《DriveGPT4: Interpretable End-to-End Autonomous Driving via Large Language Model》
2024年10月发表,来自香港大学、浙江大学、华为和悉尼大学。
多模态大型语言模型(MLLM)已成为研究界关注的一个突出领域,因为它们擅长处理和推理非文本数据,包括图像和视频。本研究旨在通过引入DriveGPT4,将MLLM的应用扩展到自动驾驶领域,DriveGPT4是一种基于LLM的新型可解释端到端自动驾驶系统。DriveGPT4能够处理多帧视频输入和文本查询,便于解释车辆动作,提供相关推理,并有效解决用户提出的各种问题。此外,DriveGPT4以端到端的方式预测低级车辆控制信号。这些高级功能是通过利用专门为自动驾驶应用量身定制的定制视觉指令调优数据集,结合混合微调训练策略来实现的。DriveGPT4代表了利用LLM开发可解释的端到端自动驾驶解决方案的开创性努力。对BDD-X数据集进行的评估显示,DriveGPT4具有卓越的定性和定量性能。此外,与GPT4-V相比,对特定领域数据的微调使DriveGPT4在自动驾驶接地方面能够产生接近甚至改进的结果。
1. 研究背景与动机
-
问题提出:传统自动驾驶系统采用模块化设计(感知、规划、控制),但面对未知场景时易失效。端到端学习系统虽能直接预测控制信号,但因其"黑盒"特性缺乏可解释性,阻碍商业化应用。
-
现有不足:现有可解释性研究多基于小规模语言模型,回答模式僵化,难以应对多样化用户提问。
-
解决方案 :利用大语言模型(LLM)的强推理能力和多模态处理能力,提出DriveGPT4,实现可解释的端到端自动驾驶,同时生成自然语言解释和低层次控制信号。
2. 核心贡献
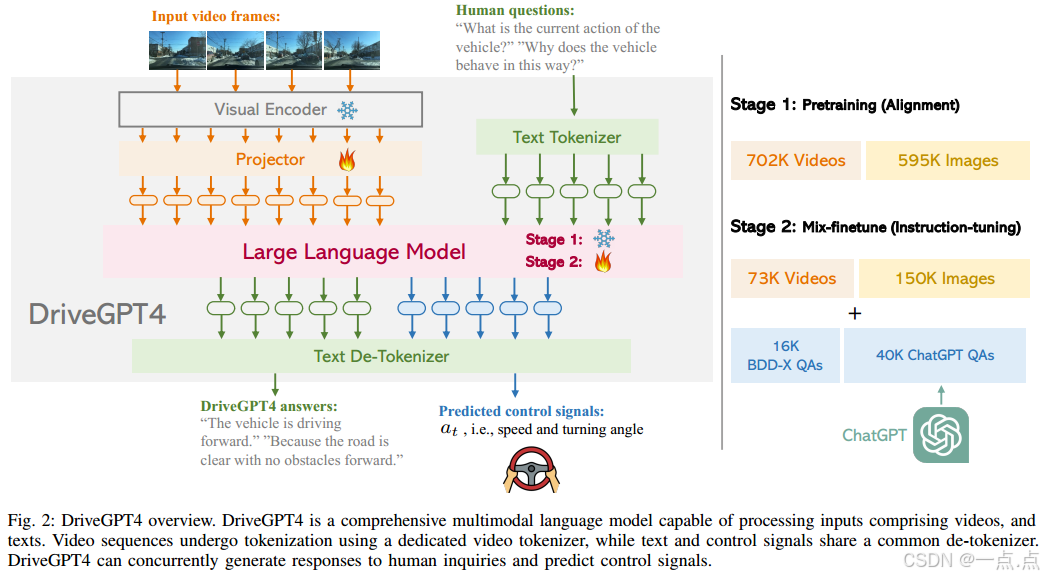
-
DriveGPT4模型:
-
多模态输入:支持视频(多帧图像)和文本输入,通过专用视频tokenizer将视频帧映射为文本域特征。
-
双输出能力:生成自然语言回答(动作描述、理由等)和低层次控制信号(速度、转向角)。
-
架构设计:基于LLaMA2,结合CLIP视觉编码器提取时空特征,控制信号与文本共享解tokenizer(类似RT-2)。
-
-
数据集构建:

-
基于BDD-X数据集(20K样本),通过ChatGPT生成多样化问答对(56K样本),包括动作描述、理由、控制信号预测及灵活对话。
-
解决传统数据集固定格式问题,提升模型泛化能力。
-
-
混合微调策略:
-
预训练:通用图像和视频-文本对(CC3M + WebVid-2M),对齐多模态特征。
-
混合微调:结合56K自动驾驶领域数据(BDD-X + ChatGPT生成)和223K通用指令数据(LLaVA、Valley),增强视觉理解和领域适应能力。
-
3. 实验与结果
-
数据集与评测:
-
BDD-X测试集:划分为简单(Easy)、中等(Medium)、复杂(Hard)场景,评估动作描述、理由生成、控制信号预测。
-
指标:自然语言生成采用CIDEr、BLEU4、ROUGE-L;控制信号预测采用RMSE和阈值准确率(AτAτ)。
-
-
关键结果:
-
可解释性任务:DriveGPT4在动作描述(CIDEr 256.03 vs. ADAPT 227.93)和理由生成(CIDEr 98.71 vs. 80.00)上显著优于基线。
-
控制信号预测:速度预测RMSE 1.30(优于ADAPT的1.69),转向角RMSE 8.98(优于9.97)。
-
泛化能力:在NuScenes数据集和视频游戏中零样本测试成功,展示跨领域适应性。
-
对比GPT4-V:DriveGPT4在动态行为理解和控制信号预测上更具优势(GPT4-V无法预测数值控制信号)。
-
4. 技术亮点
-
视频处理:通过时空特征池化(Temporal & Spatial Pooling)高效编码多帧视频信息。
-
控制信号嵌入:将数值控制信号视为"语言",利用LLM的解码能力直接生成。
-
混合微调:结合领域数据与通用数据,缓解幻觉问题(如检测虚假车辆)。
5. 局限与未来方向
-
实时性:未支持长序列输入(如32帧视频),受限于计算资源与推理速度。
-
闭环控制:当前为开环预测,未来需结合强化学习实现闭环控制。
-
数据扩展:计划通过CARLA仿真生成更多指令数据,增强复杂场景下的推理能力。
6. 总结
DriveGPT4首次将大语言模型引入可解释端到端自动驾驶系统,通过多模态输入处理、混合微调策略和灵活的输出设计,实现了自然语言解释与控制信号预测的双重目标。实验表明其在复杂场景下的优越性能,为零样本泛化和实际应用奠定了基础。未来研究可进一步优化实时性、闭环控制及数据多样性。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!