写在前面
GPT(Generative Pre-trained Transformer)是目前最广泛应用的大语言模型架构之一,其强大的自然语言理解与生成能力背后,是一个庞大而精细的训练流程。本文将从宏观到微观,系统讲解GPT的训练过程,包括数据收集、预处理、模型设计、训练策略、优化技巧以及后训练阶段(微调、对齐)等环节。
我们将先对 GPT 的训练方案进行一个简述,接着我们将借助 MiniMind 的项目,来完成我们自己的 GPT 的训练。
训练阶段概览
GPT 的训练过程大致分为以下几个阶段:
- 数据准备(Data Preparation)
- 预训练(Pretraining)
- 指令微调(Instruction Tuning)
- 对齐阶段(Alignment via RLHF 或 DPO)
- 推理部署(Inference & Serving)

准备数据
这里我们选择 MiniMind2:104M参数量的,0.1B。
使用数据集如下:
● pretrain_hq
● sft_512
● sft_2048
● dpo
我们对数据进行下载
shell
wget -c 'https://huggingface.co/datasets/jingyaogong/minimind_dataset/resolve/main/dpo.jsonl?download=true'
wget -c 'https://huggingface.co/datasets/jingyaogong/minimind_dataset/resolve/main/sft_2048.jsonl?download=true'
wget -c 'https://huggingface.co/datasets/jingyaogong/minimind_dataset/resolve/main/sft_512.jsonl?download=true'对应的内容如下:
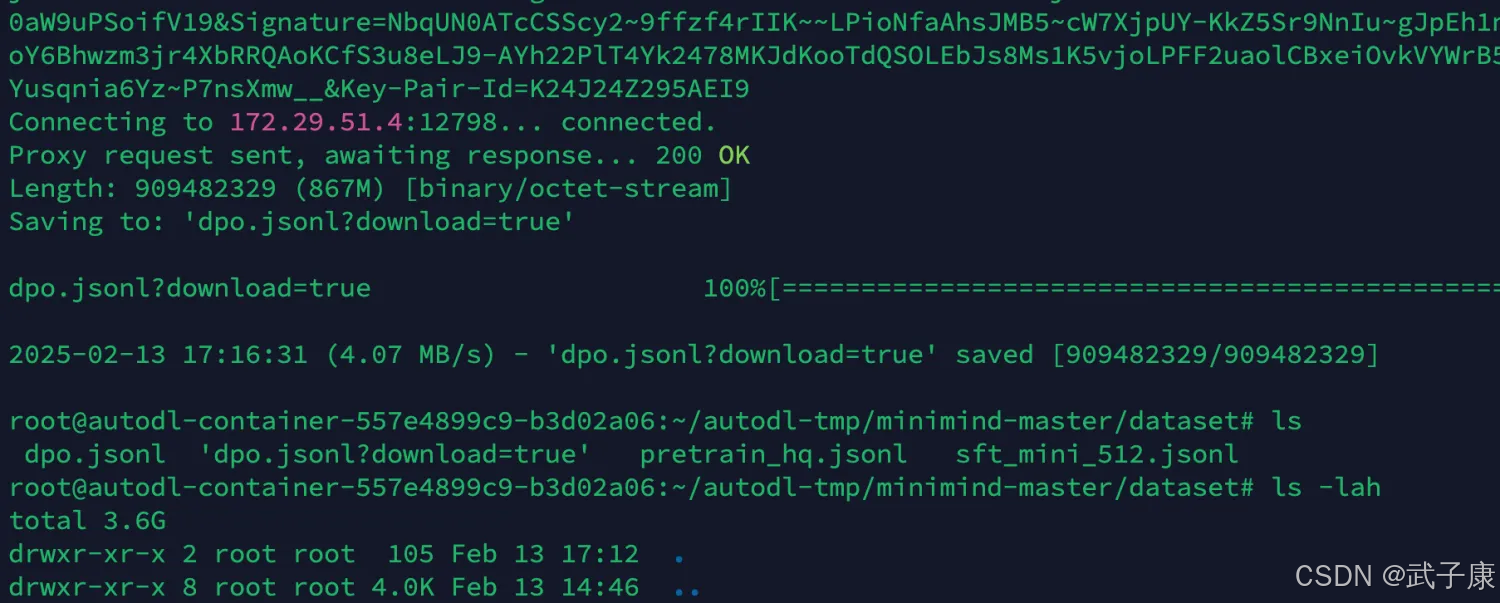
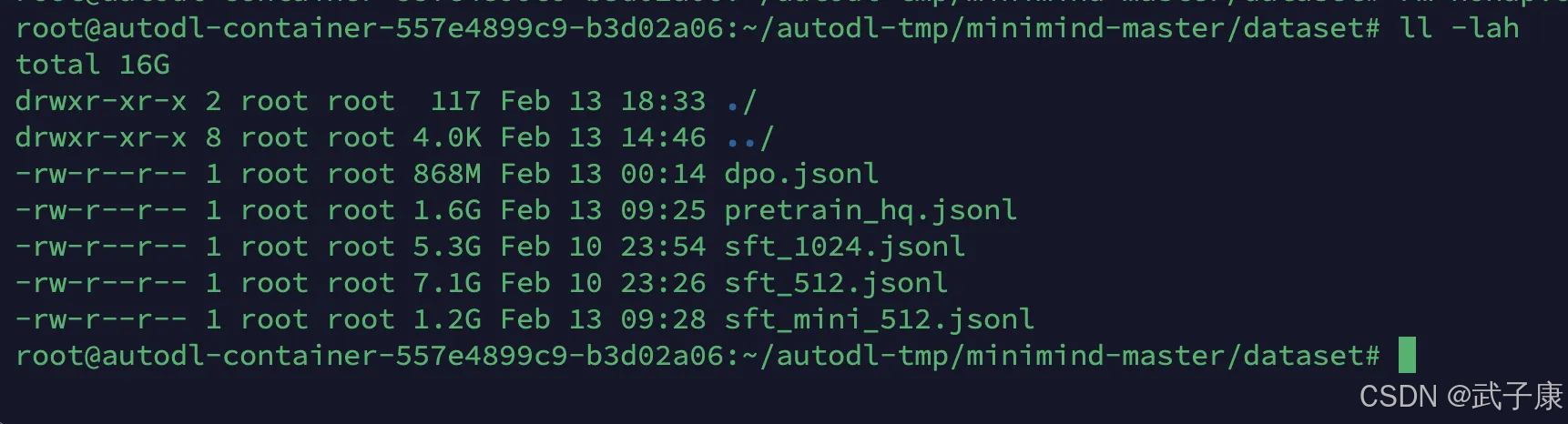
下载完毕后如下所示:
预训练
shell
torchrun --nproc_per_node 2 train_pretrain.py --n_layers 16 --dim 768 --use_wandb继续双卡训练:
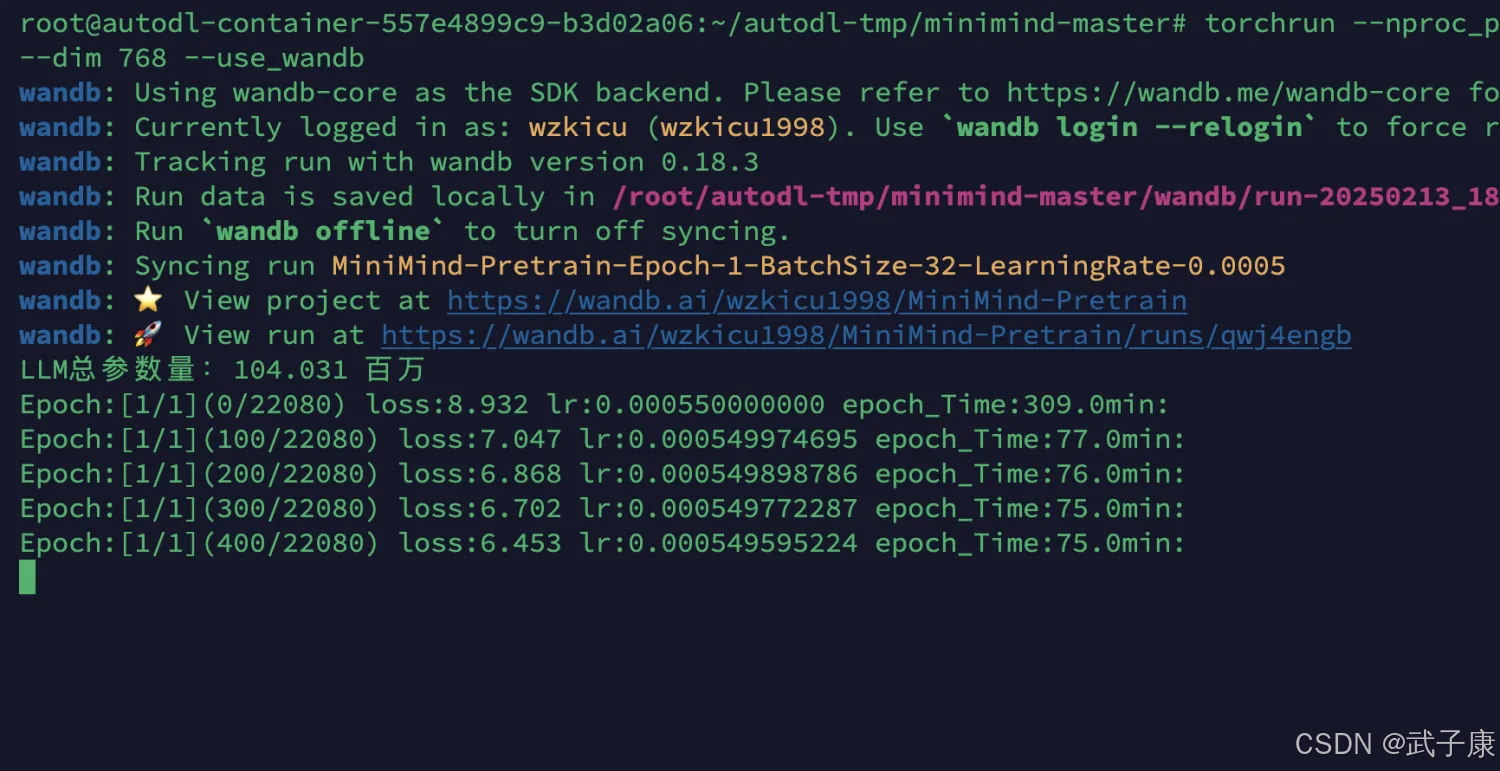
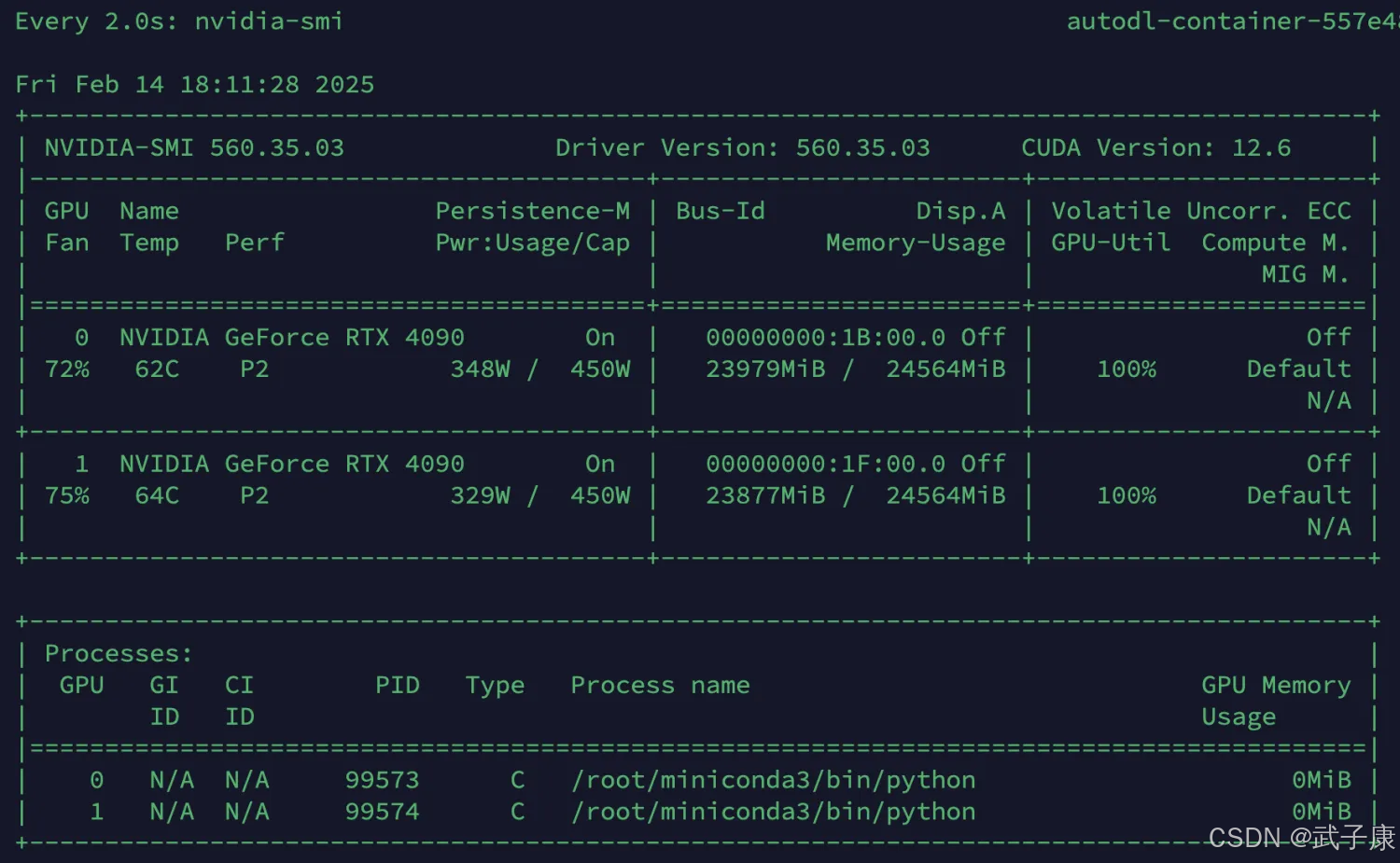
可以看到 LLM总参数量:104.031 百万,最终为 0.1B 模型。
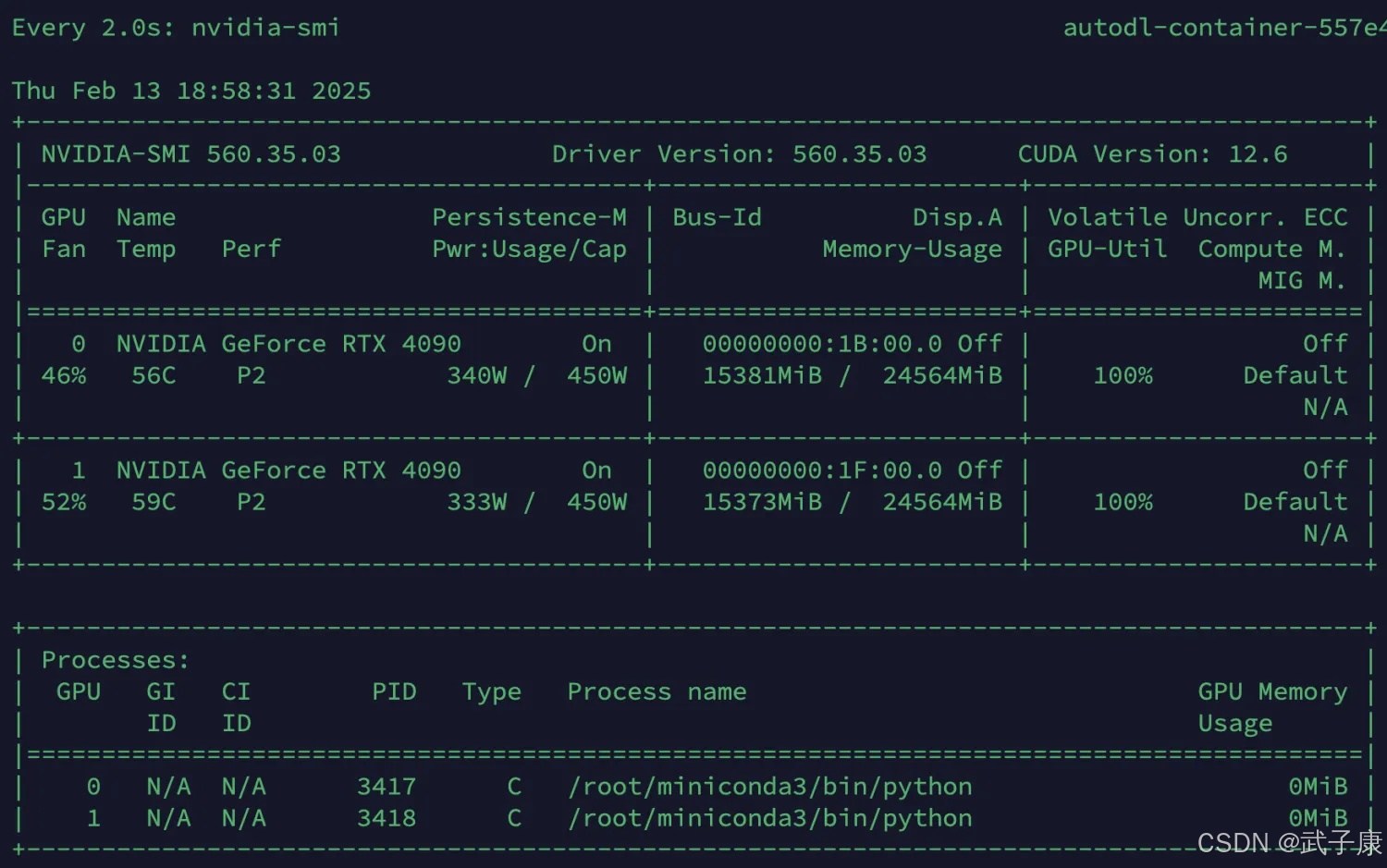
开始预训练,两张卡,各15GB显存。
sft_512
训练模型
shell
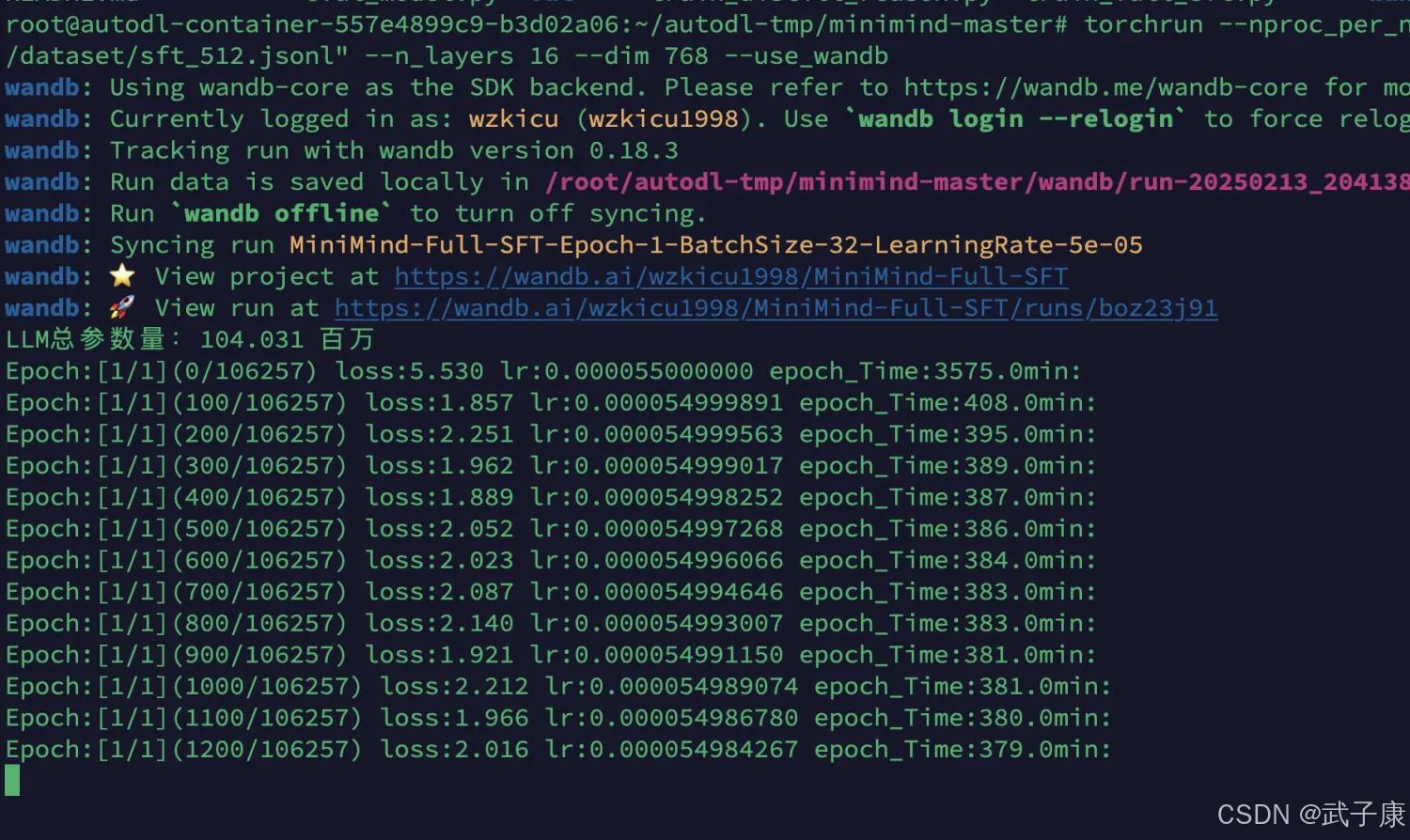
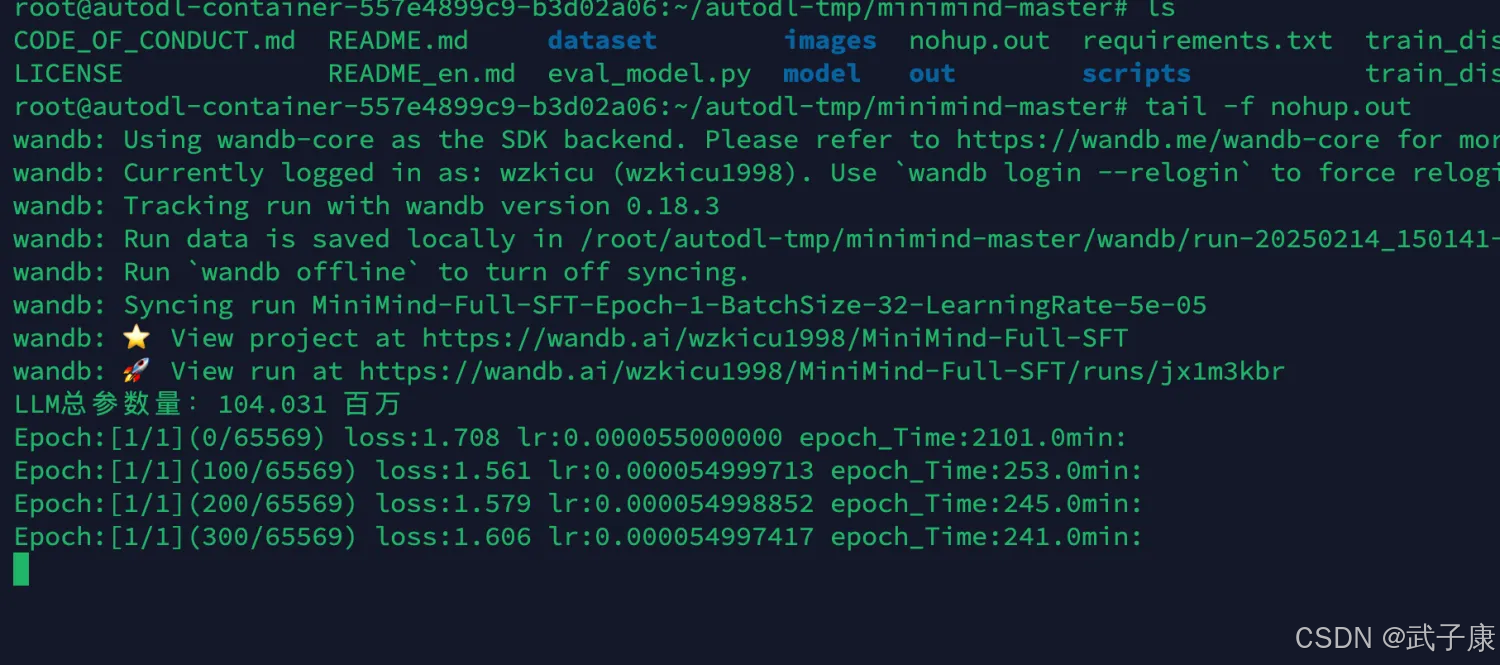
torchrun --nproc_per_node 2 train_full_sft.py --data_path "./dataset/sft_512.jsonl" --n_layers 16 --dim 768 --use_wandb开始训练:
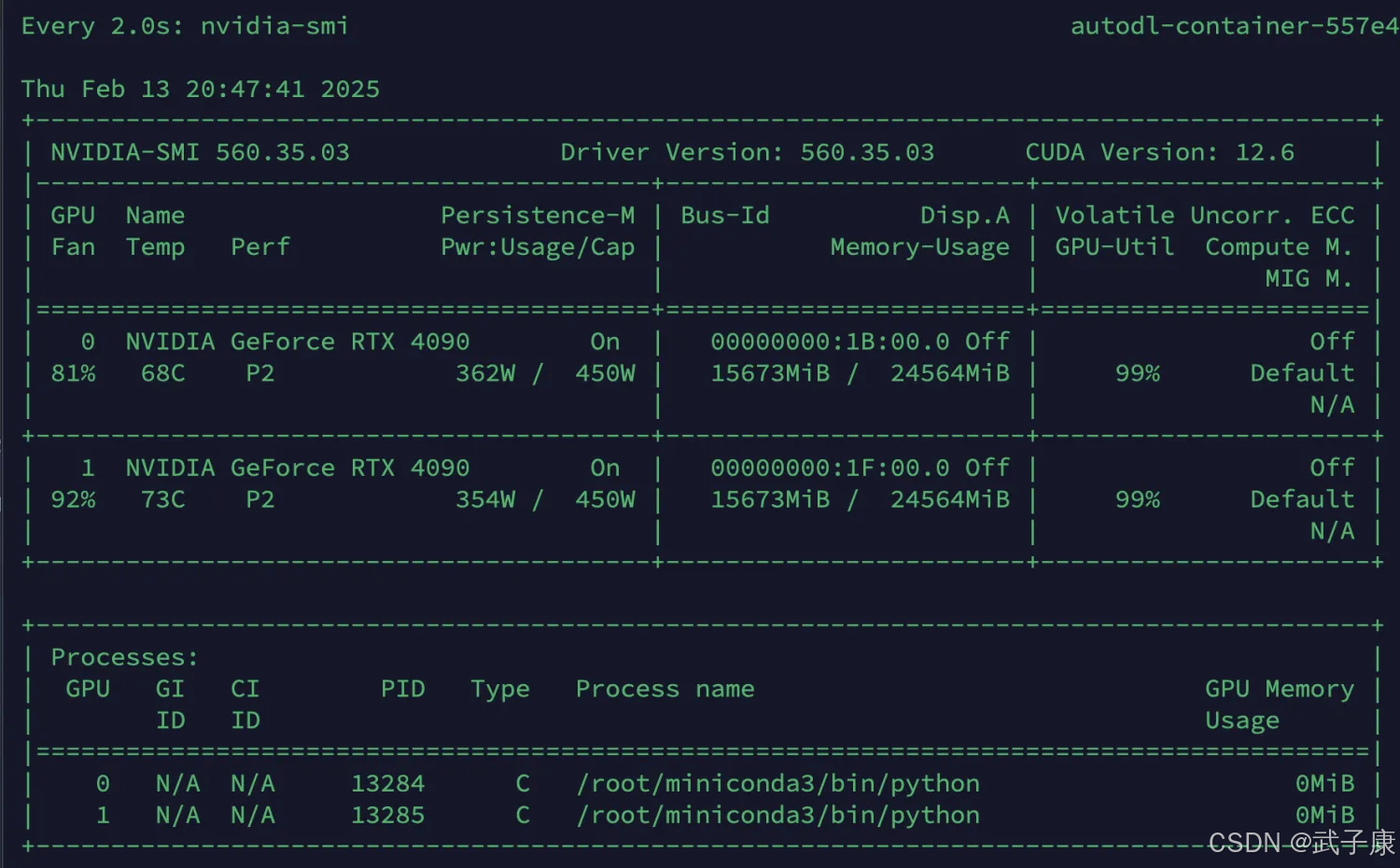
占用情况如下所示:
测试模型
shell
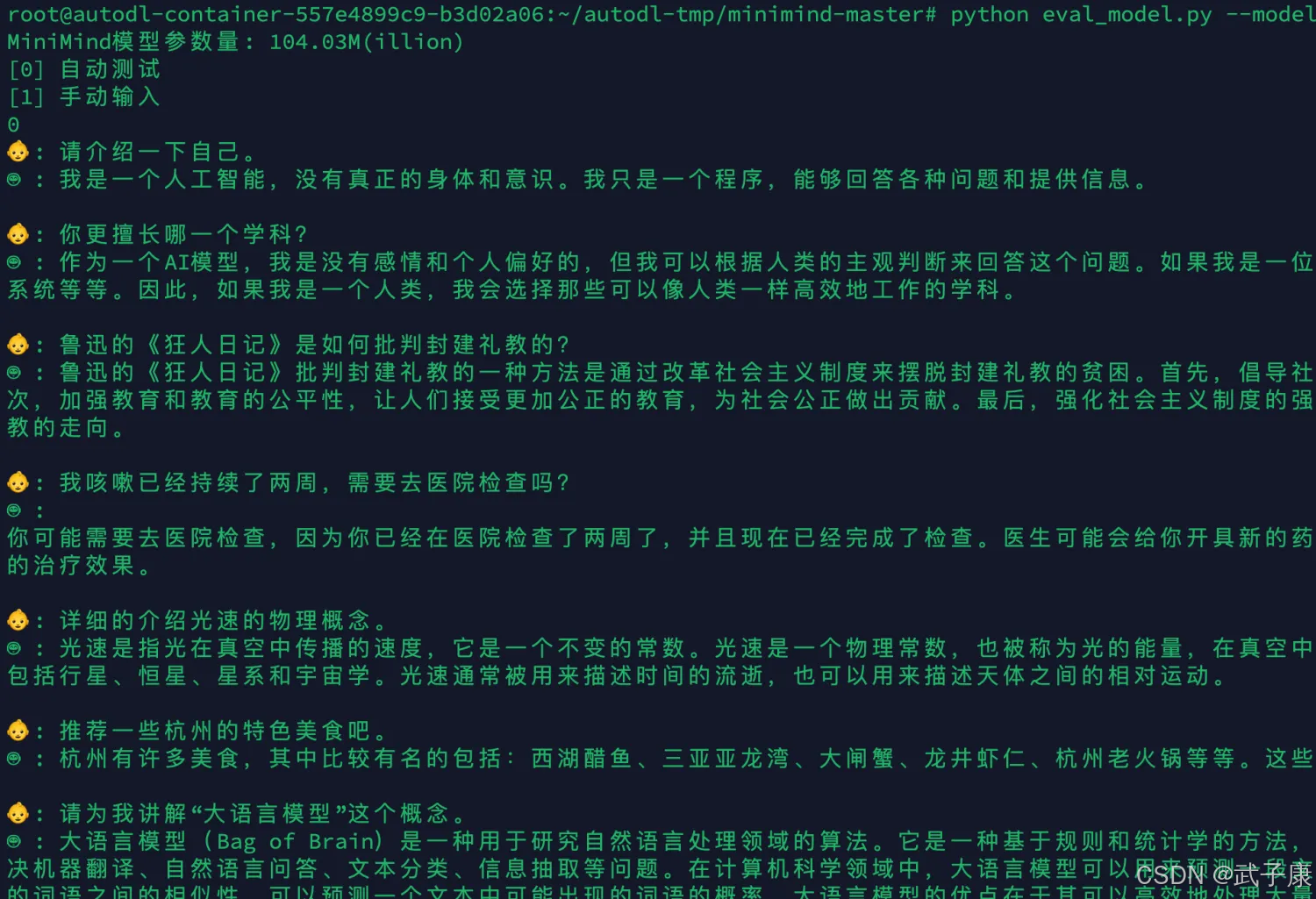
python eval_model.py --model_mode 1 --n_layers 16 --dim 768对应的内容如下所示:
sft_1024
训练模型
训练之前,我们需要将之前的 pretrained 模型备份一下(防止以后弄错了),然后把刚才训练好的模型修改为 pretrained 的名字。
简言之:在刚才sft_512上训练出来的模型上进行sft_1024的训练
shell
mv full_sft_768.pth pretrain_768.pth当前模型的列表如下所示:
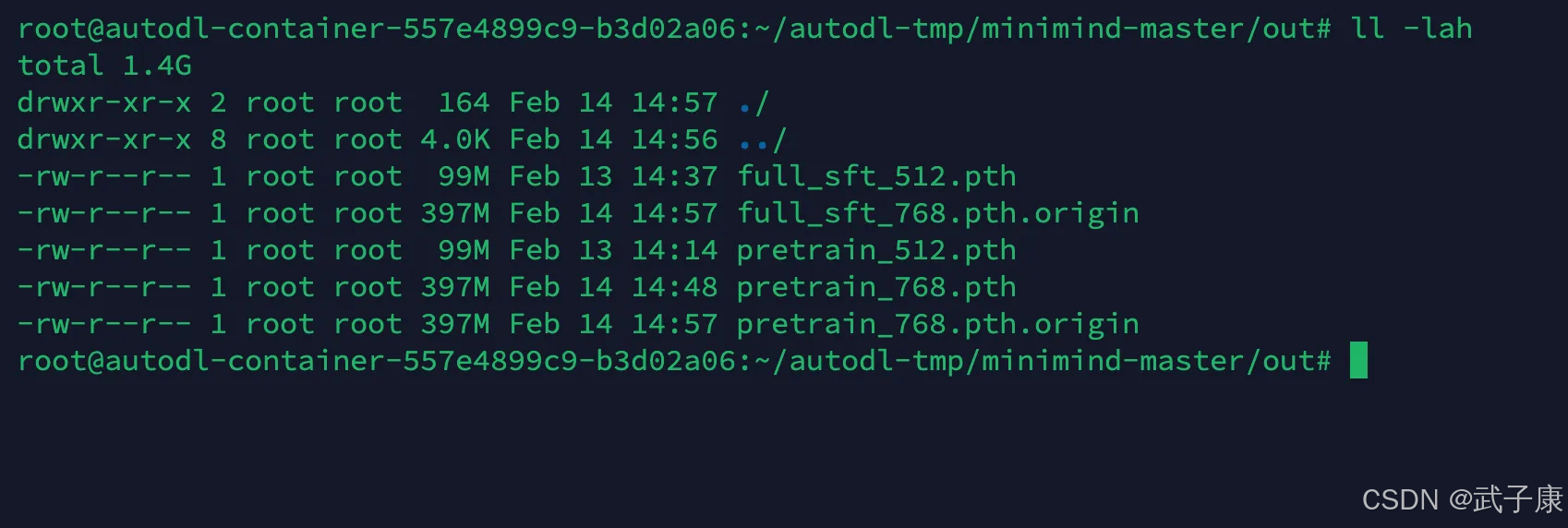
此时的 pretrain_768.pth 模型就是刚才在 sft_512 上训练出来的
shell
torchrun --nproc_per_node 2 train_full_sft.py --data_path="./dataset/sft_1024.jsonl" --n_layers 16 --dim 768 --use_wandb我们继续进行训练,这次任务估计要更久了,需要耐心的等待。
测试模型
shell
python eval_model.py --model_mode 1 --n_layers 16 --dim 768测试的执行结果如下所示:

dpo
在大模型训练中,"DPO" 通常指的是 Direct Preference Optimization(直接偏好优化),这是一种新兴的 对齐技术,用于更高效、直接地将大语言模型(LLM)对齐为更符合人类偏好的行为输出方式。它是近年来在 人类反馈强化学习(RLHF) 之后提出的一种新思路。
DPO 是不使用强化学习(如PPO)的方法,直接用"人类偏好对比数据"来优化语言模型的输出行为,使它更贴合用户期望。
大模型对齐,主要解决两个问题:
- 输出内容可控、有用、无害;
- 更符合人类用户的喜好或选择。
RLHF 是当前最流行的对齐技术,如 OpenAI 的 InstructGPT 和 ChatGPT 都用了这一方式。但 RLHF 存在如下问题:
- 实现复杂(需要 reward model、策略优化器等);
- 训练不稳定;
- PPO 的超参数难调;
- 训练代价大。
DPO 的目标:
- 用一种更简单的方式,实现类似甚至超过 RLHF 的对齐效果。
它解决了什么?
- 不用再引入复杂的 reward model + PPO;
- 直接在原始语言模型架构基础上,做最小改动即可实现。
为什么 DPO 有用?
- ✅ 不需要 reward model;
- ✅ 不使用强化学习;
- ✅ 易于实现、可以用常规优化器训练(如 Adam);
- ✅ 效果与 PPO 相当或更优;
- ✅ 可直接用于 decoder-only 架构(如 GPT);
训练模型
我们训练完了 sft_1024 的数据,接着进行下面的训练即可:
shell
torchrun --nproc_per_node 2 train_dpo.py --n_layers 16 --dim 768 ----batch_size 4 --use_wandb这里我们需要控制一下 batch_size 的大小,不然会OOM。
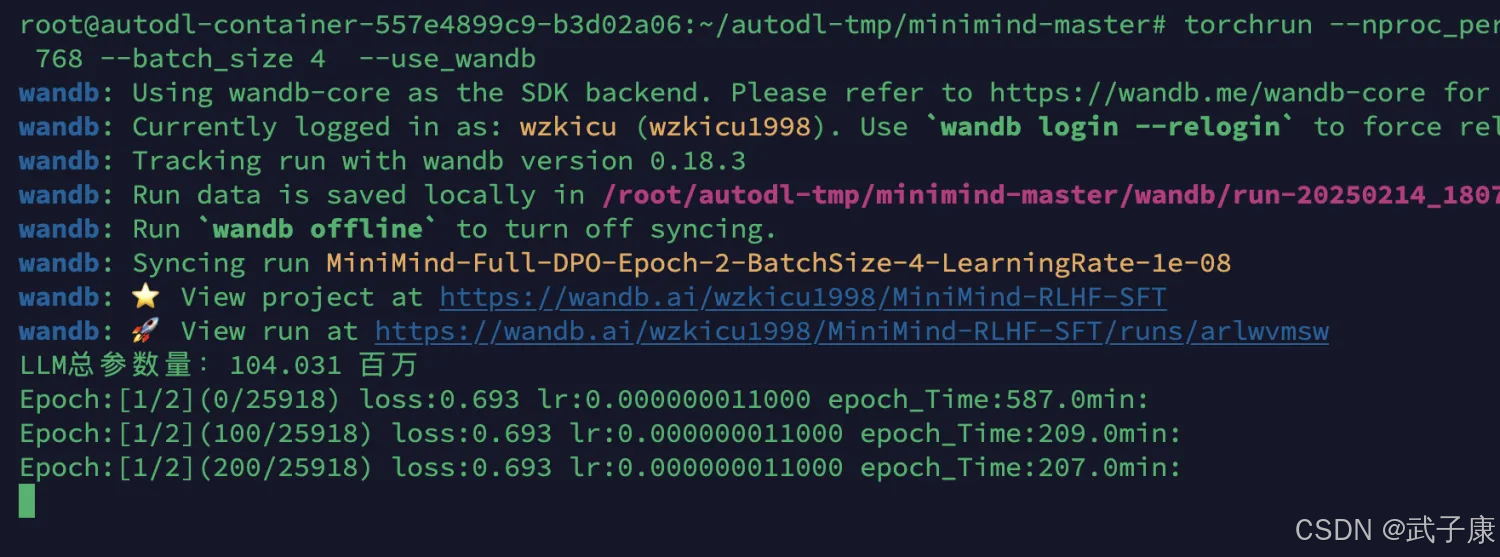
可以看到调整了 batch_size(代码里默认是8),此时调整为4,GPU也基本是要吃满的状态了: