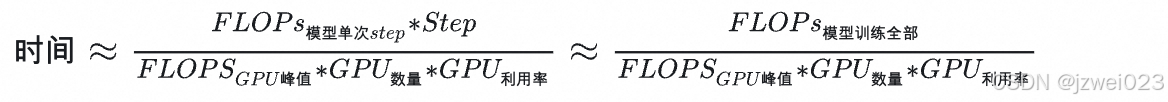
FLOPs和FLOPS的区别
- FLOPs **(Floating Point Operations)**是指模型或算法执行过程中总的浮点运算次数,单位是"次"
- FLOPS **(Floating Point Operations Per Second)**是指硬件设备(如 GPU 或 CPU)每秒能够执行的浮点运算次数,单位是"次/秒"
MFU
模型算力利用率(Model FLOPs Utilization, MFU)和硬件算力利用率(Hardware FLOPs Utilization, HFU)是评估某一模型实现对芯片计算性能利用情况的常用指标。
- 模型算力利用率:是指模型一次前反向计算消耗的矩阵算力与机器算力的比值
- 硬件算力利用率:是指考虑重计算后,模型一次前反向计算消耗的矩阵算力与机器算力的比值
矩阵相乘
矩阵是A(大小H×D),参数矩阵B(大小D×W),Y=AB的FLOPs公式就是:
H × W × ( D + (D−1)) = H × W × (2D−1)
其中Y的每个元素都是经过D次相乘以及D-1加法。如果考虑常数项或者考虑加入bias,即Y中每一个元素需要额外进行一次加法,则可以将公式中的-1省略,即:2 × H × D × W
矩阵乘法FLOPs与参数量Parameter
一个全连接层的神经网络计算的过程可以看成是两个矩阵进行相乘的操作,忽略掉激活函数(activation)部分的计算,假设输入矩阵是A、矩阵大小是H×I,全连接层的参数矩阵是B、矩阵大小是I×W,全连接层矩阵计算过程实际就是:Y=AB
所以,对于输入值大小Input_size是H ,矩阵乘法中有:
FLOPs = 2 × H × D × W = 2 × Input_size × Parameter
即可以简单认为一个token的计算量是参数量的2倍
Transformer FLOPs计算
参数量计算参考Transformer Decoder-Only 参数量计算-CSDN博客,且通过上面分析,可以知道1个token的计算量是参数量的2倍,从而可以计算transformer的每层FLOPs如下

(其中embed层的计算是查表计算,计算量为4×d_model)
推理时每个token需要的算力:C_forward per token ≈ 2N
根据反向传播的计算量是前向传播的2倍的结论,假设模型整个训练过程语料Token数是 T ,可以估算Transfomer训练(前向传播+反向传播)的FLOPs 约等于: C_train ≈ 2N × 3 × T = 6NT
如果考虑激活重计算技术(Activation Recomputation),反向传播的计算量大概是前向传播的3倍,则训练FLOPs 约等于8NT
实际情况时间估算
上面说的算理想情况:即首要考虑 GPU 前后向时算矩阵运算这个时间大头,而且 隐藏层维度d_model >> 序列长度n_ntx,利用率100%,不考虑更新、通信、切分、其他步骤(加载数据、log等等)。
实际情况不可能达到 100%,如果考虑到上述效率,一般要打折扣。折扣系数要看框架,目前比较高效的框架算上通信加载也就0.5,模型大通常来说折扣还会高。