
-
作者: Zechuan Li, Hongshan Yu, Yihao Ding, Yan Li, Yong He, Naveed Akhtar
-
单位:湖南大学,墨尔本大学,悉尼大学,安徽大学
-
论文标题:Embodied Intelligence for 3D Understanding: A Survey on 3D Scene Question Answering
主要贡献
-
首次全面综述:这是首篇对3D SQA领域进行系统性回顾的综述论文,涵盖了数据集、方法论和评估指标。
-
数据集与方法论的系统分类:对现有的3D SQA数据集和方法进行了详细的分类和比较,总结了它们的特点、优势和局限性。
-
挑战与机遇分析:深入分析了当前3D SQA领域面临的主要挑战,如数据集标准化、多模态融合和任务设计,并提出了未来的研究方向。
-
评估指标的讨论:探讨了传统评估指标和基于大模型(LLM)的评估指标的优缺点,并提出了结合两者的优势以构建更全面的评估框架。
介绍
研究背景与动机
-
传统视觉问答(VQA)的局限性
- 传统VQA主要结合视觉内容(如图像)与文本问答,但仅限于二维图像的理解,难以满足对复杂三维环境的交互需求。
-
3D场景问答(3D SQA)的兴起
-
3D SQA通过整合视觉感知、空间推理和语言理解,使智能体能够在三维环境中进行复杂推理。例如,它可以帮助机器人在室内环境中根据自然语言指令找到特定物体,或者在虚拟环境中为用户提供交互式的信息查询服务。
-
3D SQA推动了多模态人工智能的发展,为机器人技术、增强现实和自主导航等领域提供了新的可能性。
-
研究现状与挑战
-
数据集和方法的快速发展
- 近年来,随着大视觉 - 语言模型(LVLM)的发展,3D SQA领域出现了多种数据集,如ScanQA、SQA等,并发展出了指令微调和零样本学习方法。
-
面临的挑战
-
数据集之间的差异较大,缺乏统一的分析和比较标准。例如,不同的数据集在场景表示(点云、多视角图像等)、查询复杂性(从简单的文本到复杂的多模态查询)和任务类型(从基础的对象识别到复杂的导航和规划任务)方面存在显著差异。
-
方法的多样性和复杂性也增加了比较和评估的难度。早期方法主要依赖于定制的架构和人工标注的数据,而最近的方法则更多地利用预训练模型和自动化数据生成技术。
-
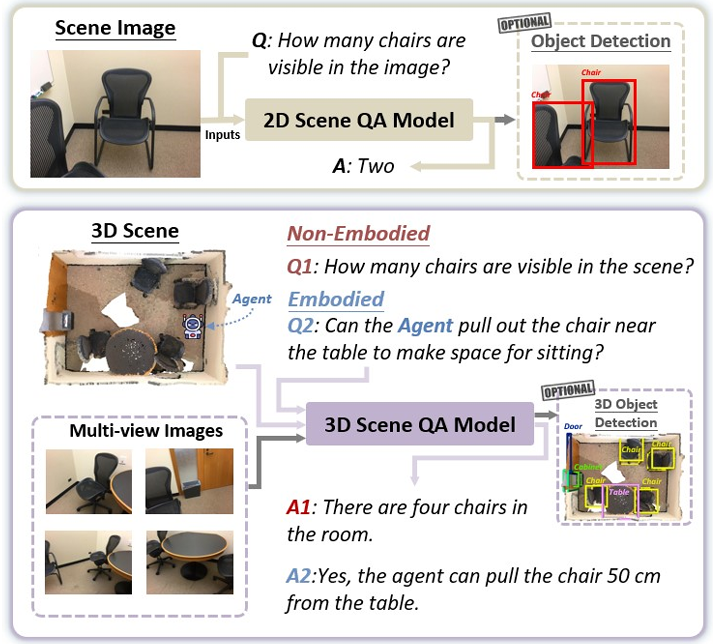
预备知识
3D SQA任务的核心是理解3D场景和查询,生成文本答案和可选的空间信息。具体定义如下:
-
输入
-
3D场景(S):可以用点云(S(p))或多种视角的图像(S(m))表示,也可以是两者的组合。
-
查询(Q):可以是文本(Q(t)),也可以包含第一人称图像(Q(e))或对象级点云(Q(o))。
-
-
输出
-
文本答案(T):对查询的文本回复。
-
空间信息(B):如相关对象的3D边界框,用于空间定位。
-
-
任务函数(F):将输入的场景和查询映射到输出的答案和空间信息,即F : (S,Q) → (T,B)。这个函数需要整合多模态推理和空间理解,以实现对3D场景的全面分析。

数据集
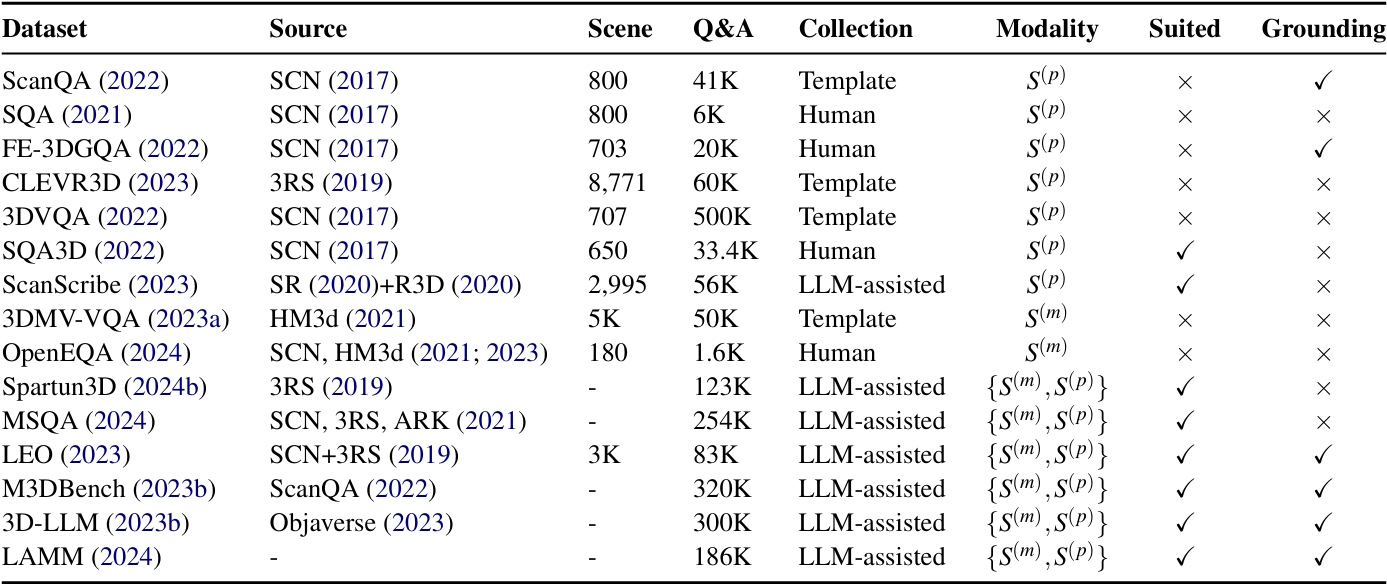
数据集结构
-
场景模态和规模
-
合成3D数据集:早期的3D SQA数据集主要基于合成环境,如EmbodiedQA和IQA,它们利用虚拟环境生成场景和问题,适合初步研究和算法验证。
-
点云数据集:如ScanQA和SQA,基于真实世界的3D扫描数据(如ScanNet),提供了更接近实际应用的场景和问题,适合研究点云处理和空间理解。
-
多视角数据集:如3DMV-VQA和OpenEQA,通过从多个视角渲染图像来表示3D场景,更符合人类的视觉感知方式,适合研究多视角融合和视觉 - 语言对齐。
-
多模态数据集:如Spartun3D和MSQA,整合了点云、图像和文本等多种模态的数据,能够提供更丰富的上下文信息,适合研究复杂的多模态交互和推理任务。
-
-
查询模态和复杂性
-
基本文本查询:早期数据集主要使用简单的文本查询,如"房间里有多少把椅子?"这类查询关注场景级属性,不涉及智能体的位置或交互。
-
以智能体为中心的查询:如SQA3D引入了描述智能体位置和方向的查询,如"坐在床边,面对沙发",增加了任务的复杂性和交互性。
-
多模态查询:最近的数据集开始结合文本、图像和空间信息等多种模态,如Spartun3D和MSQA,使查询更加丰富和真实。
-
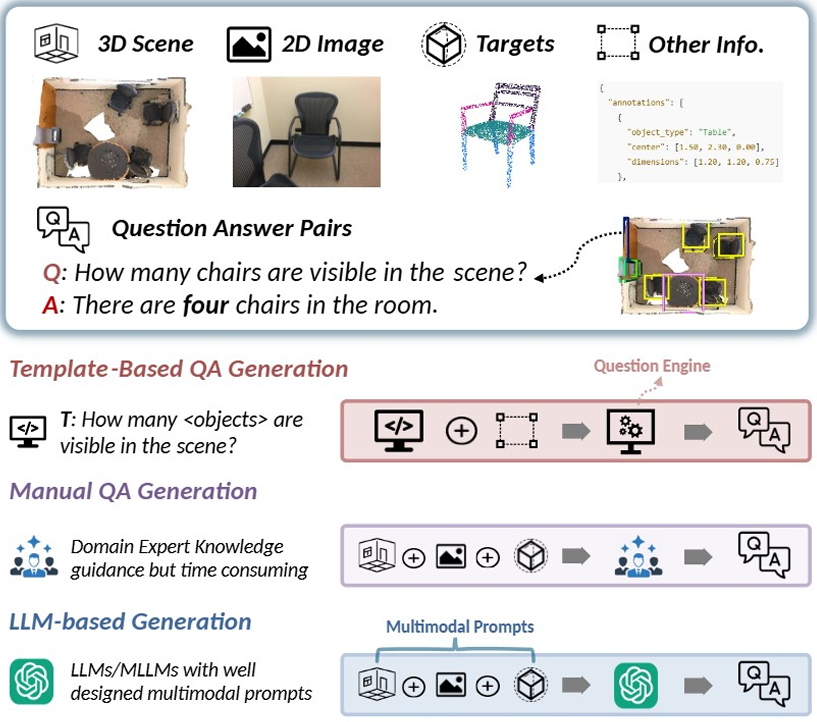
QA对生成
- 生成方法
-
模板生成:通过预定义的模板和程序化的方法生成问答对,如ScanQA利用T5模型和ScanRefer数据集生成种子问题。这种方法可以快速生成大规模数据集,但生成的问题可能缺乏多样性。
-
人工标注:通过人工标注生成问答对,如SQA和FE-3DGQA,虽然标注成本较高,但能够保证问题的质量和多样性。
-
LLM辅助生成:利用大模型(如GPT-3)生成问答对,如Spartun3D和MSQA。这种方法结合了LLM的强大生成能力和人工标注的准确性,能够生成高质量且多样化的问答对。
-
评估指标
传统指标
-
精确匹配(Exact Match,EM):衡量生成答案与真实答案是否完全一致。例如,EM@1表示生成的最可能答案与真实答案完全匹配的比例,EM@10表示前10个生成答案中至少有一个与真实答案完全匹配的比例。
-
语言生成指标:包括BLEU(用于衡量生成文本与参考文本的相似度)、ROUGE-L(用于评估生成文本与参考文本的重叠程度)、METEOR(综合考虑词汇匹配、词义匹配等多种因素)和CIDEr(用于评估生成文本的语义相关性)。这些指标主要用于评估生成答案的语言质量和多样性。
基于LLM的指标
-
Mean Relevance Score:如OpenEQA使用GPT评估生成答案的上下文相关性和正确性,通过计算生成答案与真实答案之间的语义相似度来衡量模型的性能。
-
基于GPT的评分:如MSQA使用GPT评估答案的质量,通过判断生成答案是否符合上下文逻辑和语义要求来给出评分。这种方法能够更好地捕捉生成答案的语义细节和上下文一致性。
3D SQA方法分类
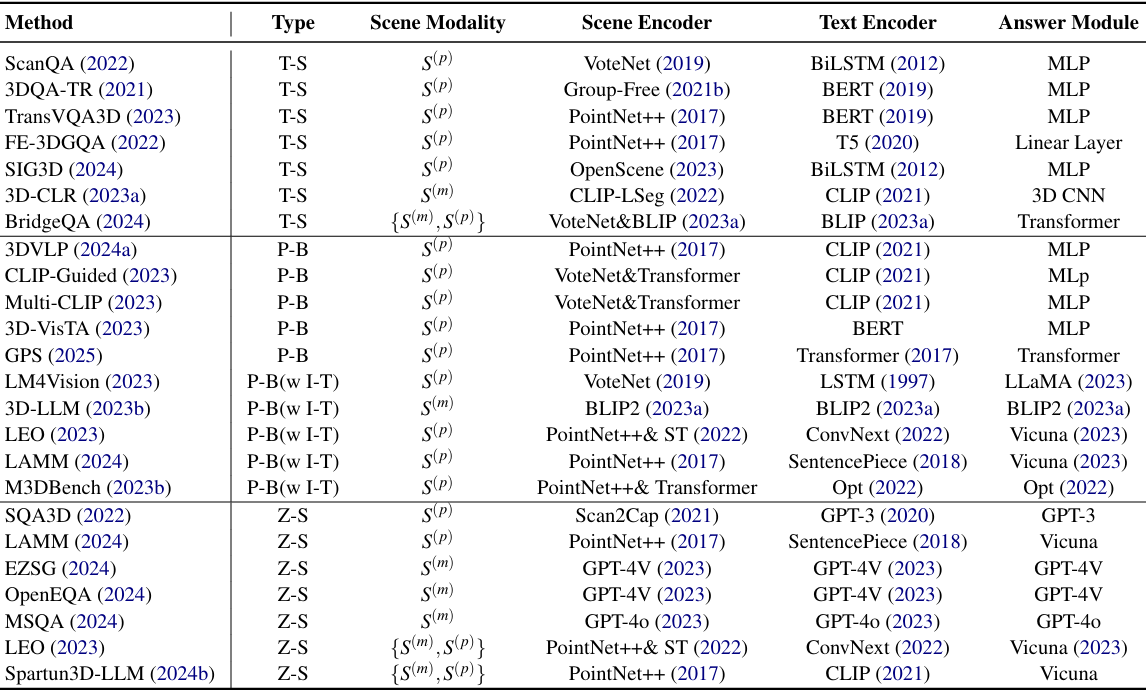
任务特定方法
-
点云方法
-
这些方法主要针对点云数据进行处理,通常采用模块化的处理流程:场景编码、查询编码、特征融合和答案预测。例如,ScanQA使用VoteNet和PointNet++提取点云的空间特征,用BiLSTM和BERT对文本查询进行编码,然后通过Transformer模块进行特征融合,最后通过MLP预测答案。
-
3DQA-TR进一步优化了这一流程,用Group-Free替代VoteNet,采用BERT对查询进行编码,增强了特征融合的效果。
-
-
多视角和2D - 3D方法
-
一些方法结合多视角图像和点云数据来提高性能。例如,3D-CLR通过多视角图像构建紧凑的3D场景表示,优化3D体素网格,从而更好地对齐视觉和语言特征。
-
BridgeQA则结合2D图像特征和3D对象特征,通过预训练的视觉 - 语言模型(如BLIP)对文本进行编码,然后通过视觉 - 语言Transformer进行特征融合,生成自由形式的答案。
-
基于预训练的方法
-
传统预训练方法
-
这些方法侧重于对齐3D空间特征与2D视觉和语言表示。例如,Parelli等人的方法利用可训练的3D场景编码器(基于VoteNet)提取对象级特征,并通过Transformer层建模对象间关系,增强多模态特征的对齐。
-
Multi-CLIP通过多视角渲染和对比学习,进一步优化了3D空间特征与2D表示的整合,提高了模型对多模态数据的理解能力。
-
-
指令微调方法
-
这些方法利用预训练的LLM或VLM作为冻结编码器,通过轻量级的任务特定层进行微调,以适应下游任务。例如,LM4Vision使用冻结的LLaMA编码器,训练轻量级的任务特定层以对齐3D QA任务。
-
LEO、M3DBench和LAMM等方法利用Vicuna(LLaMA的衍生模型)进行指令微调,通过对象级和场景级的描述增强多模态推理能力。
-
零样本学习方法
-
文本驱动方法
- 将3D场景信息转换为文本描述,然后与问题一起输入预训练的LLM或VLM进行零样本推理。例如,SQA3D使用Scan2Cap生成场景描述并输入GPT-3进行问答。这种方法虽然灵活且成本较低,但对3D空间信息的利用有限。
-
图像驱动方法
- 利用VLM将视觉特征(如图像或多视角数据)与文本结合进行推理。例如,MSQA使用GPT-4o与VLM结合,通过图像特征增强对场景的理解。这种方法能够更好地利用视觉信息,但仍依赖于文本描述来表达空间关系。
-
多模态对齐方法
- 在预训练阶段显式对齐视觉和文本信息,以提高零样本性能。例如,LEO和Spartun3D-LLM通过增强对象级和场景级特征对齐,使模型能够更好地理解和推理3D场景与文本之间的关系。这种方法虽然性能较好,但计算资源需求较高。
挑战与未来工作
数据集质量和标准化
-
挑战
-
目前3D SQA数据集发展迅速,但存在范围和模态不一致的问题,缺乏统一的基准和评估标准。
-
LLM生成数据集时可能会引入幻觉信息和上下文错位,影响数据质量。
-
-
未来工作
-
需要整合现有的数据集,构建统一的基准,以便进行标准化评估。
-
开发更强大的验证框架,利用人工标注或LLM作为验证器,确保数据集的质量和可靠性。
-
零样本学习中的3D意识增强
-
挑战
- 当前零样本模型过度依赖文本代理,对3D空间和几何特征的利用有限,难以处理复杂的3D任务。
-
未来工作
-
探索能够深度融合3D特征与语言和视觉模态的架构,提高模型在多样化任务中的泛化能力。
-
研究如何更好地平衡多模态对齐和预训练模型在零样本3D SQA中的作用,以提高效率和性能。
-
统一评估
-
挑战
- 缺乏针对3D SQA目标的标准化和专用评估指标,难以在不同数据集和模型之间进行有意义的比较。
-
未来工作
- 开发统一的评估框架,纳入多模态指标,涵盖空间推理、上下文准确性和特定任务性能等方面,以便更准确地进行基准测试和推动方法创新。
动态和开放世界场景
-
挑战
- 大多数现有方法和数据集关注静态、预定义的环境,限制了其在现实世界任务中的适用性。
-
未来工作
-
关注动态、开放世界设置,使模型能够处理实时场景变化和新问题。
-
结合具身交互(如导航和多步推理),使3D SQA系统更接近现实世界的需求。
-
可解释和可解释的3D SQA模型
-
挑战
- 当前的3D SQA模型通常被视为"黑箱",限制了其在医疗保健等信任关键领域的应用。
-
未来工作
- 开发能够可视化3D特征、突出相关区域或提供自然语言解释的可解释模型,增强用户信任并扩大其应用范围。
多模态交互与协作
-
挑战
- 3D SQA系统正朝着更自然和交互式的界面发展,但目前的研究还相对较少。
-
未来工作
-
探索整合语言、手势和视觉输入,实现与3D场景的直观交互。
-
研究协作场景(如建筑设计或教育训练)中多个用户实时与系统互动的可能性,为3D SQA开拓更广泛的应用。
-
纳入时间动态
-
挑战
- 大多数3D SQA模型目前忽略了场景的时间动态,而现实世界中的许多应用(如交通监控、机器人导航)都涉及动态环境。
-
未来工作
-
研究如何将时间动态纳入3D SQA,使模型能够推理场景随时间的变化。
-
利用时间信息(如物体运动)处理需要长期时间推理的任务,提高模型在动态环境中的适应性。
-
模型效率和部署
-
挑战
- 部署3D SQA系统到资源受限的设备(如移动机器人和边缘AI代理)上存在困难,因为这些模型通常需要较高的计算和内存资源。
-
未来工作
-
研究轻量级架构和优化技术,如剪枝、量化和知识蒸馏,以实现高效和实时的推理。
-
开发适用于嵌入式系统的节能算法和可扩展设计,提高3D SQA在实际应用中的可行性。
-
