目录
[1.1 数据集介绍](#1.1 数据集介绍)
[1.2 CNN模型层结构](#1.2 CNN模型层结构)
[1.3 定义CNN模型](#1.3 定义CNN模型)
[1.4 神经网络的前向传播过程](#1.4 神经网络的前向传播过程)
[1.5 数据预处理](#1.5 数据预处理)
[1.6 加载数据](#1.6 加载数据)
[1.7 初始化](#1.7 初始化)
[1.8 模型训练过程](#1.8 模型训练过程)
[1.9 保存模型](#1.9 保存模型)
[2.1 定义与训练时相同的CNN模型架构](#2.1 定义与训练时相同的CNN模型架构)
[2.2 图像的预处理](#2.2 图像的预处理)
[2.3 预测](#2.3 预测)
[3.1 测试方法](#3.1 测试方法)
[3.2 测试结果](#3.2 测试结果)
[四 ,总结](#四 ,总结)
[5.1 模型训练部分代码](#5.1 模型训练部分代码)
[5.2 模型测试部分代码](#5.2 模型测试部分代码)
本实验直观地体现了CNN对比全连接对于图像处理的优势
全连接网络实现MNIST数字识别实验如下链接:
基于MNIST数据集的手写数字识别(简单全连接网络)-CSDN博客
一,模型训练
1.1 数据集介绍
MNIST 数据集由 60,000 张图像构成的训练集和 10,000 张图像组成的测试集构成,其中的图像均为 28×28 像素的灰度图,涵盖 0 - 9 这 10 个阿拉伯数字,且数字书写风格、大小、位置多样。它源于美国国家标准与技术研究所(NIST)的数据集,经过归一化和中心化处理。MNIST 数据集是图像识别研究领域的经典数据集,常用于开发和评估图像识别算法与模型,也是机器学习课程中常用的教学案例,许多高性能卷积神经网络模型在该数据集测试集上准确率可达 99% 以上,充分展现出其在机器学习领域的重要价值和广泛应用。
1.2 CNN模型层结构

1.3 定义CNN模型
python
def __init__(self):
super(CNN, self).__init__() # 调用父类的初始化方法
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 定义第一个卷积层,输入通道1,输出通道32,卷积核大小3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 定义第二个卷积层,输入通道32,输出通道64,卷积核大小3x3
self.pool = nn.MaxPool2d(2, 2) # 定义最大池化层,池化核大小2x2
self.dropout1 = nn.Dropout2d(0.25) # 定义第一个Dropout层,随机丢弃25%的神经元
self.fc1 = nn.Linear(64 * 12 * 12, 128) # 定义第一个全连接层,输入维度64*12*12,输出维度128
self.dropout2 = nn.Dropout(0.5) # 定义第二个Dropout层,随机丢弃50%的神经元
self.fc2 = nn.Linear(128, 10) # 定义输出层,输入维度128,输出维度10(对应10个数字类别)定义了一个用于手写数字识别的卷积神经网络(CNN)架构,专为 MNIST 等单通道图像分类任务设计。网络包含两个卷积层(Conv1 和 Conv2)进行特征提取,每个卷积层后接 ReLU 激活函数和最大池化层(MaxPool2d)进行下采样,逐步将 28×28 的输入图像转换为更高层次的抽象特征。为防止过拟合,在卷积层后添加了 Dropout2d (0.25),在全连接层前使用 Dropout (0.5) 增强模型泛化能力。特征提取完成后,通过两次全连接层(FC1 和 FC2)将卷积输出的多维特征映射到 10 个类别,最终输出对应 0-9 数字的分类得分。
1.4 神经网络的前向传播过程
python
def forward(self, x):
# 第一层卷积+ReLU激活
x = torch.relu(self.conv1(x))
# 第二层卷积+ReLU激活+池化
x = self.pool(torch.relu(self.conv2(x)))
# 应用Dropout
x = self.dropout1(x)
# 将多维张量展平为一维向量(64*12*12)
x = x.view(-1, 64 * 12 * 12)
# 第一个全连接层+ReLU激活
x = torch.relu(self.fc1(x))
# 应用Dropout
x = self.dropout2(x)
# 输出层,得到未归一化的预测分数
x = self.fc2(x)
return x1.5 数据预处理
python
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 使用MNIST数据集的均值和标准差进行归一化
])1.6 加载数据
python
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform) # 加载MNIST训练数据集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 创建数据加载器,批次大小为64,打乱数据1.7 初始化
python
model = CNN() # 创建CNN模型实例
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 定义Adam优化器,学习率为0.0011.8 模型训练过程
python
def train(epochs):
model.train() # 设置模型为训练模式
for epoch in range(epochs): # 进行指定轮数的训练
running_loss = 0.0 # 初始化本轮的损失累加器
for batch_idx, (data, target) in enumerate(train_loader): # 遍历数据加载器中的每个批次
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播,计算模型输出
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加当前批次的损失
if batch_idx % 100 == 0: # 每100个批次打印一次损失
print(f'Epoch {epoch + 1}, Batch {batch_idx}, Loss: {loss.item():.6f}')
print(f'Epoch {epoch + 1} completed, Average Loss: {running_loss / len(train_loader):.6f}') # 打印本轮平均损失1.9 保存模型
python
if __name__ == '__main__':
train(epochs=5) # 调用训练函数,训练5轮
torch.save(model.state_dict(),'mnist_cnn_model.pth') # 保存模型的参数
print("模型已保存为: mnist_cnn_model.pth") # 打印保存模型的信息二,模型测试
2.1 定义与训练时相同的CNN模型架构
python
class CNN(nn.Module):
def __init__(self):
# 调用父类初始化方法
super(CNN, self).__init__()
# 第一个卷积层:输入1通道(灰度图),输出32通道,卷积核3x3
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
# 第二个卷积层:输入32通道,输出64通道,卷积核3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
# 最大池化层:核大小2x2,步长2
self.pool = nn.MaxPool2d(2, 2)
# Dropout层:训练时随机丢弃25%的神经元,防止过拟合
self.dropout1 = nn.Dropout2d(0.25)
# 第一个全连接层:输入维度64*12*12,输出128
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# Dropout层:训练时随机丢弃50%的神经元
self.dropout2 = nn.Dropout(0.5)
# 输出层:输入128,输出10个类别(对应0-9数字)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一层卷积+ReLU激活
x = torch.relu(self.conv1(x))
# 第二层卷积+ReLU激活+池化
x = self.pool(torch.relu(self.conv2(x)))
# 应用Dropout
x = self.dropout1(x)
# 将多维张量展平为一维向量(64*12*12)
x = x.view(-1, 64 * 12 * 12)
# 第一个全连接层+ReLU激活
x = torch.relu(self.fc1(x))
# 应用Dropout
x = self.dropout2(x)
# 输出层,得到未归一化的预测分数
x = self.fc2(x)
return x2.2 图像的预处理
python
def preprocess_image(image_path):
"""预处理自定义图像,使其符合模型输入要求"""
# 打开图像并转换为灰度图(单通道)
image = Image.open(image_path).convert('L')
# 调整图像大小为28x28像素(如果不是)
if image.size != (28, 28):
image = image.resize((28, 28), Image.Resampling.LANCZOS)
# 将PIL图像转换为numpy数组以便处理
img_array = np.array(image)
# 预处理:二值化和颜色反转
# MNIST数据集中数字为白色(255),背景为黑色(0)
if img_array.mean() > 127: # 如果平均像素值大于127,说明可能是黑底白字
img_array = 255 - img_array # 颜色反转
# 将numpy数组转换为PyTorch张量并添加批次维度
img_tensor = transforms.ToTensor()(img_array).unsqueeze(0)
# 使用MNIST数据集的均值和标准差进行归一化
img_tensor = transforms.Normalize((0.1307,), (0.3081,))(img_tensor)
return image, img_tensor # 返回原始图像和处理后的张量2.3 预测
python
def predict_digit(image_path):
"""预测自定义图像中的数字"""
# 创建模型实例
model = CNN()
# 加载预训练模型权重
model.load_state_dict(torch.load('mnist_cnn_model.pth'))
# 设置模型为评估模式(关闭Dropout等训练特有的层)
model.eval()
# 预处理输入图像
original_img, img_tensor = preprocess_image(image_path)
# 预测过程,不计算梯度以提高效率
with torch.no_grad():
# 前向传播,得到模型输出
output = model(img_tensor)
# 应用softmax将输出转换为概率分布
probabilities = torch.softmax(output, dim=1)
# 获取最高概率及其对应的数字类别
confidence, predicted = torch.max(probabilities, 1)三,测试
3.1 测试方法
如上文代码所示,我这里用的测试图片是自己定义图片,使用电脑自带的paint绘图软件,设置画布为28*28像素,黑底白字,手动写入一个字进行预测
3.2 测试结果

预测5的置信度为99.94%

预测0的置信度为99.99%
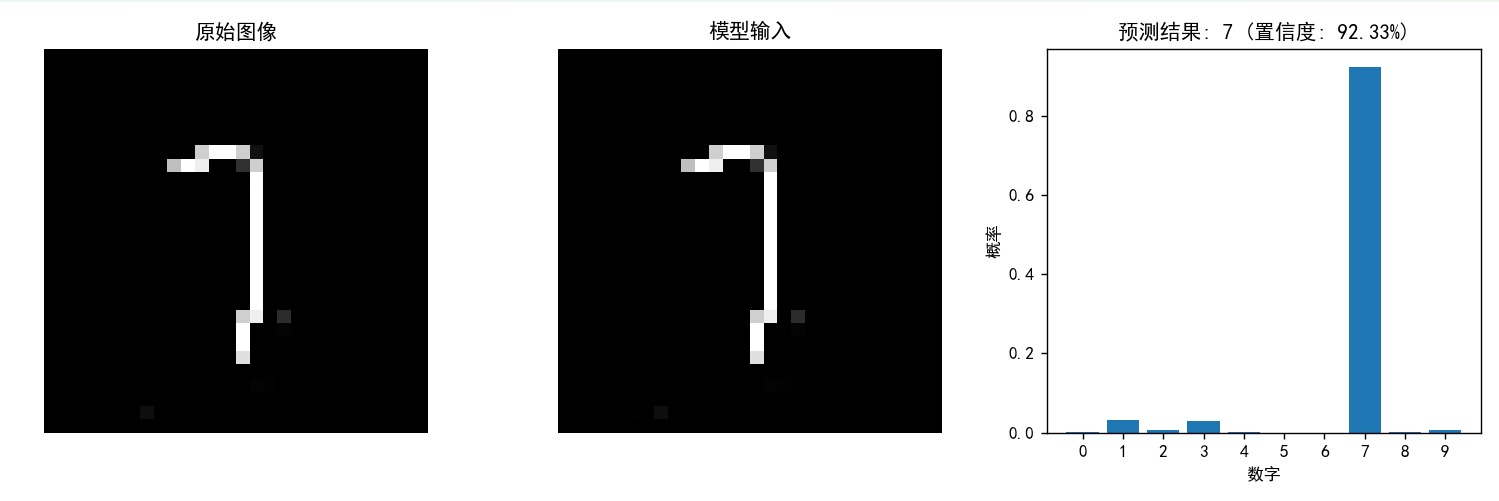
预测7的置信度为92.33%(尽管这个"7"写的很不好但是并不影响预测结果)
四 ,总结
卷积神经网络(CNN)在图像分类中相比全连接网络(FNN)具有显著优势:通过局部连接 和权重共享机制,CNN 大幅减少参数量,避免全连接网络因输入维度高导致的参数爆炸问题,计算效率更高且不易过拟合;CNN 通过卷积核逐层提取图像的局部特征(如边缘、纹理),结合池化层的平移不变性,能自动学习从低级到高级的层级化语义特征,而全连接网络将图像展平为向量,完全忽略像素空间关系,需依赖人工特征或大量数据学习;此外,CNN 的卷积结构天然具备正则化效果,对数据量需求更低,训练速度更快,且通过可视化卷积核和特征图可直观解释其对图像模式的捕捉过程,而全连接网络的特征表示缺乏可解释性。
五,完整代码
5.1 模型训练部分代码
python
import torch # 导入PyTorch库,用于深度学习
import torch.nn as nn # 导入PyTorch的神经网络模块
import torch.optim as optim # 导入PyTorch的优化器模块
from torchvision import datasets, transforms # 从torchvision导入数据集和数据变换模块
from torch.utils.data import DataLoader # 导入数据加载器模块
# 定义CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__() # 调用父类的初始化方法
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 定义第一个卷积层,输入通道1,输出通道32,卷积核大小3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 定义第二个卷积层,输入通道32,输出通道64,卷积核大小3x3
self.pool = nn.MaxPool2d(2, 2) # 定义最大池化层,池化核大小2x2
self.dropout1 = nn.Dropout2d(0.25) # 定义第一个Dropout层,随机丢弃25%的神经元
self.fc1 = nn.Linear(64 * 12 * 12, 128) # 定义第一个全连接层,输入维度64*12*12,输出维度128
self.dropout2 = nn.Dropout(0.5) # 定义第二个Dropout层,随机丢弃50%的神经元
self.fc2 = nn.Linear(128, 10) # 定义输出层,输入维度128,输出维度10(对应10个数字类别)
def forward(self, x):
x = torch.relu(self.conv1(x)) # 对第一个卷积层的输出应用ReLU激活函数
x = self.pool(torch.relu(self.conv2(x))) # 对第二个卷积层的输出应用ReLU激活函数,然后进行最大池化
x = self.dropout1(x) # 应用第一个Dropout层
x = x.view(-1, 64 * 12 * 12) # 将张量展平为一维向量,-1表示自动推断批次维度
x = torch.relu(self.fc1(x)) # 对第一个全连接层的输出应用ReLU激活函数
x = self.dropout2(x) # 应用第二个Dropout层
x = self.fc2(x) # 通过输出层
return x # 返回模型的输出
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize((0.1307,), (0.3081,)) # 使用MNIST数据集的均值和标准差进行归一化
])
# 加载数据
train_dataset = datasets.MNIST('data', train=True, download=True, transform=transform) # 加载MNIST训练数据集
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) # 创建数据加载器,批次大小为64,打乱数据
# 初始化模型、损失函数和优化器
model = CNN() # 创建CNN模型实例
criterion = nn.CrossEntropyLoss() # 定义交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # 定义Adam优化器,学习率为0.001
# 训练模型
def train(epochs):
model.train() # 设置模型为训练模式
for epoch in range(epochs): # 进行指定轮数的训练
running_loss = 0.0 # 初始化本轮的损失累加器
for batch_idx, (data, target) in enumerate(train_loader): # 遍历数据加载器中的每个批次
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播,计算模型输出
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
running_loss += loss.item() # 累加当前批次的损失
if batch_idx % 100 == 0: # 每100个批次打印一次损失
print(f'Epoch {epoch + 1}, Batch {batch_idx}, Loss: {loss.item():.6f}')
print(f'Epoch {epoch + 1} completed, Average Loss: {running_loss / len(train_loader):.6f}') # 打印本轮平均损失
# 执行训练并保存模型
if __name__ == '__main__':
train(epochs=5) # 调用训练函数,训练5轮
torch.save(model.state_dict(),'mnist_cnn_model.pth') # 保存模型的参数
print("模型已保存为: mnist_cnn_model.pth") # 打印保存模型的信息5.2 模型测试部分代码
python
# 导入PyTorch深度学习框架及其神经网络模块
import torch
import torch.nn as nn
# 导入torchvision的图像变换工具
from torchvision import transforms
# 导入PIL库用于图像处理
from PIL import Image
# 导入matplotlib用于可视化
import matplotlib.pyplot as plt
# 导入numpy用于数值计算
import numpy as np
# 导入os模块用于文件和路径操作
import os
# 设置matplotlib的字体,确保中文正常显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'WenQuanYi Micro Hei', 'Heiti TC']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 定义与训练时相同的CNN模型架构
class CNN(nn.Module):
def __init__(self):
# 调用父类初始化方法
super(CNN, self).__init__()
# 第一个卷积层:输入1通道(灰度图),输出32通道,卷积核3x3
self.conv1 = nn.Conv2d(1, 32, kernel_size=3)
# 第二个卷积层:输入32通道,输出64通道,卷积核3x3
self.conv2 = nn.Conv2d(32, 64, kernel_size=3)
# 最大池化层:核大小2x2,步长2
self.pool = nn.MaxPool2d(2, 2)
# Dropout层:训练时随机丢弃25%的神经元,防止过拟合
self.dropout1 = nn.Dropout2d(0.25)
# 第一个全连接层:输入维度64*12*12,输出128
self.fc1 = nn.Linear(64 * 12 * 12, 128)
# Dropout层:训练时随机丢弃50%的神经元
self.dropout2 = nn.Dropout(0.5)
# 输出层:输入128,输出10个类别(对应0-9数字)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 第一层卷积+ReLU激活
x = torch.relu(self.conv1(x))
# 第二层卷积+ReLU激活+池化
x = self.pool(torch.relu(self.conv2(x)))
# 应用Dropout
x = self.dropout1(x)
# 将多维张量展平为一维向量(64*12*12)
x = x.view(-1, 64 * 12 * 12)
# 第一个全连接层+ReLU激活
x = torch.relu(self.fc1(x))
# 应用Dropout
x = self.dropout2(x)
# 输出层,得到未归一化的预测分数
x = self.fc2(x)
return x
def preprocess_image(image_path):
"""预处理自定义图像,使其符合模型输入要求"""
# 打开图像并转换为灰度图(单通道)
image = Image.open(image_path).convert('L')
# 调整图像大小为28x28像素(如果不是)
if image.size != (28, 28):
image = image.resize((28, 28), Image.Resampling.LANCZOS)
# 将PIL图像转换为numpy数组以便处理
img_array = np.array(image)
# 预处理:二值化和颜色反转
# MNIST数据集中数字为白色(255),背景为黑色(0)
if img_array.mean() > 127: # 如果平均像素值大于127,说明可能是黑底白字
img_array = 255 - img_array # 颜色反转
# 将numpy数组转换为PyTorch张量并添加批次维度
img_tensor = transforms.ToTensor()(img_array).unsqueeze(0)
# 使用MNIST数据集的均值和标准差进行归一化
img_tensor = transforms.Normalize((0.1307,), (0.3081,))(img_tensor)
return image, img_tensor # 返回原始图像和处理后的张量
def predict_digit(image_path):
"""预测自定义图像中的数字"""
# 创建模型实例
model = CNN()
# 加载预训练模型权重
model.load_state_dict(torch.load('mnist_cnn_model.pth'))
# 设置模型为评估模式(关闭Dropout等训练特有的层)
model.eval()
# 预处理输入图像
original_img, img_tensor = preprocess_image(image_path)
# 预测过程,不计算梯度以提高效率
with torch.no_grad():
# 前向传播,得到模型输出
output = model(img_tensor)
# 应用softmax将输出转换为概率分布
probabilities = torch.softmax(output, dim=1)
# 获取最高概率及其对应的数字类别
confidence, predicted = torch.max(probabilities, 1)
# 创建可视化窗口
plt.figure(figsize=(12, 4))
# 子图1:显示原始输入图像
plt.subplot(1, 3, 1)
plt.imshow(original_img, cmap='gray')
plt.title('原始图像')
plt.axis('off') # 关闭坐标轴显示
# 子图2:显示模型实际输入(归一化后的图像)
plt.subplot(1, 3, 2)
plt.imshow(img_tensor[0][0], cmap='gray')
plt.title('模型输入')
plt.axis('off')
# 子图3:显示预测结果和置信度条形图
plt.subplot(1, 3, 3)
plt.bar(range(10), probabilities[0].numpy())
plt.xticks(range(10)) # 设置x轴刻度为0-9
plt.title(f'预测结果: {predicted.item()} (置信度: {confidence.item() * 100:.2f}%)')
plt.xlabel('数字')
plt.ylabel('概率')
# 自动调整子图布局
plt.tight_layout()
# 显示图像
plt.show()
# 返回预测结果和置信度
return predicted.item(), confidence.item() * 100
if __name__ == '__main__':
# 指定要测试的图像路径,请替换为实际路径
image_path = r"C:\Users\10532\Desktop\Study\test\Untitled.png"
# 检查文件是否存在
if not os.path.exists(image_path):
print(f"错误:文件 '{image_path}' 不存在")
else:
# 执行预测
digit, confidence = predict_digit(image_path)
print(f"预测结果: {digit},置信度: {confidence:.2f}%")