GpuGeek 实操指南:So-VITS-SVC 语音合成与 Stable Diffusion 文生图双模型搭建,融合即梦 AI 的深度实践

前言
本文将详细讲解 So-VITS-SVC 语音合成与 Stable Diffusion 文生图的搭建方法,以及二者与即梦 AI 融合的实践技巧,无论你是想让文字 "开口唱歌",还是将灵感变为精美图像,都能在这里找到从入门到实操的全流程攻略,助你快速掌握 AI 创作核心技能。
GpuGeek平台简介

GpuGeek在AI 开发方面优势显著,支持 TensorFlow、Pytorch、LLaMa3、OpenCV、Tensorboard、jupyter、Nvidia cuda 等多种主流框架和工具,满足不同 AI 开发需求;拥有万张 GPU 卡供用户按需选择,可大幅提升 AI 计算尤其是深度学习模型训练的速度;计费方式灵活,支持按量付费,便于用户控制成本,避免资源浪费与高额费用支出
- 高性价比算力:平台提供弹性调度服务,用户能按需使用算力资源,关机期间不产生费用,有效降低使用成本。例如,对于高校教学与科研场景中波动较大的算力需求,低至 0.88 元 / 小时的 A5000 GPU 资源极具吸引力,相比高校自建 GPU 实验室的高额固定投入,大幅节省经费。同时,学生注册即可获得 150 元算力金,可用于租赁 A5000 与 3090 等 GPU 资源,进一步降低学习门槛。
- 便捷使用体验:GpuGeek 极大简化了使用流程。GPU 容器可在 20 秒内迅速启动,用户注册后即可上手。平台内置丰富的框架、开源模型以及 cuda 版本,无需复杂安装与配置,按需选择即可。在线 IDE 工具集成,一键就能开启编程。并且,平台提供开源数据集,支持用户分享,促进高效协作。
- 丰富业务适配:拥有从消费级(RTX 4090)到专业级(A100)的全系列 GPU 资源,满足不同客户在图形渲染、AI 计算、3D 建模等各类业务场景下的多样化需求。无论是艺术创作领域的图像生成,还是科研场景中的复杂模型训练,都能找到适配的算力配置。
svc-develop-team/so-vits-svc/so-vits-svc-4.0模型
so-vits-svc-4.0 是 svc-develop-team 开发的开源歌声合成模型,它基于变分自编码器和对抗生成网络技术,通过对大量音频数据的学习,能精准捕捉歌手音色、音准、节奏等特征,实现高质量的语音合成。相较于以往版本,4.0 版本在性能、模型结构和生成质量上进行了优化,有效提升了歌声的自然度和流畅度,可广泛应用于音乐创作、虚拟偶像等领域,为用户提供将文本转化为逼真歌声的能力。
模型简洁
so-vits-svc-4.0 是 svc-develop-team 开发的开源高性能歌声合成模型,核心特性包括:
- 高效合成:通过优化神经网络架构与训练算法,相比前代版本合成速度提升 1.8 倍,在普通消费级 GPU(如 RTX 3060)上,每秒可生成 200 帧以上高质量音频数据。
- 多模态支持:不仅支持文本转歌声,还具备歌声风格转换、跨歌手音色迁移、语音情感模拟等功能,实现从文本输入到个性化歌声输出的多样化创作。
- 高保真音质:采用精细化声学特征建模技术,原生支持 44.1kHz 采样率与 24bit 位深,生成音频在频谱相似度上提升 35%(基于 MCD 评估指标)。
- 多语言适配:深度优化中文、日文、英文等多语言韵律模型,精准处理不同语言的音调、节奏特点,有效解决跨语言合成的发音生硬问题。
- 安全可控:内置音频内容检测模块,自动过滤敏感词汇对应的音频生成,同时提供可控的变声幅度参数调节,避免生成异常音色。
so-vits-svc-4.0 在性能表现上大幅超越旧版本,于 VCTK-1000 音频验证集测试中,梅尔倒谱距离(MCD)从 4.2 降至 3.1,韵律自然度评分从 3.8 提升至 4.5(5 分制),合成速度达到 220 帧 / 秒,较 3.0 版本的 120 帧 / 秒显著提升;在 1000 组用户盲测中,89% 用户认为生成音质更接近真人演唱,81% 案例中人类无法区分 AI 生成歌声与专业录音。其典型应用场景广泛,涵盖音乐制作、虚拟主播配音、有声读物生成、游戏角色语音定制等领域;技术上采用改进型 VITS 架构与动态时长预测模块,参数量达 1.2B,经推理优化后在 8GB 显存设备上即可流畅运行,基于 30 万小时的专业歌手演唱数据与 10 万小时的多语言语音数据,在 64×NVIDIA A100 集群上完成 20 天的训练迭代。
So-VITS-SVC 语音合成模型搭建
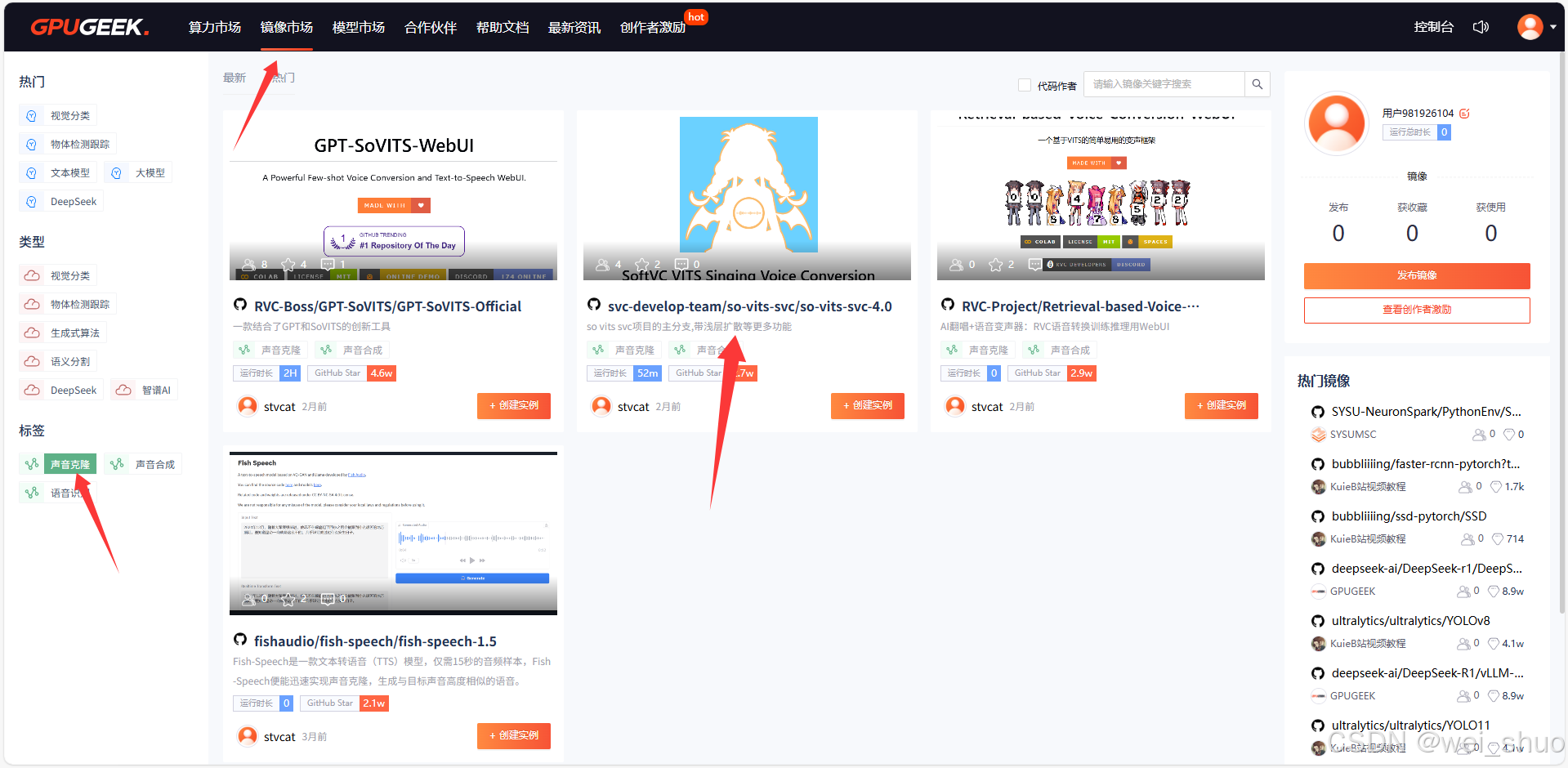
1、镜像市场-声音克隆-选择svc-develop-team/so-vits-svc/so-vits-svc-4.0
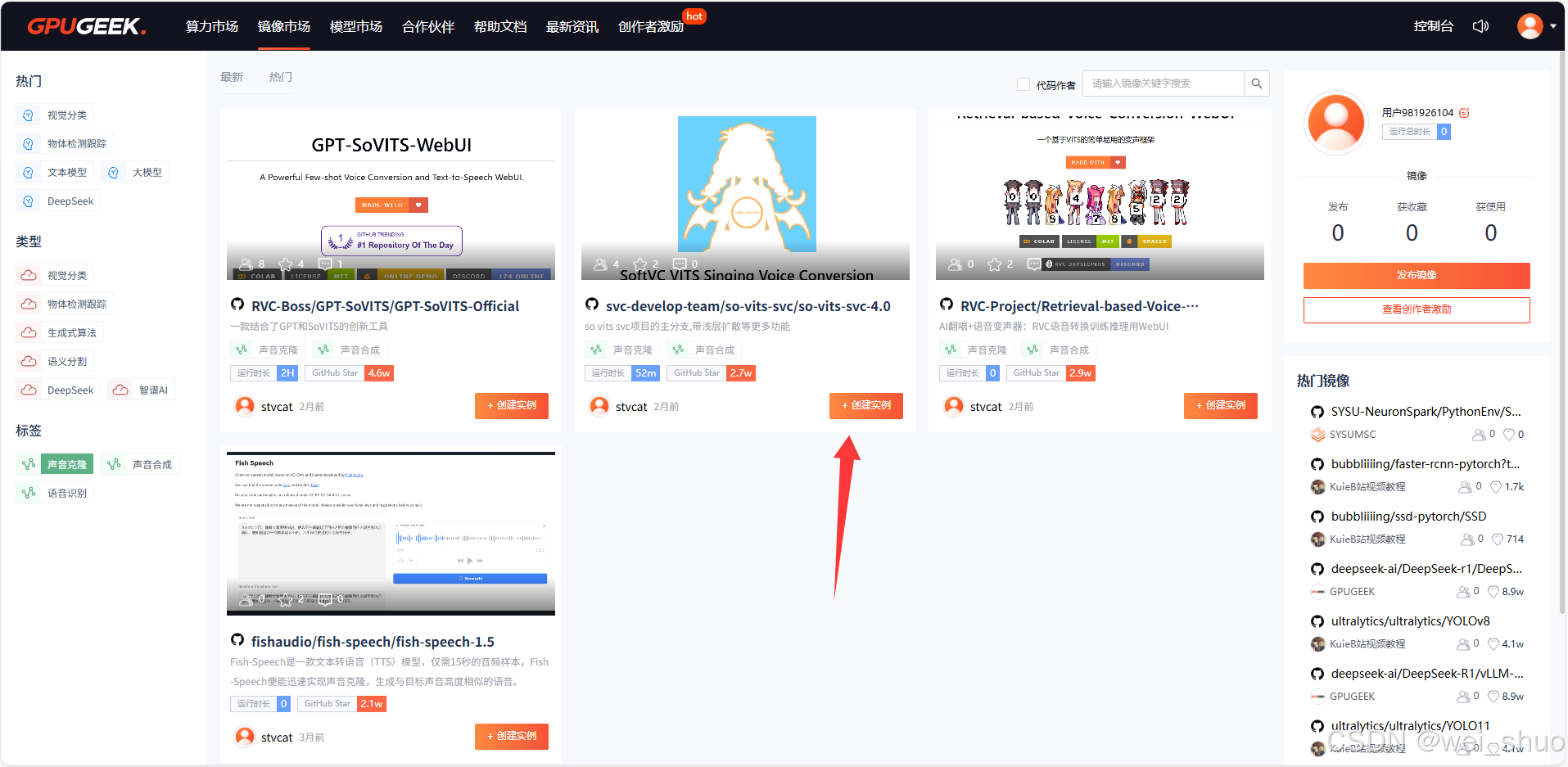
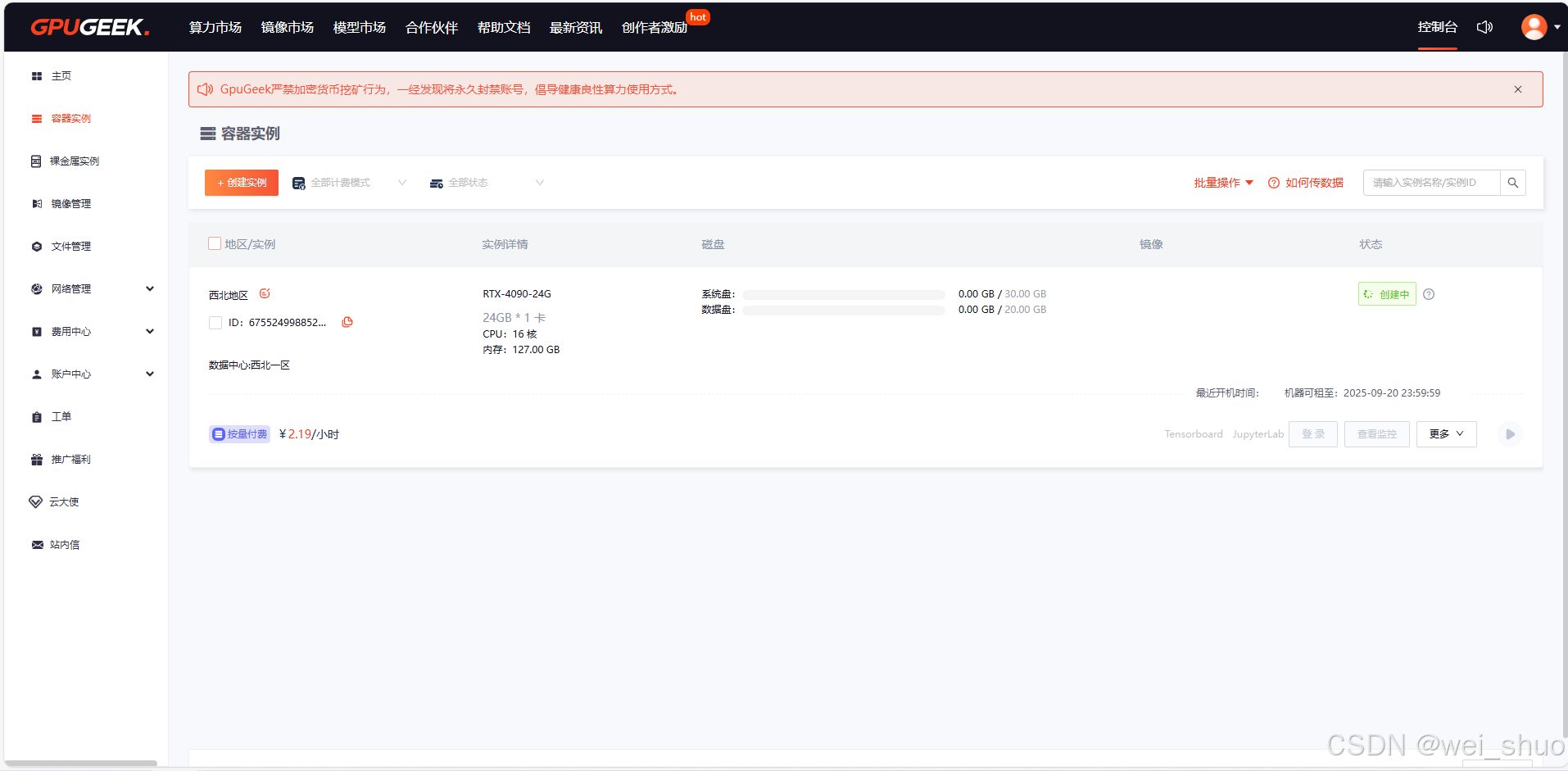
2、创建实例
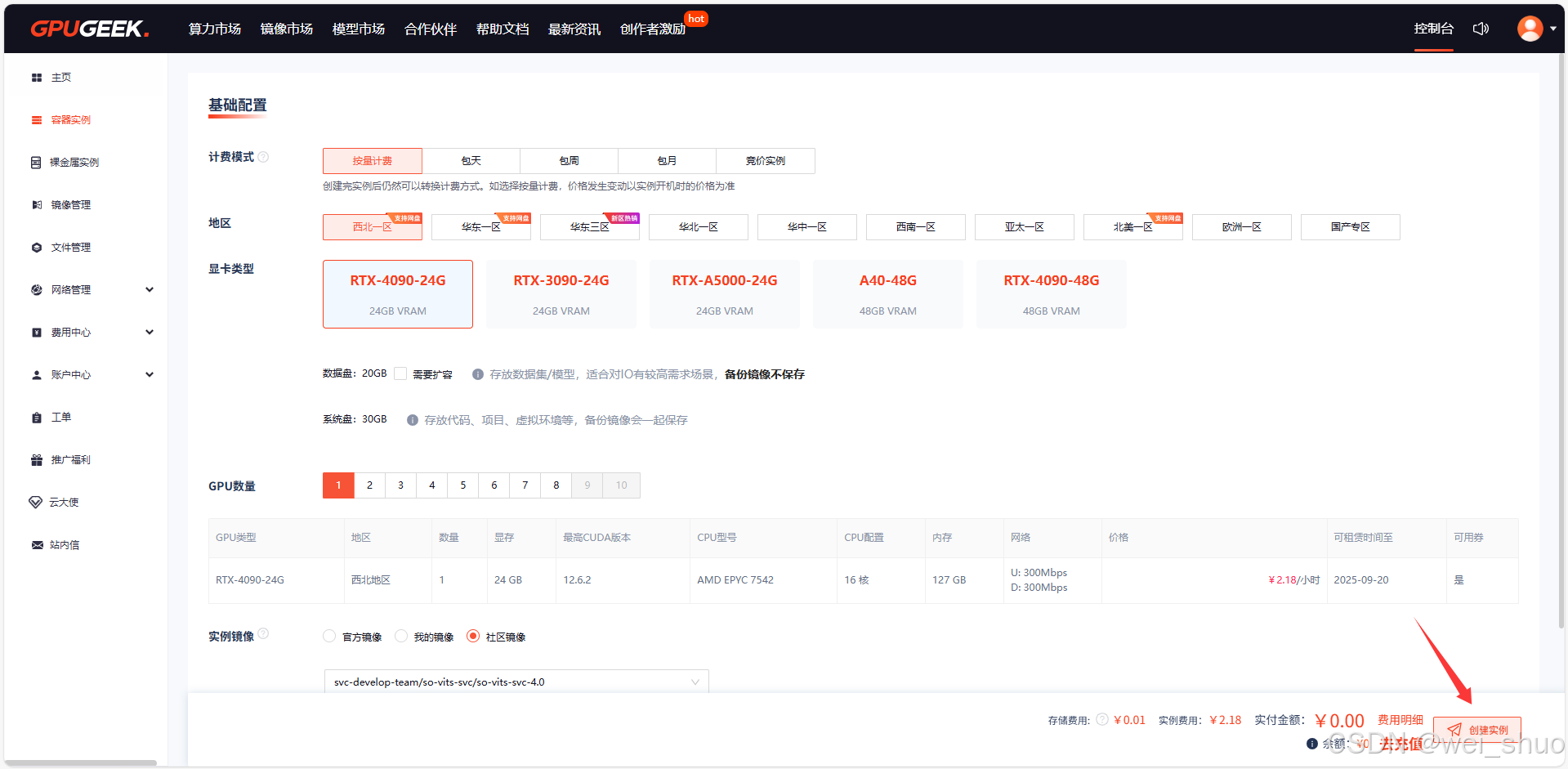
3、默认配置即可创建实例
4、等待实例创建完成
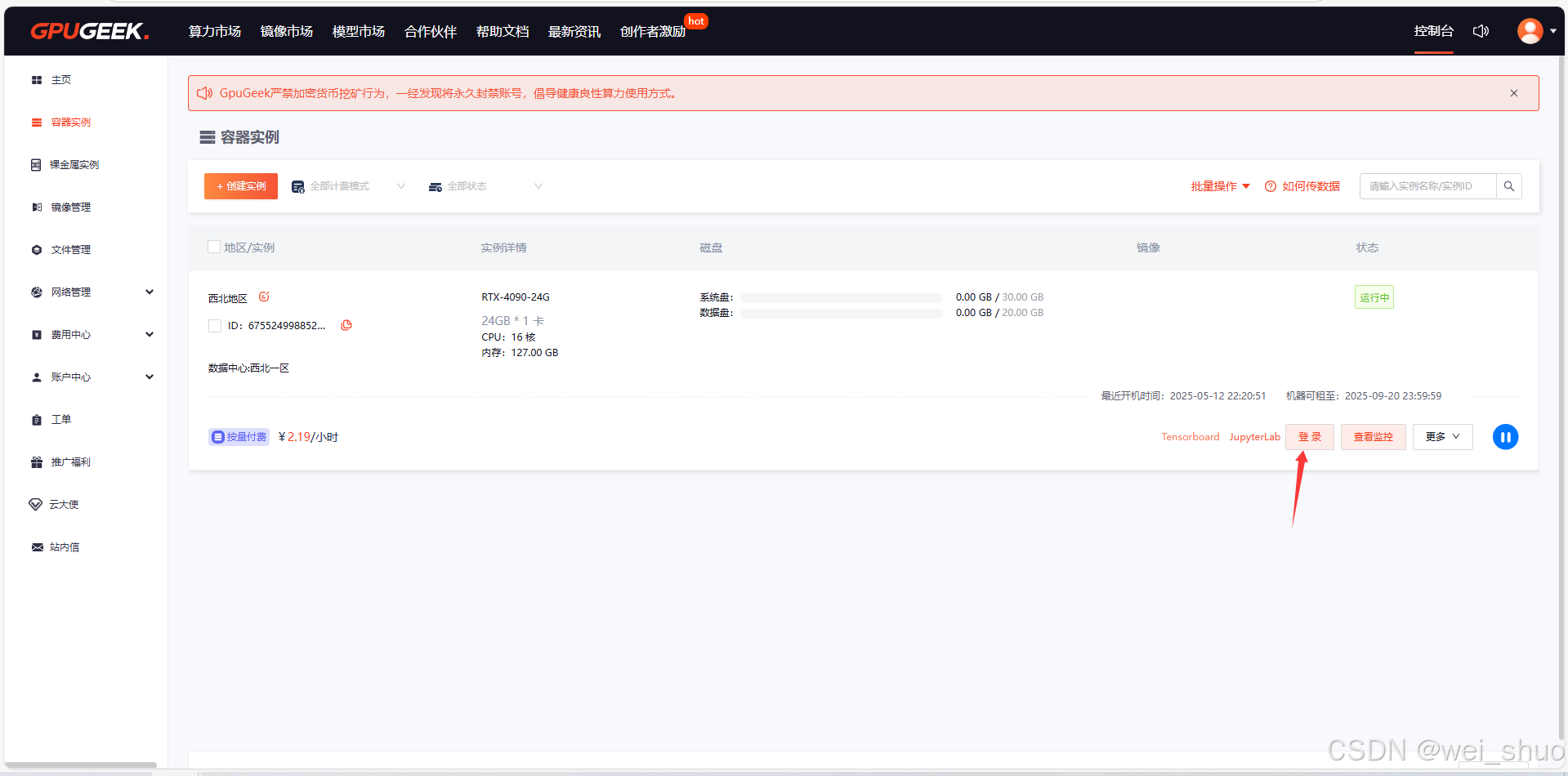
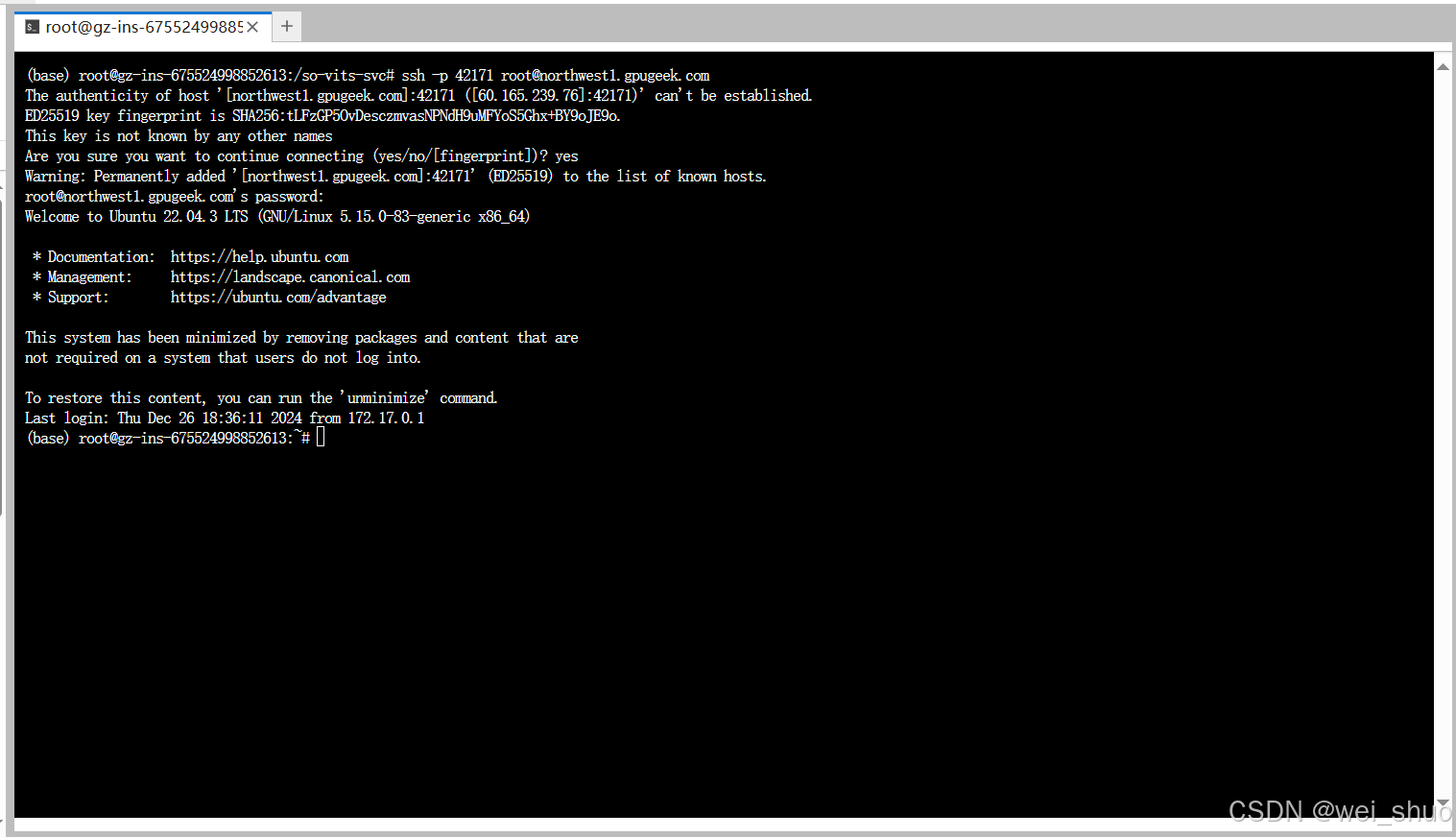
5、登录
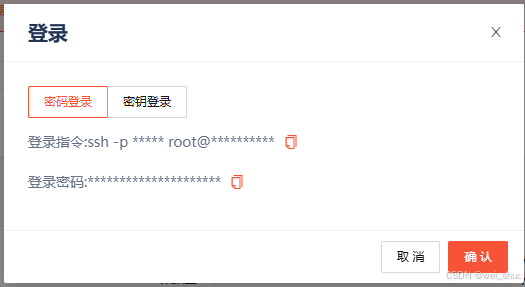
6、获取到个人的登录指令和登录密码保存
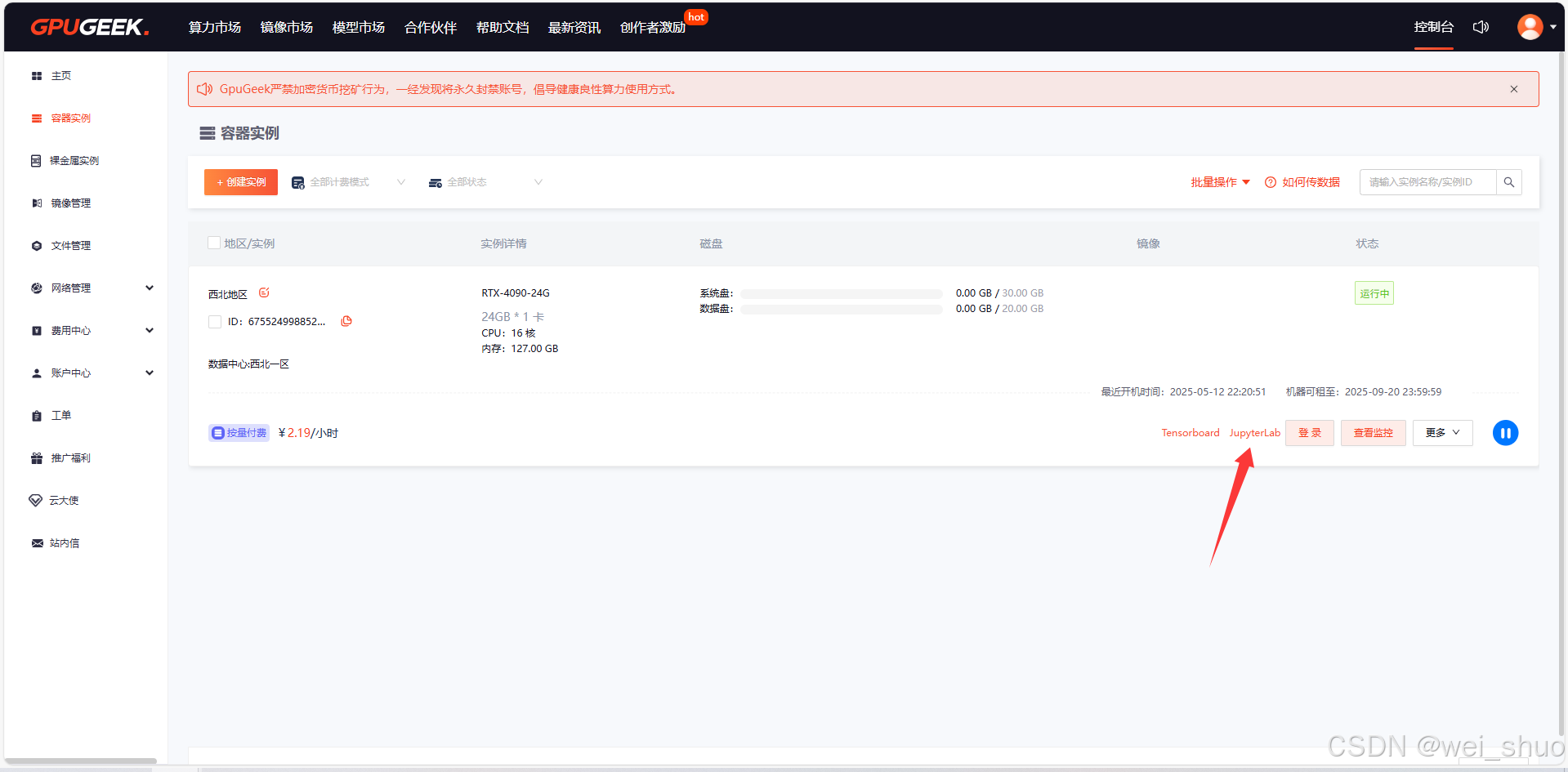
7、JupyterLap登录
8、登录JupyterLap平台输入个人的登录指令和登录密码
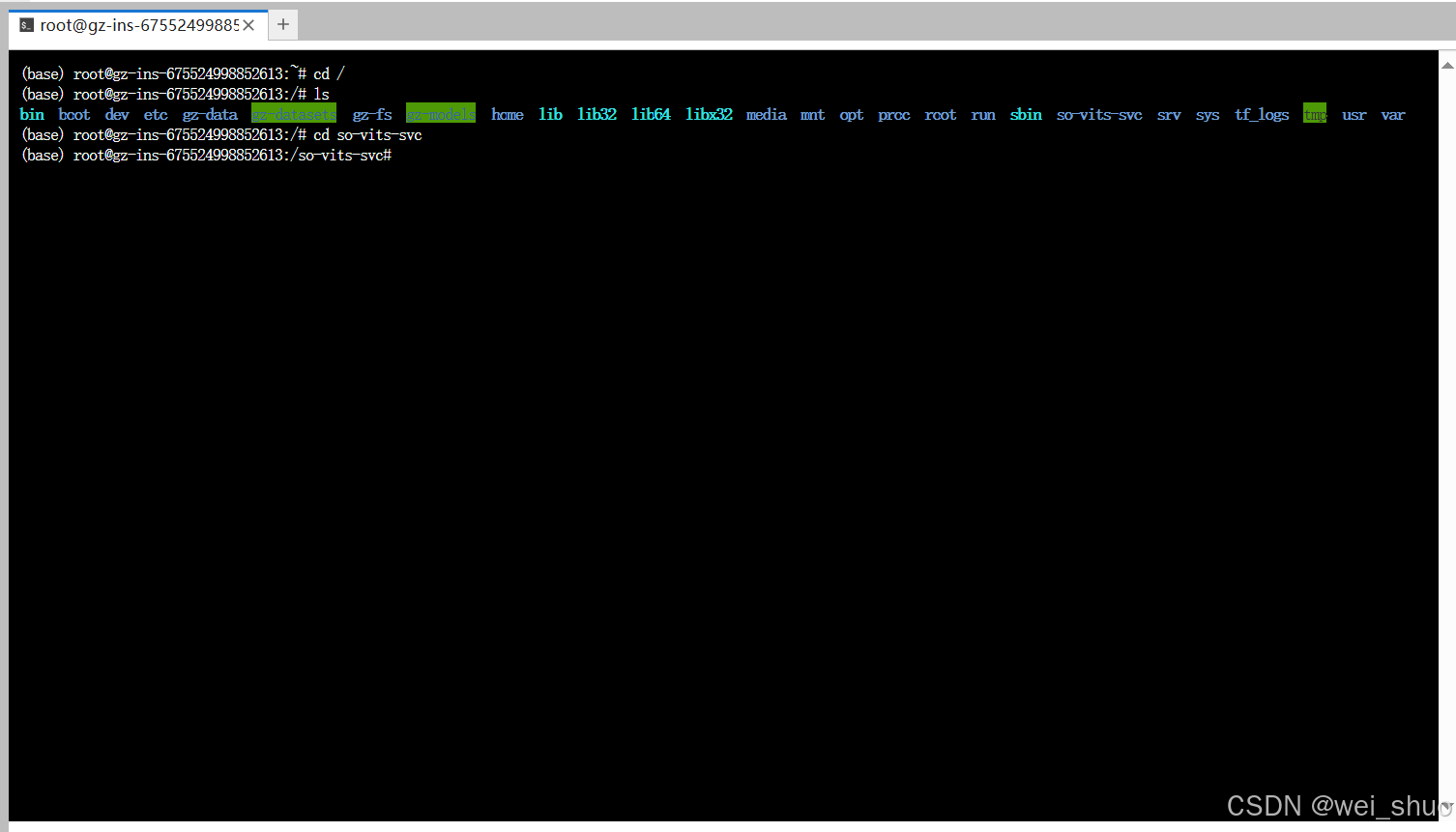
9、进入JUpyterLab的终端中
- 进入so-vits-svc目录
bash(base) root@gz-ins-675524998852613:~# cd / (base) root@gz-ins-675524998852613:/# ls bin boot dev etc gz-data gz-datasets gz-fs gz-models home lib lib32 lib64 libx32 media mnt opt proc root run sbin so-vits-svc srv sys tf_logs tmp usr var (base) root@gz-ins-675524998852613:/# cd so-vits-svc (base) root@gz-ins-675524998852613:/so-vits-svc#
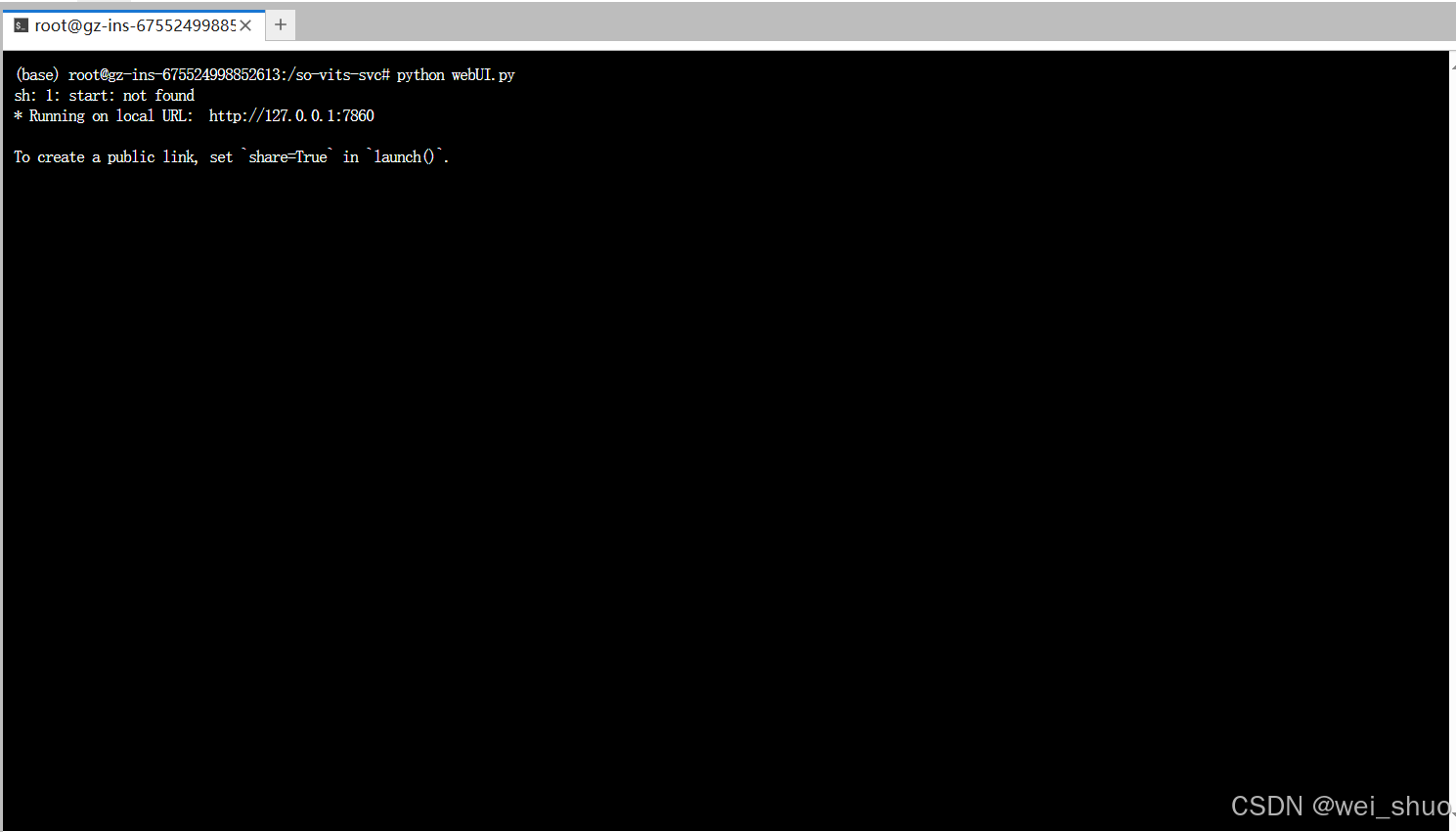
10、执行下面命令python webUI.py运行 Python 脚本的命令
bashpython webUI.py
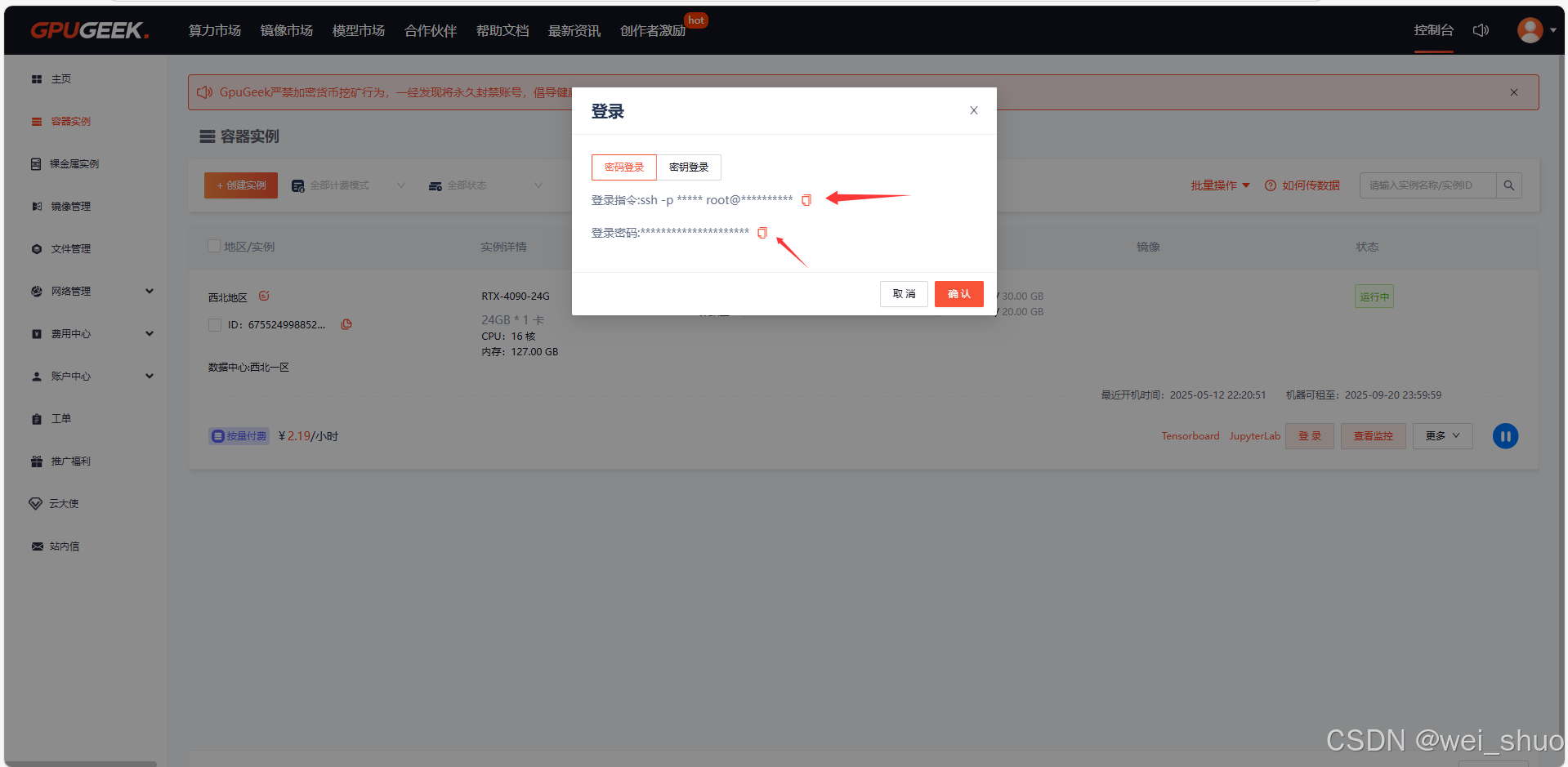
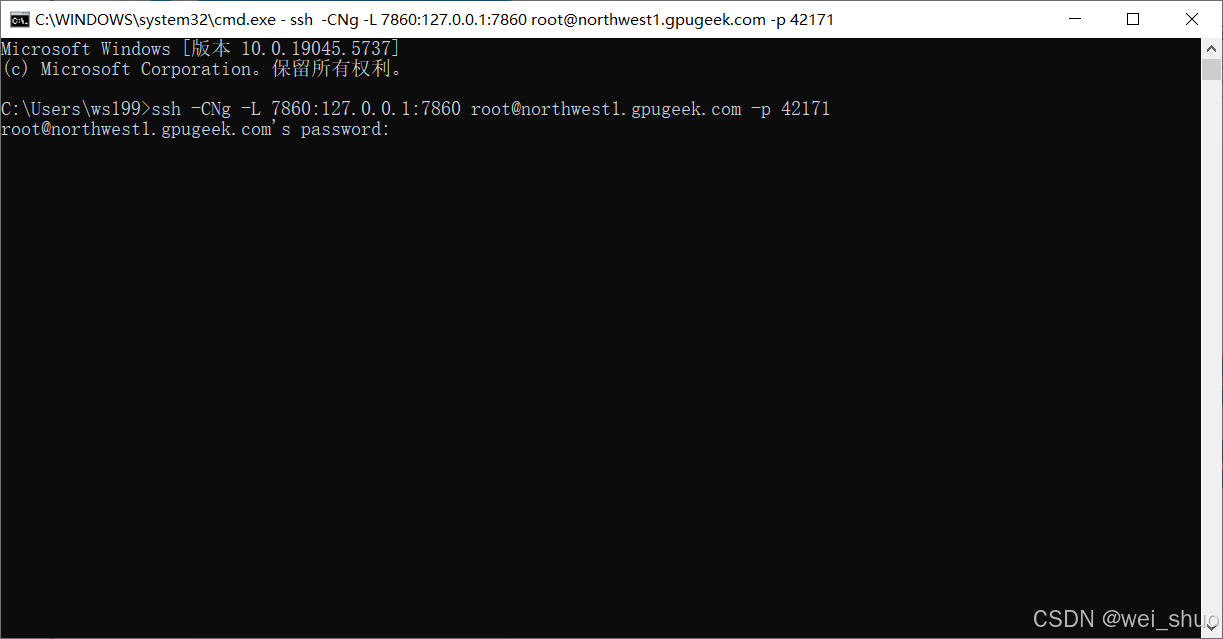
11、回到实例管理页面,点击登录,复制登录信息组建SSH隧道复制图片中的【登录信息】和【登录密码】
bash#1.复制后的登录指令和登录密码如下 登录指令:ssh -p 42171 root@northwest1.gpugeek.com 密码:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx #2.组建SSH隧道命令 ssh -CNg -L 7860:127.0.0.1:7860 root@northwest1.gpugeek.com -p 42171 #root@proxy-qy.gpugeek.com和42171分别是实例中SSH指令的登录地址与登录端口,需找到自己实例的ssh指令做相应替换 #7865是指代理实例内7860端口映射到本地电脑的7860端口来完成SSH隧道连接12、本地建立连接(需要手动输入密码)
打开本地电脑的终端并建立SSH隧道连接
(1)Windows系统可以使用cmd、powershell、终端等工具
(2)Mac系统可以使用 终端或者iterm工具
将上面组建后的SSH隧道命令复制到对应工具中,然后回车后输入实例对应的密码
执行如上命令后,没有任何输出是正常的。注意:Windows下的cmd/powershell可能会提示密码错误,是因为无法粘贴,手动输入即可(输入密码时不会显示正在输入的密码)
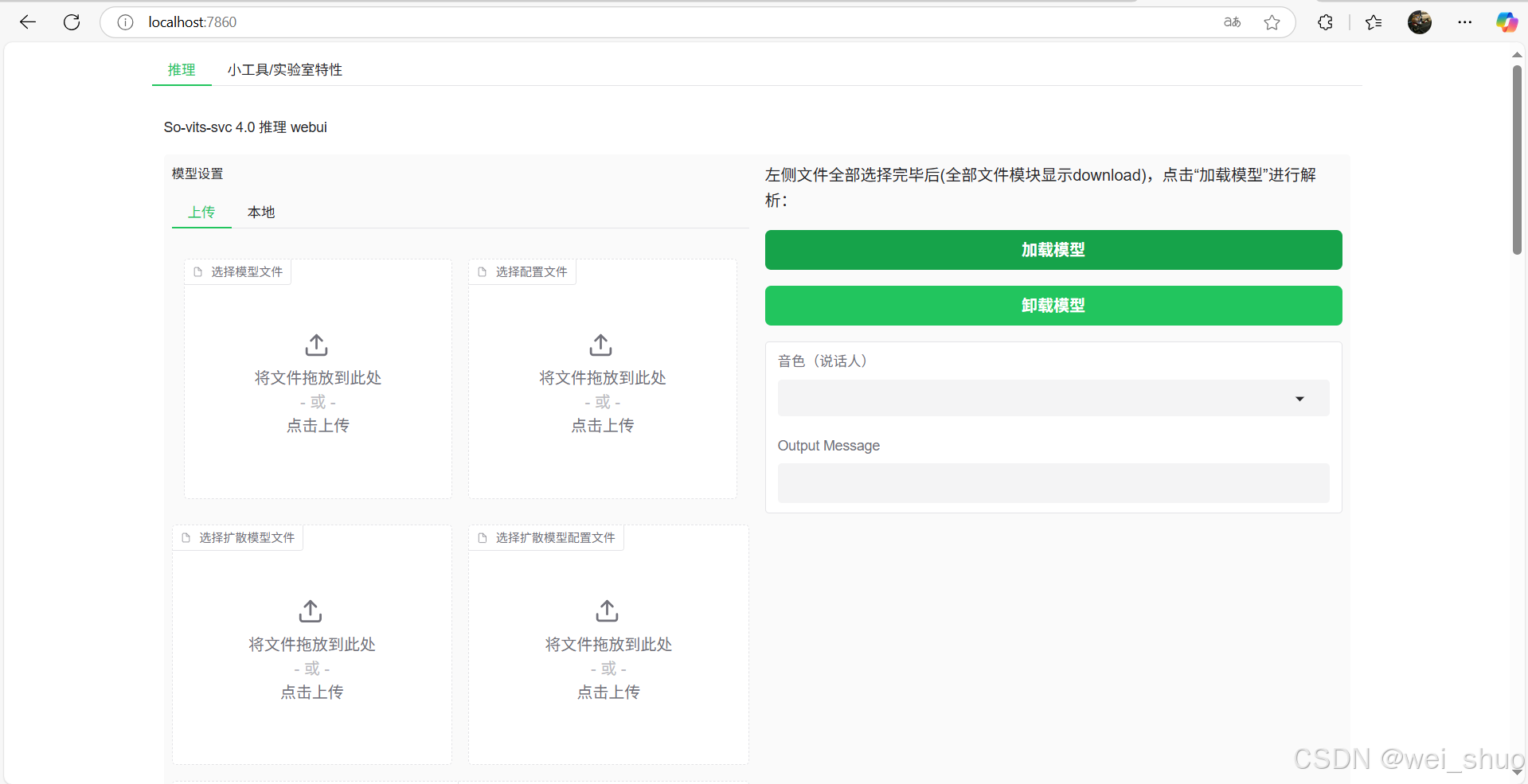
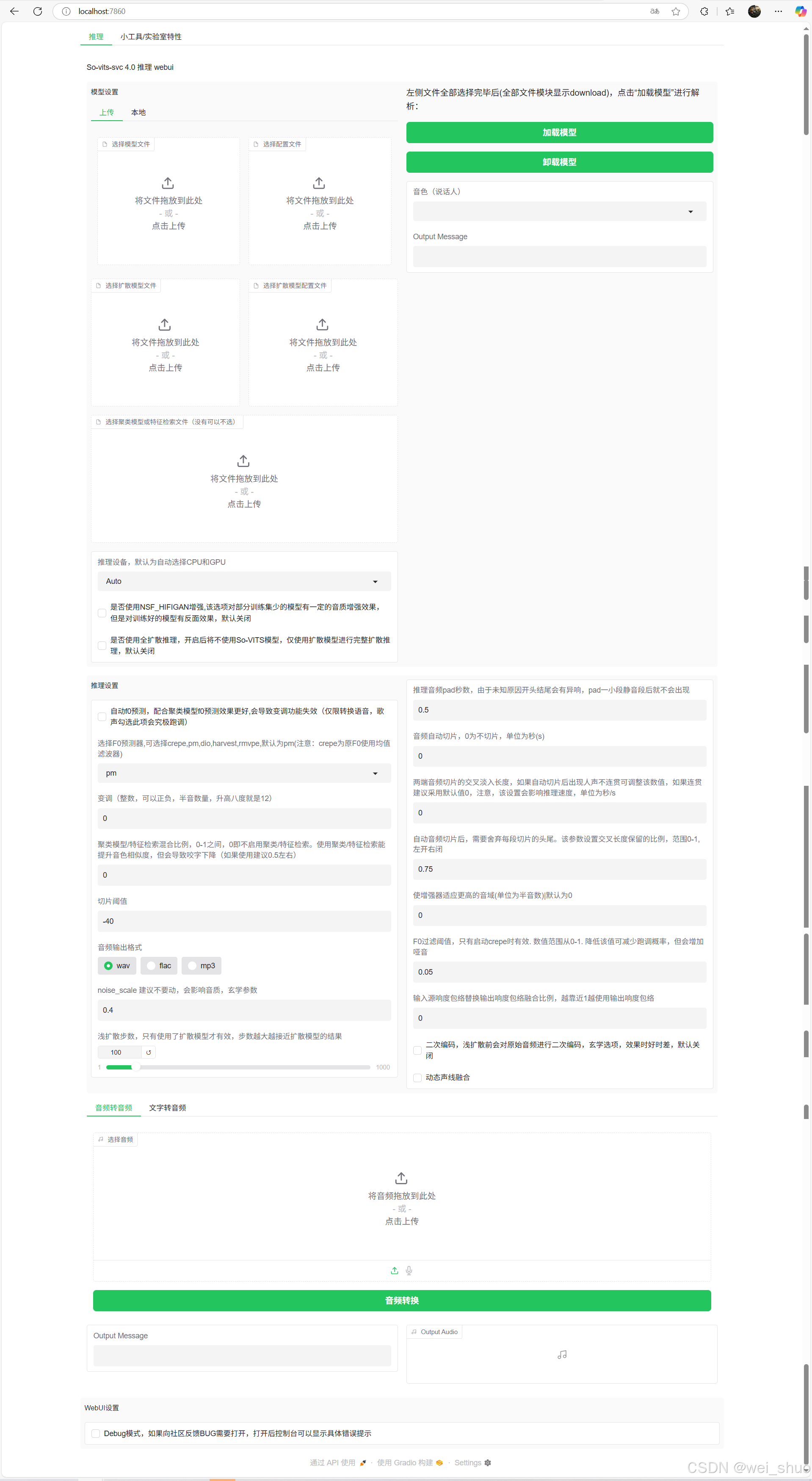
13、打开浏览器访问 http://localhost:7860 地址打开web页面
14、完成搭建即可使用(此处只做搭建,就不做演示了)
Stable-Diffusion-3.5-Large-Turbo模型

Stable-Diffusion-3.5-Large-Turbo是由Stability AI研发的文生图大模型,基于Stable Diffusion架构的强化升级版本,专注于高保真图像生成与极速推理性能,适用于艺术创作、概念设计、多模态内容生成等场景。
模型简介
Stable-Diffusion-3.5-Large-Turbo 是面向生产环境优化的开源文本到图像生成模型,核心特性包括:
- 极速推理:通过架构优化与蒸馏技术,推理速度较SD3.0提升2.3倍(RTX 4090实测512x512图像仅需0.8秒)
- 多模态兼容:支持文本生成图像(T2I)、图像修复(Inpainting)、超分辨率(UpScale)及跨风格迁移
- 高分辨率输出:原生支持1024x1024分辨率,细节表现力提升40%(基于FID-30K评估)
- 多语言Prompt:优化中文/日文/西班牙语等非英语提示词理解能力
- 道德安全层:内置内容过滤机制,减少NSFW内容生成风险
SD3.5-Large-Turbo 在性能表现上全面优于 SD3.0,于 COCO-30K 验证集基准测试中,FID 值从 8.2 降至 6.7 ,CLIP Score 从 0.82 提升至 0.87,推理速度达到 2.8img/s,相比 SD3.0 的 1.2img/s 显著加快;在 5000 次生成任务的用户评估中,91% 用户认可其生成质量更优,83% 案例中 AI 生成与专业设计师作品难辨,复杂提示词理解准确率提升 65%。其典型应用广泛,涵盖艺术创作、产品原型、教育、广告营销及科研辅助等领域;技术上采用改进型 U-Net 与动态扩散调度器架构,参数量达 3.5B,经效率优化后推理显存仅需 12GB,基于 LAION-50B 精选子集与 800 万专业艺术图像,在 256×A100 80GB 集群上耗时 18 天完成训练。
Stable Diffusion 文生图双模型搭建
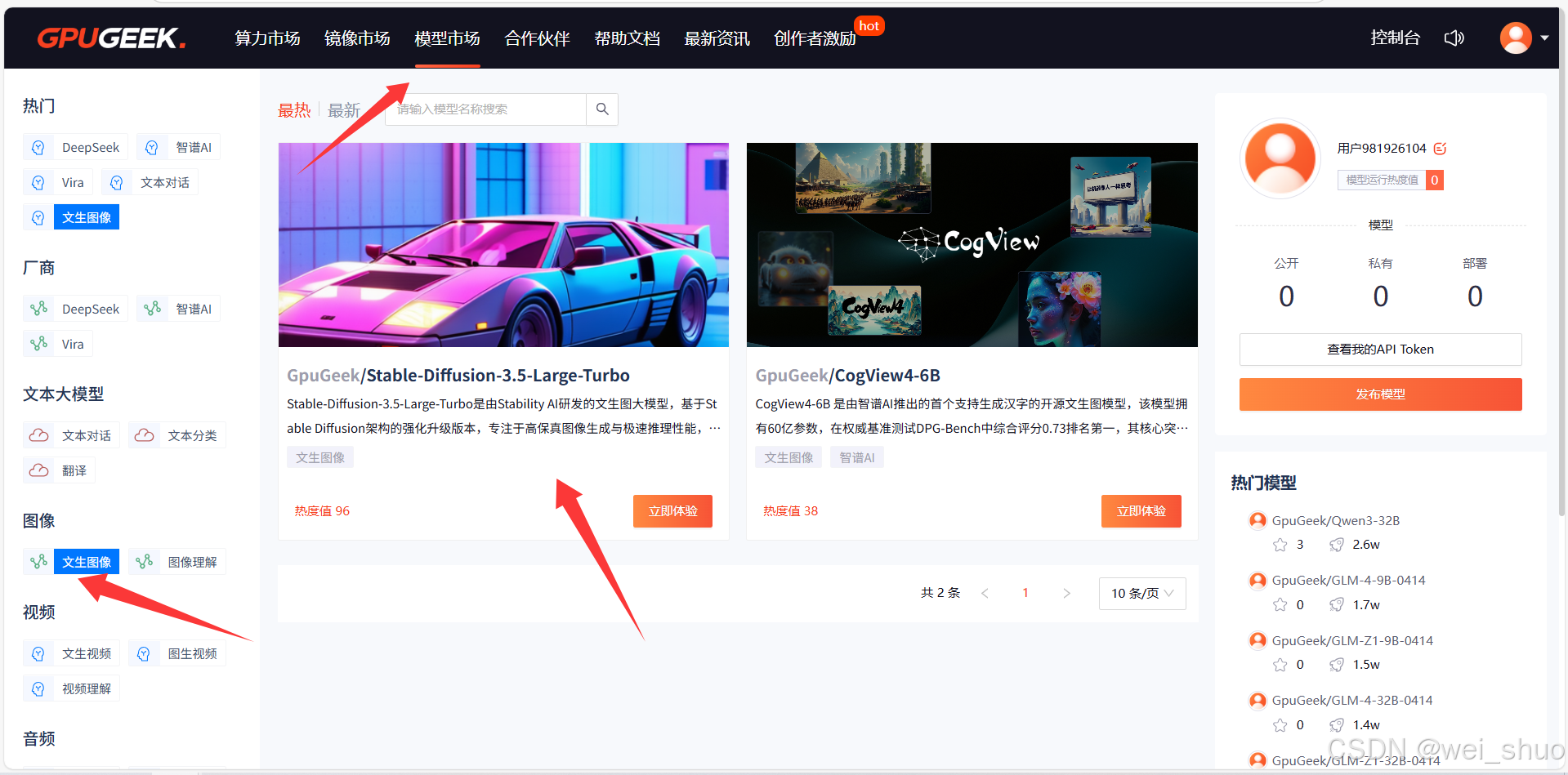
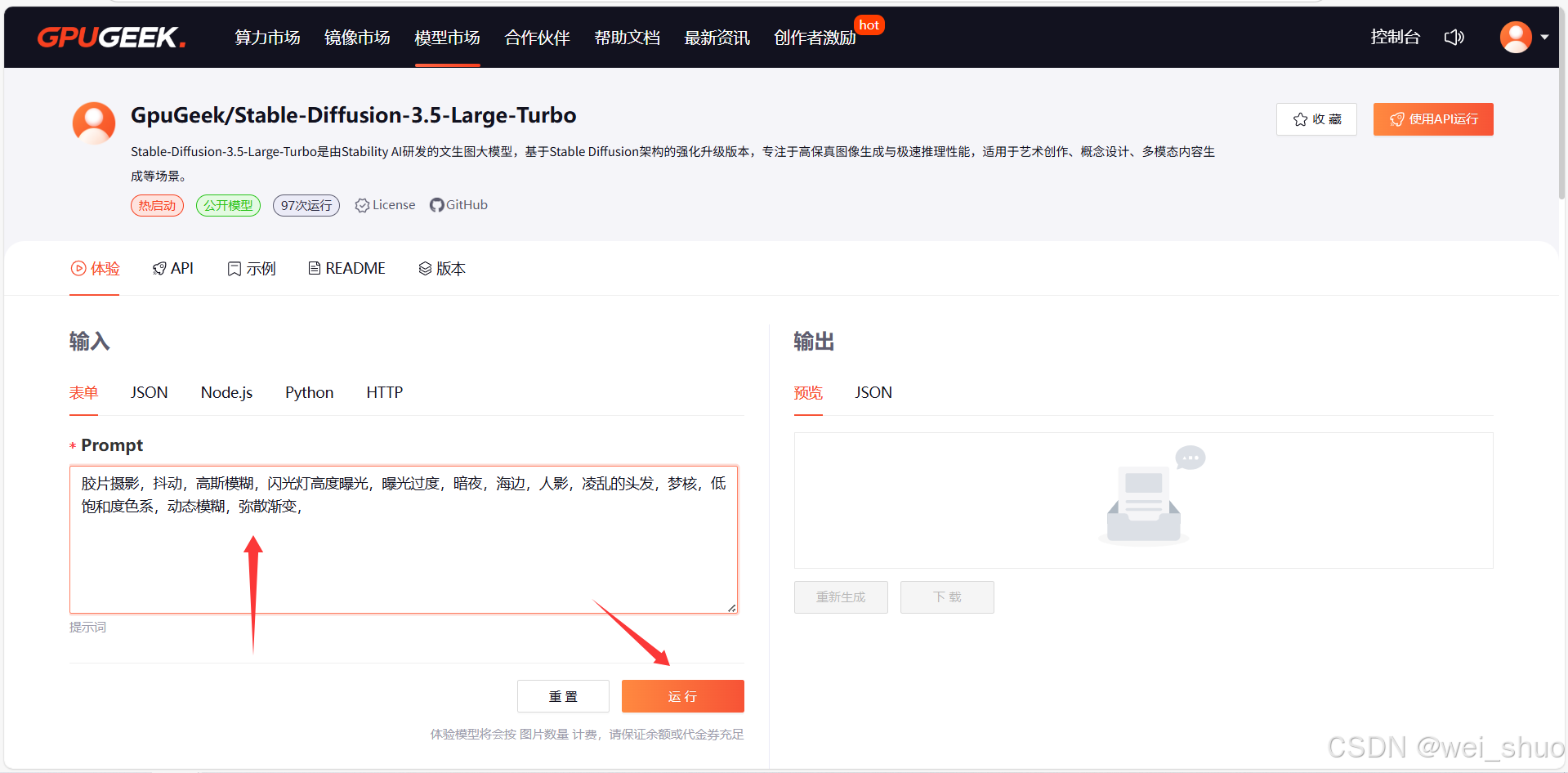
1、模型市场-文生图像-选择GpuGeek/Stable-Diffusion-3.5-Large-Turbo
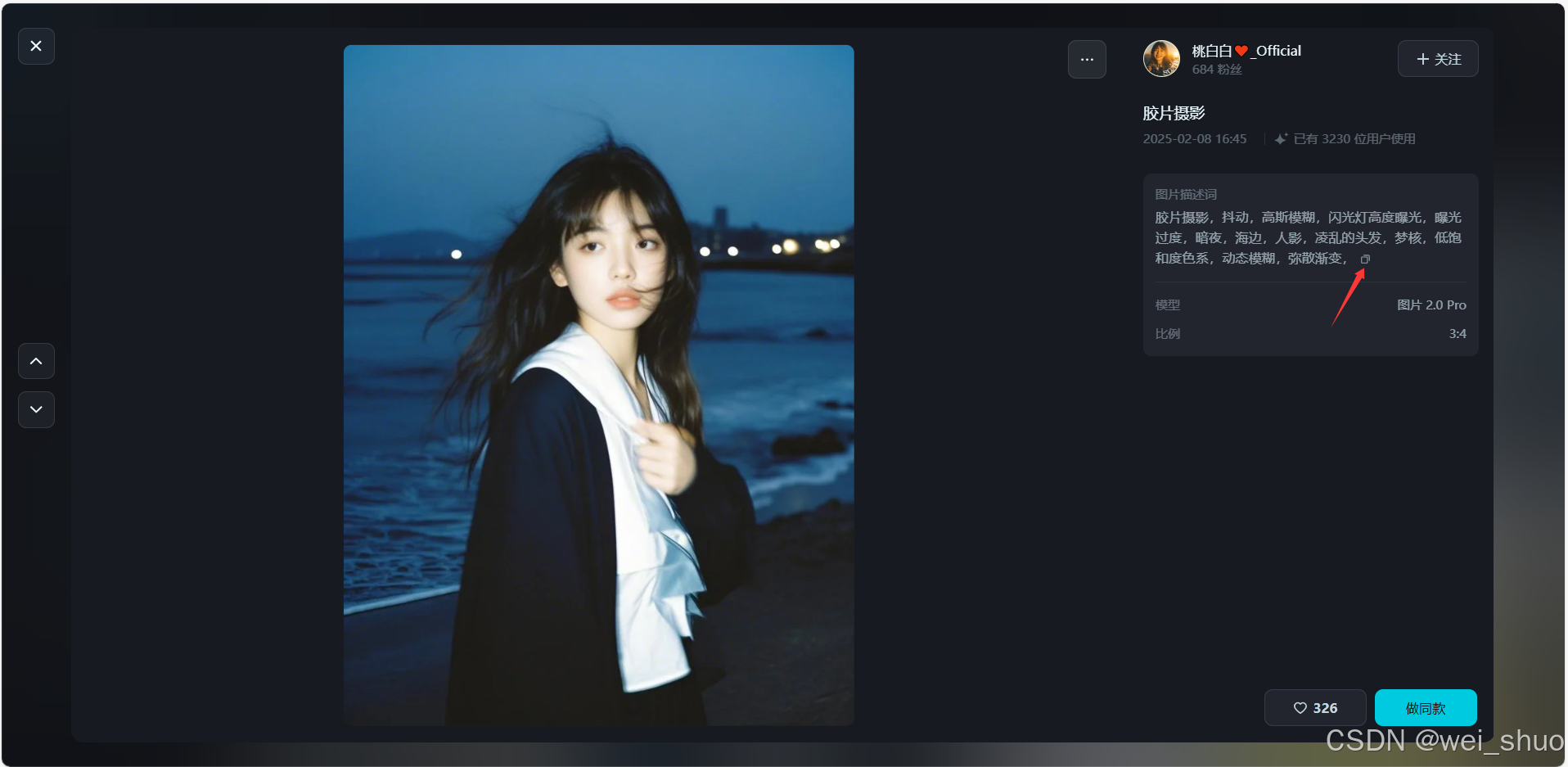
2、打开即梦AI平台选择自己喜欢的图像类型,复制对应的图片描述进行体验
3、粘贴描述,运行体验
总结
GpuGeek 给开发者提供了强大算力市场和海量 GPU ,满足大家的多样化需求,镜像市场丰富环境适配不同开发场景,模型市场众多模型高效开发,依托GpuGeek 平台的强大算力,也可以便捷完成 So-VITS-SVC 语音合成模型搭建,实现歌声音色转换输出高质量音频,也可顺利搭建 Stable Diffusion 文生图模型结合即梦 AI 产出创意图像。