1. 堆(Heap)
1.1. Python实现堆的插入、堆顶删除和排序
class MaxHeap:
def __init__(self):
# 初始化空堆,使用列表表示
self.heap = []
def insert(self, val):
# 插入元素并执行上浮
self.heap.append(val)
self._sift_up(len(self.heap) - 1)
def delete(self):
# 删除并返回堆顶元素
if not self.heap:
return None
self._swap(0, len(self.heap) - 1)
max_val = self.heap.pop()
self._sift_down(0)
return max_val
def build_heap(self, arr):
# 从任意数组构建大顶堆
self.heap = arr[:]
for i in range((len(self.heap) - 2) // 2, -1, -1):
self._sift_down(i)
def heapsort(self):
# 原地堆排序(不会额外开辟空间)
n = len(self.heap)
# 先构建堆
for i in range((n - 2) // 2, -1, -1):
self._sift_down(i)
# 每次把最大值(堆顶)放到末尾,然后缩小堆范围
for end in range(n - 1, 0, -1):
self._swap(0, end)
self._sift_down(0, end)
def _sift_up(self, idx):
# 上浮操作,保持堆结构
parent = (idx - 1) // 2
while idx > 0 and self.heap[idx] > self.heap[parent]:
self._swap(idx, parent)
idx = parent
parent = (idx - 1) // 2
def _sift_down(self, idx, size=None):
# 下沉操作,保持堆结构(可传入范围用于排序)
if size is None:
size = len(self.heap)
while True:
largest = idx
left = 2 * idx + 1
right = 2 * idx + 2
if left < size and self.heap[left] > self.heap[largest]:
largest = left
if right < size and self.heap[right] > self.heap[largest]:
largest = right
if largest == idx:
break
self._swap(idx, largest)
idx = largest
def _swap(self, i, j):
# 辅助函数:交换堆中两个元素
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __str__(self):
# 返回堆内容的字符串表示
return str(self.heap)
import heapq
def heapsort_asc(iterable):
heap = []
for value in iterable:
heapq.heappush(heap, value) # 构建最小堆
return [heapq.heappop(heap) for _ in range(len(heap))] # 升序弹出
# 示例
nums = [7, 2, 5, 3, 1]
print("升序堆排序结果:", heapsort_asc(nums))1.2. 堆的定义
1. 堆的基本概念
- 堆是一种特殊的树形数据结构,广泛应用于算法中,如堆排序。
- 堆的两个主要特征:
- 完全二叉树:除了最后一层,其他层的节点都已满,最后一层的节点靠左排列。
- 节点值的大小关系:
大顶堆(Max-Heap):每个节点的值都大于或等于其子节点的值。
小顶堆(Min-Heap):每个节点的值都小于或等于其子节点的值。
2. 堆的实现与存储
- 堆通常使用数组来存储,因为完全二叉树的结构适合用数组表示。
- 对于列表下标为
i的节点:
左子节点下标:2i + 1
右子节点下标:2i + 2
父节点下标:i -1 // 2
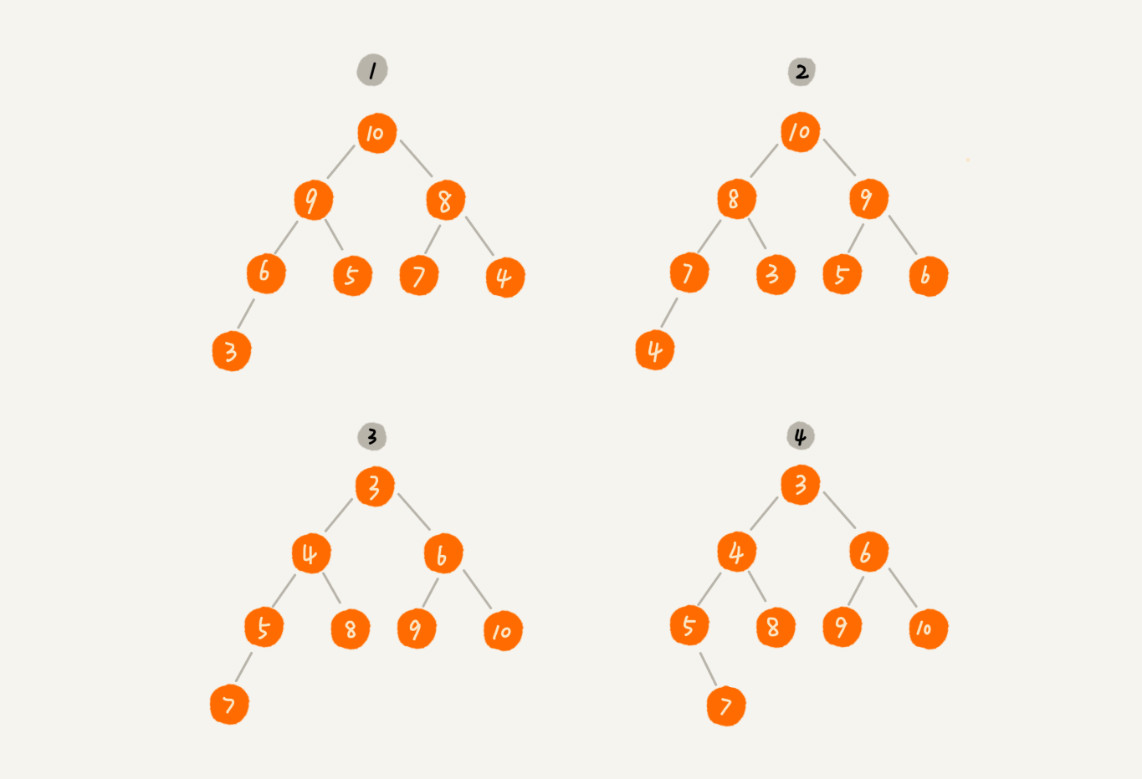
1.3. 堆的核心操作
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
具体python代码见5.1,以大顶堆为例。
1. 往堆中插入一个元素
- 将新元素插入堆的最后,然后进行堆化(Heapify)操作来恢复堆的性质。
- 堆化分为两种方式:
自下而上堆化:从插入的节点开始,依次与父节点比较,直到堆的性质恢复。
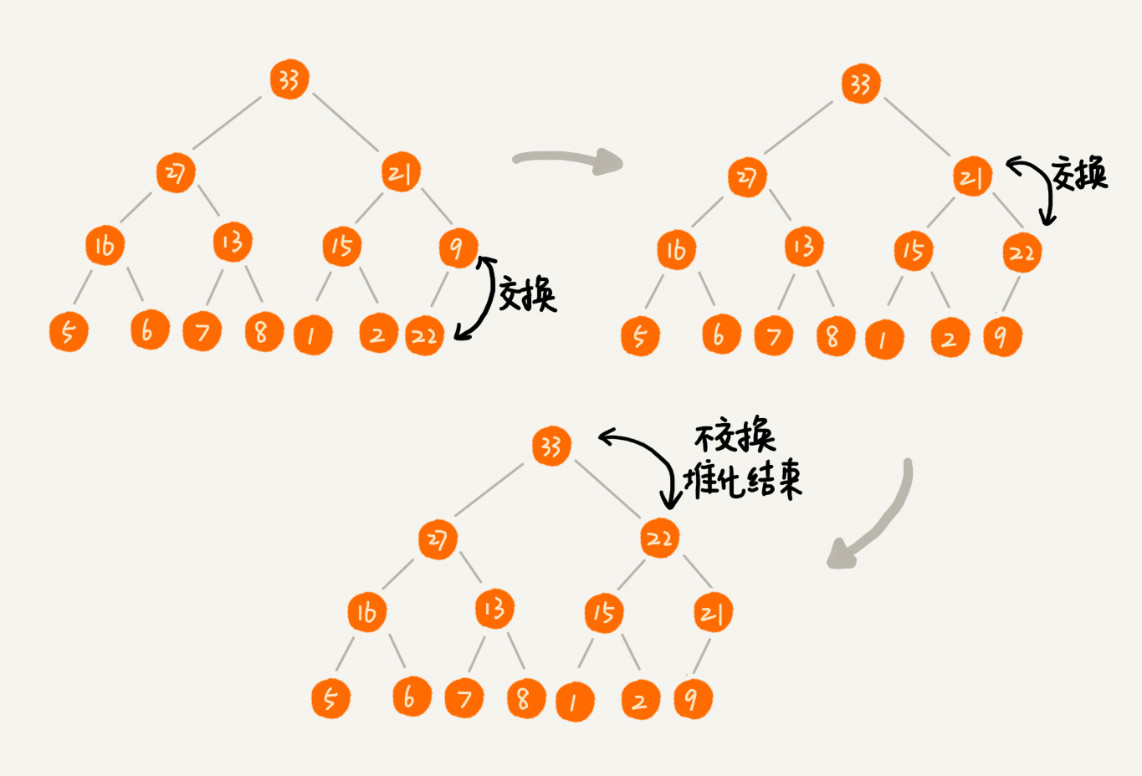
2. 删除堆顶元素
删除堆顶元素(最大或最小)后,将最后一个元素移动到堆顶,并进行自上而下堆化来恢复堆的性质。
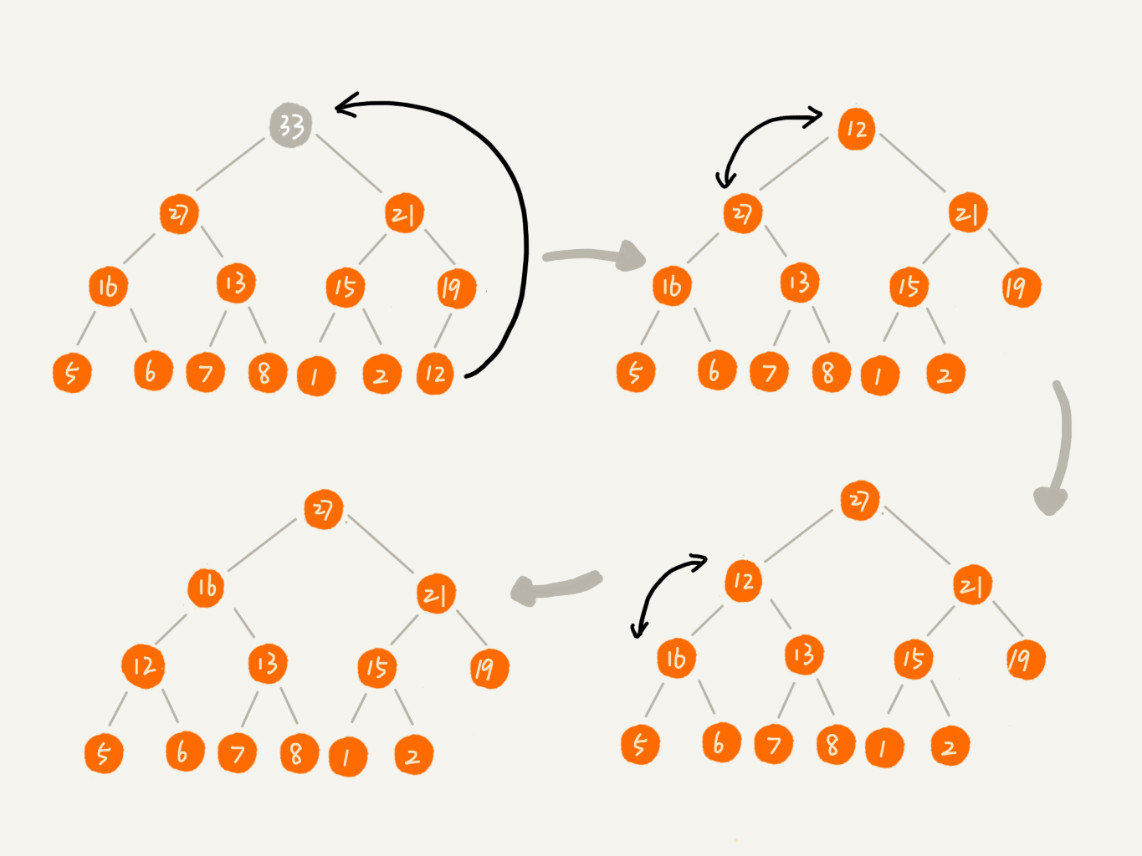
时间复杂度:
一个包含 n个节点的完全二叉树,树的高度不会超过 log2n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 O(logn)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(logn)。
3. 堆排序
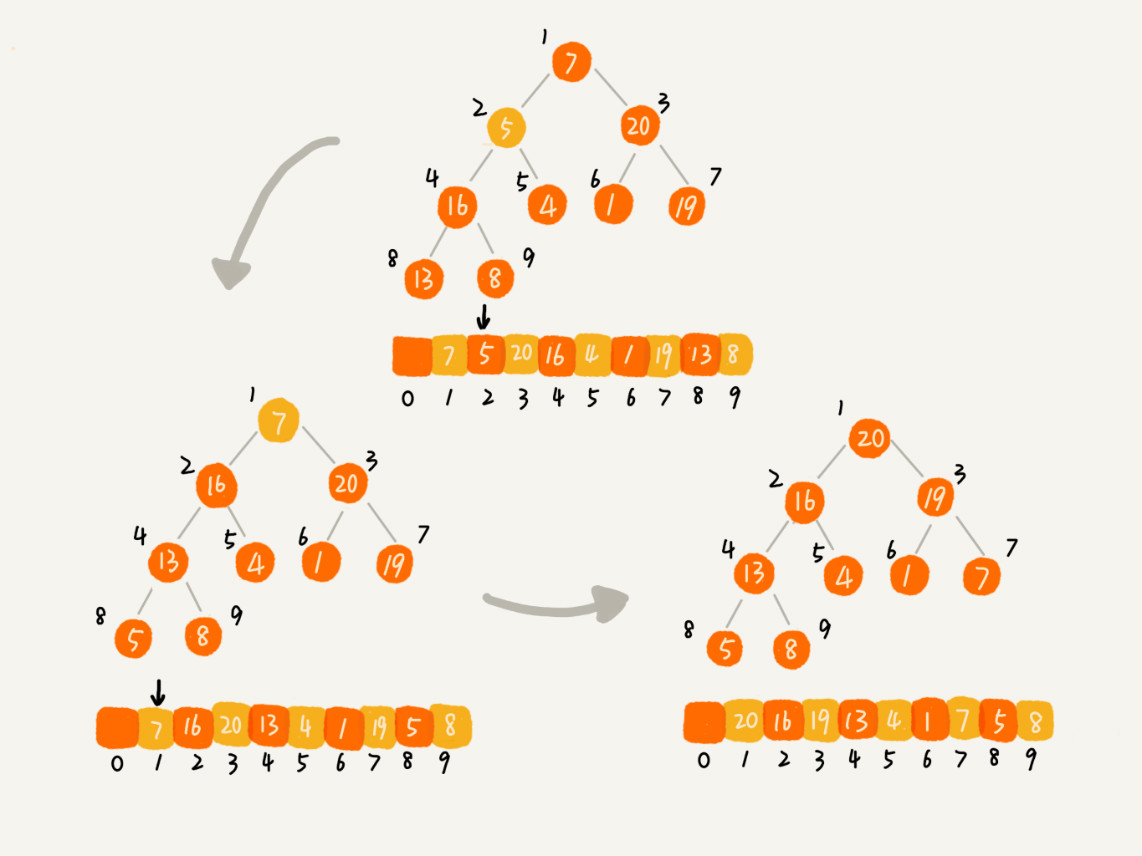
堆排序的过程大致分解成两个大的步骤,建堆 和排序。
建堆:
- 将数组构建成一个堆。
- 可以从前往后逐个插入元素构建堆(自下而上堆化)。
- 或者从后往前处理,使用自上而下堆化的方式来构建堆。
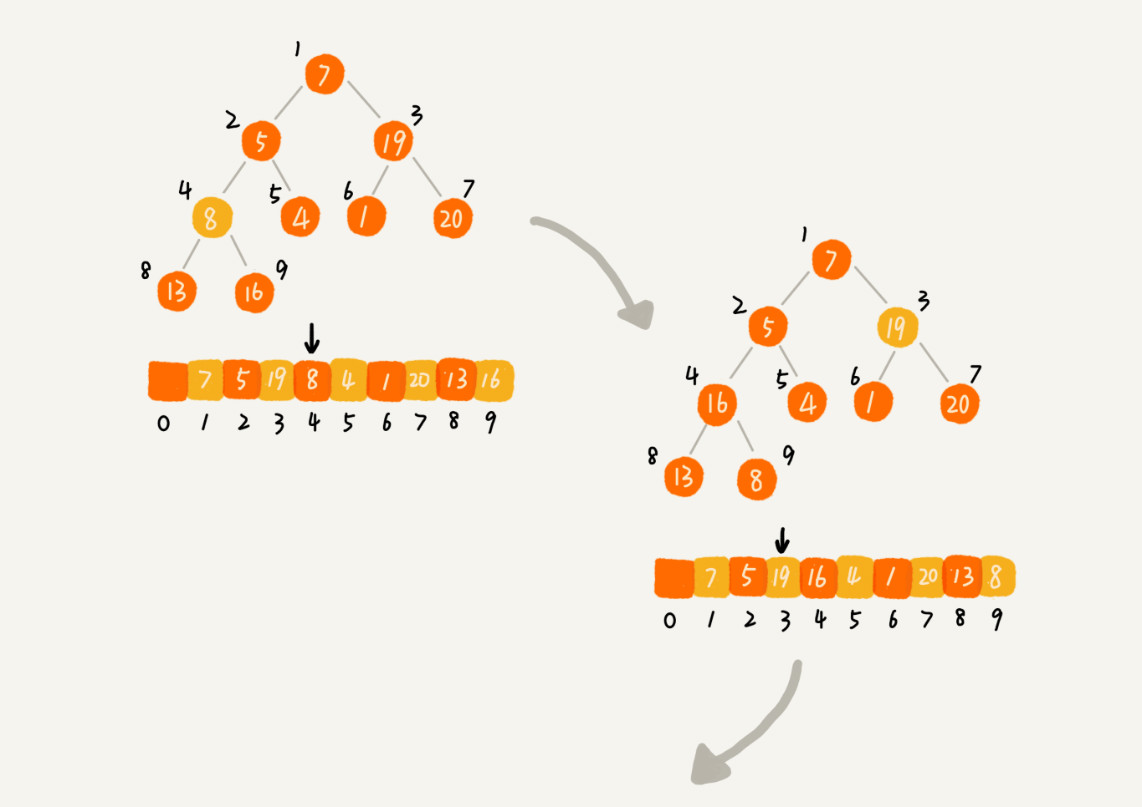
排序:
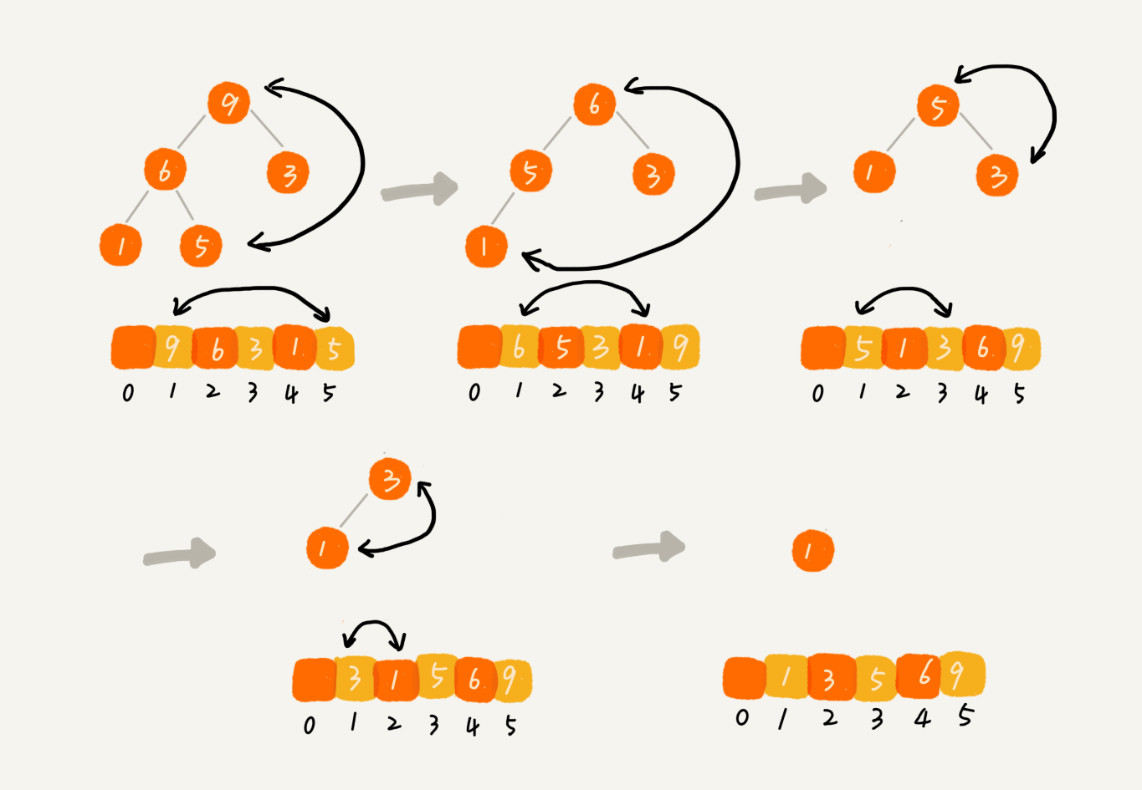
每次将堆顶元素(最大或最小)与最后一个元素交换,将堆的大小减小 1,然后进行堆化。重复此过程直到数组排序完成。
不是稳定的排序算法。
时间复杂度分析:
建堆:
虽然每个节点堆化的时间复杂度为 O(log n),但由于堆的层数递减,因此建堆的时间复杂度是 O(n)。
排序:
每次删除堆顶元素并堆化的时间复杂度为 O(log n),重复此过程 n 次,因此堆排序的总时间复杂度是 O(n log n)。
**快速排序 vs 堆排序:**性能对比表(实际开发视角)
|-----------|------------------------|------------------------------------------|
| 对比维度 | 快速排序(Quick Sort) | 堆排序(Heap Sort) |
| 数据访问模式 | 局部顺序访问:访问相邻元素,缓存友好 | 非顺序访问:跳跃式访问(如下标 1 → 2 → 4 → 8),缓存不友好 |
| 缓存命中率 | 高(连续访问内存,有利于 CPU 缓存预取) | 低(访问分散,频繁触发缓存未命中) |
| 数据交换次数 | 相对较少,尤其在数据部分有序的情况下 | 多:建堆过程中频繁打乱已有顺序,导致额外的交换 |
| 对初始有序性敏感 | 是(部分有序时性能更好) | 否(建堆打乱顺序) |
| 排序过程破坏有序度 | 否,尽量保持已有的顺序结构 | 是,建堆导致已有顺序被打乱 |
1.4. 堆的应用
1. 优先级队列(Priority Queue)
定义:
- 与普通队列不同,出队顺序按优先级高低而非 FIFO。
- 堆可高效实现优先级队列:
插入元素:O(logn)
取出优先级最高元素(堆顶):O(logn)
应用示例:
合并有序小文件:
- 场景:将 100 个 100MB 的有序小文件合并为一个大文件。
- 方案:
每个文件取一个字符串放入小顶堆。
每次从堆顶取最小值写入结果文件,再从对应文件中取下一个值加入堆。
时间复杂度大幅优于线性遍历(数组)。
高性能定时器:
- 维护很多任务,每个任务有执行时间。
- 传统方法每秒轮询扫描任务表,低效。
- 使用小顶堆优化:
堆顶存放最早执行的任务。
定时器睡眠到该任务执行时间,节省资源。
每次取堆顶更新下一次唤醒时间。
2. 利用堆求 Top K 问题
Top K 分为两类:
静态 Top K(一次性获取):
- 使用K 大小的小顶堆。
- 遍历整个数组:
若当前元素 > 堆顶:替换堆顶,重新堆化。
- 时间复杂度:
O(nlogK)
动态 Top K(实时查询):
- 维护一个固定大小为 K 的小顶堆。
- 插入新数据时:
若新数据 > 堆顶:替换堆顶。
否则忽略。
- 查询时直接返回堆中元素。
3. 利用堆求中位数(及任意百分位数据)
静态数据集合:
- 可直接排序取中位数,代价高但结果固定。
动态数据集合:
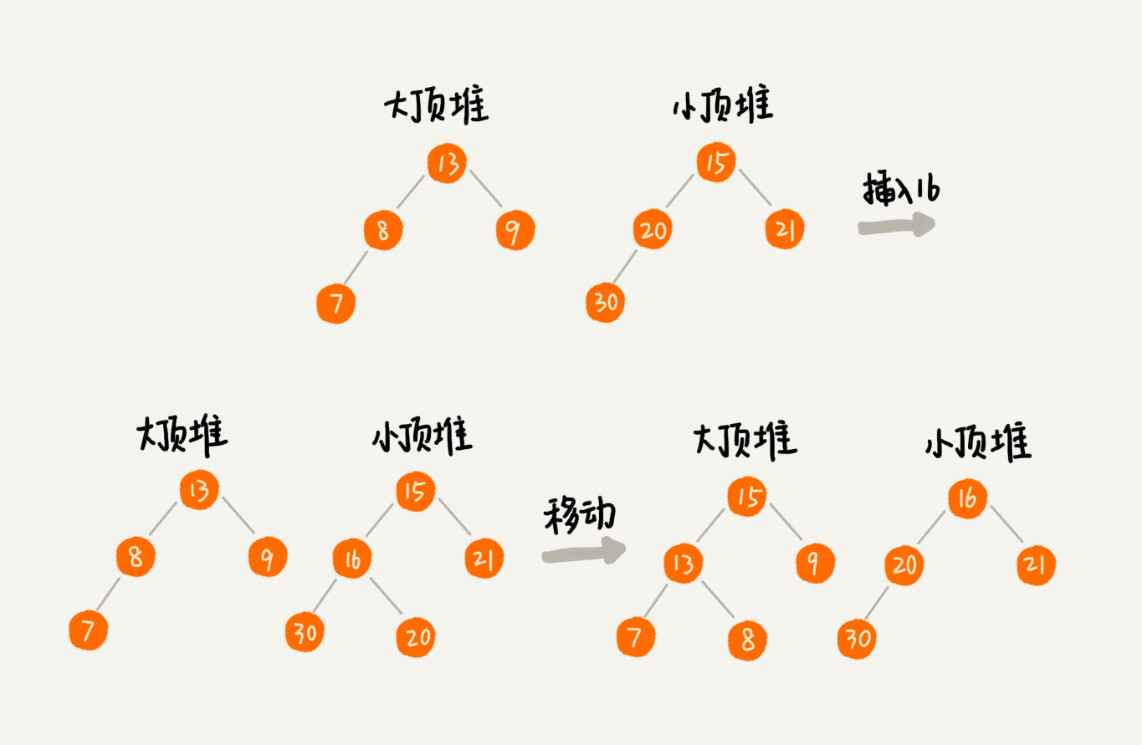
- 方法:双堆法
大顶堆(max-heap):存前半部分数据。
小顶堆(min-heap):存后半部分数据,且小顶堆中的数据都大于大顶堆中的数据。
保持两个堆平衡(大小相差不超过1)。
中位数取决于两个堆的堆顶元素。
优势:
- 每次插入数据后,只需调整两个堆即可,效率高。
- 实现实时获取中位数,时间复杂度约为
O(logn)。