**前言:**哇,今天终于能访问豆瓣了,前几天爬太多次了,网页都不让我访问了(要登录)。
先来个小练习试试手吧!
爬取豆瓣第一页(多页同上篇文章)所有电影的排名、电影名称、星级和评分,并用Excel存储
网址是:豆瓣电影 Top 250 大家先自己尝试一下吧,还是简单的,我就直接放代码了
python
import requests
from bs4 import BeautifulSoup
import pandas as pd
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
r=requests.get("https://movie.douban.com/top250",headers=headers)
if r.status_code!=200:
raise Exception("error")
soup=BeautifulSoup(r.text,"html.parser")
datas=[['排名','电影名称','星级','评分']]
articles=soup.find_all('div',class_='item')
for article in articles:
rank=article.find('em').get_text()
title=article.find('span',class_='title').get_text() #星级在class属性里,get('class')返回的是列表,因为HTML的class属性可以包含多个类名,因此BeautifulSoup将其存储为一个列表
star=article.find('div',class_='bd').find('span').get('class')[0].replace('rating','').replace('-t','') #string的replace方法,只保留数字
score=article.find('span',class_='rating_num').get_text()
datas.append([rank,title,star,score])
df=pd.DataFrame(datas)
df.to_excel('doubanTop25.xlsx')easy吧,不过,值得提一下的是,网页带小数星级的表示不准确,4.5星级为45

可以观察到star与score都在同一个div标签下,所以还可以用这两行代码代替
python
data=article.find('div',class_='bd').find('div').find_all('span')
star,score=data[0]['class'][0],data[1].get_text() #这样star就是一整个字符爬取动态加载的网页
我们来试着爬取杭州今年5个月的天气数据(最近都是下雨,有点不喜欢哦,小小的毛毛细雨我觉得还好,但是大暴雨真是什么都不方便)
我们选择不同的月份,可以发现网页的url都没有发生改变,说明这个网页不是静态网页,它是后台异步加载的动态网页,我们表面不能知道它实际的链接的,那么我们需要抓包来进行分析。
右键,点击"检查",点击"网络"
不要直接点击"重新加载页面",那会加载大量页面弹出来一大堆。我们再次查询一个月份信息,发现后台会发送一个请求"GetHistoty......"(或者点击Fecth/XHR这是发送异步请求的意思,里面就是我们要抓的包)
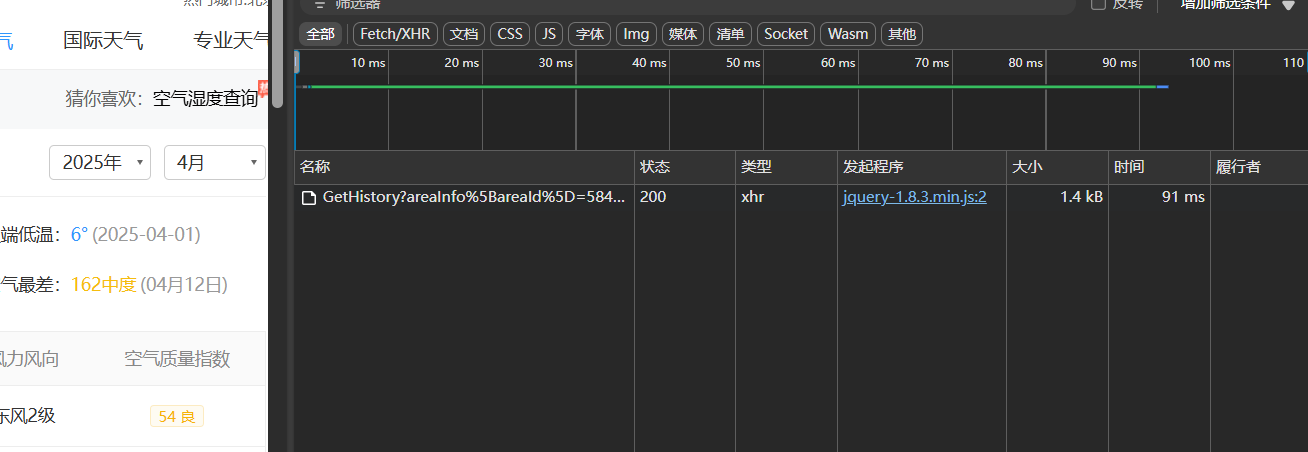 点击"请求"进去看一下,可以发现"请求URL"与网页上方的url不是同一个,这个就是异步加载的,请求方式为"GET"。复制URL"?"前面的部分(后面是参数部分,都在负载里)为url
点击"请求"进去看一下,可以发现"请求URL"与网页上方的url不是同一个,这个就是异步加载的,请求方式为"GET"。复制URL"?"前面的部分(后面是参数部分,都在负载里)为url
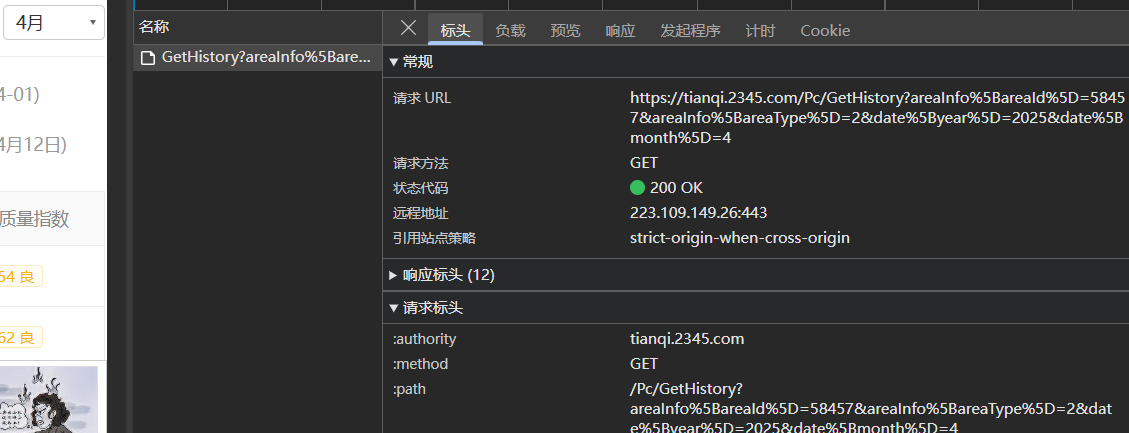
复制"请求标头"里的User-Agent,设置为headers用于反爬

这个网站的反爬做的有点好啊,还需要设置headers的Referer属性 ,也在请求标头里面,复制下来
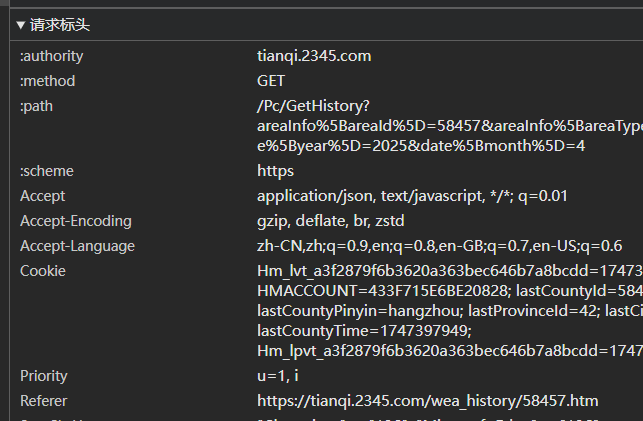
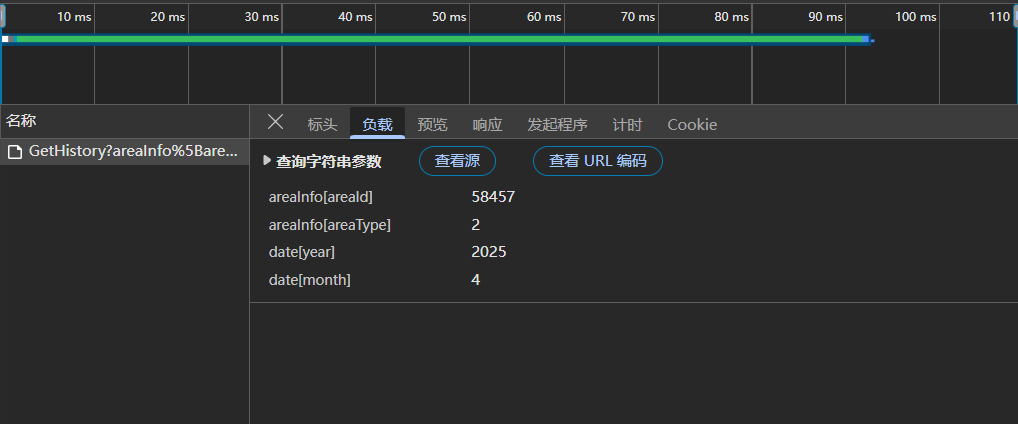
点击"负载",前两项是杭州地区有关的编码,都是不会变的,下面两项就是查询的year与month。复制里面的内容为请求的参数(设为字典类型)
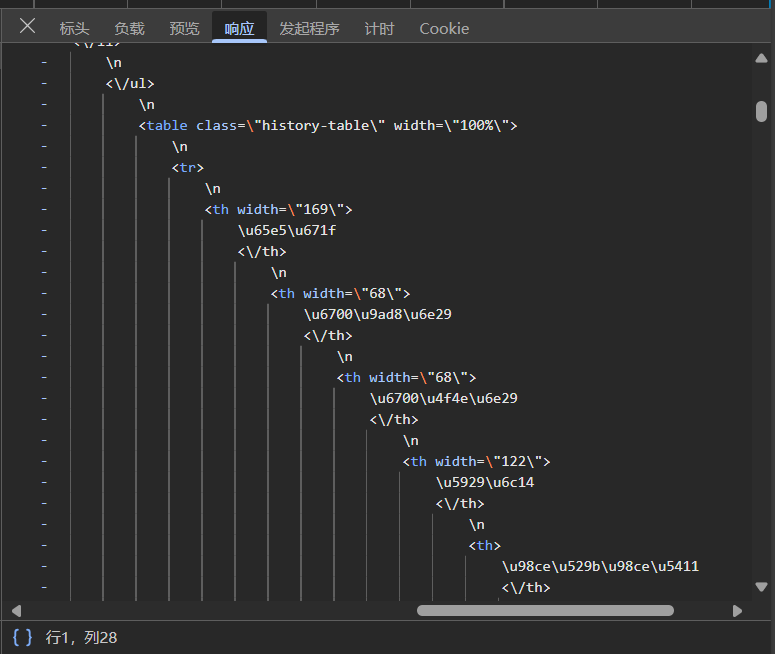
点击"响应",看一下返回的结果是怎样的
可以看到响应是json类型的数据( JSON (JavaScript Object Notation)数据由键值对组成,类似于字典,是一种轻量级的数据交换格式**)**
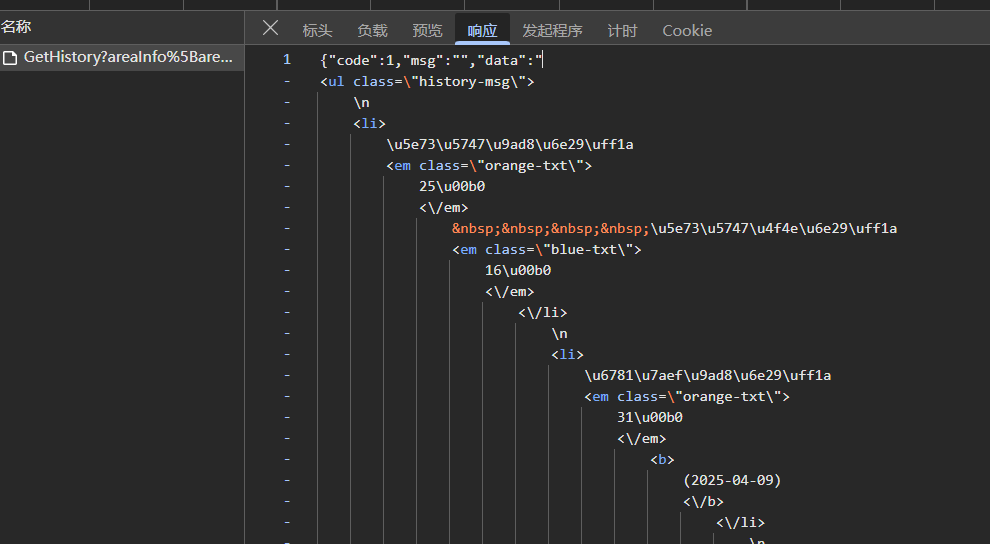
点击"预览",可以看到格式化的展示,将鼠标移到data的值可以看到html的数据(截图没法展示,自行看),可以发现里面有个<table>标签
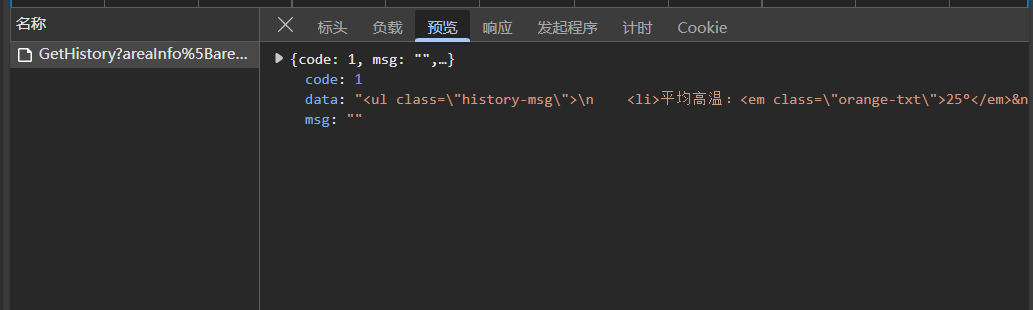
"响应"里也能看到,不过"预览"可视化更好
表格数据用pandas可以很容易地解析
python
import requests
import pandas as pd
from io import StringIO
url='https://tianqi.2345.com/Pc/GetHistory'
headers={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0','Referer':'https://tianqi.2345.com/wea_history/58457.htm'}
params={
"areaInfo[areaId]":58457,
"areaInfo[areaType]":2,
"date[year]":2025,
"date[month]":4
}
r=requests.get(url,headers=headers,params=params) #请求头和参数都为字典类型
if r.status_code!=200:
raise Exception('error')
data=r.json()["data"] #r.json()方法会将返回的JSON格式的响应解析为一个Python对象(一般为字典/列表),我们取出'data'键的值(是字符串)
data=StringIO(data) #使用StringIO对象来包装HTML字符串,可以将字符串视为文件来读取
df=pd.read_html(data)[0] #pd.read_html()方法可以解析一个网页中所有的表格,返回一个列表,里面的元素是DataFrame的数据结构
print(df)这样我们单个的网页就爬取成功了,输出如下

我们现在来爬取1-5月的数据,根据前面的分析,只需要将参数改一下就可以了
python
import requests
import pandas as pd
from io import StringIO
url='https://tianqi.2345.com/Pc/GetHistory'
headers={"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36 Edg/136.0.0.0','Referer':'https://tianqi.2345.com/wea_history/58457.htm'}
def craw_weather(month):
params={
"areaInfo[areaId]":58457,
"areaInfo[areaType]":2,
"date[year]":2025,
"date[month]":month
}
r=requests.get(url,headers=headers,params=params)
if r.status_code!=200:
raise Exception('error')
data=r.json()["data"]
data=StringIO(data)
df=pd.read_html(data)[0]
return df
lst=[] #里面是每个月的df数据
for n in range(1,6):
df=craw_weather(n)
lst.append(df)
datas=pd.concat(lst) #pd.concat()方法用于将多个Pandas对象(DataFrame或Series)沿着特定轴连接起来,非常灵活,可以用于行连接、列连接等多种操作
datas.to_excel('杭州1-5月天气数据.xlsx',index=False) #Pandas在将df保存为Excel时,会将df的索引作为单独的一列写入文件,设置index=False可以不包含索引列展示如下,昨天的数据都有了
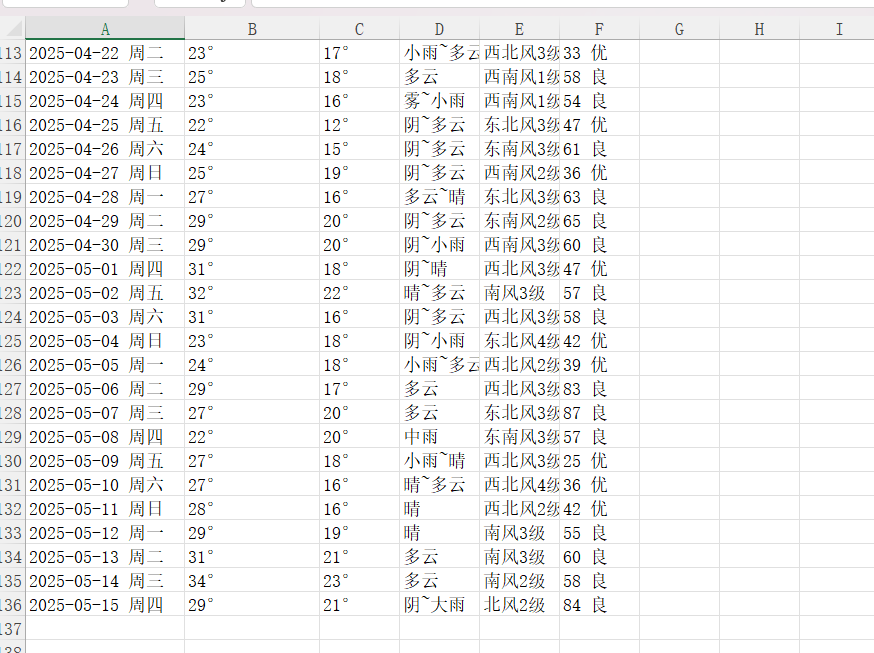
批量爬取正本小说
整本小说稍微有点多了,我们就拿番茄小说的top1为例吧,爬取前10章的内容,先批量爬取每一章的链接和章节名称,再根据链接爬取正文,最后将文章写到文件中去
网页地址为十日终焉完整版在线免费阅读_十日终焉小说_番茄小说官网
直接检索元素哈,可以发现所有章节都在特定的<div>标签下
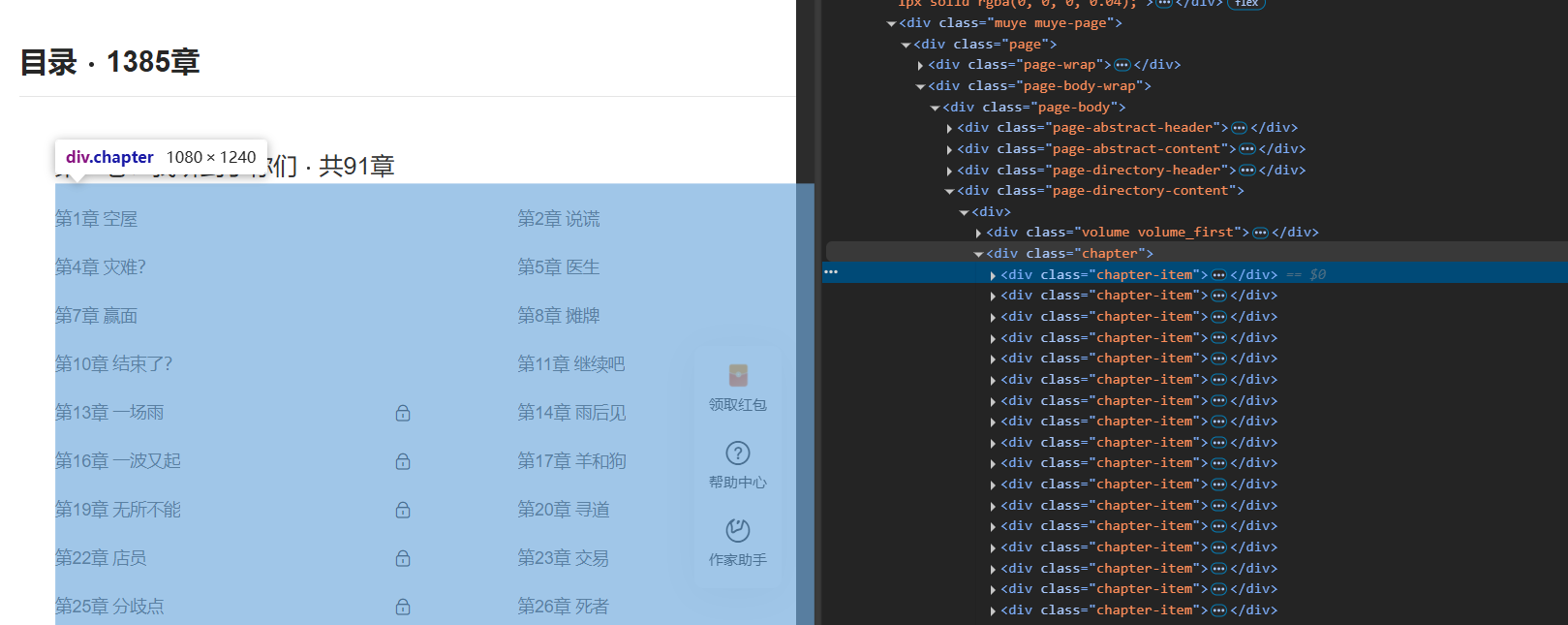
文章内容也在特定<div>标签下
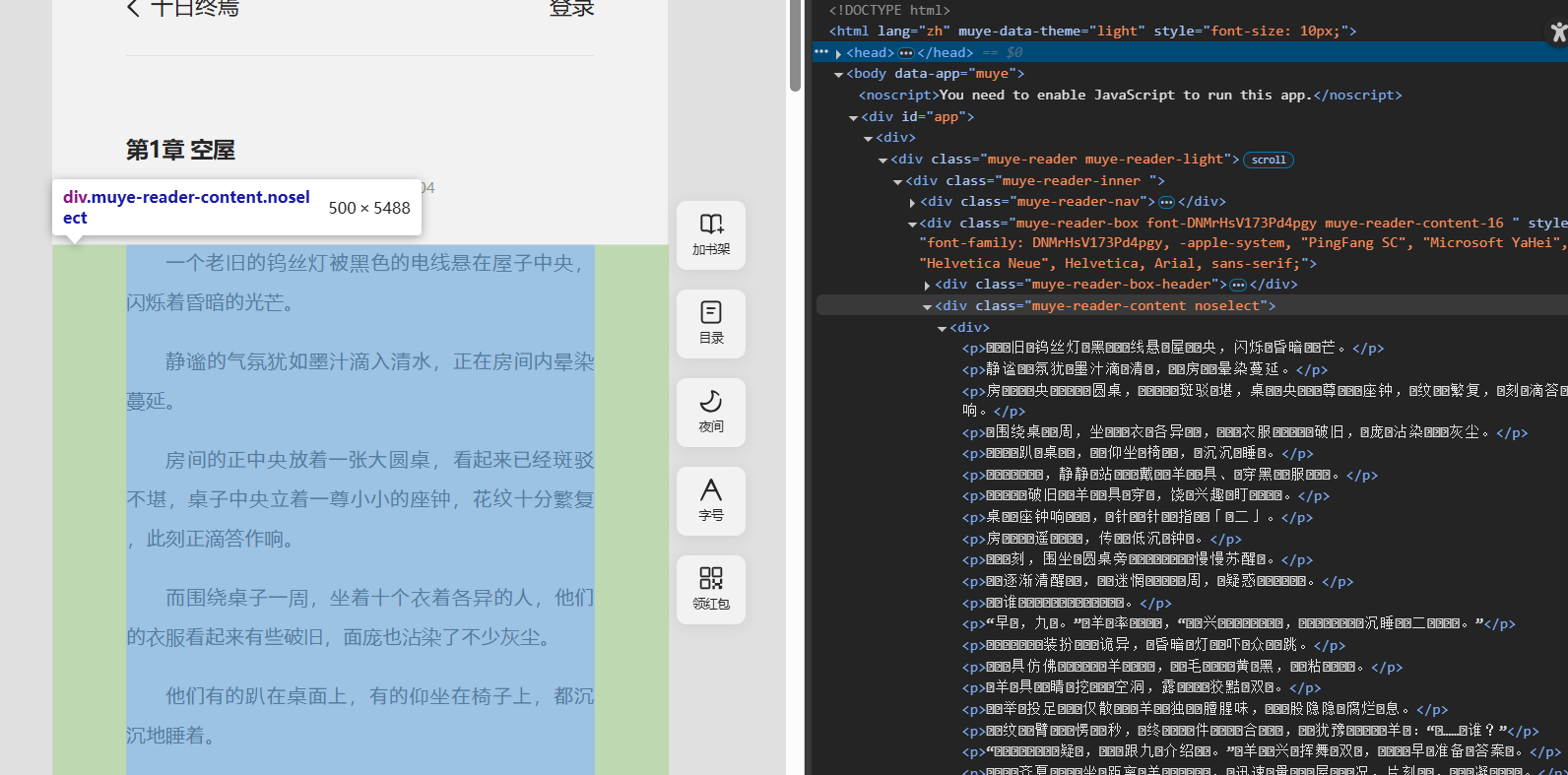 代码如下
代码如下
python
import requests
from bs4 import BeautifulSoup
def get_urls():
root_url='https://fanqienovel.com/page/7143038691944959011'
r=requests.get(root_url)
if r.status_code!=200:
raise Exception('error')
soup=BeautifulSoup(r.text,"html.parser")
datas=[]
n=0
for chapter in soup.find('div',class_='chapter').find_all('a'):
if n==10:
break
datas.append(['https://fanqienovel.com'+chapter['href'],chapter.get_text()])
n+=1
return datas
def get_chapter(url):
r=requests.get(url)
if r.status_code!=200:
raise Exception('error')
soup=BeautifulSoup(r.text,"html.parser")
content=soup.find('div',"muye-reader-content noselect").get_text()
return content
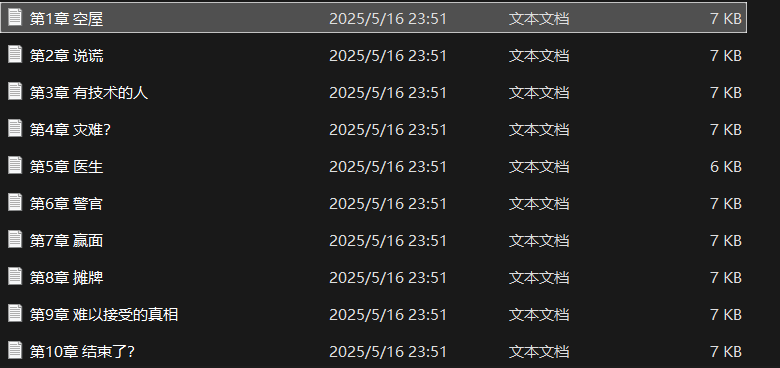
for urls in get_urls():
url,title=urls
with open(f'{title}.txt','w',encoding='utf-8') as ch: #写入文件
ch.write(get_chapter(url))展示如下

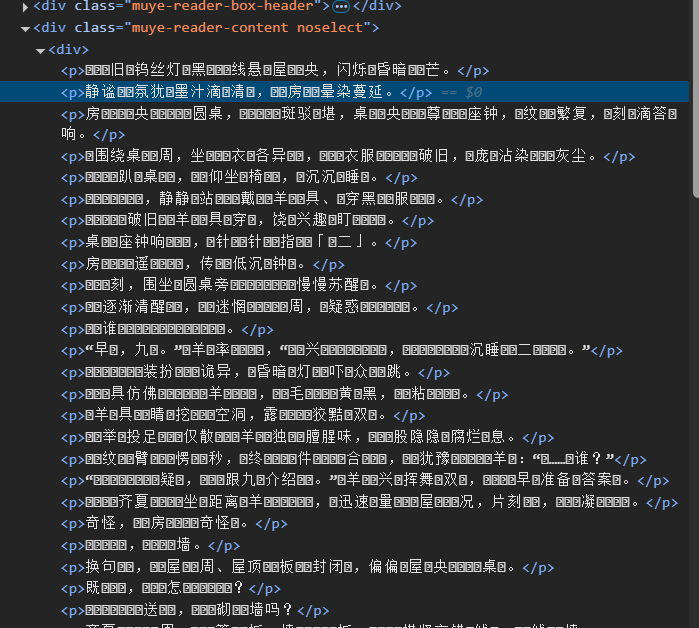
最后文章字符是乱码,因为网页源代码就是乱码的,查看<head>标签里的charset,编码就是'utf-8'每错,主包也尝试了几种方法还是不能正常显示,可能浏览器可能会对显示的内容进行一些渲染或转换 ,我们讲到后面再来尝试
 那爬这个有什么用呢? 有些盗版网站不是小广告很多嘛,那你就可以把文章爬下来看咯~
那爬这个有什么用呢? 有些盗版网站不是小广告很多嘛,那你就可以把文章爬下来看咯~