Finetuning method参数
- full(全量微调)
- 更新模型全部参数,完全适配新任务
- 效果最好,但资源消耗最大
- 适用于计算资源充足的场景
- 存在过拟合的风险,需要大量数据支持
- 更新模型全部参数,完全适配新任务
- freeze(冻结微调)
- 固定底层参数,仅微调高层或分类头
- 显存需求最低,训练速度最快
- 保留预训练通用特征,灵活性较低
- 适合迁移学习场景
- 固定底层参数,仅微调高层或分类头
- lora(低秩微调)
- 通过低秩矩阵分解注入可训练参数
- 参数效率高,显存占用仅为全量微调的1/10
- 训练速度比全量微调快25%
- 效果接近全量微调,无推理延迟
- 支持多任务共享基础模型
- 通过低秩矩阵分解注入可训练参数
选型建议:资源受限优先选择lora,需要最高精度且资源充足用ful,快速适配相似领域用freeze。
| 💡 如图所示,页面中还有RLHF、GaLore、APOLLO、BAdam、SwanLab这些和上面三者有什么关联、区别呢?

上面说的full、freeze、lora属于参数更新策略 ,决定微调哪些参数。
其他的是在参数更新策略上优化的工具:
| RLHF | 对齐方法 | 通过人类反馈优化模型输出质量 |
|---|---|---|
| GaLore | 梯度优化算法 | 低秩投影降低梯度计算内存消耗 |
| BAdam/APOLLO | 二阶优化器 | 改进Adam的预训练适应性 |
| SwanLab | 实验管理工具 | 记录训练过程指标对比 |
两者属于协同关系,比如:
- GaLore可与Full-tuning结合实现内存优化(需禁用LoRA)
- RLHF通常在SFT(含LoRA/Freeze)后作为对齐阶段使用
- BAdam/APOLLO可作为Full-tuning的优化器替代品
Full/Freeze/LoRA GaLore/BAdam RLHF 微调方法 参数更新 优化技术 训练加速 对齐方法 输出优化 模型输出
Stage参数
| 💡llama-factory中Stage(The stage to perform in training.)包含的参数值有:Supervised Fine-Tuning、Reward Modeling、PPO、DPO、KTO、Pre-Training
核心训练阶段
- Supervised Fine-Tuning(SFT)
- 使用标注数据微调模型,适配下游任务
- 兼容freeze/lora/ful微调方法
- Pre-Training
- 增量预训练阶段,扩展模型知识
- 通常采用full微调方法更新全部参数
对齐优化阶段
-
reward modeling ,训练奖励模型用于RLHF ,需要独立训练不依赖微调方法
-
PPO ,策略梯度强化学习优化输出 ,需要与SFT阶段微调方法解偶
-
DPO/KTO ,直接偏好优化替代RLHF ,可以结合lora微调
-
关系图
预训练阶段
监督微调
对齐优化
Full-tuning Freeze/LoRA 独立训练 Pre-Training SFT DPO/KTO Reward Model PPO
参数解释
基本配置
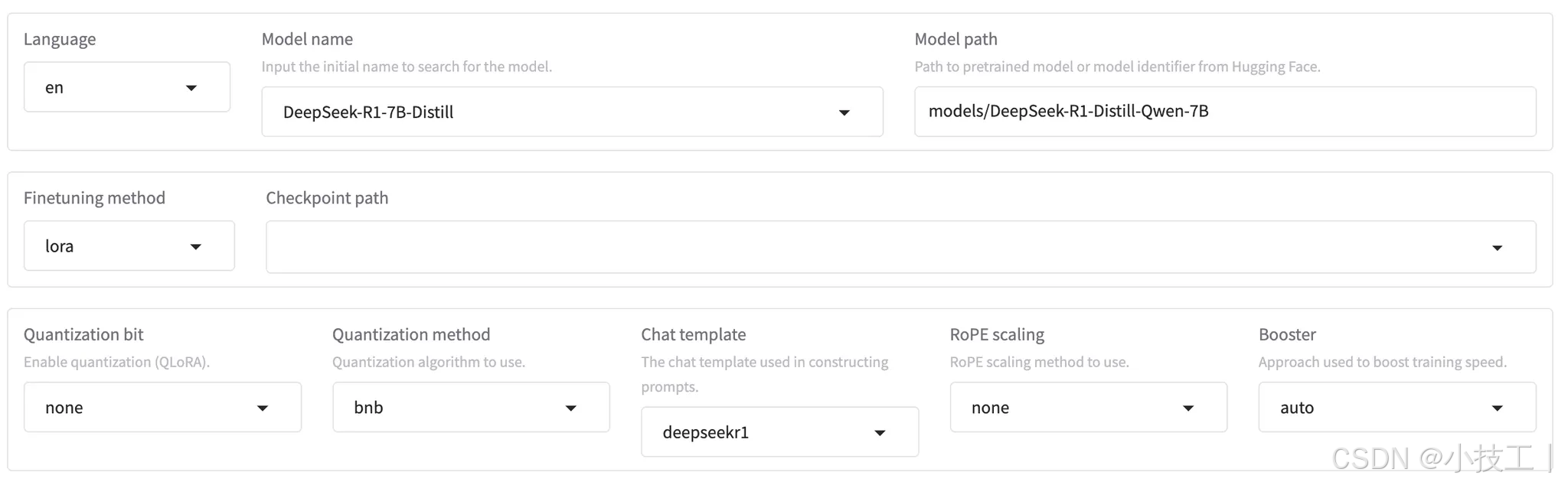
-
Language
- 选择
zh页面则是全中文,en则是英文
- 选择
-
Model Name
- 模型名称
-
Model path
- 本地模型的文件路径或 Hugging Face 的模型标识符。会从HF上下载,存在网络问题。
-
Finetuning method
- 微调方法:
lora、freeze、fulllora:通过低秩适配器(Low-Rank Adaptation)微调,仅训练少量参数,适合资源有限场景。freeze:冻结大部分层,仅微调特定层(如分类头),速度最快但灵活性低。full:全参数微调,更新所有模型参数,效果最佳但显存消耗大。
- 建议:优先用
lora节省资源,效果接近full全参数微调;显存充足时可选full。
- 微调方法:
-
Checkpoint Path
- 指定预训练模型或者已有的微调权重的路径
-
Quantization Bit
- 模型权重量化位数,降低显存占用:
none、8、4none:不启用量化,保留原始精度(fp16、bf16)8、4:8位、4位量化,大幅减少显存,但效果相较原始精度略低。
- 建议:显存不足时选
4,需要配合量化方法(Quantization Method)
- 模型权重量化位数,降低显存占用:
-
Quantization Method
- 量化具体实现库:
bnb、hqq、eetqbnb:BitsAndBytes最常用的量化库,支持8、4 bit量化,兼容性好,适用于需要压缩和加速大规模模型的场景hqq:Half-Quadratic Quantization是一种半二次量化方法,通过二次函数逼近量化误差,提升量化精度,适用于对精度要求较高的低比特量化场景(高效量化,适合低精度推理)eetq:Efficient and Effective Ternary Quantization是一种高效的三值量化方法,将权重和激活值量化为-1、0、1三个值,适用于需要极致压缩和加速的场景,尤其是硬件资源受限的环境。
- 建议:训练时用
bnb,推理可尝试hqq或eetq
- 量化具体实现库:
-
Chat Template
- 构建提示词时使用的模板,根据模型来选择,要和模型预训练格式对齐。
-
RoPE Scaling
- RoPE (Rotary Position Embeddings)scaling,扩展模型上下文长度的RoPE(旋转位置嵌入)策略,以提高模型处理更长序列的能力:
none、linear、dynamic、yarn、llama3linear:线性插值,简单扩展但长文本效果可能不稳定dynamic:动态调整插值系数,平衡长短文本性能yarn:结合插值和微调,稳定扩展至更长上下文llama3:MetaAI官方扩展方法,适配Llama3的长上下文需求
- 建议:长文本任务优先选
dynamic、yarn
- RoPE (Rotary Position Embeddings)scaling,扩展模型上下文长度的RoPE(旋转位置嵌入)策略,以提高模型处理更长序列的能力:
-
Booster
- 加速训练的技术选项:
auto、flashattn2、unsloth、liger_kernel flashattn2:优化注意力计算,显著提速且省显存unsloth:轻量化训练框架,减少冗余计算liger_kernel:定制化GPU内核,针对特定硬件加速
- 加速训练的技术选项:
-
建议:默认
auto选择,显存不足时优先选flashattn2
训练配置(train)
- Stage
Pre-training、SFT、Reward Modeling、PPO、DPO、KTOSFT(监督微调):基础任务,用标注数据微调模型。PPO(策略优化):强化学习阶段,优化生成策略。DPO/KTO:直接偏好优化,用人类偏好数据对齐模型输出。
- 建议:从
SFT开始,再根据任务需求进入强化学习或偏好优化阶段。
- Learning Rate
- 学习率,控制参数更新步长
- full建议1e-5~5e-5,lora可以设置更高1e-4,因为参数更新量小。
- Epochs
- 训练轮次,SFT任务通常3-10轮足够,(偏好优化)DPO、PPO任务1-3轮即可。
- Maximum Gradient Norm
- 最大梯度裁剪范数,默认1.0,如果训练不稳定(如:loss突增),可以降低至0.5
- Max Samples
- 限制样本集样本数量,数量大时可以限制1w~10w
- Compute Type
- 是否使用混合精度训练:
bf16`fp16\fp32\pure_bf16` fp16`fp32`大多数硬件都支持、所以可以用混合精度训练提高吞吐。bf16只有新的硬件支持,v100/升腾910不支持pure_bf16强制精度位bf16
- 是否使用混合精度训练:
- Cutoff Length
- 用于控制输入文本的截断长度:4096、8192 ...
- 内存管理、训练效率、避免过拟合、模型一致性
- Batch Size 、Gradient Accumulation
- 单步训练的数据量
batch size * gradient accumulation - 显存不足时,减少
batch size,增大gradient accumulation(梯度累计)
- 单步训练的数据量
- Val Size
- 验证集比例:0.1即数据集中10%的数据作为验证集,数据量大时可以设置0.001
- LR Scheduler
- 动态调整学习率:
cosine、linear、constant_with_warmuplinear:线性衰减cosine:余弦衰减,平滑衰减,适合长周期训练constant_with_warmup:带热身的恒定学习率,适合小数据集
- 动态调整学习率: