在计算机视觉领域,目标检测一直是一个重要且热门的研究方向,广泛应用于安防监控、自动驾驶、机器人视觉等诸多场景。YOLO(You Only Look Once)系列算法凭借其出色的实时性和较高的检测精度,在目标检测领域占据着重要地位。本文将深入探讨 YOLOV3 算法,带你全面了解这一目标检测的高效利器。
一、YOLOV3 核心改进
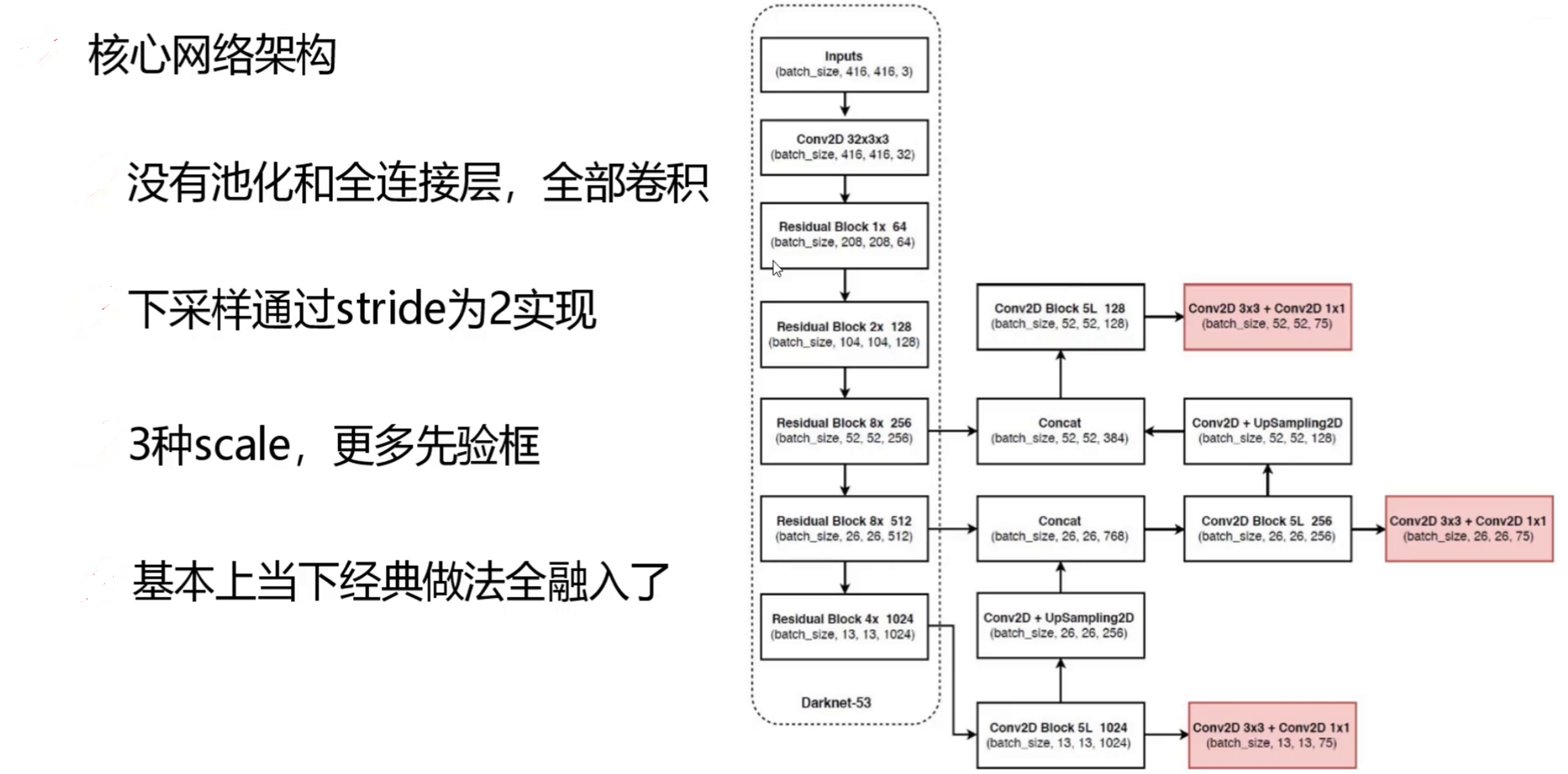
yolo v3的最大改进是网络架构,采用Darknet-53网络结构代替原来的Darknet-19,使其更适合小目标检测
特征做的更细致,融入多持续特征图信息来预测不同规格物体
先验框更丰富,3种scale,每种3个规格,一共9种
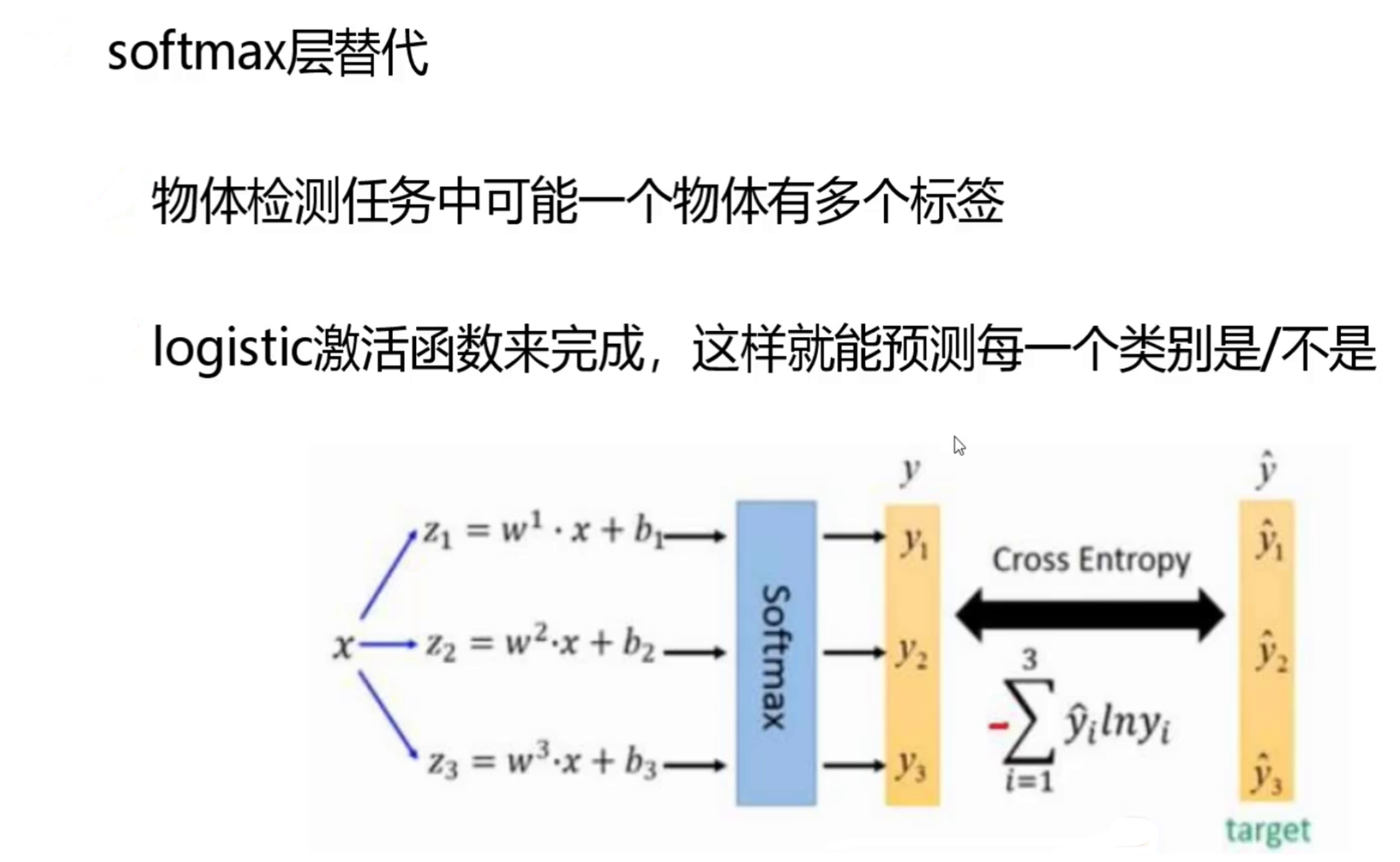
softmax改进,采用独立的逻辑回归分类器代替 softmax,预测多标签任务
二、网络架构升级
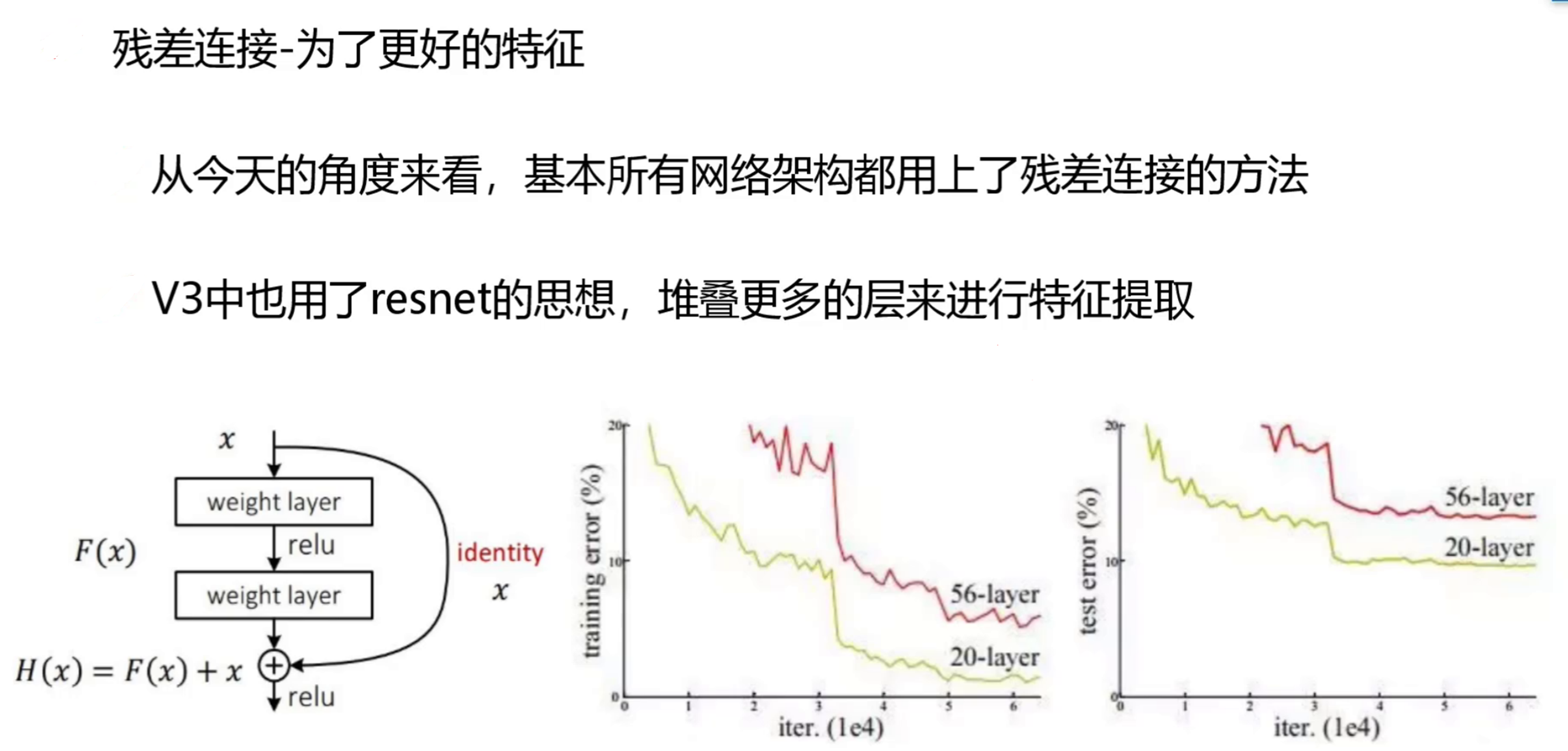
YOLOv3 最大的改进之一体现在网络架构上,采用 Darknet-53 代替了 YOLOv2 中的 Darknet-19。Darknet-53 由 53 个卷积层组成,其主要由 1×1 和 3×3 卷积层交替堆叠,并且大量运用残差连接。残差连接的引入,有效解决了深度神经网络中梯度消失的问题,使得网络能够不断加深层数。相比 Darknet-19,Darknet-53 能够提取到更丰富、更细致的图像特征,尤其是对小目标的特征捕捉能力显著增强。
残差链接:可以搭建更大、更深层次的网络。缓解梯度消失问题,加快网络收敛速度,加强特征表达能力,降低网络学习难度
三、多尺度特征融合及先验框优化
YOLOv3 融入多尺度特征图信息来预测不同规格物体,这是其另一个关键优化。算法在 3 个不同尺度的特征图(13×13、26×26 和 52×52)上进行预测。小尺寸特征图感受野大,适合检测大目标;大尺寸特征图感受野小,对小目标检测更具优势。通过这种多尺度预测机制,YOLOv3 实现了对不同大小目标的全面覆盖。
在融合多尺度特征时,YOLOv3 先对骨干网络输出的特征图进行下采样得到小尺寸特征图,再通过上采样与中间层、浅层特征图进行融合。这种方式使得网络既能获取高层语义信息用于目标分类,又能保留底层细节信息用于目标定位。以自然场景图像为例,在检测其中的鸟类、昆虫等小目标,以及树木、建筑等大目标时,多尺度特征融合让 YOLOv3 能够同时精准检测出各类目标,显著提升检测的完整性和准确性。
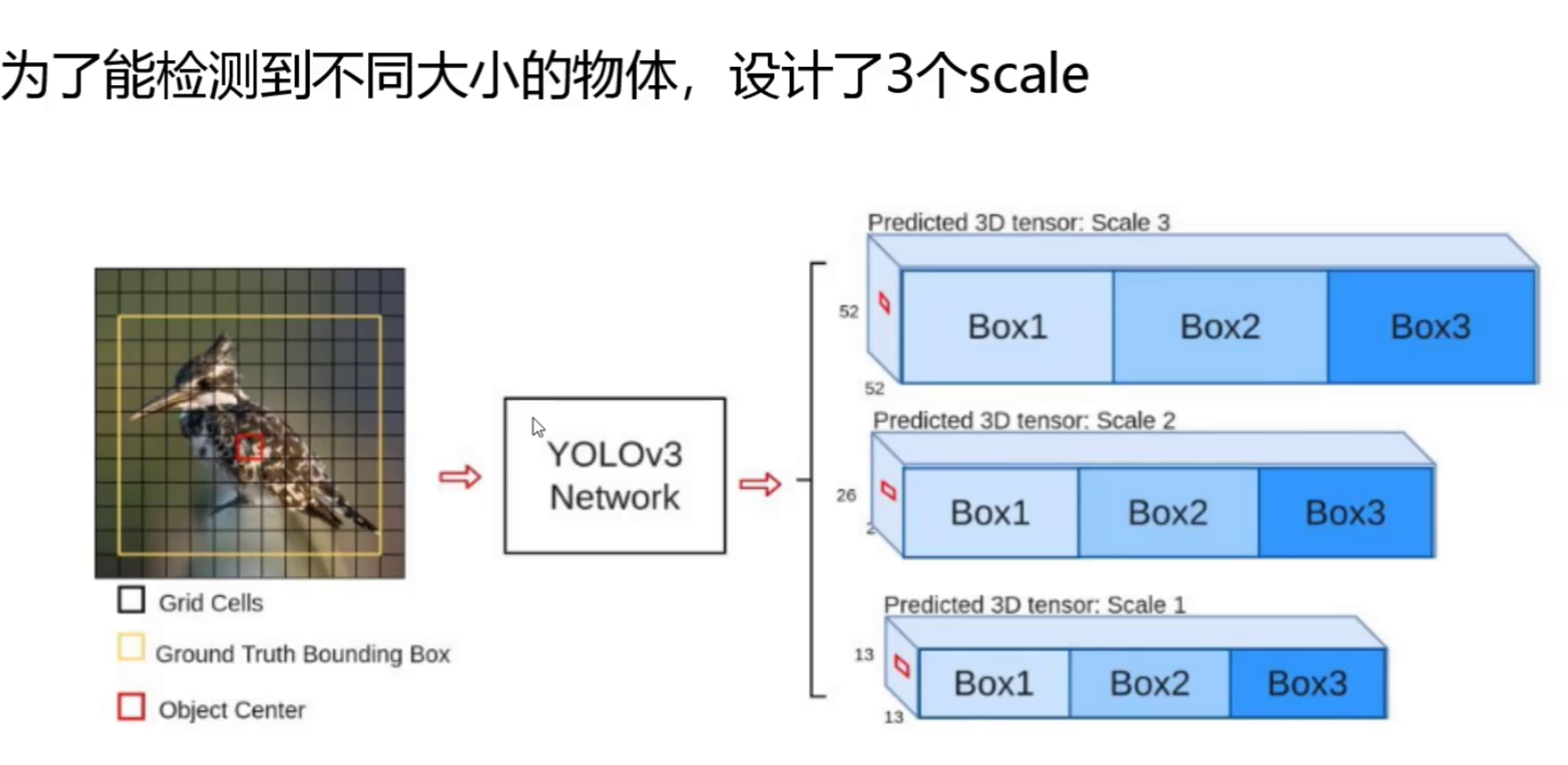
采用 3 种 scale,每种 scale 包含 3 个规格,共计 9 种先验框。这些不同大小和宽高比的先验框,能够更好地匹配数据集中各种形状和尺度的目标。在训练过程中,模型依据真实边界框与先验框的匹配情况,学习如何调整先验框,使其更贴合目标实际形状和位置。
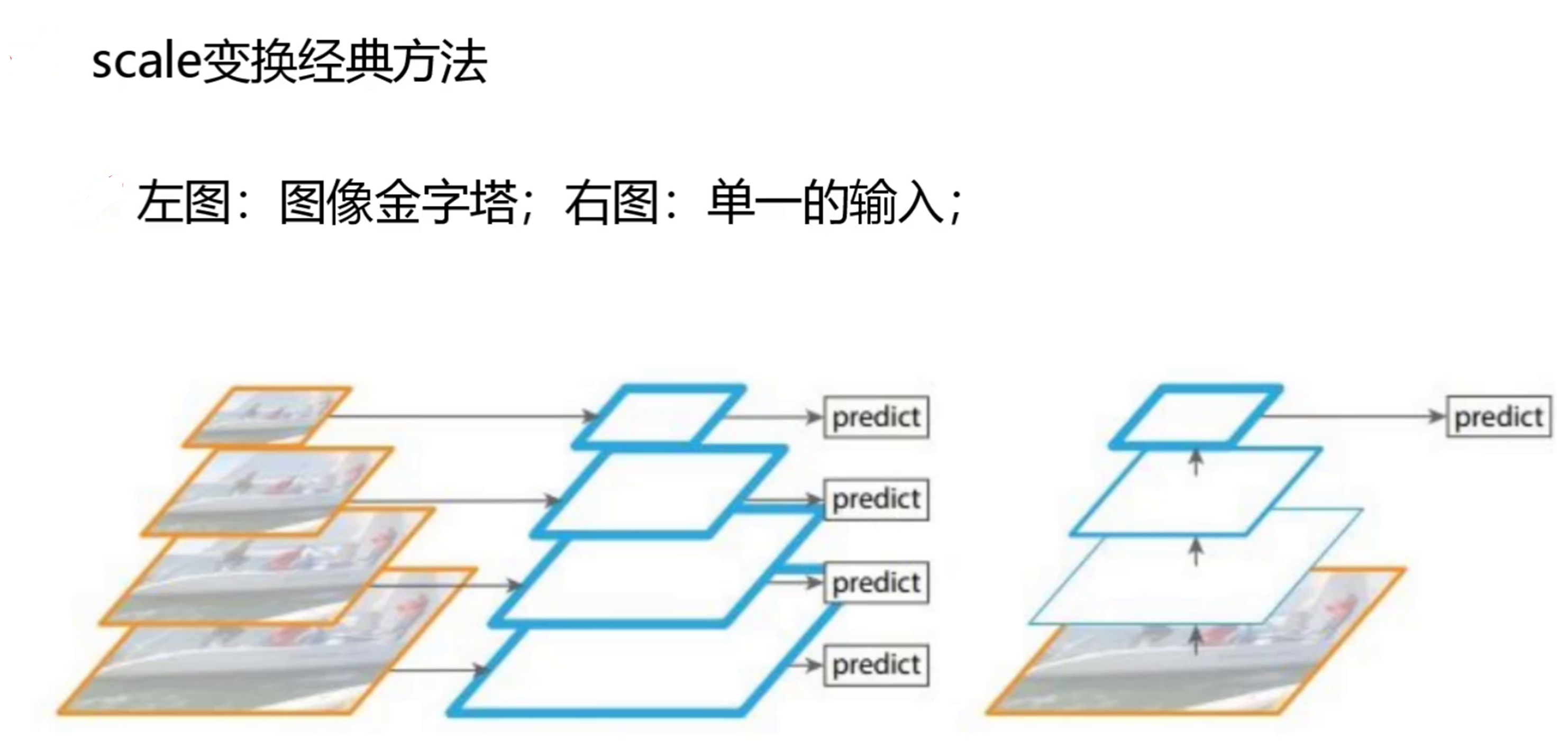
图像金字塔:将图像通过不同尺度的缩放,生成一系列不同分辨率的图像,类似金字塔形状 。一般是先对原始图像进行下采样得到低分辨率图像,再逐步往上采样得到不同分辨率的图像层。
单一输入:仅将原始图像作为网络输入,不进行多尺度缩放处理 。直接对原始图像进行特征提取、目标检测等操作。
但是这两张方法不利于yolo检测速度
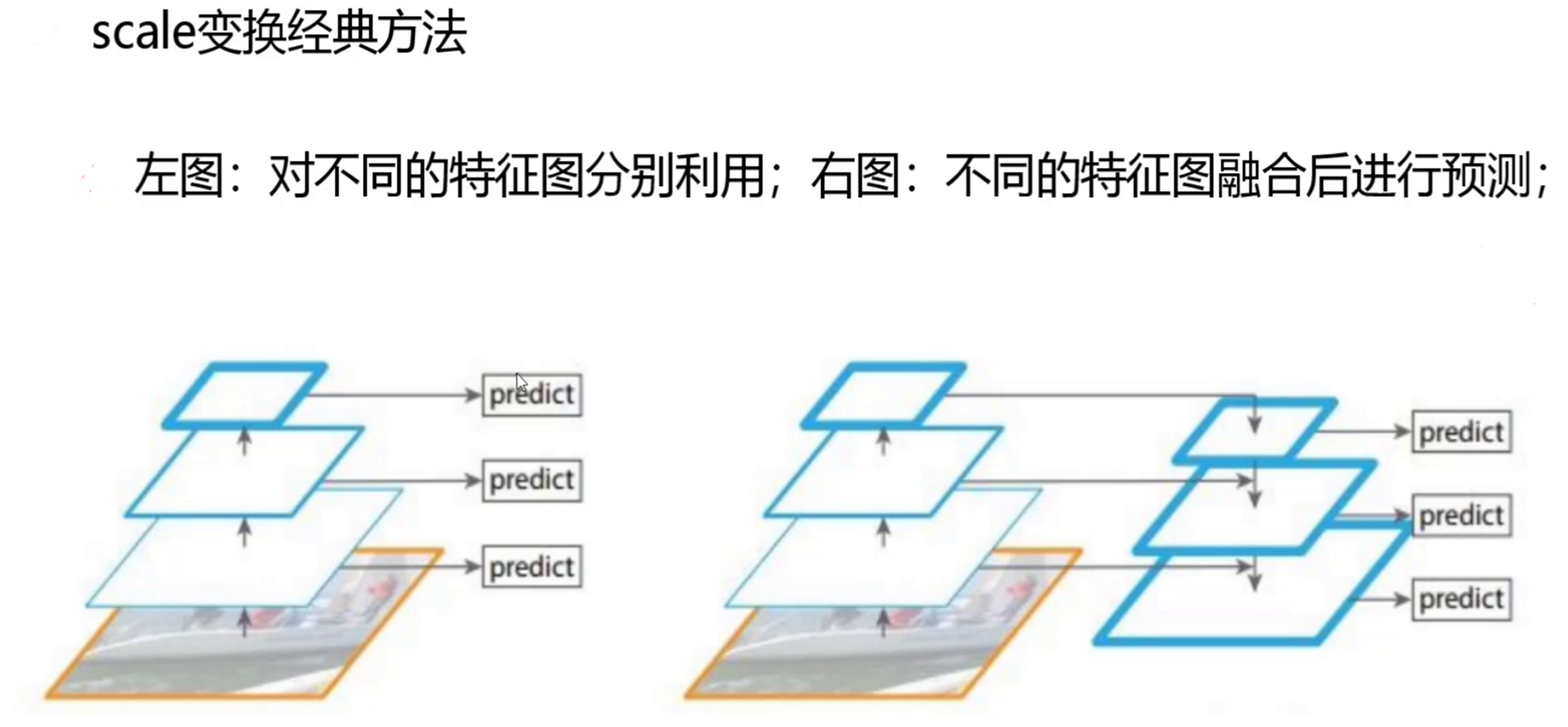
对不同特征图分别利用:从网络不同层获取不同尺度特征图,每个特征图单独进行目标检测预测,不进行特征图间融合操作 。例如在卷积神经网络中,浅层特征图包含更多细节信息,深层特征图包含更多语义信息,分别用这些特征图做预测。
不同特征图融合后进行预测:先对不同尺度特征图进行上采样或下采样等操作,使它们在相同尺度下,再通过拼接、相加等方式融合特征信息,最后基于融合后的特征图进行目标检测预测 。如 YOLOv3 通过上采样将深层特征图和浅层特征图融合,结合不同层次特征优势。
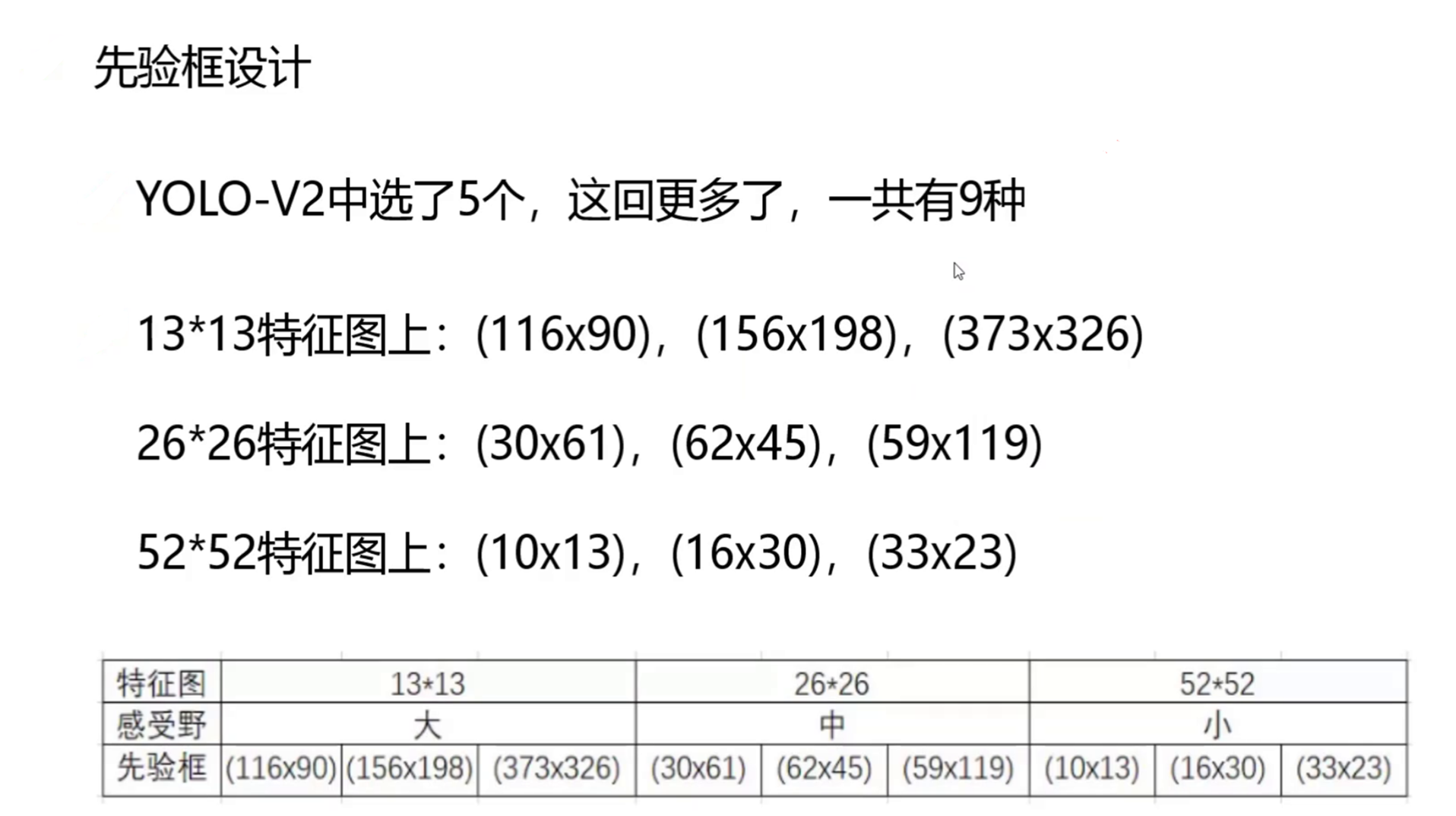
YOLO3延续了K-means聚类得到先验框的尺寸方法,为每种下采样尺度设定3种先验框,总共聚类出9种尺寸的先验框。在COCO数据集这9个先验框是:(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)。
分配上,在最小的13*13特征图上(有最大的感受野)应用较大的先验框(116x90),(156x198),(373x326),适合检测较大的对象。中等的26*26特征图上(中等感受野)应用中等的先验框(30x61),(62x45),(59x119),适合检测中等大小的对象。较大的52*52特征图上(较小的感受野)应用较小的先验框(10x13),(16x30),(33x23),适合检测较小的对象。
四、预测机制改进:从 softmax 到多标签预测
YOLOv3用多个独立的Logistic分类器替代了传统目标检测模型中常用的Softmax分类层
YOLOv3 对预测机制进行了革新,改进了 softmax,使其能够处理多标签任务。传统的 softmax 函数假设每个目标仅属于一个类别,但在实际场景中,一个目标可能同时具有多个类别属性,比如一个救援机器人可能同时具备 "救援设备" 和 "移动机器人" 等多个标签。
在Logistic分类器(逻辑回归)中,每个类别的预测是独立进行的。对于输入样本,分类器会为每个类别计算一个概率值,表示该样本属于该类别的可能性。
Logistic分类器通常使用Sigmoid函数(也称为Logistic函数)作为激活函数。Sigmoid函数将神经网络的输出映射到(0, 1)区间,表示样本属于某个类别的概率。Sigmoid函数的数学表达式为如下图,其中,z是神经网络的原始输出。
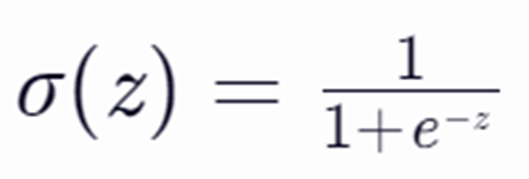
假设有一个图像分类任务,需要识别图像中是否包含"猫"、"狗"和"鸟"三种动物。使用Logistic分类器时,模型会为每个类别(猫、狗、鸟)分别计算一个概率值。例如:
• 图像 A :猫的概率 =0.8 ,狗的概率 =0.3 ,鸟的概率 =0.1
• 图像 B :猫的概率 =0.2 ,狗的概率 =0.7 ,鸟的概率 =0.6
设定阈值为0.5,则:
• 图像 A 会被标记为"猫"(因为猫的概率 >0.5 ),而不会被标记为"狗"或"鸟"(因为它们的概率 <0.5 )。
• 图像 B 会被标记为"狗"和"鸟"(因为它们的概率都 >0.5 ),而不会被标记为"猫"(因为猫的概率 <0.5 )。