Diversifying the High-level Features for better Adversarial Transferability
- 摘要-Abstract
- 引言-Introduction
- [相关工作-Related Work](#相关工作-Related Work)
- 方法-Methodology
- 实验-Experiments
- 结论-Conclusion

本文 "Diversifying the High-level Features for better Adversarial Transferability" 提出多样化高级特征(DHF)方法,利用 DNNs 参数冗余,在梯度计算时对高层特征随机变换并与良性样本特征混合,提升对抗样本迁移性。在 ImageNet 数据集实验表明,DHF 能有效提升基于动量攻击的迁移性,在基于输入变换的攻击中表现更优,攻击防御模型时也显著优于基线方法。
摘要-Abstract
Given the great threat of adversarial attacks against Deep Neural Networks (DNNs), numerous works have been proposed to boost transferability to attack real-world applications. However, existing attacks often utilize advanced gradient calculation or input transformation but ignore the white-box model. Inspired by the fact that DNNs are over-parameterized for superior performance, we propose diversifying the high-level features (DHF) for more transferable adversarial examples. In particular, DHF perturbs the high-level features by randomly transforming the high-level features and mixing them with the feature of benign samples when calculating the gradient at each iteration. Due to the redundancy of parameters, such transformation does not affect the classification performance but helps identify the invariant features across different models, leading to much better transferability. Empirical evaluations on ImageNet dataset show that DHF could effectively improve the transferability of existing momentumbased attacks. Incorporated into the input transformation-based attacks, DHF generates more transferable adversarial examples and outperforms the baselines with a clear margin when attacking several defense models, showing its generalization to various attacks and high effectiveness for boosting transferability.
鉴于深度神经网络(DNN)面临对抗攻击的巨大威胁,人们提出了许多方法来提高攻击在现实世界应用中的迁移性。然而,现有的攻击方法通常采用先进的梯度计算或输入变换,但忽略了白盒模型。受 DNN 为实现卓越性能而过度参数化这一事实的启发,我们提出多样化高级特征(DHF)的方法,以生成更具迁移性的对抗样本。具体来说,DHF 在每次迭代计算梯度时,通过对高层特征进行随机变换,并将其与良性样本的特征混合,来扰动高级特征。由于参数的冗余性,这种变换不会影响分类性能,但有助于识别不同模型间的不变特征,从而显著提高迁移性。在 ImageNet 数据集上的实证评估表明,DHF 能够有效提高现有的基于动量攻击的迁移性。将 DHF 融入基于输入变换的攻击中,它能生成更具迁移性的对抗样本,并且在攻击多个防御模型时,明显优于基线方法,这表明 DHF 对各种攻击具有通用性,并且在提高迁移性方面非常有效。
引言-Introduction
这部分主要阐述研究背景与动机,指出深度神经网络(DNNs)易受对抗样本攻击,现有攻击方法在跨模型时迁移性差,引出通过利用 DNN 参数冗余提升对抗样本迁移性的研究思路,具体内容如下:
- 研究背景:DNNs 在诸多领域广泛应用,但易受对抗样本攻击,这种攻击对物理世界中部署的DNN安全构成重大威胁。现有对抗攻击在攻击者获取目标模型全部知识时攻击性能良好,但跨模型迁移性差,在现实世界中效率低下。
- 现有改进方法及不足:为提升对抗样本迁移性,已提出输入变换、集成模型攻击和模型特定方法等。其中模型特定方法通过修改或利用 DNN 内部结构提升迁移性,效果较好且能与其他方法兼容,但现有这类方法对模型结构和图像特征的利用仍不充分,存在改进空间。
- 研究动机与创新点:许多研究表明 DNNs 存在过参数化现象,深层网络参数冗余明显。受此启发,文章聚焦于扰动高层特征,提出统一的扰动操作,建立了过参数化与对抗迁移性之间的关系,旨在利用高层特征的过参数化提升对抗样本迁移性。
- 研究贡献:首次建立过参数化与对抗迁移性的联系;提出多样化高层特征(DHF)方法,通过线性变换高层特征并与良性样本特征混合,有助于识别不同模型间的不变特征;大量实验表明 DHF 在对抗迁移性上优于现有方法,且对其他攻击具有通用性。
相关工作-Related Work
该部分主要介绍了与本文研究相关的工作,涵盖对抗攻击、对抗防御和 DNNs 过参数化三个方面,具体内容如下:
- 对抗攻击:自从 Szegedy 等人发现 DNNs 易受对抗样本攻击后,多种对抗攻击方法被提出。基于梯度、迁移、分数、决策、生成的攻击是主要的攻击类型。其中,迁移攻击因无需访问目标模型,在现实场景攻击深度模型中较受欢迎。为提升对抗迁移性,研究人员提出动量攻击和输入变换方法。但现有工作较少关注白盒模型本身,本文旨在通过多样化高层特征生成更具迁移性的对抗样本,且该方法适用于任何 DNN。
- 对抗防御:为减轻对抗攻击威胁,出现多种防御方法。包括对抗训练、输入预处理、特征去噪、认证防御等。如 JPEG 通过压缩输入图像消除对抗扰动,HGD 基于 U-Net 训练去噪自动编码器净化图像,R&P 通过随机调整图像大小和填充减轻对抗效果,Bit-Red 减少像素位数挤压扰动,FD 采用基于 JPEG 的压缩框架防御,Cohen 等人采用随机平滑训练鲁棒的 ImageNet 分类器,NRP 采用自监督对抗训练机制有效消除扰动。
- DNNs 的过参数化:自 Krizhevsky 等人使用卷积神经网络在 ImageNet 上取得优异成绩后,DNNs 变得更深更宽,参数众多。过参数化能显著提升模型性能,而模型量化技术用低精度权重替代浮点权重,减少过参数化模型的内存需求,这表明 DNNs 包含冗余信息。本文旨在利用这种冗余生成更具迁移性的对抗样本。
方法-Methodology
该部分详细阐述了多样化高层特征(DHF)方法的动机、具体操作、高层特征优于低层特征的原因以及与 Ghost 方法的差异,具体内容如下:
- 动机 :Lin 等人将对抗样本生成类比于模型训练过程,输入变换方法类似于数据增强,能提升对抗迁移性,Li 等人提出的 Ghost 网络通过对模型应用随机失活和缩放操作使内部特征多样化来提升迁移性。受此启发,作者研究如何通过特征多样化提升迁移性。由于 DNNs 参数冗余,对高层特征进行小扰动对模型性能影响小,且不同模型在特征上有相似性,因此可以通过扰动高层特征找到不变特征,进而提升对抗样本的迁移性。
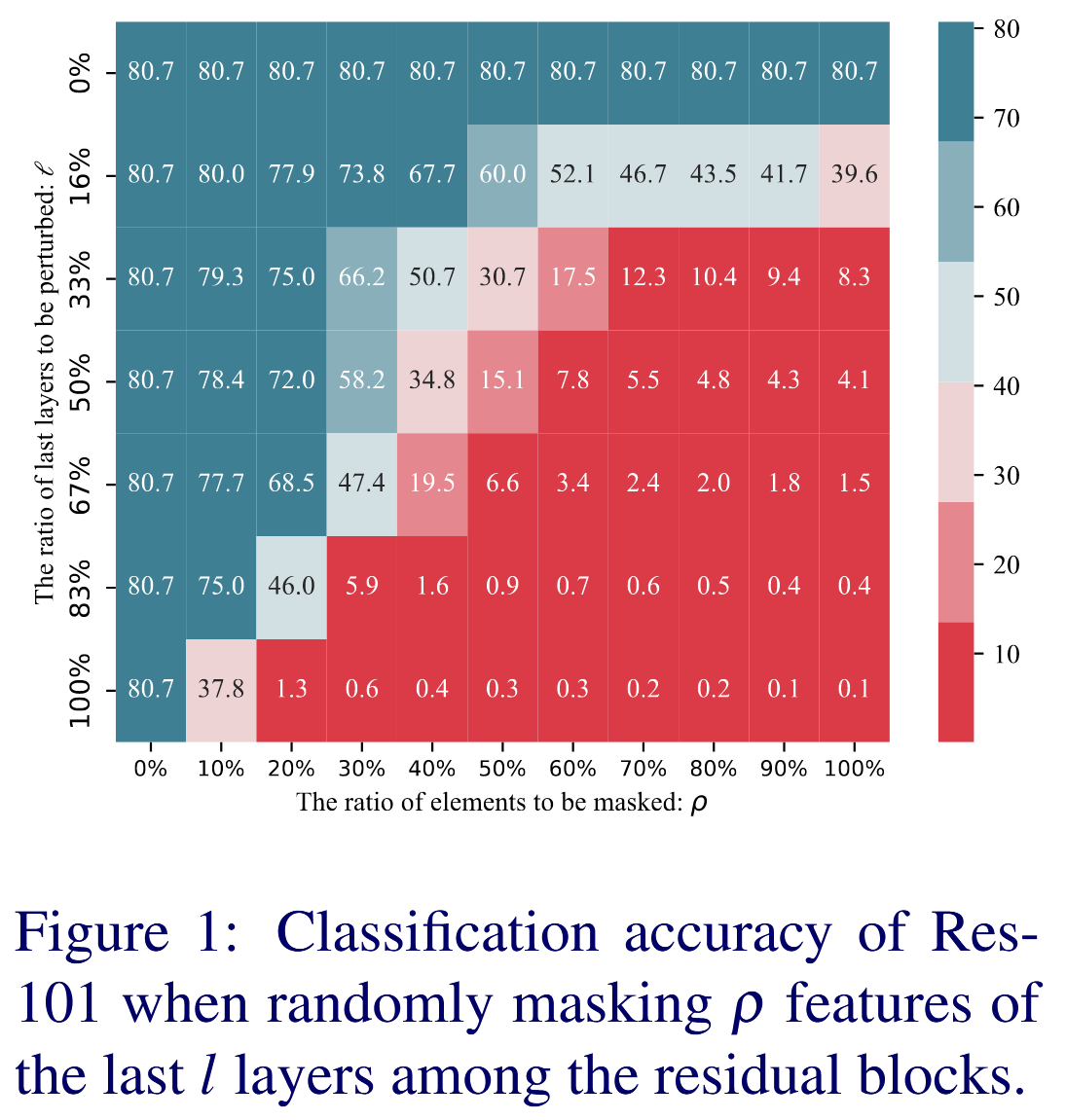
图1:在残差块中随机掩蔽最后 l l l 层的 ρ ρ ρ 个特征时,Res101 的分类准确率。

图2:良性图像及其由 DHF 生成的相应对抗样本的可视化结果。 - 多样化高层特征操作 :
- 混合特征 :为在不改变识别性能的情况下使对抗样本特征多样化,将当前样本特征 y l a d v y_{l}^{a d v} yladv 与良性样本特征 y l y_{l} yl 按公式 y l ∗ = ( 1 − η ) ⋅ y l a d v + η ⋅ y l y_{l}^{*}=(1-\eta) \cdot y_{l}^{a d v}+\eta \cdot y_{l} yl∗=(1−η)⋅yladv+η⋅yl 混合, η \eta η 服从 ( 0 , η m a x ) (0, \eta_{max }) (0,ηmax) 的均匀分布。与 Admix 不同,DHF 仅与良性样本特征混合,使中间层特征多样化的同时不影响识别结果,稳定前向和反向传播,使梯度更可靠。
- 随机调整特征 :随机用特征均值替换 ρ \rho ρ 比例的特征元素,由于 DNNs 参数冗余,这样做能稳定传播并提升迁移性,且该操作可微,能得到更精确的梯度。与调整参数影响整个特征图不同,这种局部特征替换只改变特定元素。
- 特征分析:采用平均 Hessian 迹衡量网络层敏感性,随着网络层增加,平均 Hessian 迹下降,模型对高层特征的敏感性降低。在过参数化网络中,适当改变高层特征不会改变模型输出,因此在增强特征多样性时,选择敏感性低的高层特征进行扰动,既可以获得多样特征,又不会改变模型预测,更适合用于生成更具迁移性的对抗样本。
- 与 Ghost 对比 :
- 动机:DHF 基于参数冗余使特征多样化以获取不变特征,Ghost 旨在降低集成模型攻击的训练成本。
- 策略:DHF 扰动高层特征,因为低层参数冗余较少;Ghost 认为对后层的扰动无法提供迁移性,所以密集扰动各层特征。
- 变换:DHF 混合当前样本和良性样本特征,并随机用均值替换特征;Ghost 在卷积层密集采用随机失活层或对残差连接进行随机缩放。
- 泛化性:实验表明 DHF 能持续提升各种攻击的迁移性,而 Ghost 有时会降低性能。
实验-Experiments
这部分通过多种实验评估了 DHF 的有效性,涵盖实验设置、数值结果分析以及参数研究,具体内容如下:
- 实验设置 :
- 数据集:从 ILSVRC 2012 验证集中随机选取 1000 个类别中的 1000 张图像,所选模型均能正确分类这些图像。
- 模型:评估涉及 9 种模型,包含卷积神经网络(如ResNet - 18、ResNet - 50等)和Transformer(如Vision Transformer、Swin)架构。同时考虑了多种具有防御机制的模型,像 NIPS 2017 防御竞赛中的前3名提交模型,以及输入预处理、认证防御和对抗扰动去噪相关的模型。
- 评估设置 :选择基于动量的攻击方法 MI-FGSM 和 NI-FGSM,以及基于输入变换的攻击方法 DIM 和 TIM。设置 DHF 扰动最后 5 6 S \frac{5}{6}S 65S 层,混合权重上界 η m a x = 0.2 \eta_{max}=0.2 ηmax=0.2,扰动元素比例 ρ = 10 % \rho = 10\% ρ=10%,扰动预算 ε = 16 \varepsilon = 16 ε=16,迭代次数 T = 10 T = 10 T=10,步长 α = 1.6 \alpha = 1.6 α=1.6,衰减因子 μ = 1.0 \mu = 1.0 μ=1.0。
- 数值结果 :
- 基于动量攻击评估 :对比 MI-FGSM 和 NI-FGSM 攻击,所有方法都比原始模型生成的对抗样本迁移性更好,DHF 在 CNNs 和 Transformer 模型上攻击成功率最高,比表现最佳的基线方法 Ghost 平均分别高出 3.4% 和 4.1%.
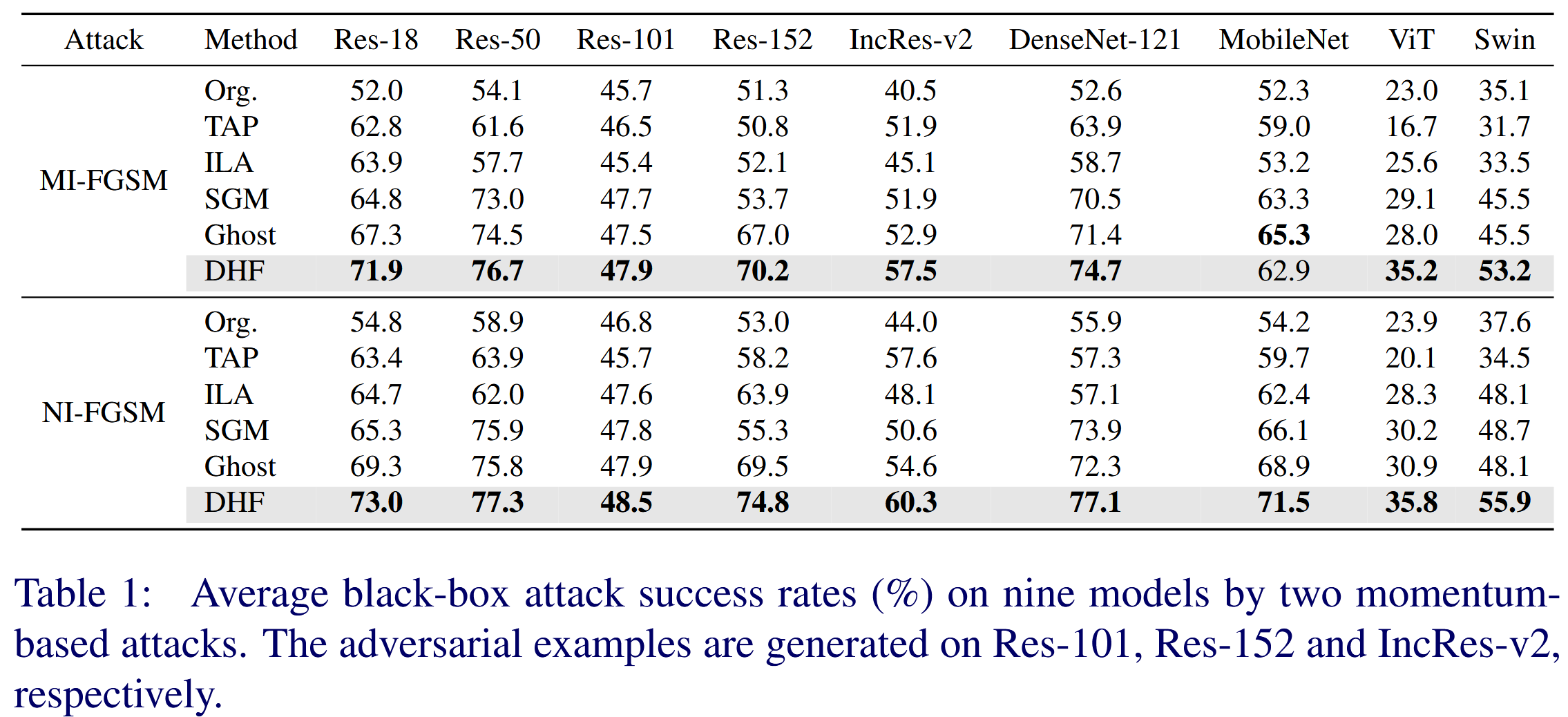
表1:两种基于动量的攻击方法在九个模型上的平均黑盒攻击成功率(%)。对抗样本分别在 Res-101、Res-152 和 Inception-ResNet v2 上生成。 - 基于输入变换攻击评估 :将 DIM 和 TIM 集成到 MI-FGSM 中,结果显示 DHF 在对抗迁移性上表现最优,比 Ghost 分别高出 4.0% 和 5.4%,验证了利用参数冗余扰动高层特征可显著提升迁移性的假设。
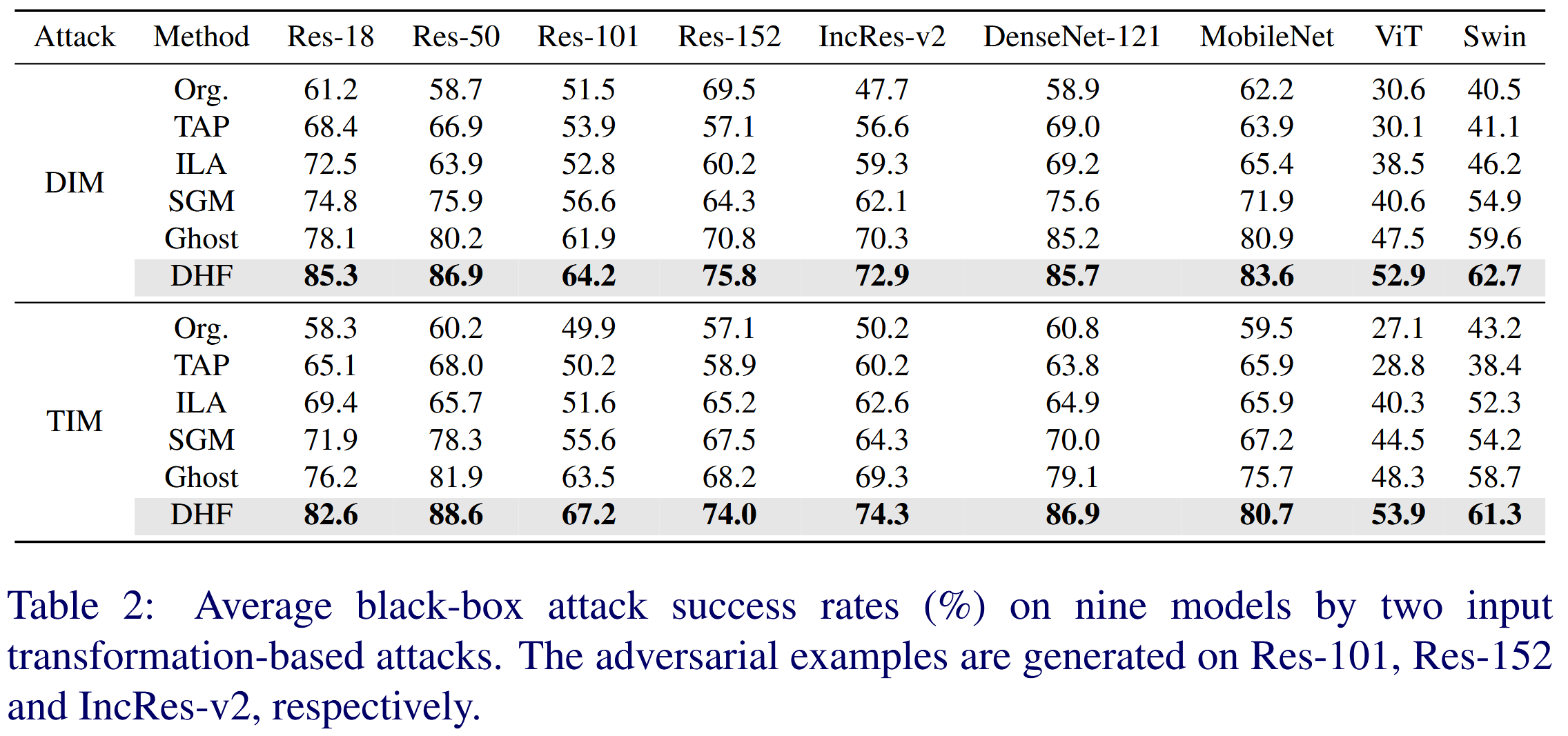
表2:两种基于输入变换的攻击方法在九个模型上的平均黑盒攻击成功率(%)。对抗样本分别在 Res-101、Res-152 和 Inception-ResNet v2 上生成。 - 防御模型评估 :针对多种防御模型,用 DIM 在不同模型上生成对抗样本进行测试。DHF 攻击成功率平均为56.2%,比基线方法 SGM 平均高出5.3% ,而 Ghost 表现最差,表明 DHF 在攻击不同防御机制的黑盒模型时有效性和通用性高。
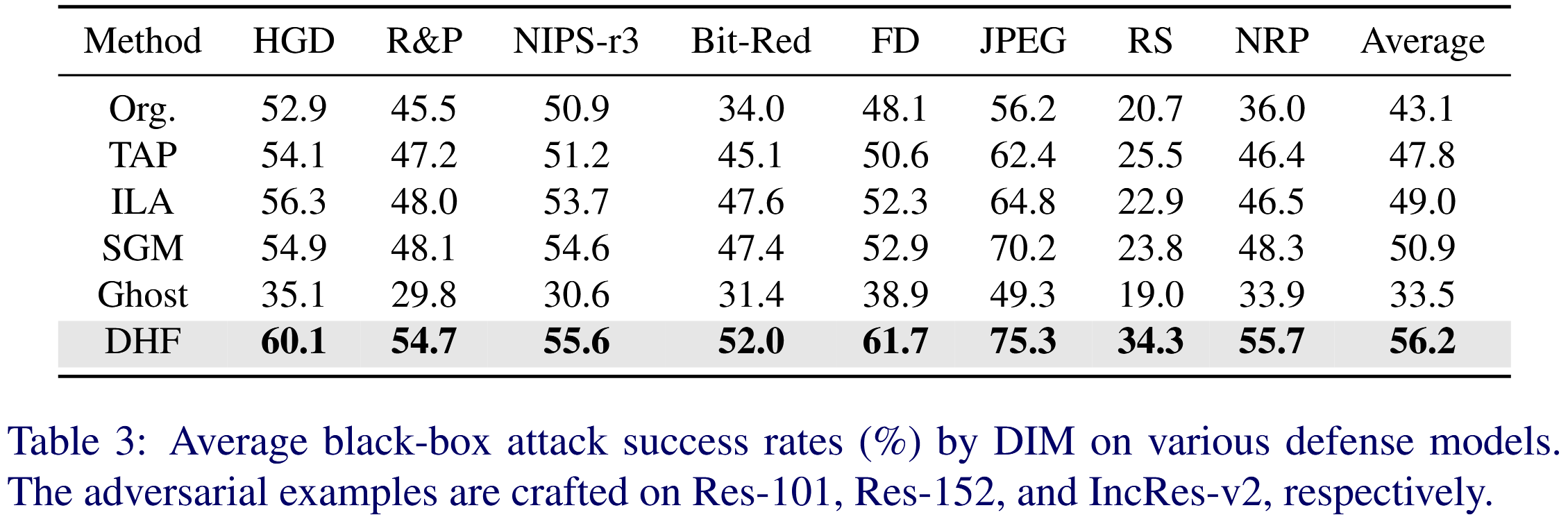
表3:通过 DIM 方法在各种防御模型上的平均黑盒攻击成功率(%)。对抗样本分别在 Res-101、Res-152 和 Inception-ResNet v2 模型上生成。
- 基于动量攻击评估 :对比 MI-FGSM 和 NI-FGSM 攻击,所有方法都比原始模型生成的对抗样本迁移性更好,DHF 在 CNNs 和 Transformer 模型上攻击成功率最高,比表现最佳的基线方法 Ghost 平均分别高出 3.4% 和 4.1%.
- 参数研究 :
- 混合权重上界 η m a x \eta_{max} ηmax : η m a x \eta_{max} ηmax 平衡干净样本和对抗样本特征。实验发现, η m a x = 0 \eta_{max}=0 ηmax=0 时混合操作无效,迁移性低;在 η m a x = 0.2 \eta_{max}=0.2 ηmax=0.2 左右攻击性能达到峰值;继续增大 η m a x \eta_{max} ηmax,干净特征占比过大,难以计算准确梯度,攻击性能下降,因此实验采用 η m a x = 0.2 \eta_{max}=0.2 ηmax=0.2。
- 调整元素比例 ρ \rho ρ : ρ \rho ρ 用于减少特征方差以识别不变特征。实验显示, ρ \rho ρ 在不超过0.1时,整体性能略有提升并在 ρ = 0.1 \rho = 0.1 ρ=0.1 时达到峰值;更大的 ρ \rho ρ 会因过多用特征均值替换元素而降低分类精度,导致梯度不准确,攻击性能显著下降,所以实验采用 ρ = 0.1 \rho = 0.1 ρ=0.1。
- 调整层数比例 r r r : 实验发现不扰动特征( r = 0 % r = 0\% r=0%)时 DHF 无效,迁移性最低;扰动特征可显著提升迁移性,在扰动最后 5 6 \frac{5}{6} 65 层( r = 83 % r = 83\% r=83%)时达到峰值;扰动所有层性能反而不如扰动最后 5 6 \frac{5}{6} 65 层,因此实验选择扰动最后 5 6 \frac{5}{6} 65 层以获得更好性能。
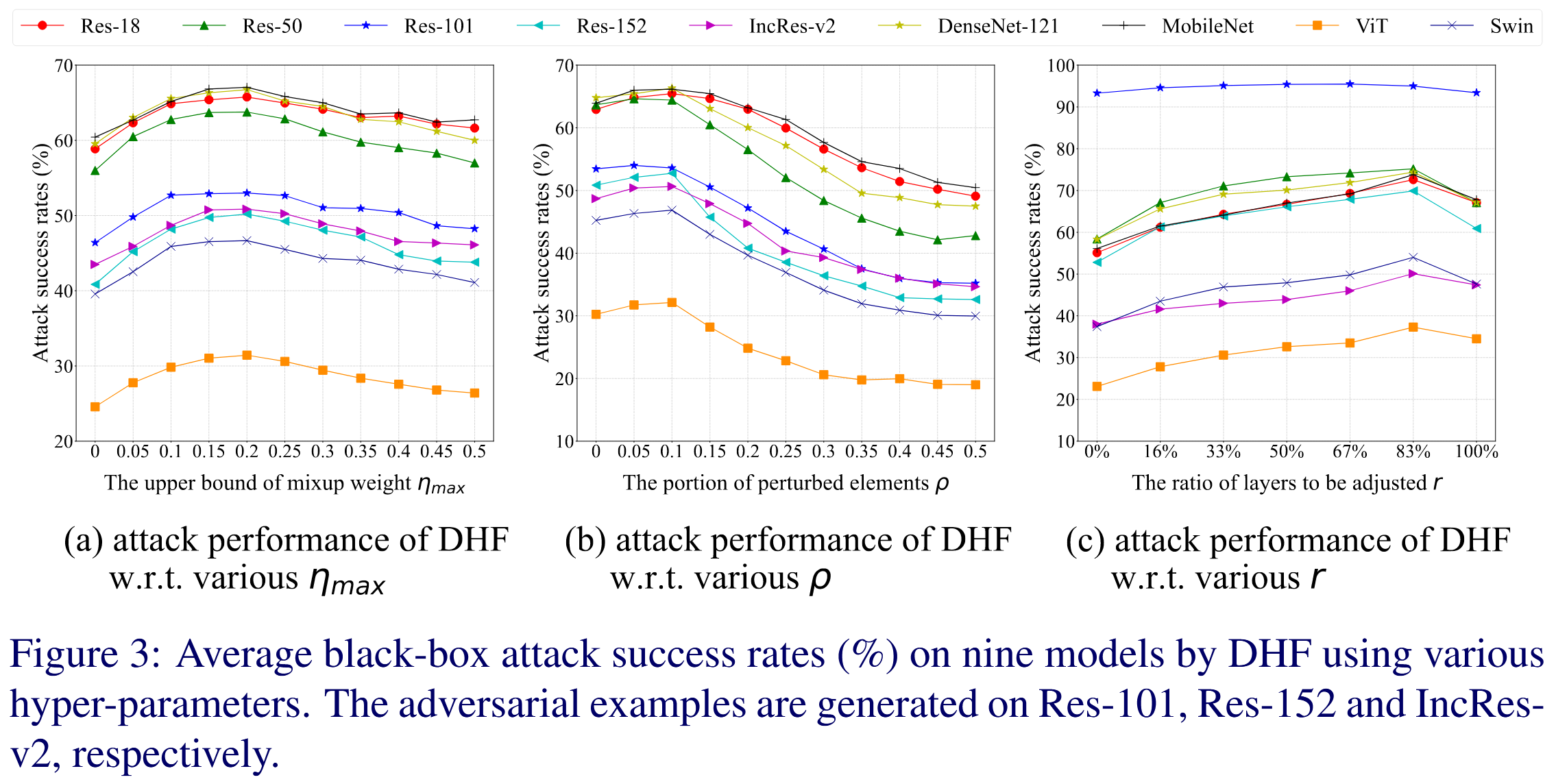
图3:使用不同超参数的 DHF 对九个模型的平均黑盒攻击成功率(%)。对抗样本分别在 Res-101、Res-152 和 IncRes-v2 上生成。
结论-Conclusion
该部分指出深度神经网络(DNNs)常因追求良好的泛化性而过度参数化。文章利用这一特性,提出多样化高层特征(DHF)的方法来增强对抗样本的迁移性。
- 方法核心:发现对 DNNs 的高层特征进行小的扰动,对模型整体性能的影响微乎其微。基于此,DHF 在梯度计算过程中,对高层特征进行随机变换,并将其与良性样本的特征相混合。
- 理论分析:文中还从理论层面分析了在进行特征多样化时,高层特征相较于低层特征更具优势的原因。
- 实验验证:大量的评估实验表明,与现有的最先进攻击方法相比,DHF 方法在对抗样本迁移性上有显著提升。这充分证明了 DHF 方法的有效性,为对抗攻击领域提供了新的思路和方法。