系统架构
概述了 Dify 的系统架构,解释主要组件如何协同工作以提供大语言模型(LLM)应用开发平台。内容涵盖高层架构、部署选项、核心子系统和外部集成。
1. 整体架构
Dify 采用基于微服务的架构,将前端 Web 应用与后端 API 服务分离。系统设计支持可扩展性、可部署性,并能适应多种环境(包括自托管和云部署)。
高层组件概览
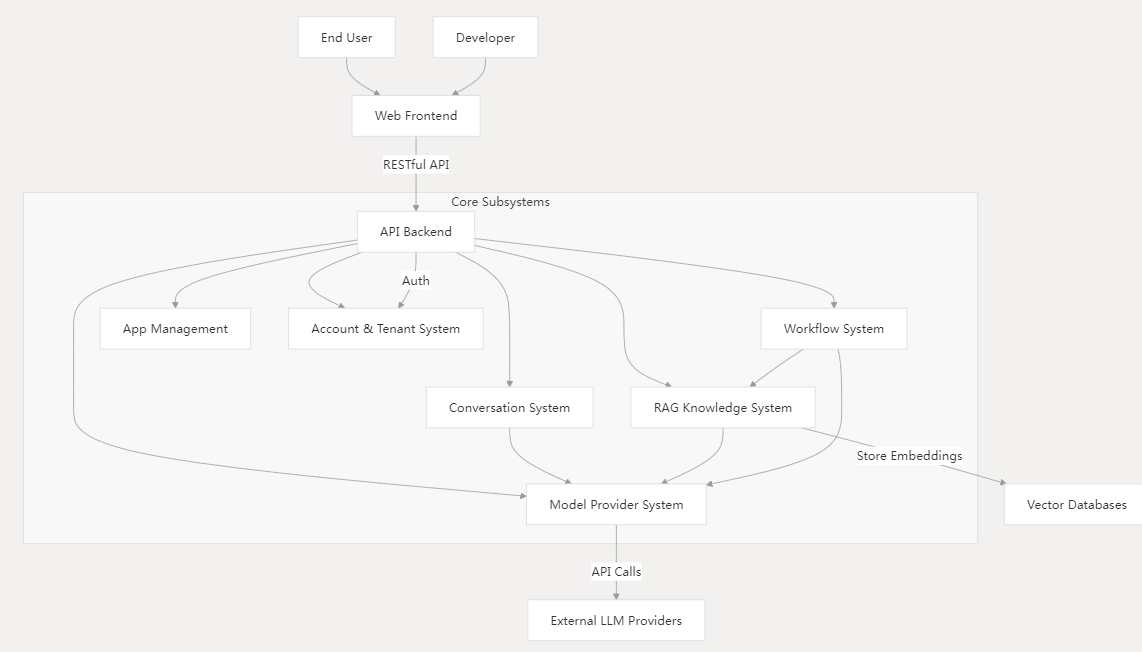
架构组成:
- Web 前端:基于 Next.js 的 Web 应用,为开发者提供应用创建界面,为终端用户提供交互界面。
- API 后端:基于 Flask 的 API 服务器,处理前端请求并协调核心子系统。
- 核心子系统 :
- 会话系统:管理聊天与补全交互
- RAG 知识系统:处理文档处理、索引与检索
- 工作流系统:支持复杂 AI 工作流创建
- 模型供应系统:集成多 LLM 供应商
- 账户与租户系统:管理用户、工作空间及认证
- 外部集成 :
- LLM 供应商(OpenAI、Azure、Anthropic 等)
- 向量数据库(Weaviate、Qdrant、Milvus 等)
- 关系型数据库(PostgreSQL)
- 缓存系统(Redis)
2. 部署架构
Dify 使用 Docker 实现容器化部署,支持灵活环境部署。系统由多个可独立扩展的服务组成。
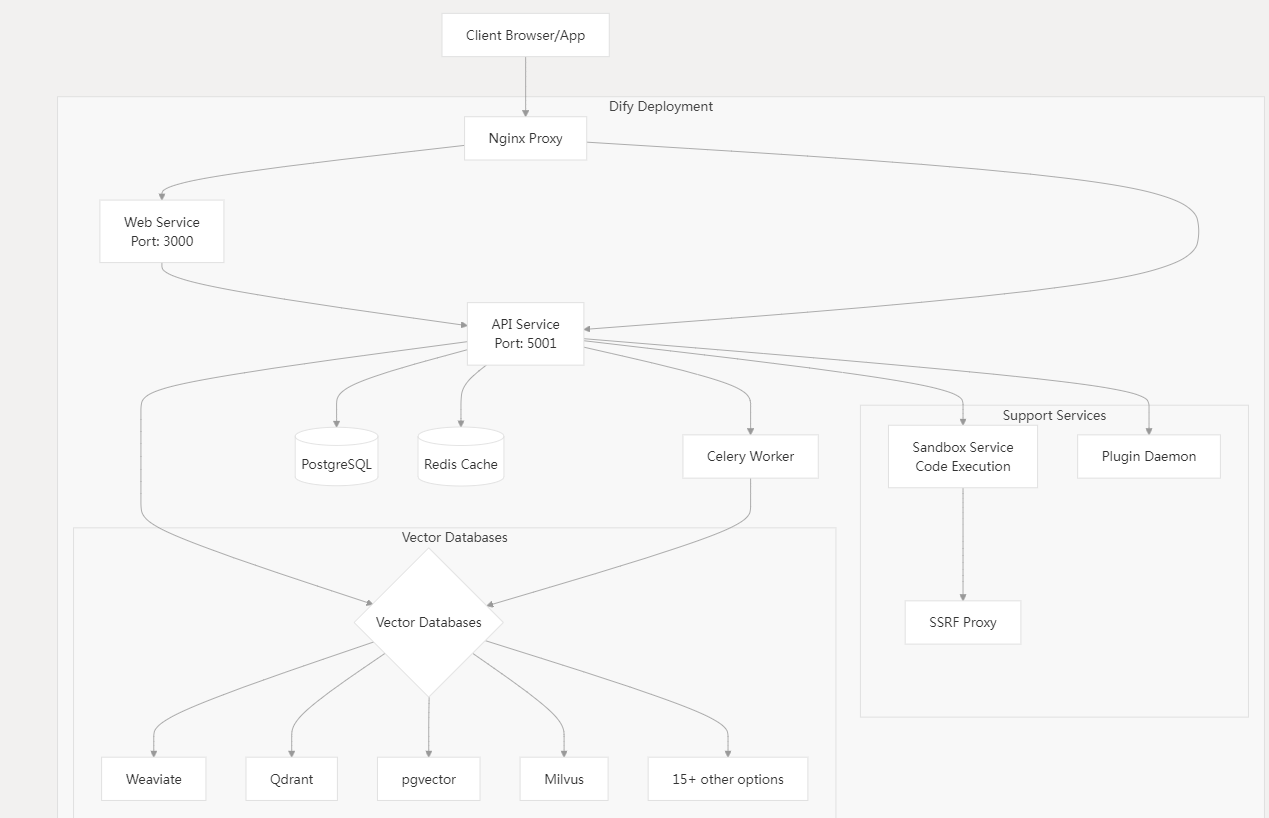
关键部署组件:
- API 服务 :提供 REST API 端点的 Flask 应用(端口 5001,镜像
langgenius/dify-api)。 - Web 服务 :Next.js 前端应用(端口 3000,镜像
langgenius/dify-web)。 - 工作节点服务:处理异步任务的 Celery 工作节点(如文档处理与索引)。
- 支持服务 :
- sandbox(安全代码执行)
- plugin插件守护进程(管理插件)
- SSRF 代理(防御服务端请求伪造攻击)
- 数据库与缓存 :
- PostgreSQL(结构化数据)
- Redis(缓存与 Celery 任务队列)
- 向量数据库(可配置:Weaviate、Qdrant 等)
- Nginx:作为 Web 和 API 服务的反向代理。
3. 核心子系统
3.1 API 后端架构
基于 Flask 的模块化设计,通过服务和控制器处理业务逻辑。
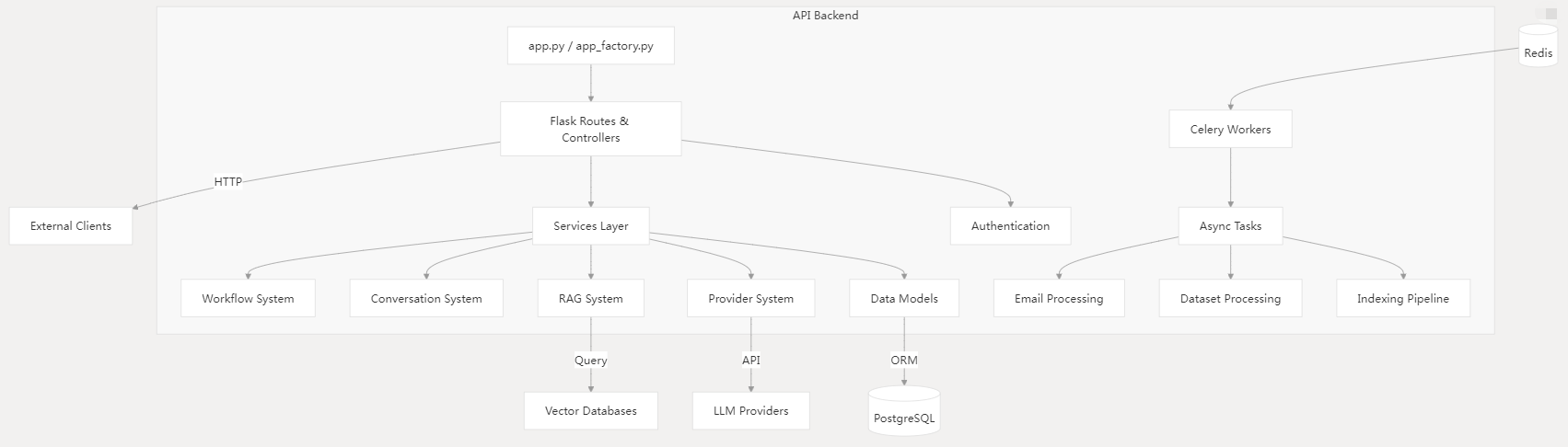
关键组件:
- 入口点 :
app.py(主入口)和app_factory.py(Flask 应用工厂)。 - 控制器层 :位于
api/controllers/,实现 REST API 端点。 - 服务层 :位于
api/services/,封装核心业务逻辑。 - 异步处理:Celery 工作节点处理文档索引等资源密集型操作。
3.2 Web 前端架构
基于 Next.js 和 React 的现代化响应式界面。
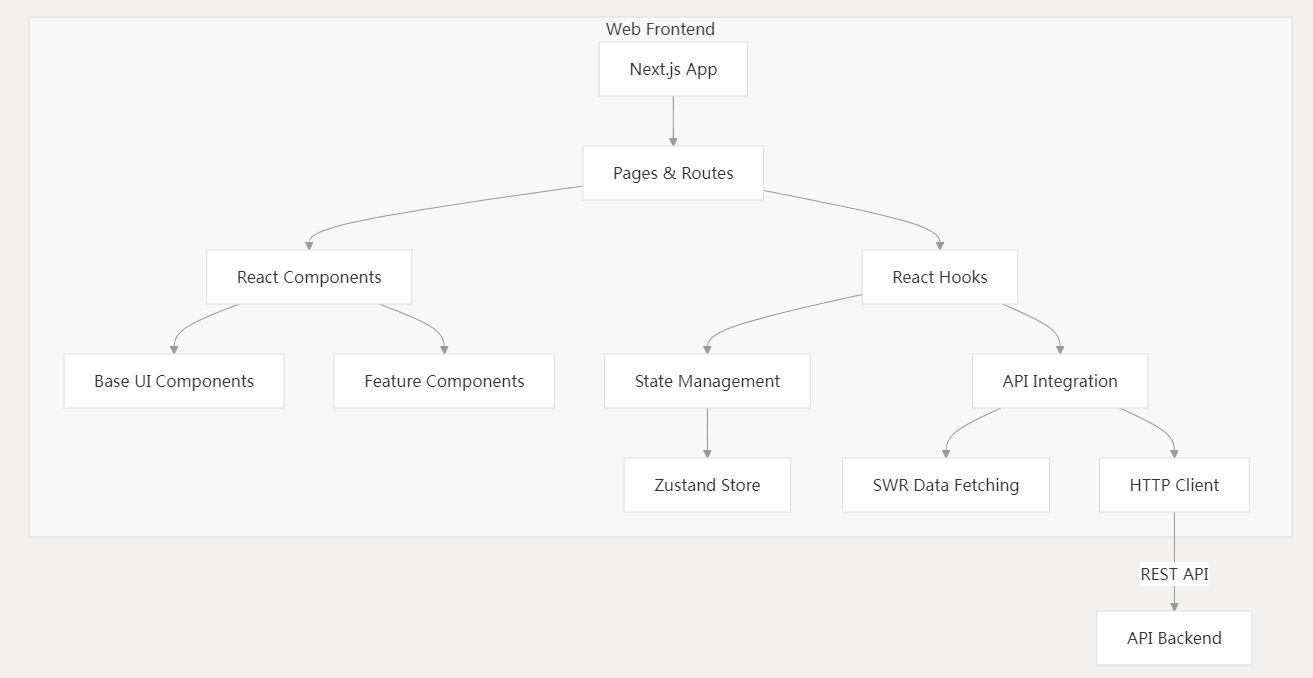
关键组件:
- Next.js 应用 :位于
web/app/,支持服务端渲染。 - 组件库:可复用的基础与功能组件。
- 状态管理:使用 Zustand 管理复杂 UI 状态。
- API集成:与后端API进行通信 使用SWR进行数据获取和缓存以及为不同的端点实现API客户端。
3.3 RAG 知识系统
负责文档处理、嵌入存储和检索,支持 LLM 上下文增强。
关键功能:
- 数据集服务 :管理文档数据集
- 创建并配置数据集
- 处理文档上传与处理
- 索引运行器 :通过ETL管道处理文档
- 提取:从各种文档格式中获取文本
- 转换:分块、清理并准备文本
- 加载:创建嵌入并存储到向量数据库中
- 检索系统 :支持多种检索方法
- 使用向量嵌入进行语义搜索
- 关键词搜索
- 全文搜索
- 结合多种方法的混合方法
- 向量存储工厂 :抽象向量数据库实现
- 支持多种向量数据库(如Weaviate、Qdrant、Milvus等)
- 为创建和查询向量存储提供统一接口
3.4 模型供应系统
集成多 LLM 供应商并提供统一接口。
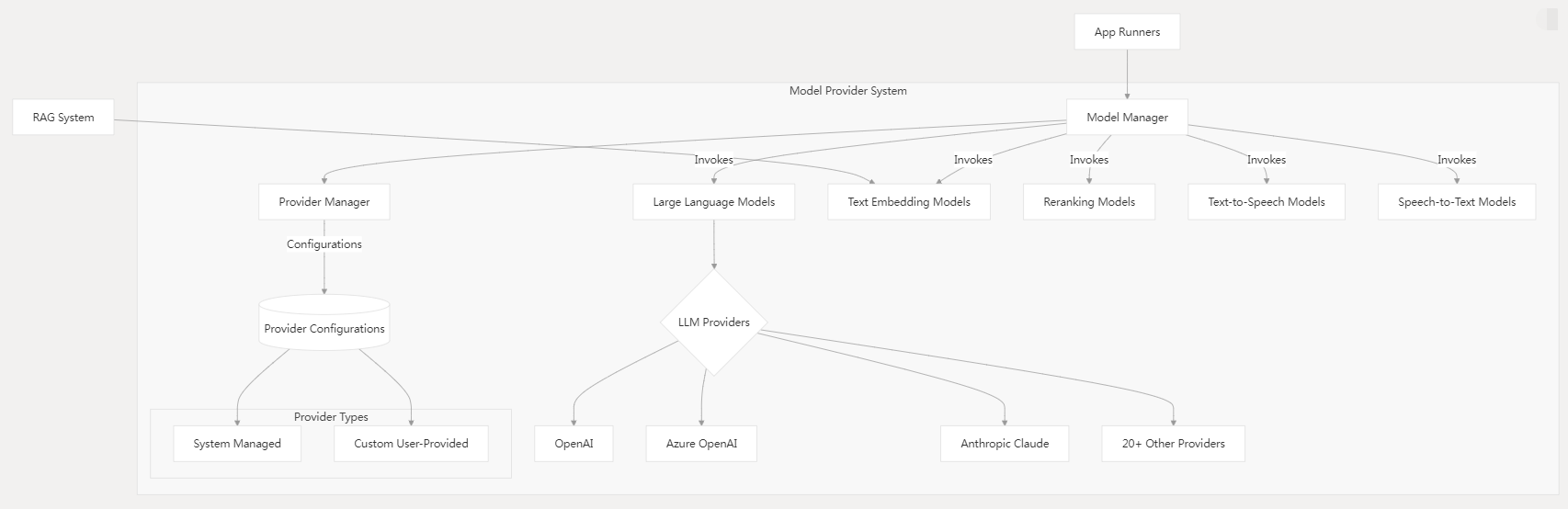
关键功能:
- 模型管理器 :模型交互的核心接口
- 支持不同的模型类型(大语言模型、嵌入模型、重排模型等)
- 处理模型选择和回退策略
- 供应商管理器 :管理供应商配置
- 安全存储API密钥和端点
- 支持系统管理和用户提供的凭证
- 模型类型 :
- 大语言模型(LLMs):用于文本生成
- 文本嵌入模型:用于向量表示
- 重排模型:用于提高搜索相关性
- 文本转语音:用于音频生成
- 语音转文本:用于转录
- 供应商集成 :
- 支持20多家模型供应商
- 为所有供应商提供标准化接口
- 凭证管理和API密钥轮换
3.5 对话系统
对话系统负责管理用户与大型语言模型(LLM)之间的交互,处理聊天历史记录、消息格式化和上下文管理。
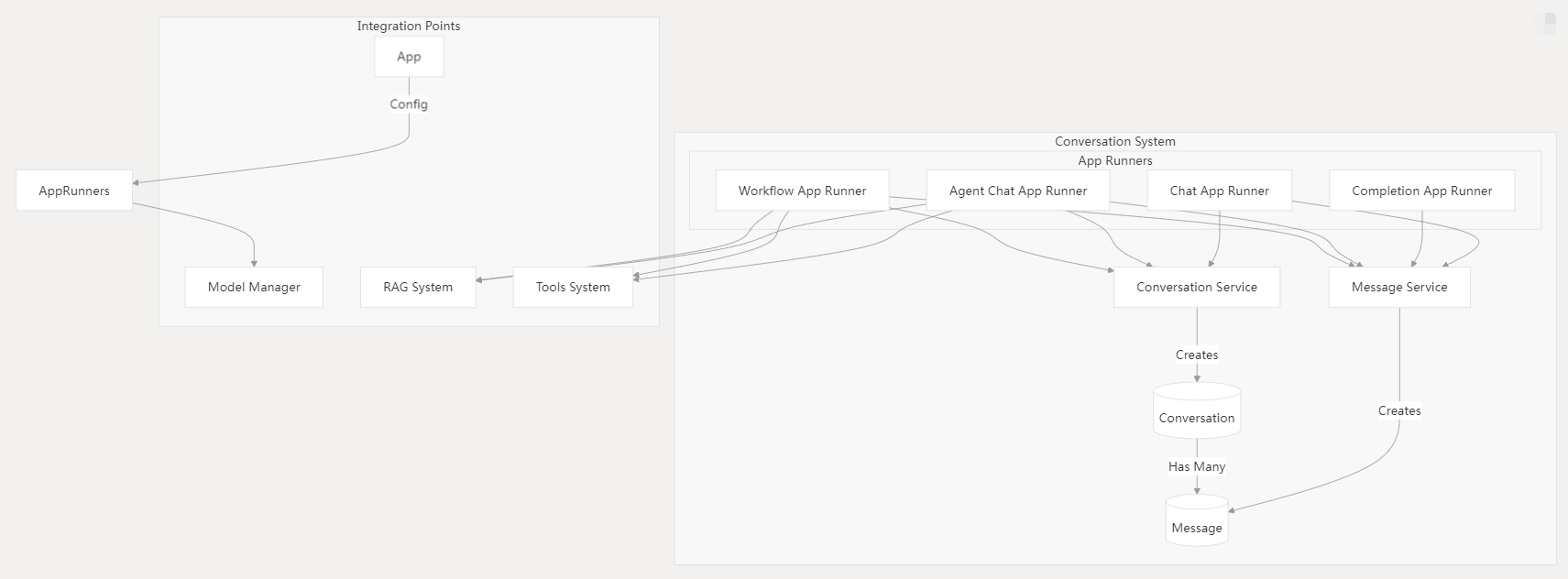
关键功能
- 对话服务 :管理对话会话
- 创建和更新对话
- 维护对话状态和元数据
- 消息服务 :处理单独的消息
- 处理用户输入
- 格式化模型响应
- 存储消息历史
- 应用运行器 :实现不同的应用类型
- Chat:支持多轮对话
- Completion:处理单次交互
- Agent Chat:支持使用工具的代理交互
- Workflow:执行复杂多步骤流程
- 集成点
- 应用配置
- 文本生成的模型集成
- 知识检索的RAG系统
- 代理能力的工具支持
3.6 工作流系统
工作流系统支持创建和执行复杂的AI流程,将LLM交互与工具、分支逻辑和数据转换相结合。
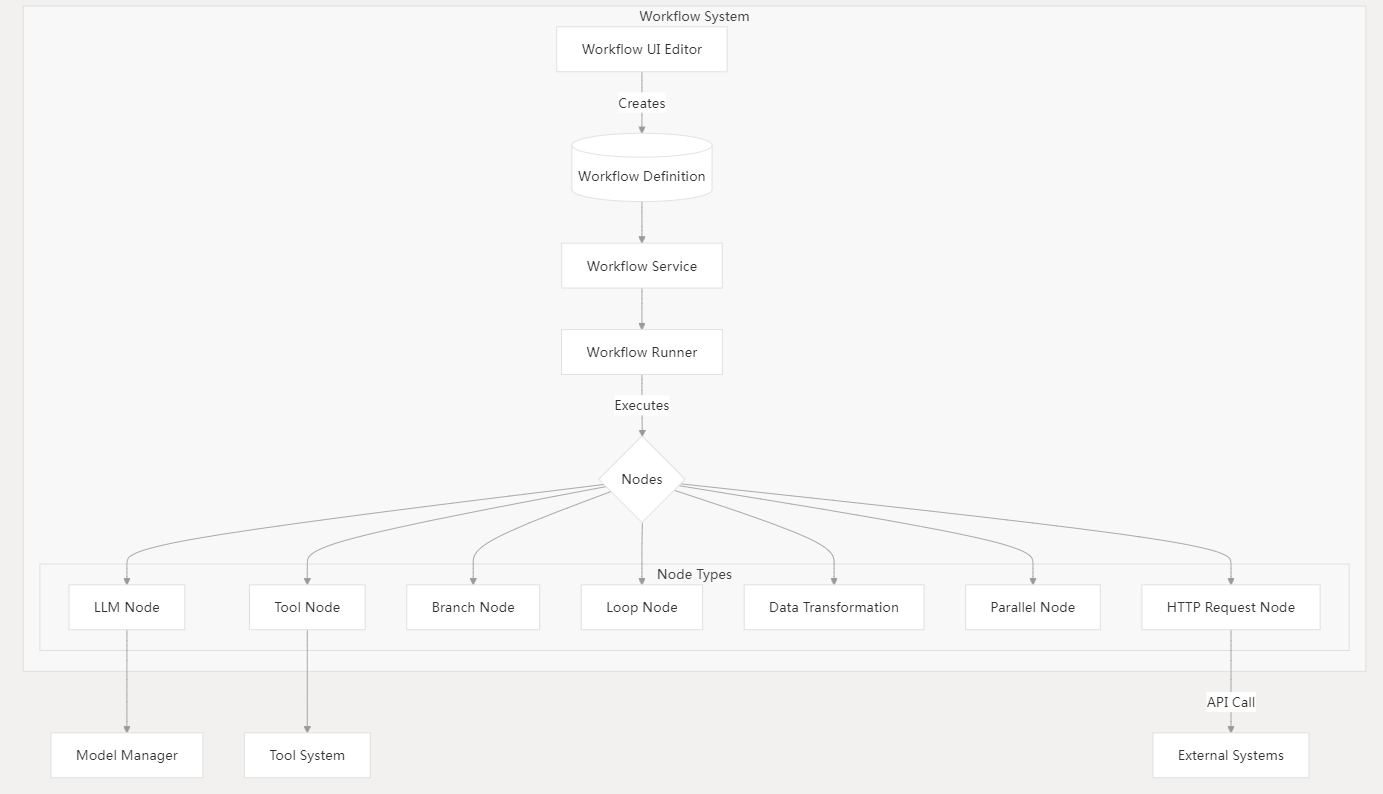
关键组件
- 工作流编辑器
- 基于节点的可视化编辑界面
- 配置节点参数
- 测试和调试工作流
- 工作流服务
- 存储工作流配置
- 管理版本控制与发布
- 工作流运行器
- 遍历工作流图
- 管理执行状态
- 处理错误恢复
- 节点类型
- LLM节点:文本生成
- 工具节点:调用外部工具和插件
- 分支节点:条件逻辑控制
- 循环节点:迭代处理
- 数据转换:数据操作
- 并行节点:并发执行
- HTTP请求节点:外部API调用
4. 存储与数据库
Dify使用多种存储系统来管理不同类型的数据。
4.1 PostgreSQL
存储结构化数据,关键表包括用户、应用、数据集、会话和工作流。
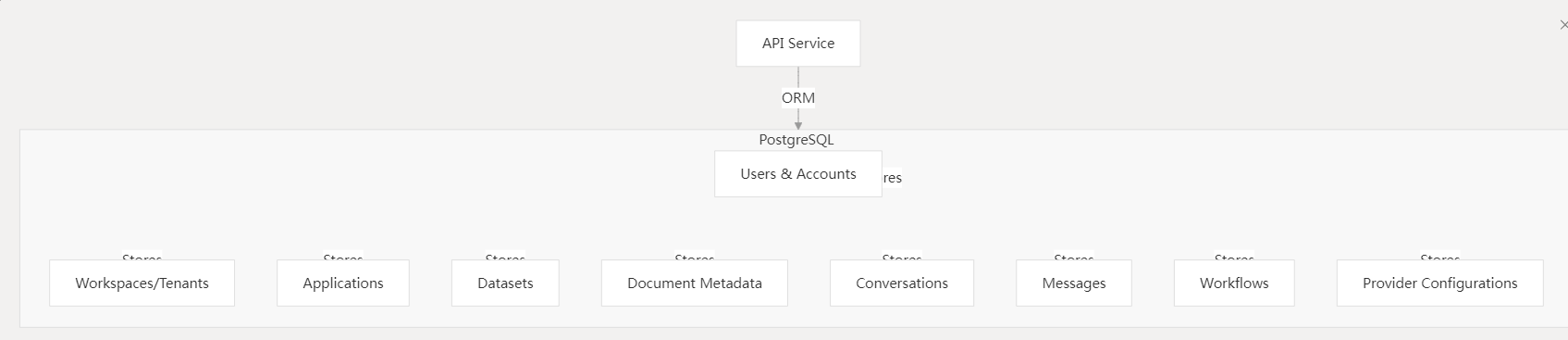
关键组件:
- 数据库配置:
- 可配置的连接参数
- 为提升性能的连接池
- 对pgvector扩展的支持(可选)
- 关键表:
- 用户与账户
- 租户(工作区)
- 应用程序
- 数据集与文档
- 对话与消息
- 工作流和节点
- 提供商配置
4.2 向量数据库
Dify支持多种向量数据库选项,用于存储RAG系统中使用的嵌入。
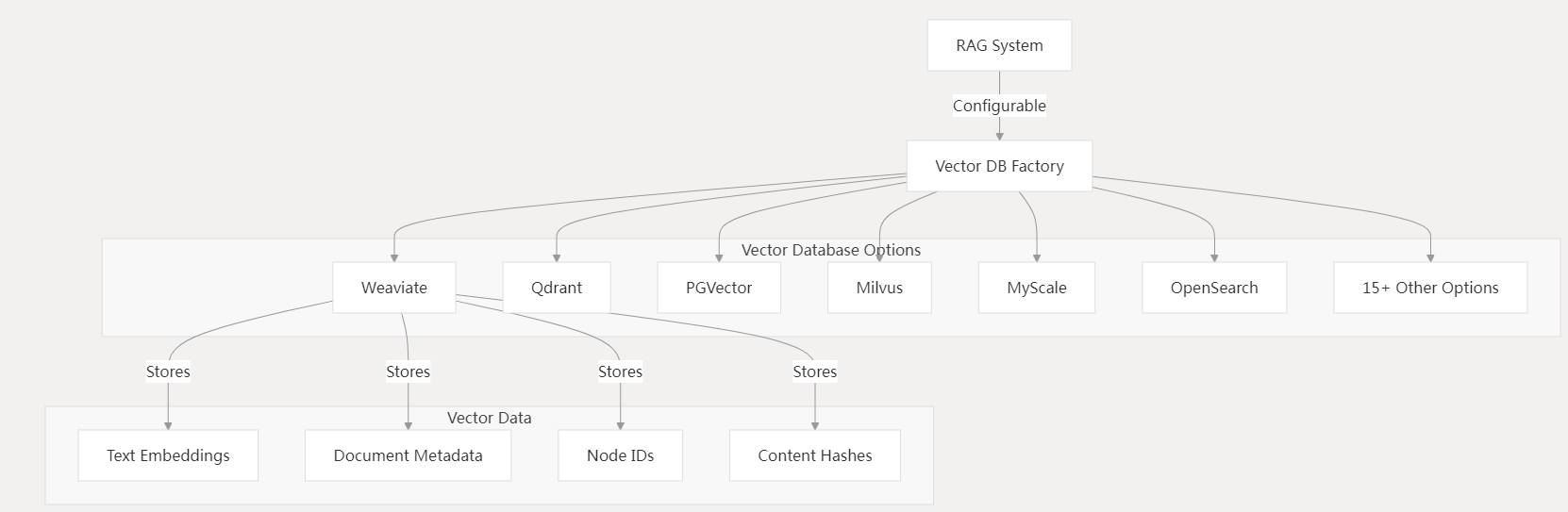
关键特征:
-
向量工厂抽象:
- 统一接口:为不同向量数据库提供统一接口
- 动态实例化:基于配置实现动态实例化
- 运行时切换:支持运行时切换向量数据库
-
支持的向量数据库:
- Weaviate(默认)
- Qdrant
- PGVector(PostgreSQL 扩展)
- Milvus
- MyScale
- OpenSearch
- 其他 15+ 选项
-
向量数据存储:
- 文本嵌入向量:存储生成的文本嵌入
- 文档元数据:关联文档的元数据信息
- 节点 ID 检索:存储用于检索的节点标识符
- 内容哈希去重:通过内容哈希值实现去重功能
4.3 文件存储
Dify使用一个可配置的存储系统来进行文件上传和文档存储。
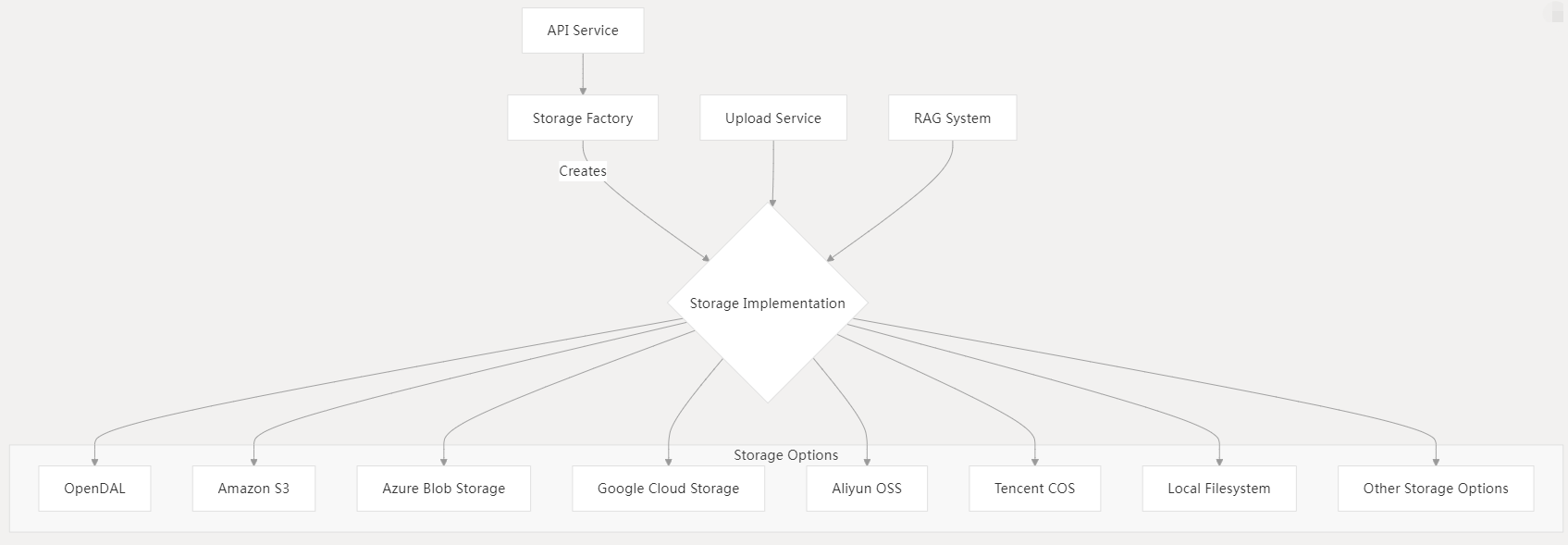
主要特性:
-
存储工厂模式:
- 对不同存储后端的抽象
- 统一文件操作接口
- 支持运行时配置
-
支持的存储选项:
- OpenDAL(默认,支持多后端)
- Amazon S3
- Azure Blob Storage
- Google Cloud Storage
- 阿里云OSS
- 腾讯云COS
- 本地文件系统
- 其他多种存储提供商
-
使用场景:
- RAG系统的文档上传
- 用户文件附件存储
- 应用程序资源管理
5. 系统配置
Dify使用了一套全面的配置系统,该系统支持环境变量、配置文件和运行时设置。
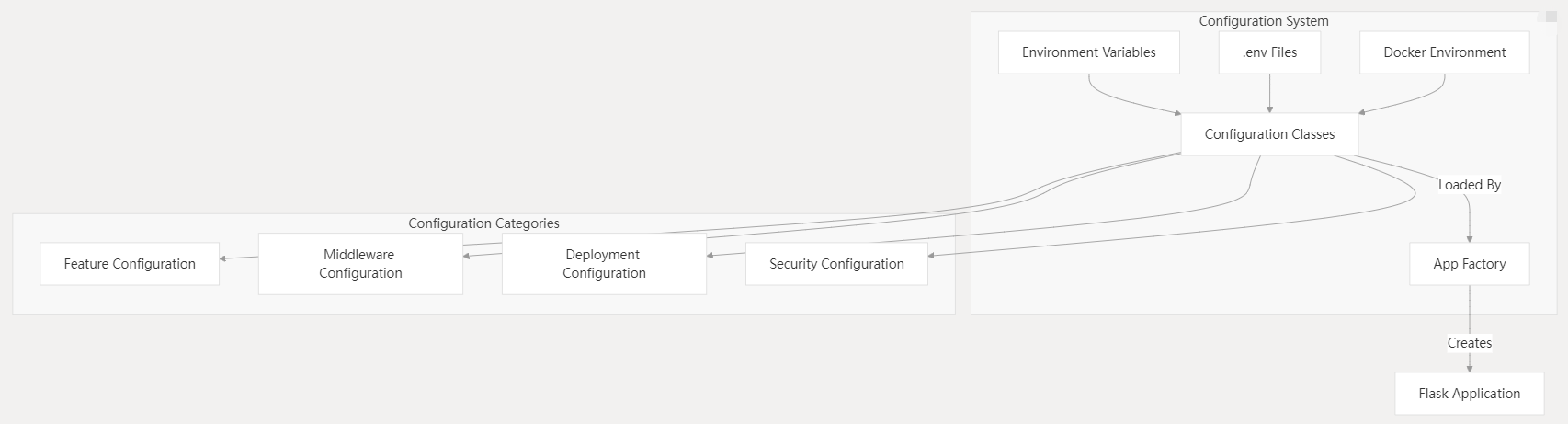
关键配置机制
-
配置来源
- 环境变量(Environment Variables)
.env配置文件- Docker 环境变量
- 命令行参数(Command-line Arguments)
-
配置分类
- 功能配置:控制应用程序特性开关
- 中间件配置:数据库连接、缓存策略、存储设置
- 部署配置:运行时参数(如端口、并发数)
- 安全配置:身份验证、数据加密、访问控制
-
技术实现
- Pydantic 配置类:基于类型注解的配置建模
- 强类型校验:自动验证配置数据类型
- 环境感知加载:根据运行环境动态载入配置
- 默认值机制:提供安全的缺省参数配置
6. 开发与部署流程
介绍Dify的开发和部署工作流程。
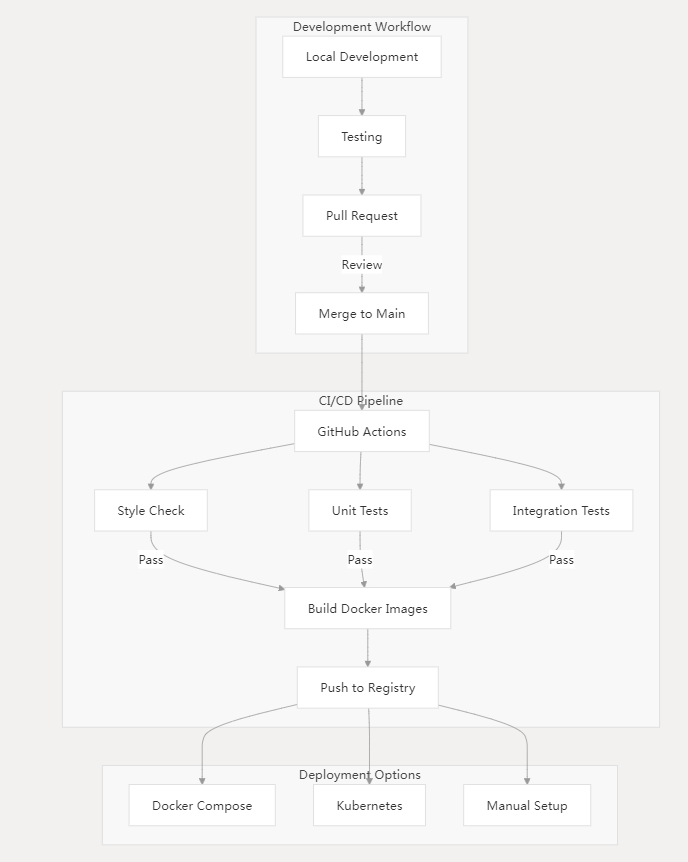
工作流:
本地开发 → 测试 → PR 审查 → 合并至主分支 → CI/CD(GitHub Actions) → 构建镜像 → 部署(Docker/K8s) 核心要点:
-
开发流程:
- 使用Docker Compose进行本地开发
- 本地测试运行
- 代码审查制的Pull Request流程
-
CI/CD管道:
- GitHub Actions自动化流程
- 代码风格检查
- 单元测试与集成测试
- Docker镜像构建与推送
-
部署方案:
- Docker Compose部署(推荐方案)
- Kubernetes集群部署
- 手动配置部署