《DriveGenVLM: Real-world Video Generation for Vision Language Model based Autonomous Driving》 2024年8月发表,来自哥伦比亚大学的论文。
自动驾驶技术的进步需要越来越复杂的方法来理解和预测现实世界的场景。视觉语言模型(VLM)正在成为革命性的工具,具有影响自动驾驶的巨大潜力。本文提出了DriveGenVLM框架来生成驾驶视频,并使用VLM来理解它们。为了实现这一目标,我们采用了一种基于去噪扩散概率模型(DDPM)的视频生成框架,旨在预测真实世界的视频序列。然后,我们通过使用一种称为"自我中心视频高效情境学习"(EILEV)的预训练模型,探索我们生成的视频在VLM中使用的充分性。扩散模型使用Waymo开放数据集进行训练,并使用Frechet Video'Distance(FVD)评分进行评估,以确保生成视频的质量和真实性。EILEV为这些生成的视频提供了相应的叙述,这在自动驾驶领域可能是有益的。这些叙述可以增强对交通场景的理解,有助于导航,提高规划能力。DriveGenVLM框架中视频生成与VLM的集成代表了利用先进的人工智能模型解决自动驾驶复杂挑战的重要一步。
1. 研究背景与目标
自动驾驶技术需要动态环境理解和预测能力,传统视频生成模型(如GANs、VAEs)在长视频生成中存在连贯性不足的问题。本文提出 DriveGenVLM 框架,结合 去噪扩散概率模型(DDPM) 生成驾驶视频,并利用 视觉语言模型(VLMs) 验证视频的可解释性,以提升自动驾驶的场景理解、导航与规划能力。
2. 核心方法
-
视频生成模型(DDPM)
-
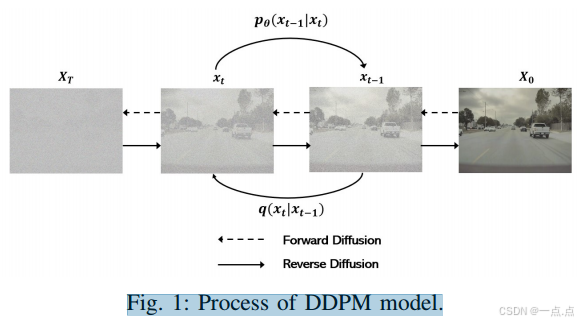
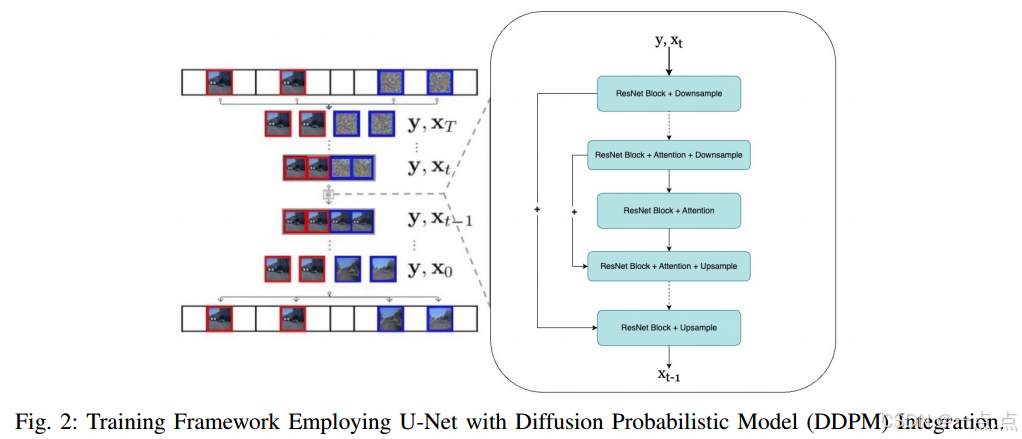
架构:基于U-Net的扩散模型,通过前向(加噪)和反向(去噪)过程生成视频。
-
条件扩展:通过条件输入(如初始帧)生成未来帧,支持长视频生成。
-
采样策略:
-
Autoreg:逐帧生成,依赖前序帧。
-
Hierarchy-2:分层采样,先粗粒度后细粒度。
-
Adaptive Hierarchy-2:动态调整条件帧,优化多样性(基于LPIPS距离)。
-
-
-
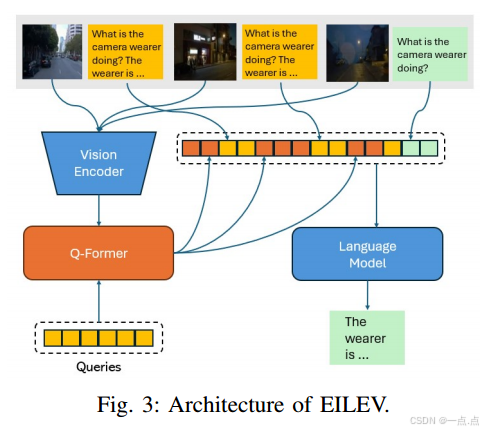
视觉语言模型(EILEV)
-
基于BLIP-2的预训练模型,通过上下文学习生成视频的文字描述。
-
验证生成视频的可解释性,例如识别场景(高速公路、夜间驾驶)和关键事件(行人、车辆)。
-
3. 实验与结果
-
数据集:Waymo开放数据集(包含多摄像头视角的驾驶视频,分辨率128×128)。
-
评估指标:
- FVD(Frechet Video Distance):衡量生成视频与真实视频的分布相似性,数值越低质量越高。
-
关键结果:
-
Adaptive Hierarchy-2采样策略在三个摄像头视角(Front、Front-left、Front-right)中均取得最低FVD分数(如Front Camera: 1174.56)。
-
EILEV模型成功为生成视频生成准确文字描述(如"车辆在夜间行驶"),验证其可解释性。
-
4. 贡献与创新
-
首次将DDPM应用于驾驶视频生成,解决传统模型在长视频生成中的连贯性问题。
-
提出自适应采样策略(Adaptive Hierarchy-2),显著提升生成视频的多样性与质量。
-
集成VLMs(EILEV)验证生成视频的实用性,为自动驾驶提供可解释的场景描述。
5. 局限性与未来方向
-
局限性:
-
复杂交通场景(如行人动态、多车交互)的细节捕捉不足。
-
生成视频分辨率较低(128×128),可能影响实际部署效果。
-
-
未来方向:
-
优化模型以处理更高分辨率视频。
-
结合强化学习,将生成视频直接应用于自动驾驶决策系统。
-
6. 实际意义
DriveGenVLM框架为自动驾驶提供了一种新的数据增强和场景模拟工具:
-
训练数据扩展:生成多样化驾驶场景,缓解真实数据不足问题。
-
安全测试:模拟极端场景(如恶劣天气、突发事故),测试系统鲁棒性。
-
人机交互:通过VLMs生成自然语言指令,增强用户对自动驾驶决策的理解。
总结
本文通过DDPM与VLMs的结合,提出了一种创新的驾驶视频生成与验证框架,实验表明其在视频质量和可解释性上的优势。尽管存在对复杂场景建模的挑战,DriveGenVLM为自动驾驶的动态环境理解和决策优化提供了重要技术支撑。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!