写在前文:之所以设计这一套流程,是因为 Python在前沿的科技前沿的生态要比Java好,而Java在企业级应用层开发比较活跃;
毕竟许多企业的后端服务、应用程序均采用Java开发,涵盖权限管理、后台应用、缓存机制、中间件集成及数据库交互等方面 。但是现在的AI技术生态发展得很快,而Python在科研(数据科学/机器学习领域)语言,在这方面有天然的优势;所以为了接入大模型LLMs,选择用Python接入大模型LLMs,然后通过FastAPI发布HTTP接口,让Java层负责与前端Vue.js应用及Python流接口进行交互 ,这样的话,前端直接访问Java应用,企业应用只需要保持现有生态即可,当前的权限、后台应用、缓存、中间件等流程都不用再Python端再次开发,省去了很多工作;
整个流程如下: python负责和模型交互---Java作为中间层负责和前端Vue以及Python流接口交互-----Vue负责展示;
技术体系
XML
PythonAI端:
- LLM模型:本地ChatOllama+Qwen VLLm+Qwen、本地通过HF的Transformer加载
- Embedding向量:OllamaEmbedding + nomic-embed-text:latest
- 向量库FAISS:使用本地版本的Faiss库
- 检索优化:
混合(二阶段)检索:similarity_score_threshold相似性打分(向量检索)+BM25(关键字)检索构成的混合检索 结合 FlashRank重排序优化
检索继续优化,多阶段检索:多查询检索(LLM扩展)、混合检索(向量检索+BM25关键字检索)、重排序优化、LLM压缩;---之所以不使用多查询LLM扩展和LLM压缩,是因为性能问题---在使用LLM压缩时,最好结合微调效果会好很多,不然可能会排除掉一些问题和答案关联性不强但实际上是一一对应的问题答案;使用单独使用混合检索的时候满足绝大多数情况;
- 重排序:离线的FlashRankRerank+默认ms-marco-MultiBERT-L-12模型
- 流输出:使用StreamingResponse包装结合yield关键字;
- 性能优化:调用astream的异步执行方法/如果要使用stream同步方法,那么使用iterate_in_threadpool转异步/也可以使用async+with来管理异步执行
JavaAI端:
- 核心:Springboot
- 请求流接口:WebClient
- 返回流结果:Flux
前端:vue3+vite构建项目核心接口主要包含下面的功能:
Python的流输出:Python通过yield定义一个生成器函数(可以不间断的返回数据),然后通过"StreamingResponse"包装后流式返回;
---注意:return是一次性返回;
Java请求流接口:在Java端我们使用WebClient请求Python的流接口;
Java流输出:将结果转为Flux类型的数据返回到前端页面;
--- 此时这两个接口,都是可以直接通过浏览器访问接口查看效果
--- 如果使用Postman,必须返回标准的SSE格式的数据,不然是看不到效果的;
SSE数据格式:每个数据块以"data: "开头,结尾加两个换行符
PythonAI ---- 本文主要是本地Ollama加载模型
下一篇更新:云服务通过VLLm部署模型,然后本地使用OpenAI加载云端的VLLm模型;以及"使用HuggingFace的原生Transformer加载LLM"
流式输出核心代码
主要是通过yield定义一个生成器函数,再通过StreamingResponse包装返回,注意设置media_type="text/event-stream;charset=utf-8"
python
def llm_astream(self, faiss_query):
from fastapi.concurrency import iterate_in_threadpool
sync_generator = self.chain.astream(faiss_query)
# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步
async for chunk in iterate_in_threadpool(sync_generator):
# yield chunk.content
# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。
# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符
# yield f"data: {chunk.content}\n\n" # 使用String字符串返回
import json
# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码
yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"
# # 如果 chain.stream 本身是异步生成器,直接使用:
# async for chunk in self.chain.stream(faiss_query):
# yield chunk.content
@app.get("/stream")
async def llm_stream(query: str):
from starlette.responses import StreamingResponse
return StreamingResponse( # 使用StreamingResponse包装,流返回
retriever.llm_astream(query),
media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8
)注意:此种方法可以使用浏览器看到效果;但是用Postman---如果不是标准的SSE格式数据就看不到效果;
注意:我们返回数据时一定要返回SSE格式的数据,不然Java端要报错"java.lang.NullPointerException: The mapper xxxxxxx$$Lambda$880/0x0000000801118d08 returned a null value";
SSE标准格式,返回JSON格式版本:yield f"data: {json.dumps({'content': chunk.content})}\n\n"
Java端使用"ServerSentEvent"事件接收;
SSE标准格式,返回字符串格式版本:yield f"data: {chunk.content}\n\n"
Java端使用"String"事件接收;
完整的代码
下面关于检索优化、构建链、llm交互、rag知识入库、向量库、Ollama加载云端API等...技术知识见我之前发的几篇文章;---- 安装了依赖以后,可以直接运行下面代码;
请求地址:http://localhost:8000/astream?query=xxxxx
---还可以访问stream接口看看使用异步协程、同步返回的不同效果;
python
"""检索agent"""
import asyncio
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langserve import add_routes
def log_retrieved_docs(ctx):
# print(f"[{ctx['msgid']}] [{ctx['query']}] Retrieved documents:[{ctx['content']['content']}]")
print(f"Retrieved documents:[{ctx}]")
return ctx # 确保返回原数据继续链式传递
class RetrieverLoad:
def __init__(self):
print("加载向量库...")
from langchain_ollama import OllamaEmbeddings
self.faiss_persist_directory = 'faiss路径'
self.embedding = OllamaEmbeddings(model='nomic-embed-text:latest')
self.faiss_index_name = 'faiss_index名称'
self.faiss_vector_store = self.load_embed_store()
self.llm = ChatOllama(model="qwen2.5:3b")
self.prompt = ChatPromptTemplate.from_template(retriver_template)
self.retriever = self.retriever()
self.chain = self.llm_chain()
def load_embed_store(self):
return FAISS.load_local(
self.faiss_persist_directory,
embeddings=self.embedding,
index_name=self.faiss_index_name, # 需与保存时一致
allow_dangerous_deserialization=True
)
def retriever(self, score_threshold: float = 0.5, k: int = 5):
sst_retriever = self.faiss_vector_store.as_retriever(
search_type='similarity_score_threshold',
search_kwargs={"score_threshold": score_threshold, "k": k}
)
# 初始化BM25检索
# (使用公共方法获取文档)
documents = list(self.faiss_vector_store.docstore._dict.values())
from langchain_community.retrievers import BM25Retriever
bm25_retriever = BM25Retriever.from_documents(
documents,
k=20, # 返回数量
k1=1.5, # 默认1.2,增大使高频词贡献更高
b=0.8 # 默认0.75,减小以降低文档长度影响
)
# 混合检索:BM25+embedding的
from langchain.retrievers import EnsembleRetriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, sst_retriever],
weights=[0.3, 0.7]
)
# 混合检索后 重排序
# 构建压缩管道:重排序 + 内容提取
from flashrank import Ranker
from langchain_community.document_compressors import FlashrankRerank
flashrank_rerank = FlashrankRerank(
client=Ranker(cache_dir='D://A4Project//LLM//flash_rankRerank//'),
top_n=8
)
# 三阶段检索:粗检索、重排序、内容压缩
from langchain.retrievers import ContextualCompressionRetriever
base_retriever = ContextualCompressionRetriever(
# step1. 粗检索---30% BM25+70% Embedding向量检索
base_retriever=ensemble_retriever,
# step2. 重排序---FlashRank
base_compressor=flashrank_rerank
)
# step3、内容压缩---LLM---部分场景不推荐使用LLM内容压缩,压缩可能会删除RAG里面原本Q&A对应但是答案中不包含问题,导致关联性小的数据;而且很影响性能
# from langchain.retrievers.document_compressors import LLMChainExtractor
# # 重排序后 压缩上下文
# compressor_prompt = """
# 鉴于以下问题和内容,提取与回答问题相关的背景*按原样*的任何部分。如果上下文都不相关,则返回{no_output_str}。
# 记住,*不要*编辑提取上下文的部分。
# 问题: {{question}}
# 内容: {{context}}
# 提取相关部分:
# """
# from langchain_core.prompts import PromptTemplate
# compressor_prompt_template = PromptTemplate(
# input_variables=['question', 'context'],
# template=compressor_prompt.format(no_output_str='NO_OUTPUT'))
# compressor = LLMChainExtractor.from_llm(prompt=compressor_prompt_template, llm=self.llm)
# # compressor = LLMChainExtractor.from_llm(llm=self.llm)
# pipeline_retriever = ContextualCompressionRetriever(
# base_retriever=base_retriever,
# base_compressor=compressor
# )
return base_retriever
def llm_chain(self):
# 处理检索结果的函数(将文档列表转换为字符串)
from langchain_core.runnables import RunnableLambda
# process_docs = RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs]))
from langchain_core.runnables import RunnablePassthrough
prompt = """
请根据以下内容回答问题,内容中如果没有的那就回答"请咨询人工...",内容中如果有其他不相干的内容,直接删除即可。
内容:{content}
问题:{query}
回答:
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
from operator import itemgetter
chain = (
# RunnableLambda(log_retrieved_docs) | # 直接打印传递进来的参数
{
# 这个content和query会继续往下传递,直到prompt --->{content}、{query}
"content": RunnableLambda(lambda x: x[
"query"]) # 必须,不然要报错"TypeError: Expected a Runnable, callable or dict.Instead got an unsupported type: <class 'str'"
| self.retriever # 检索
# | RunnableLambda(log_retrieved_docs) # 打印出检索到的文档,检索后未处理
# 先检索再处理文档
| RunnableLambda(lambda docs: "\n".join([doc.page_content for doc in docs])),
# | process_docs # 先检索再处理文档 --- 和上面方法二选一
# | RunnableLambda(log_retrieved_docs), # 打印出检索后的文档 --- 这里传递的仅仅是检索到的内容且预处理后的内容
"query": itemgetter("query"), # 直接传递用户原始问题
"msgid": RunnableLambda(lambda x: x["msgid"]), # 显示传递msgid --- 和itemgetter同样的效果
}
| RunnableLambda(log_retrieved_docs) # 传递的是前面整个content、query、msgid的值到日志中
| prompt_template # 组合成完整 prompt
| self.llm # 传给大模型生成回答
# | RunnableLambda(log_retrieved_docs) # 传递的是LLM生成的内容 --- 但是在这一步以后,系统会同步返回---不推荐在这里打印日志
)
return chain
async def llm_invoke(self, query):
return self.chain.invoke(query)
async def retriever_stream(self, query):
return self.retriever.stream(query)
async def llm_astream(self, query: str, msgid: str):
# 直接使用astream 异步执行
chunks = []
result = ""
async for chunk in self.chain.astream({"query": query, "msgid": msgid}):
chunks.append(chunk.content)
result += chunk.content
# yield chunk.content
# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。
# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符
import json
# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码
yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"
print(f"query:{query} msgid:{msgid} llm:{result}")
# # 如果 chain.stream 本身是异步生成器,直接使用:
# async for chunk in self.chain.stream(query):
# yield chunk.content
async def llm_stream(self, query):
from fastapi.concurrency import iterate_in_threadpool
# 如果 chain.stream 是同步生成器,使用 iterate_in_threadpool 转换为异步
async for chunk in iterate_in_threadpool(self.chain.stream(query)):
# yield chunk.content
# 标准的SEE数据格式;如果不修改为下面这个,那么在使用Java的WebClient请求时,返回的是空白/报错。
# # 包装成SSE格式,每个数据块以"data: "开头,结尾加两个换行符
import json
# 统一返回Json格式,并且禁止Unicode编码---不然返回的就是Unicode编码后的代码
yield f"data: {json.dumps({'content': chunk.content}, ensure_ascii=False)}\n\n"
# # 如果 chain.stream 本身是异步生成器,直接使用:
# async for chunk in self.chain.stream(query):
# yield chunk.content
from fastapi import FastAPI
app = FastAPI(title='ruozhiba', version='1.0.0', description='ruozhiba检索')
# 添加 CORS --- 跨域 中间件
from fastapi.middleware.cors import CORSMiddleware
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 允许所有来源,生产环境建议指定具体域名
allow_credentials=True, # 允许携带凭证(如cookies)
allow_methods=["*"], # 允许所有HTTP方法(可选:["GET", "POST"]等)
allow_headers=["*"], # 允许所有HTTP头
)
# 同步返回
@app.get("/invoke")
async def llm_invoke(query: str):
results = await retriever.llm_invoke(query)
return {"results": results.content}
@app.get("/retriever")
async def retriever_stream(query: str):
return await retriever.retriever_stream(query)
# 流式输出------异步执行
@app.get("/astream")
async def astream(query: str, msgid: str):
from starlette.responses import StreamingResponse
print(f"请求开始:query:{query} msgid:{msgid}")
return StreamingResponse(
retriever.llm_astream(query, msgid),
media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8
)
# 流式输出------同步执行
@app.get("/stream")
async def llm_stream(query: str):
from starlette.responses import StreamingResponse
return StreamingResponse(
retriever.llm_stream(query),
media_type="text/event-stream;charset=utf-8" # text/plain、text/event-stream;强制响应头charset=utf-8
)
if __name__ == '__main__':
# asyncio.run(main())
import uvicorn
retriever = RetrieverLoad()
uvicorn.run(app, host='localhost', port=8000)JavaAI
引入依赖
XML
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
</dependencies>返回Flux流 --- 测试
---浏览器访问就可以看到流效果...但是中文的话,会是乱码;
java
@GetMapping(value = "/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chat() {
// Thread.sleep()会阻塞线程,改用Flux.interval实现非阻塞延迟:
return Flux.interval(Duration.ofMillis(100)) // 每100ms生成一个数字
.map(i -> "消息:" + i) // 转换为消息字符串
.take(10); // 限制总数量为10000条
// return Flux.create(emitter -> {
// // 模拟数据流
// for (int i = 0; i < 10000; i++) {
// emitter.next("Message " + i);
// try {
// Thread.sleep(100); // 模拟延迟
// } catch (InterruptedException e) {
// emitter.error(e);
// }
// }
// emitter.complete();
// });
}解决中文乱码问题
如果不使用Filter,那么在返回前端页面的时候会是中文乱码;
java
@Component
@Order(Ordered.HIGHEST_PRECEDENCE)
public class FluxPreProcessorFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
response.setCharacterEncoding("UTF-8");
chain.doFilter(request, response);
}
}结合Python流接口
初始化WebClient
java
private final WebClient webClient;
public ChatMsgController(WebClient.Builder webClientBuilder) {
this.webClient = webClientBuilder.clientConnector(
new ReactorClientHttpConnector(
HttpClient.create()
.responseTimeout(Duration.ofSeconds(30)) // 第一次请求可以设置长点
.compress(false) // 关闭压缩(如果开启可能缓冲)
)
)
// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))
// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)
// 网上说:必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE
// 实际测试,与这无关
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.baseUrl("http://localhost:8000") // python项目地址
.build();
}接收String流
java
public Flux<Object> stream(String query) {
return webClient.get()
.uri("/stream?query={query}", query)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
.bodyToFlux(String.class)
.doOnError(e->System.err.println("发生错误: " + e.getMessage()));
}接收JSON流
java
public Flux<String> stream(String query) {
return webClient.get()
.uri("/stream?query={query}", query)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
.bodyToFlux(ServerSentEvent.class)// 解析为标准的SSE事件
.mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分
.doOnError(e->System.err.println("发生错误: " + e.getMessage()))
.map(Object::toString); // 返回是否需要根据情况来定 --- 如果不需要,返回"Flux<Object>"即可
}日志&错误处理
java
public Flux<String> stream(@PathVariable("query") String query) {
String msgid = UUID.randomUUID().toString().replace("-", "");
log.info("请求开始。msgid:{},query:{}", msgid, query);
return webClient.get()
.uri("/stream?query={query}", query)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
// 请求失败返回错误。
// 状态码 --- 当未请求成功时的异常
.onStatus(HttpStatusCode::isError, response -> {
log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());
return response.bodyToMono(String.class)
.flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));
})
.bodyToFlux(String.class)
.log() // 打印日志
.doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据
.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常
}移除多余的前缀
java
@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> astream(@PathVariable("query") String query) {
String msgid = UUID.randomUUID().toString().replace("-", "");
log.info("请求开始。msgid:{},query:{}", msgid, query);
return webClient.get()
.uri("/astream?query={query}&msgid={msgid}", query, msgid)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
.onStatus(HttpStatusCode::isError, response -> {
log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());
return response.bodyToMono(String.class)
.flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));
})
.bodyToFlux(String.class) // 转为String
// 移除多余的Python返回的前缀; --- 因为我们返回给前端的也是SSE数据格式,所以返回的数据也是默认会有data:
.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", ""))
.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常
.map(Object::toString);
}保存历史记录
java
public Flux<String> astream(@PathVariable("query") String query) {
String msgid = UUID.randomUUID().toString().replace("-", "");
log.info("请求开始。msgid:{},query:{}", msgid, query);
Flux<String> dataFlux = webClient.get()
.uri("/astream?query={query}&msgid={msgid}", query, msgid)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。
// 必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求
// 不开启cache的话---相当于前端请求一次,后端发起了三次请求
.cache()
.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常
.map(Object::toString);
// 单独订阅以收集并保存数据 --- 下面是测试方法,二选一
// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]
// 自己拼装List
dataFlux.collectList() //
.flatMap(list -> {
String join = String.join("", list);
log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);
return Mono.just(join);
})
.subscribeOn(Schedulers.boundedElastic())
.subscribe(
null,
error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),
() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query)
);
// 使用reduce,合并Chunk
dataFlux.reduce((a, b) -> a + b)
.flatMap(list -> {
log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);
return Mono.just(list);
})
.subscribeOn(Schedulers.boundedElastic())
.subscribe(
null,
error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),
() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query)
);
return dataFlux;
}完整代码
SpringBoot启动---浏览器请求
java
@RestController
@RequestMapping("/ai")
@CrossOrigin("*")
@Slf4j
public class ChatMsgController {
private final WebClient webClient;
public ChatMsgController(WebClient.Builder webClientBuilder) {
this.webClient = webClientBuilder.clientConnector(
new ReactorClientHttpConnector(
HttpClient.create()
.responseTimeout(Duration.ofSeconds(60))
.compress(false) // 关闭压缩(如果开启可能缓冲)
)
)
// .codecs(configurer -> configurer.defaultCodecs().maxInMemorySize(256 * 1024 * 1024))
// .defaultHeader(HttpHeaders.AUTHORIZATION, "Bearer " + openAi)
// ⚠️ 必须设置为JSON格式;初始设置MediaType.TEXT_EVENT_STREAM_VALUE会导致请求失败,必须使用APPLICATION_JSON_VALUE
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.baseUrl("http://localhost:8000")
.build();
}
@GetMapping(value = "/astream/{query}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> astream(@PathVariable("query") String query) {
String msgid = UUID.randomUUID().toString().replace("-", "");
log.info("请求开始。msgid:{},query:{}", msgid, query);
Flux<String> dataFlux = webClient.get()
.uri("/astream?query={query}&msgid={msgid}", query, msgid)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
// 请求失败返回错误。
// 状态码 --- 当未请求成功时的异常
.onStatus(HttpStatusCode::isError, response -> {
log.error("错误状态码。msgid:{},query:{},errorCode:{}", msgid, query, response.statusCode());
return response.bodyToMono(String.class)
.flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));
})
.bodyToFlux(String.class) // 转为String
// .bodyToFlux(ServerSentEvent.class) // 解析为标准的SSE事件
// .mapNotNull(ServerSentEvent::data) // 提取标准的SEE数据格式的 数据部分
.map(x -> x.substring(0, x.length() - 2).replace("{\"content\": \"", ""))
// .log() // 打印日志 --- 这个日志是一个chunk一个chunk打印的
.cache()// 通过cache()共享数据流,单独订阅以保存数据,避免重复请求,确保保存操作仅触发一次。必须开启,不然在后续执行"dataFlux.collectList()/ dataFlux.reduce"会再次发起请求---相当于前端请求一次,后端发起了三次请求
// .doOnNext(data -> System.out.println("接收到数据块:" + data)) // 打印接收到的数据
.doOnError(e -> log.error("发生错误。msgid:{},query:{},error:{}", msgid, query, e.getMessage())) // 请求成功后,返回来的异常
.map(Object::toString);
// 单独订阅以收集并保存数据
// 使用.collectList() 收集成一个完整的 List<String>,打印出来的list是一个chunk,["你好", ",世界", "!"]
// 自己拼装List
dataFlux.collectList() //
.flatMap(list -> {
String join = String.join("", list);
log.info("触发collectList保存。msgid:{},query:{},llm:{}", msgid, query, join);
return Mono.just(join);
})
.subscribeOn(Schedulers.boundedElastic())
.subscribe(
null,
error -> log.error("collectList保存失败。msgid:{},query:{}", msgid, query, error),
() -> log.info("collectList数据已保存。msgid:{},query:{}", msgid, query)
);
// 使用reduce,合并Chunk
dataFlux.reduce((a, b) -> a + b)
.flatMap(list -> {
log.info("触发reduce保存。msgid:{},query:{},llm:{}", msgid, query, list);
return Mono.just(list);
})
.subscribeOn(Schedulers.boundedElastic())
.subscribe(
null,
error -> log.error("reduce保存失败。msgid:{},query:{}", msgid, query, error),
() -> log.info("reduce数据已保存。msgid:{},query:{}", msgid, query)
);
return dataFlux;
}
}Test/Main启动
java
public class StreamApiClient {
public void streamData(String query) {
// WebClient client = WebClient.create("http://localhost:8000");
WebClient client = WebClient.builder()
.clientConnector(
new ReactorClientHttpConnector(
HttpClient.create()
.responseTimeout(Duration.ofSeconds(10))
// .compress(false) // 关闭压缩(如果开启可能缓冲)
)
)
// .defaultHeader(HttpHeaders.CONTENT_TYPE, MediaType.APPLICATION_JSON_VALUE)
.baseUrl("http://localhost:8000")
.build();
Flux<String> stream = client.get()
.uri("/stream?query={query}", query)
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
.onStatus(HttpStatusCode::isError, response -> { // 请求失败返回错误
System.out.println("错误状态码: " + response.statusCode());
return response.bodyToMono(String.class)
.flatMap(body -> Mono.error(new RuntimeException("HTTP错误: " + body)));
})
.bodyToFlux(String.class)
// .log()
// .doOnNext(data -> System.out.println("接收到数据块:" + data))
.doOnError(e -> System.err.println("发生错误: " + e.getMessage()));
stream.subscribe(
chunk -> System.out.println("Received chunk: " + chunk),
error -> System.err.println("Error: " + error),
() -> System.out.println("Stream completed")
);
}
public static void main(String[] args) throws InterruptedException {
StreamApiClient streamApiClient = new StreamApiClient();
streamApiClient.streamData("五块能娶几个老婆");
Thread.sleep(40000); // 可以适当提升时间,不然可能程序还没得到返回就结束了,看不到效果
}
}Vue前端
前端使用vue3+vite构建
创建项目
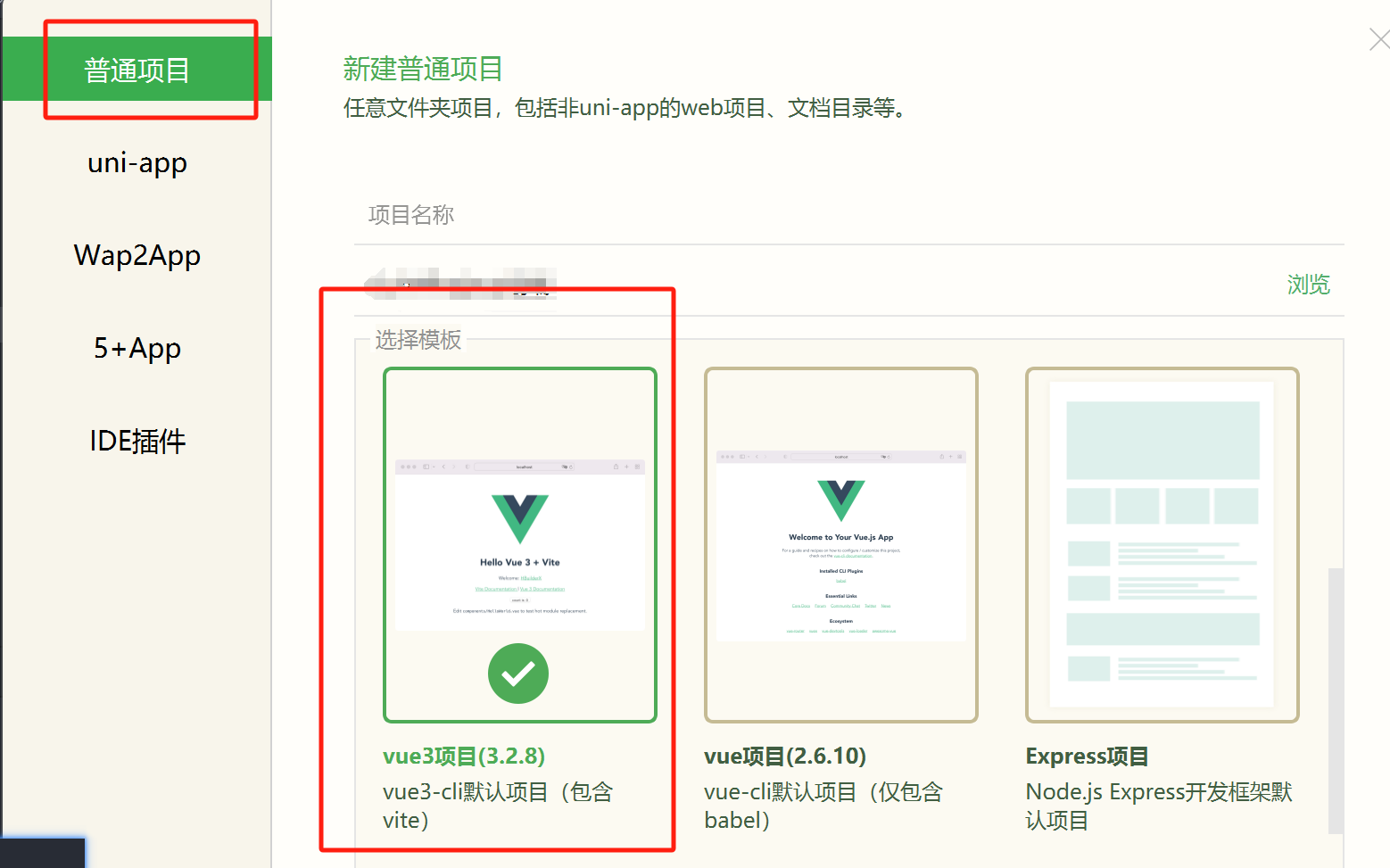
HBuilderX创建

使用命令创建
bash
npm create vite@latest my-vue-app -- --template vue # 创建项目
cd my-vue-app # 进入到项目中
npm install # 安装依赖
npm run dev # 运行dev环境项目
<!-- 其中: -->
<!-- index.html 主要是标签---包含标签页itme样式; -->
<!-- src/App.vue ---主页访问,系统 import HelloWorld from './components/HelloWorld.vue'导入了HelloWorld.vue -->
<!-- src/components/HelloWorld.vue ---刚开始是广告页,可以修改内容 -->
<!-- 所以启动成功后,访问"http://localhost:3000/index"会直接进入HelloWorld.vue; -->
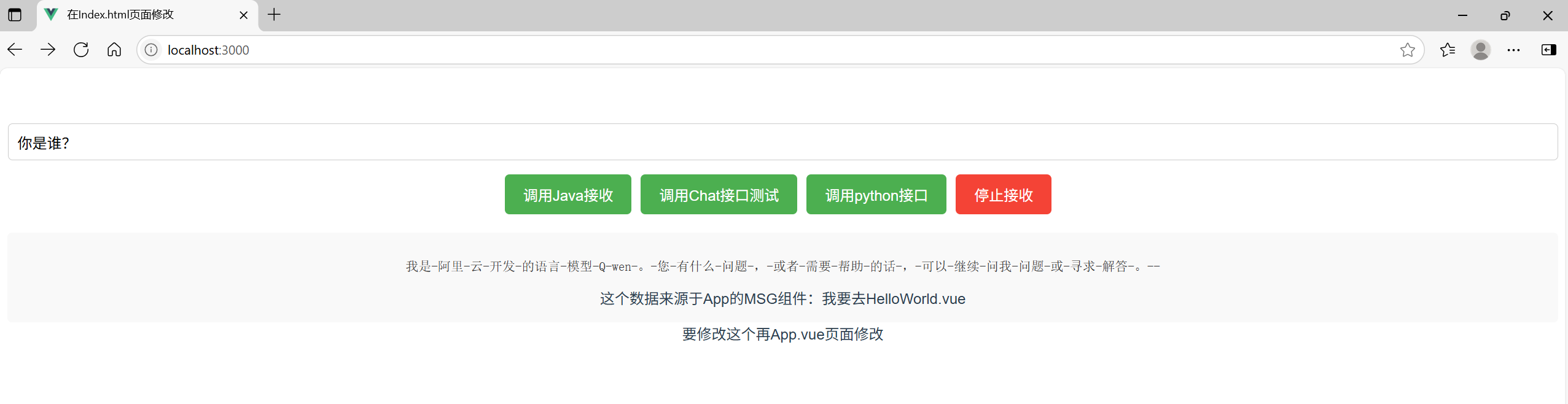
<!-- 我们现在只需要修改HelloWorld.vue即可 -->修改HelloWorld.vue
html
<template>
<div>
<input v-model="query" placeholder="输入查询内容" class="query-input" />
<button @click="startStream" class="action-button start-button">调用Java接收流</button>
<button @click="chatStream" class="action-button start-button">调用Chat接口测试</button>
<button @click="pythonStream" class="action-button start-button">调用python接口</button>
<button @click="closeStream" class="action-button stop-button">停止接收</button>
<div class="result-container">
<pre class="response-data">{{ responseData }}</pre>
<div>这个数据来源于App的MSG组件:{{msg}}</div>
</div>
</div>
</template>
<script setup>
import { ref, onBeforeUnmount } from 'vue'
// Props 定义
const props = defineProps({
msg: String
})
// 响应式数据
const query = ref('为什么砍头不找死刑犯来演')
const responseData = ref('')
const eventSource = ref(null)
// 方法
const pythonStream = () => {
closeStream()
responseData.value = ''
const url = `http://localhost:8000/astream?query=${encodeURIComponent(query.value)}&msgid=123456`
eventSource.value = new EventSource(url)
eventSource.value.onmessage = (event) => {
const data = JSON.parse(event.data)
responseData.value += data.content + "\n"
}
eventSource.value.onerror = (error) => {
console.warn("EventSource warn:", error)
closeStream()
}
}
const chatStream = () => {
closeStream()
responseData.value = ''
const url = `http://localhost:8080/ai/chat`
eventSource.value = new EventSource(url)
eventSource.value.onmessage = (event) => {
responseData.value += event.data + "\n"
}
eventSource.value.onerror = (error) => {
console.warn("EventSource warn:", error)
closeStream()
}
}
const startStream = () => {
closeStream()
responseData.value = ''
const url = `http://localhost:8080/ai/astream/${encodeURIComponent(query.value)}`
eventSource.value = new EventSource(url)
eventSource.value.onmessage = (event) => {
responseData.value += event.data + "-"
}
eventSource.value.onerror = (error) => {
console.warn("EventSource warn:", error)
closeStream()
}
}
const closeStream = () => {
if (eventSource.value) {
eventSource.value.close()
eventSource.value = null
}
}
// 生命周期钩子
onBeforeUnmount(() => {
closeStream()
})
</script>
<style scoped>
.container {
max-width: 600px;
margin: 50px auto;
padding: 20px;
border-radius: 10px;
box-shadow: 0 4px 8px rgba(0, 0, 0, .1);
background-color: #fff;
}
.query-input {
width: calc(100% - 22px);
padding: 10px;
margin-bottom: 15px;
border: 1px solid #ccc;
border-radius: 5px;
font-size: 16px;
}
.action-button {
padding: 10px 20px;
margin-right: 10px;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
transition: all .3s ease;
}
.start-button {
background-color: #4CAF50;
color: white;
}
.stop-button {
background-color: #f44336;
color: white;
}
.start-button:hover {
background-color: #45a049;
}
.stop-button:hover {
background-color: #e53935;
}
.result-container {
margin-top: 20px;
padding: 15px;
background: #f9f9f9;
border-radius: 5px;
overflow-x: auto;
}
.response-data {
white-space: pre-wrap;
word-wrap: break-word;
font-size: 14px;
color: #333;
}
</style>请求测试