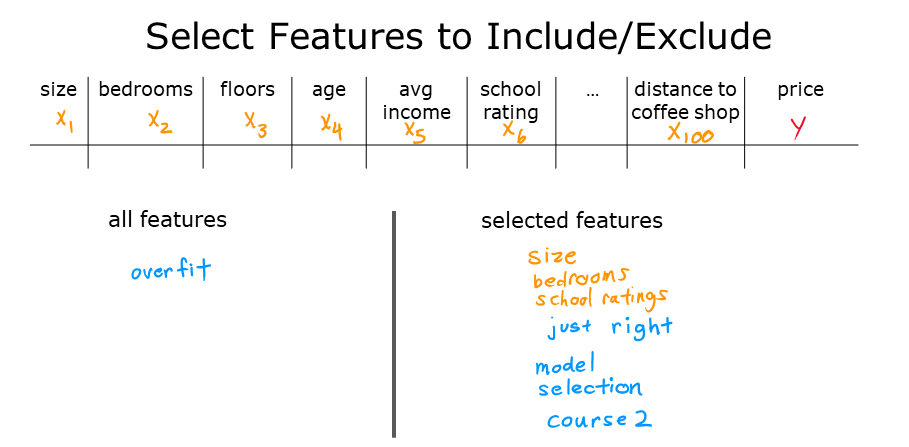
二、选择特征
选择合适的特征可以减少模型的复杂度,从而降低过拟合的可能性。
- 特征选择:从众多特征中选择最相关的特征,去除无关或冗余的特征。
- 优点:减少模型复杂度,提高训练速度。
- 缺点:可能丢失一些有用的信息。
| 特征选择方法 | 说明 |
|---|---|
| Filter Methods | 通过相关性分析等方法预选特征 |
| Wrapper Methods | 通过模型性能评估选择特征组合 |
| Embedded Methods | 在模型训练过程中自动选择特征 |
三、正则化
正则化是一种通过在损失函数中添加惩罚项来限制模型复杂度的方法。
- L1正则化 :添加参数的绝对值之和。公式为: λ ∑ j = 1 n ∣ w j ∣ \lambda \sum_{j=1}^{n} |w_j| λj=1∑n∣wj∣
- L2正则化 :添加参数的平方和。公式为: λ ∑ j = 1 n w j 2 \lambda \sum_{j=1}^{n} w_j^2 λj=1∑nwj2
- 作用:使参数值更小,减少模型对单个特征的依赖。
| 正则化方法 | 优点 | 缺点 |
|---|---|---|
| L1正则化 | 可进行特征选择,稀疏性好 | 收敛速度较慢 |
| L2正则化 | 收敛速度快,稳定性好 | 无法进行特征选择 |
四、过拟合解决方法总结
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 收集更多数据 | 训练数据量不足时 | 提高模型泛化能力 | 数据收集成本高 |
| 特征选择 | 特征数量多且存在冗余特征时 | 减少模型复杂度,提高训练速度 | 可能丢失有用信息 |
| 正则化 | 模型参数量大,容易过拟合时 | 有效控制模型复杂度,提高泛化能力 | 需要调整正则化参数 |
| 交叉验证 | 数据集有限,需要充分利用数据进行模型评估时 | 减少数据浪费,提高模型评估准确性 | 计算成本高 |
| 早停 | 模型训练时间长,容易过拟合时 | 防止模型在训练集上过优化,保存较好的泛化能力 | 需要确定合适的停止点 |
continue...