目录
- [0 专栏介绍](#0 专栏介绍)
- [1 最大熵贝尔曼方程](#1 最大熵贝尔曼方程)
- [2 SAC算法原理推导](#2 SAC算法原理推导)
-
- [2.1 参数化动作-价值函数](#2.1 参数化动作-价值函数)
- [2.2 参数化策略](#2.2 参数化策略)
- [2.3 参数化温度](#2.3 参数化温度)
- [3 算法流程](#3 算法流程)
0 专栏介绍
本专栏以贝尔曼最优方程等数学原理为根基,结合PyTorch框架逐层拆解DRL的核心算法(如DQN、PPO、SAC)逻辑。针对机器人运动规划场景,深入探讨如何将DRL与路径规划、动态避障等任务结合,包含仿真环境搭建、状态空间设计、奖励函数工程化调优等技术细节,旨在帮助读者掌握深度强化学习技术在机器人运动规划中的实战应用
1 最大熵贝尔曼方程
经典强化学习的目标是希望得到使累计奖赏最大的策略
π ∗ = a r g max π ∈ Π E ( s t , a t ) π ∑ t R s t → s t + 1 a t \pi ^*=\underset{\pi \in \Pi}{\mathrm{arg}\max}\mathbb{E} _{\left( s_t,a_t \right) ~\pi}\left \\sum_t{R_{s_t\\rightarrow s_{t+1}}\^{a_t}} \\right π∗=π∈ΠargmaxE(st,at) πt∑Rst→st+1at
由于从 π \pi π产生动作过程中的最大值算子 a r g m a x argmax argmax(确定性策略 )或高斯采样(随机性策略),此时策略是如图所示的单峰分布。
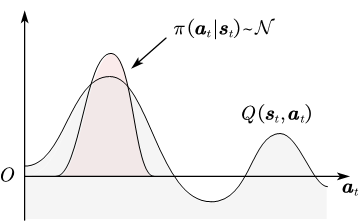
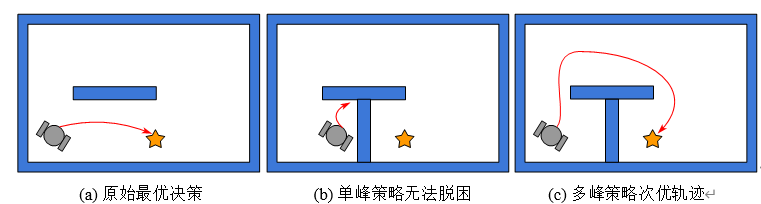
单峰策略的缺陷在于容易过拟合到局部最优点。如下图所示,迷宫寻路问题中,一个训练好的智能体按照既定的最优决策运动到目标点,此时环境中增加噪声,在单峰策略作用下,智能体将在动态障碍物处反复做出过往的最优动作,产生徘徊无解的现象。
为了解决这个问题,最大熵强化学习(Maximum Entropy Reinforcement Learning)引入了熵作为额外的策略优化目标
π ∗ = a r g max π ∈ Π E ( s t , a t ) π ∑ t R s t → s t + 1 a t + α H ( π ( s t , a t ) ) \pi ^*=\underset{\pi \in \Pi}{\mathrm{arg}\max}\mathbb{E} _{\left( s_t,a_t \right) ~\pi}\left \\sum_t{R_{s_t\\rightarrow s_{t+1}}\^{a_t}+\\alpha H\\left( \\pi \\left( s_t,a_t \\right) \\right)} \\right π∗=π∈ΠargmaxE(st,at) πt∑Rst→st+1at+αH(π(st,at))
其中熵
H ( π ( s t , a t ) ) = E ( s t , a t ) π − log π ( s t , a t ) H\left( \pi \left( s_t,a_t \right) \right) =\mathbb{E} _{\left( s_t,a_t \right) ~\pi}\left -\\log \\pi \\left( s_t,a_t \\right) \\right H(π(st,at))=E(st,at) π−logπ(st,at)
衡量了决策的随机性,温度系数 α \alpha α衡量了熵的重要性,特别地,均匀分布的熵最大,即每个动作都有同等概率被选择。不妨令
R s t → s t + 1 s o f t , a t = R s t → s t + 1 a t + γ α H ( π ( s t + 1 , a t + 1 ) ) R_{s_t\rightarrow s_{t+1}}^{\mathrm{soft},a_t}=R_{s_t\rightarrow s_{t+1}}^{a_t}+\gamma \alpha H\left( \pi \left( s_{t+1},a_{t+1} \right) \right) Rst→st+1soft,at=Rst→st+1at+γαH(π(st+1,at+1))
则应用经典贝尔曼递推算子可以保证收敛,对经典贝尔曼公式不熟悉的同学可以参考:
最大熵贝尔曼价值函数为
V s o f t π ( s ) = Δ α log ∫ a exp ( 1 α Q s o f t π ( s , a ) ) d a V_{\mathrm{soft}}^{\pi}\left( s \right) \xlongequal{\Delta}\alpha \log \int_a{\exp \left( \frac{1}{\alpha}Q_{\mathrm{soft}}^{\pi}\left( s,a \right) \right) \mathrm{d}a} Vsoftπ(s)Δ αlog∫aexp(α1Qsoftπ(s,a))da
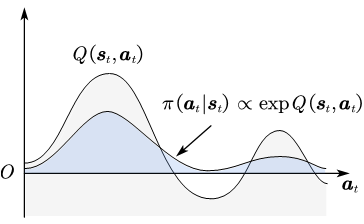
所以最大熵强化学习输出一个多峰策略,且峰值正比于价值 。如图所示,多峰策略的优势在于探索性强,可以适应于多模态、多目标的复杂任务;鲁棒性强,熵正则会让智能体倾向于学习所有较优动作
2 SAC算法原理推导
**软性演员-评论家(Soft Actor-Critic, SAC)**算法是基于最大熵原理的离线策略方法,具有高效的采样效率和泛化能力
2.1 参数化动作-价值函数
同样出于降低过估计的目的设置Critic网络 Q ( s , a ; w ) Q\left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{w} \right) Q(s,a;w)与 Q ^ ( s , a ; w ^ ) \hat{Q}\left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{\hat{w}} \right) Q^(s,a;w^),结合最大熵贝尔曼方程可设计损失函数
J ( w ) = 1 2 E ( Q ( s , a ; w ) − ( r s → s ′ + γ max a ′ ( Q \^ ( s ′ , a ′ ; w \^ ) − α log π ( s ′ , a ′ ; θ ) ) ) ) J\left( \boldsymbol{w} \right) =\frac{1}{2}\mathbb{E} \left \\left( Q\\left( \\boldsymbol{s},\\boldsymbol{a};\\boldsymbol{w} \\right) -\\left( r_{\\boldsymbol{s}\\rightarrow \\boldsymbol{s}'}+\\gamma \\max _{\\boldsymbol{a}'}\\left( \\hat{Q}\\left( \\boldsymbol{s}',\\boldsymbol{a}';\\boldsymbol{\\hat{w}} \\right) -\\alpha \\log \\pi \\left( \\boldsymbol{s}',\\boldsymbol{a}';\\boldsymbol{\\theta } \\right) \\right) \\right) \\right) \\right J(w)=21E(Q(s,a;w)−(rs→s′+γa′max(Q\^(s′,a′;w\^)−αlogπ(s′,a′;θ))))
2.2 参数化策略
设SAC算法的输出是一个高斯分布,为了便于求导进行重参数化,令 π ( s , a ; θ ) \pi \left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{\theta } \right) π(s,a;θ)的输出是均值 μ ( s ; θ ) \boldsymbol{\mu }\left( \boldsymbol{s};\boldsymbol{\theta } \right) μ(s;θ)和标准差 σ ( s ; θ ) \boldsymbol{\sigma }\left( \boldsymbol{s};\boldsymbol{\theta } \right) σ(s;θ),从标准正态分布 N ( 0 , 1 ) \mathcal{N} \left( 0,1 \right) N(0,1)中采样 ε \varepsilon ε,则可得动作 ρ ( u ∣ s ) = μ ( s ; θ ) + ε ⋅ σ ( s ; θ ) \rho \left( \boldsymbol{u}|\boldsymbol{s} \right) =\mu \left( \boldsymbol{s};\boldsymbol{\theta } \right) +\varepsilon \cdot \sigma \left( \boldsymbol{s};\boldsymbol{\theta } \right) ρ(u∣s)=μ(s;θ)+ε⋅σ(s;θ)。由于正态分布的取值不受限,SAC进一步采用 tanh \tanh tanh函数进行压缩,以考虑有限区间的动作,即
a = π ( s , a ; θ ) = tanh ( u ) \boldsymbol{a}=\pi \left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{\theta } \right) =\tanh \left( \boldsymbol{u} \right) a=π(s,a;θ)=tanh(u)
动作压缩导致概率分布的不一致性 π ( a ∣ s ) ≠ ρ ( u ∣ s ) \pi \left( \boldsymbol{a}|\boldsymbol{s} \right) \ne \rho \left( \boldsymbol{u}|\boldsymbol{s} \right) π(a∣s)=ρ(u∣s),所以
π ( a ∣ s ) = ρ ( u ∣ s ) ∣ d a d u T ∣ − 1 ⇒ log π ( a ∣ s ) = log ρ ( u ∣ s ) − log ∣ d a d u T ∣ \pi \left( \boldsymbol{a}|\boldsymbol{s} \right) =\rho \left( \boldsymbol{u}|\boldsymbol{s} \right) \left| \frac{\mathrm{d}\boldsymbol{a}}{\mathrm{d}\boldsymbol{u}^T} \right|^{-1}\Rightarrow \log \pi \left( \boldsymbol{a}|\boldsymbol{s} \right) =\log \rho \left( \boldsymbol{u}|\boldsymbol{s} \right) -\log \left| \frac{\mathrm{d}\boldsymbol{a}}{\mathrm{d}\boldsymbol{u}^T} \right| π(a∣s)=ρ(u∣s) duTda −1⇒logπ(a∣s)=logρ(u∣s)−log duTda
接着,根据最大熵贝尔曼策略改进定理设计策略损失函数
J ( θ ) = E ( s , a ) π ( log π ( s , a ; θ ) − 1 α Q ( s , a ; w ) + log Z ( s ) ) J\left( \boldsymbol{\theta } \right) =\mathbb{E} _{\left( \boldsymbol{s},\boldsymbol{a} \right) ~\pi}\left( \log \pi \left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{\theta } \right) -\frac{1}{\alpha}Q\left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{w} \right) +\log Z\left( \boldsymbol{s} \right) \right) J(θ)=E(s,a) π(logπ(s,a;θ)−α1Q(s,a;w)+logZ(s))
简化为
J ( θ ) = E ( s , a ) π ( α log π ( s , a ; θ ) − Q ( s , a ; w ) ) J\left( \boldsymbol{\theta } \right) =\mathbb{E} _{\left( \boldsymbol{s},\boldsymbol{a} \right) ~\pi}\left( \alpha \log \pi \left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{\theta } \right) -Q\left( \boldsymbol{s},\boldsymbol{a};\boldsymbol{w} \right) \right) J(θ)=E(s,a) π(αlogπ(s,a;θ)−Q(s,a;w))
2.3 参数化温度
在训练过程中,随着策略的改善,熵可能会发生不可预测的变化,因此采用固定的温度超参数 α \alpha α衡量熵项的权重将使训练效果不稳定。SAC设计了温度的自适应调整机制,要求在最大化期望回报的同时,每次迭代的策略需要满足最小熵约束。设置损失函数
J ( α ) = E − α log π ( s , a ; θ ) − α H 0 J\left( \alpha \right) =\mathbb{E} \left -\\alpha \\log \\pi \\left( \\boldsymbol{s},\\boldsymbol{a};\\boldsymbol{\\theta } \\right) -\\alpha H_0 \\right J(α)=E−αlogπ(s,a;θ)−αH0
J ( α ) J\left( \alpha \right) J(α)指出,若动作熵大于目标熵,则正梯度将减小温度系数 α \alpha α,降低策略分布的随机性,使模型专注于获得更高的单峰回报;若动作熵小于目标熵,则负梯度将增大温度系数 α \alpha α,提升策略分布的随机性,防止产生过拟合
至此完成了SAC算法的参数化过程
3 算法流程
SAC算法完整的流程如下所示

🔥 更多精彩专栏:
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇