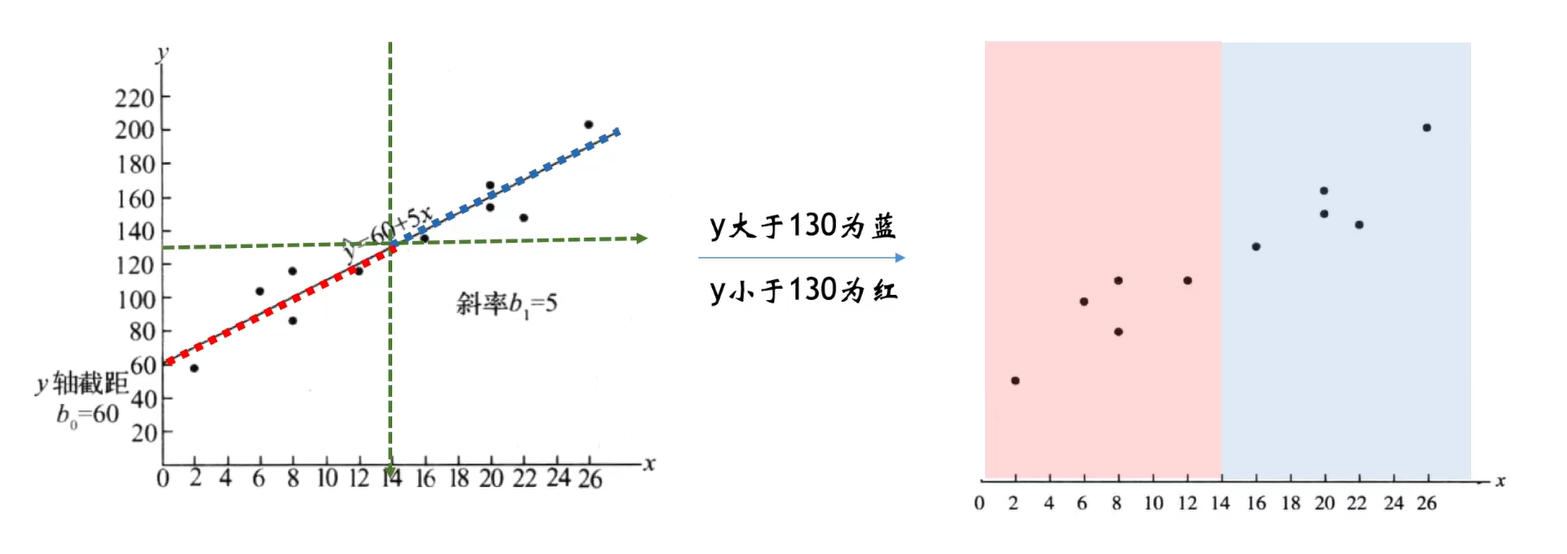
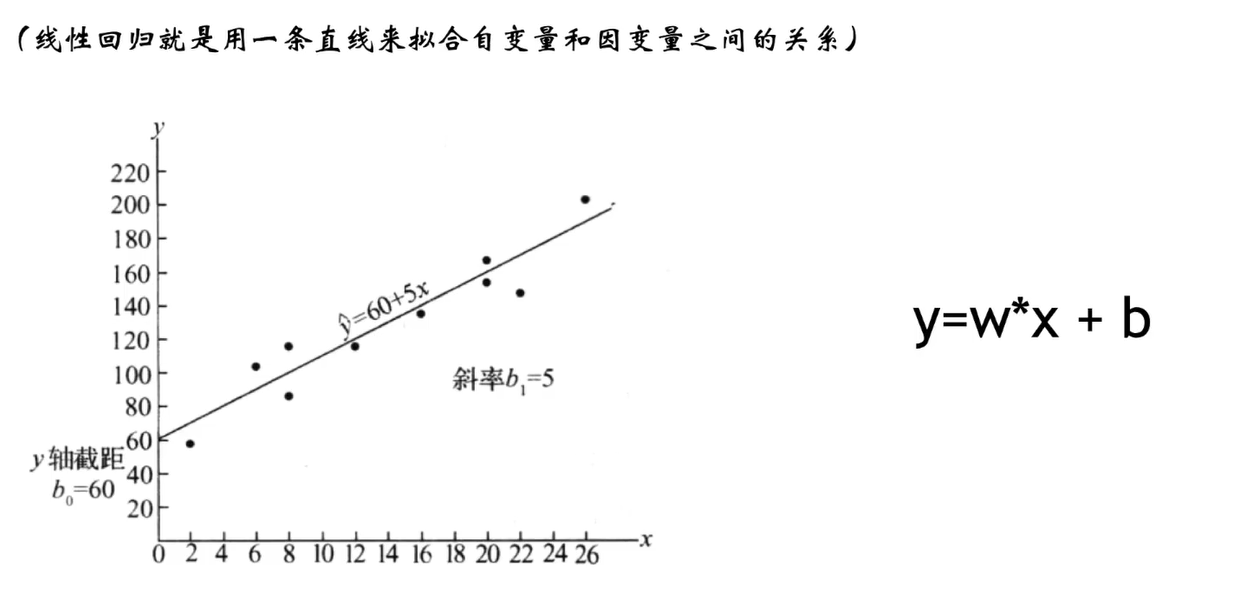
一、逻辑回归的作用
解决二分类问题
二、逻辑回归模型原理
逻辑回归模型包括两个部分:一个是线性回归函数 ;另一个是应用在线性回归函数输出结果上的逻辑函数(Sigmoid函数),它将线性回归的输出映射到0和1之间,从而可以将线性输出表示为概率。
1.线性回归函数
对于多特征数据:
输入特征与权重的点积加上偏置项(截距),k为特征权重,b为函数偏置,x为特征。完成逻辑回归模型第一步的计算。
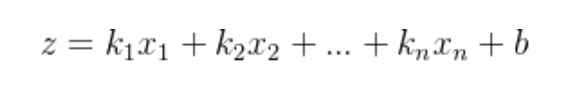
2.Sigmoid函数
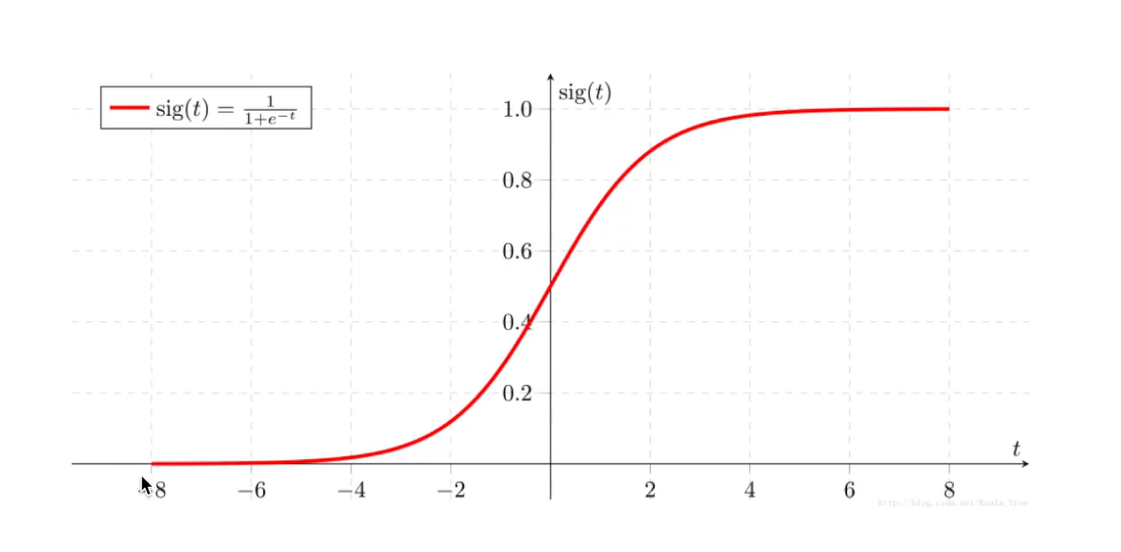
Sigmoid函数如何起作用?
给定输入特征x时,样本属于类别1的概率可以使用Sigmoid函数计算:
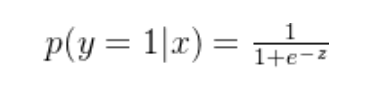
其中,z为线性回归函数,由此输出一个介于0和1之间的概率值。
通常将概率值0.5作为阈值,当p大于0.5时,预测类别为1;否则,预测类别为0。(可自定义值)
关系总结:

模型损失函数
逻辑回归模型训练过程中的参数优化一般使用最大似然估计 来实现。对应的损失函数是交叉熵损失(Cross-Entropy Loss),也称为对数损失(Log Loss)


对数损失函数的设计确保了以下特性:
当真实标签 y = 1时:
- 模型预测概率
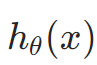 越接近 1,损失越小(趋近于 0)。
越接近 1,损失越小(趋近于 0)。 - 模型预测概率越接近 0,损失越大(趋近于无穷大)。
当真实标签 y = 0 时:
- 模型预测概率 越接近 0,损失越小(趋近于 0)。
- 模型预测概率 越接近 1,损失越大(趋近于无穷大)。
这种特性使得模型在训练时会强烈惩罚那些预测错误且置信度高的样本,从而促使模型学习更准确的分类边界。

模型训练优化器
梯度下降
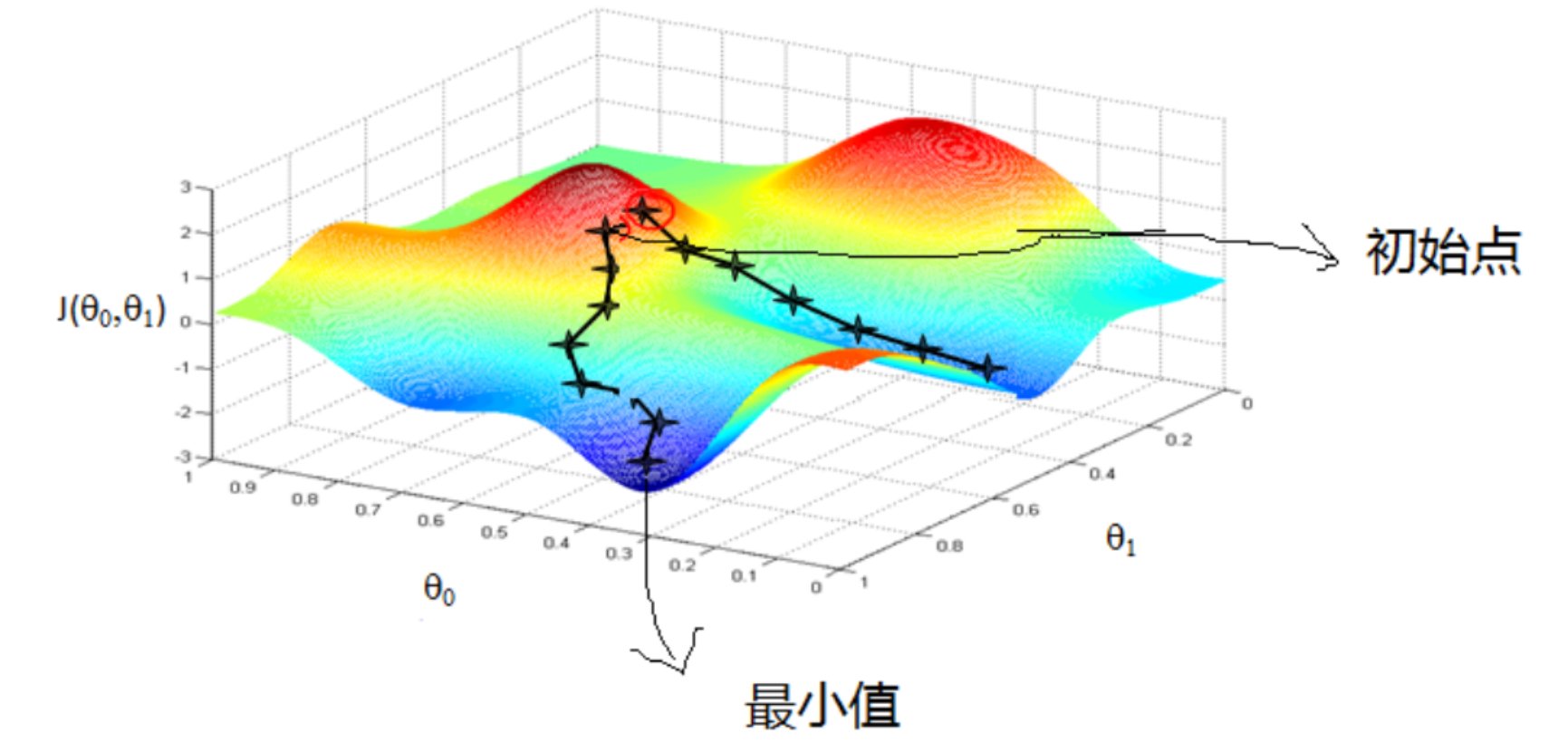
梯度下降(Gradient Descent)是一种优化算法,用于寻找函数的局部最小值。在机器学习中,它被广泛用于最小化损失函数(如逻辑回归中的对数损失),从而找到模型的最优参数。以下是关于梯度下降的详细解释:
1. 直观理解:下山类比
假设你站在一座山上,想要找到最低点(山谷)。梯度下降的策略是:
- 观察当前位置的坡度(即梯度,代表函数增长最快的方向)。
- 朝着坡度的反方向走一步(即梯度的负方向,函数下降最快的方向)。
- 重复上述步骤,直到无法继续下降(到达山谷或接近最低点)。
关键要点:
- 梯度:函数在某点的导数(多维情况下是偏导数组成的向量),指示函数增长最快的方向。
- 步长 :每次移动的距离,由学习率(
learning_rate)控制。
初始参数的选择
初始值不同,获得的最小值也有可能不同,梯度下降有可能得到的是局部最小值。如果损失函数是凸 函数,则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法 ,关键损失函数的 最小值,选择损失函数最小化的初值。
实战
python
import numpy as np
import matplotlib.pyplot as plt
# 1. 数据加载与预处理
def load_data(file_path):
data = np.loadtxt(file_path, delimiter='\t')
X = data[:, :-1] # 特征(前两列)
y = data[:, -1].astype(int) # 标签(第三列,转为整数类型)
# 添加偏置项(截距)theta[0]是偏置项,theta[1]和theta[2]是特征权重,决定边界的斜率和截距。
X = np.hstack((np.ones((X.shape[0], 1)), X)) # 在第一列添加全1向量
return X, y
# 2. 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 3. 定义逻辑回归模型(线性回归的结果输入sigmoid函数)
def logistic_regression(X, theta):
z = np.dot(X, theta)
return sigmoid(z)
# 4. 定义损失函数(对数损失)
def loss_function(h, y):
m = y.shape[0]
return - (1 / m) * np.sum(y * np.log(h) + (1 - y) * np.log(1 - h))
# 5. 定义梯度下降优化算法
def gradient_descent(X, y, theta, learning_rate, num_iterations):
m = y.shape[0]
loss_history = []
for iteration in range(num_iterations):
h = logistic_regression(X, theta)
gradient = (1 / m) * np.dot(X.T, (h - y))
theta -= learning_rate * gradient
# 记录损失值
if iteration % 100 == 0:
loss = loss_function(h, y)
loss_history.append((iteration, loss))
return theta, loss_history
# 6. 绘制决策边界与数据点
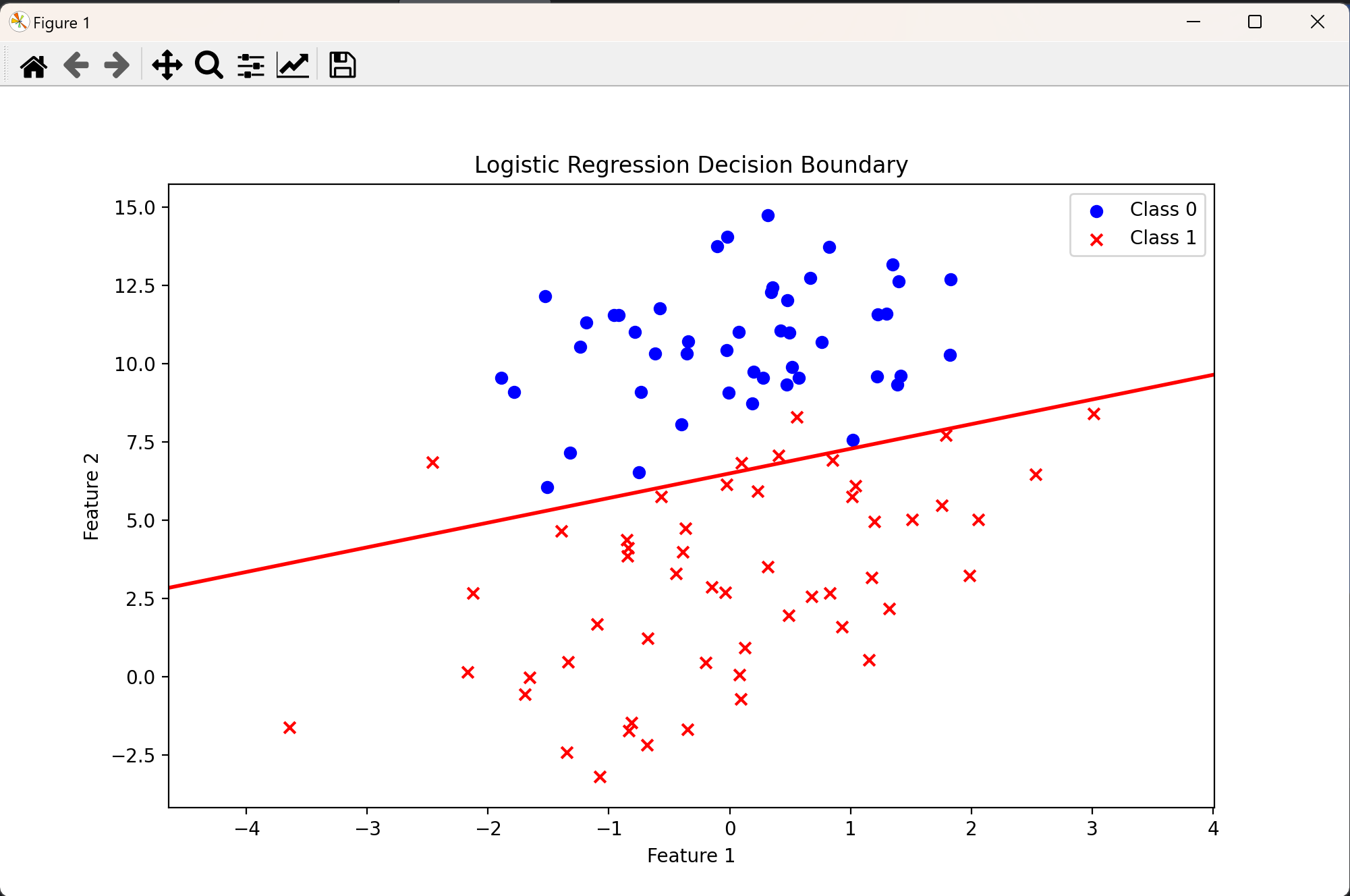
def plot_decision_boundary(X, y, theta):
# 提取特征数据(不包含偏置项)
x1 = X[:, 1]
x2 = X[:, 2]
# 创建网格点
x_min, x_max = x1.min() - 1, x1.max() + 1
y_min, y_max = x2.min() - 1, x2.max() + 1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
# 计算决策边界
Z = sigmoid(np.c_[np.ones((xx.ravel().shape[0], 1)), xx.ravel(), yy.ravel()].dot(theta))
Z = Z.reshape(xx.shape)
# 绘制图像
plt.figure(figsize=(10, 6))
# 绘制决策边界
plt.contour(xx, yy, Z, levels=[0.5], linewidths=2, colors='r')
# 绘制数据点(0类为蓝色圆形,1类为红色叉号)
plt.scatter(x1[y == 0], x2[y == 0], color='blue', marker='o', label='Class 0')
plt.scatter(x1[y == 1], x2[y == 1], color='red', marker='x', label='Class 1')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Logistic Regression Decision Boundary')
plt.legend()
plt.show()
# 7. 绘制损失函数收敛曲线
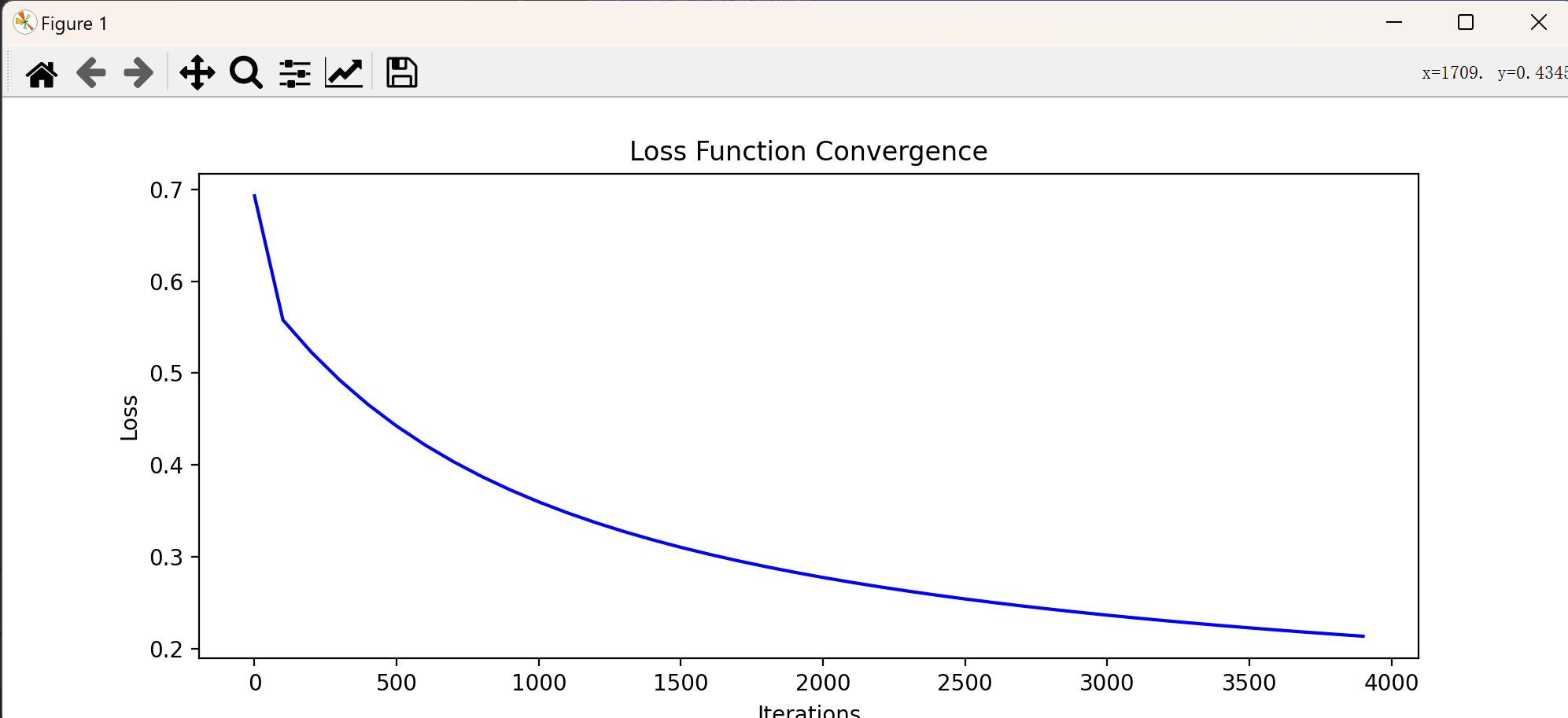
def plot_loss_history(loss_history):
iterations = [i[0] for i in loss_history]
losses = [i[1] for i in loss_history]
plt.figure(figsize=(10, 4))
plt.plot(iterations, losses, color='blue')
plt.xlabel('Iterations')
plt.ylabel('Loss')
plt.title('Loss Function Convergence')
plt.show()
# 主函数
if __name__ == "__main__":
# 配置参数
file_path = 'test5Set.txt' # 数据文件路径
learning_rate = 0.01 # 学习率
num_iterations = 4000 # 迭代次数
# 加载数据
X, y = load_data(file_path)
# 初始化参数(包含偏置项)
theta = np.zeros(X.shape[1]) # 特征数量+1(偏置项)
# 执行梯度下降优化
theta, loss_history = gradient_descent(X, y, theta, learning_rate, num_iterations)
# 打印最终参数
print("Final Parameters (theta):", theta)
# 绘制决策边界
plot_decision_boundary(X, y, theta)
# 绘制损失收敛曲线
plot_loss_history(loss_history)首先从文件加载数据,提取特征和标签并添加偏置项(数学方程中的截距,作用是让模型的决策边界(或函数曲线)能够在特征空间中自由平移,从而更好地拟合数据。);接着定义 Sigmoid 函数将线性回归结果映射为概率值;然后通过逻辑回归模型计算预测概率,并使用对数损失函数评估模型误差;之后利用梯度下降算法迭代优化参数(模型的权重向量**,**它包含偏置项和特征权重。),使损失函数最小化;最后通过可视化展示模型效果,包括绘制决策边界(区分两类样本的分界线)和损失函数收敛曲线(验证算法是否正常工作)。整个过程涵盖了数据处理、模型构建、参数优化和结果可视化的完整机器学习流程。
梯度下降函数步骤(每次迭代使用全部样本):
- 预测:用当前参数计算预测概率。
- 求导:计算损失函数对参数的梯度。
- 更新:沿负梯度方向更新参数。
- 记录:定期记录损失值,监控收敛性。
最终返回优化后的参数 theta 和损失历史 loss_history,用于后续评估模型效果。
运行结果