- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
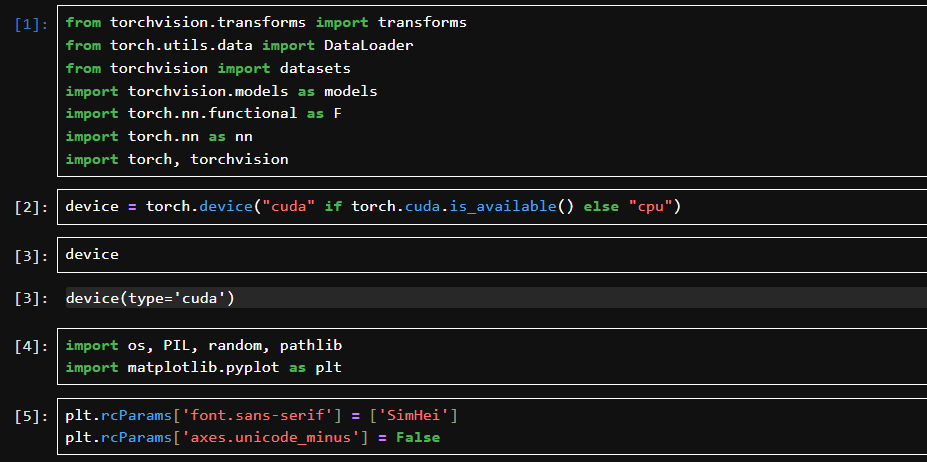
自动检测系统是否有可用的 GPU(CUDA),如果有就使用 GPU,否则使用 CPU。
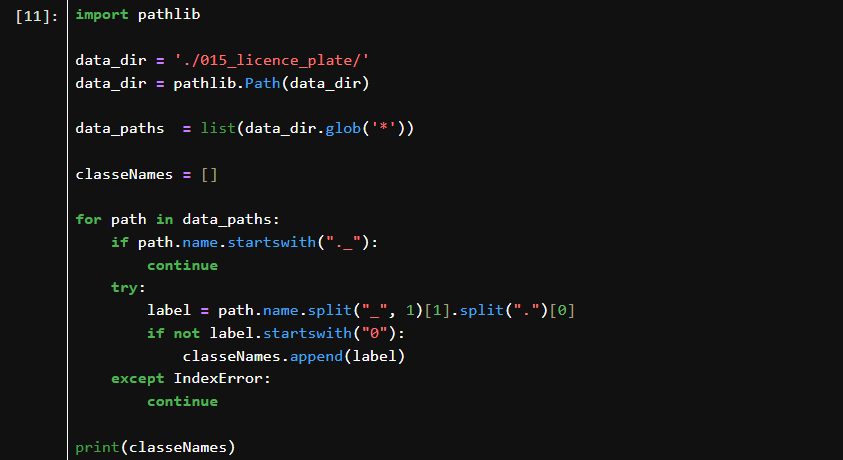
设定包含图像文件的目录,并将其转换为 Path 对象。
获取 data_dir 中所有文件(或文件夹),生成的是一个 Path 对象列表,储存在 data_paths 中。
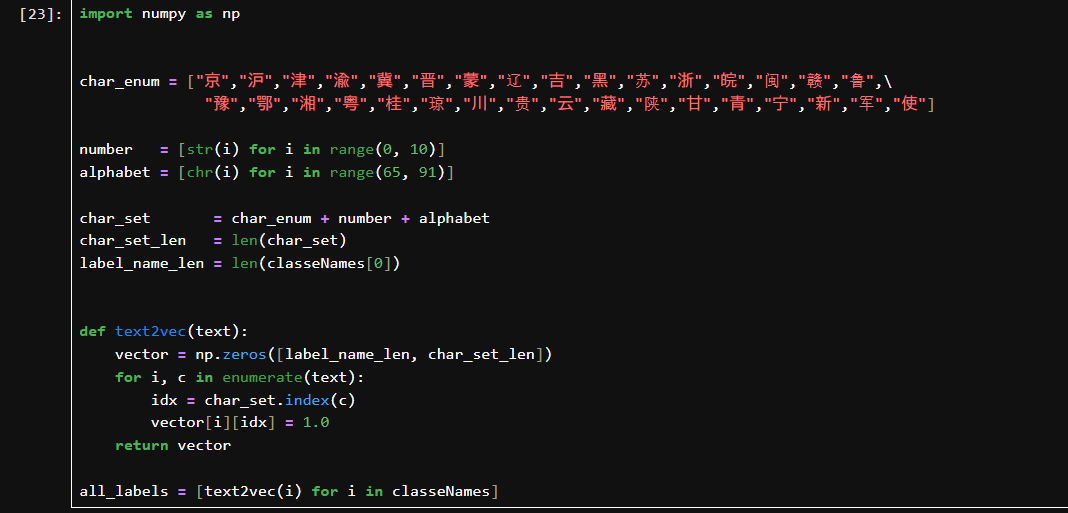
组成字符集合 char_set,用于车牌字符可能出现的全集。
char_set 是所有可能字符的集合。
char_set_len 是字符种类数量。
label_name_len 是每个 label 的字符数长度。
对每个字符进行 one-hot 编码,每行表示该位置上的字符。
对 classeNames 中所有车牌标签进行编码,得到 all_labels 列表。
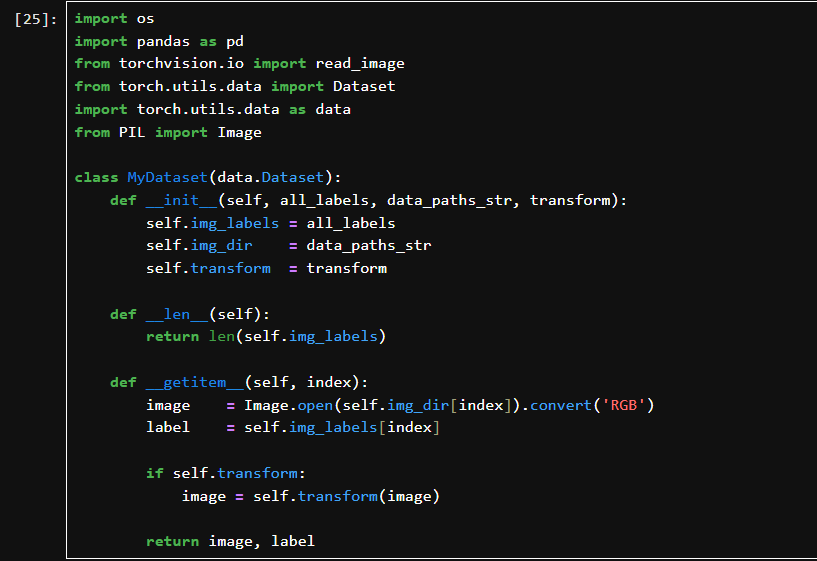
all_labels: 即上一段生成的标签列表。
data_paths_str: 图像路径列表(字符串路径)。
transform: 数据增强操作。根据索引读取图像并转为 RGB。
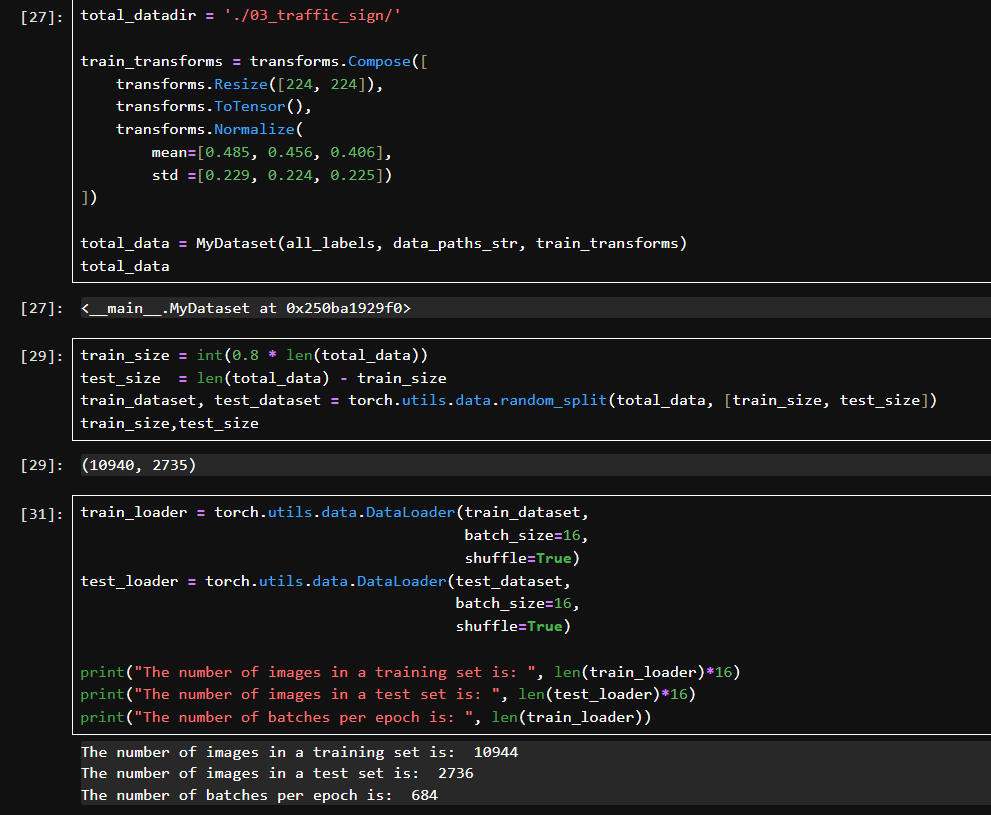
定义了数据增强管道 train_transforms:
Resize(224, 224): 调整图像大小为 ResNet 常用尺寸。
ToTensor(): 转为 PyTorch 的张量格式。
Normalize(...): 按照 ImageNet 的均值与标准差进行归一化处理。
按照 80% : 20% 的比例划分训练集和测试集。使用 random_split 确保划分是随机的。
使用 batch_size=16,对训练和测试集分别构造了 DataLoader。shuffle=True 代表每个 epoch 都会打乱数据顺序。
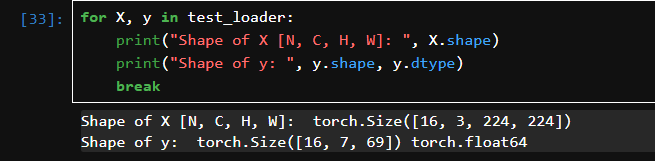
迭代 test_loader 中的一个 batch(图像 X 和标签 y)。
break:只取第一个 batch。
X.shape:输出图像张量的形状。
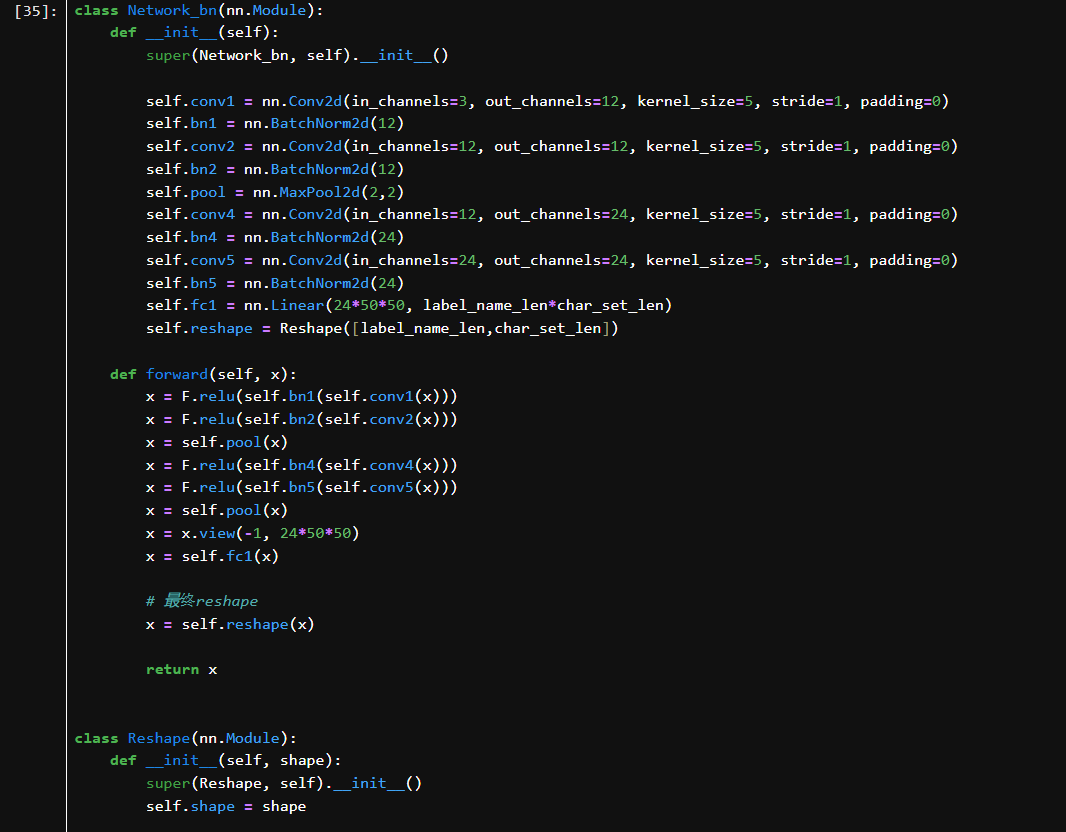
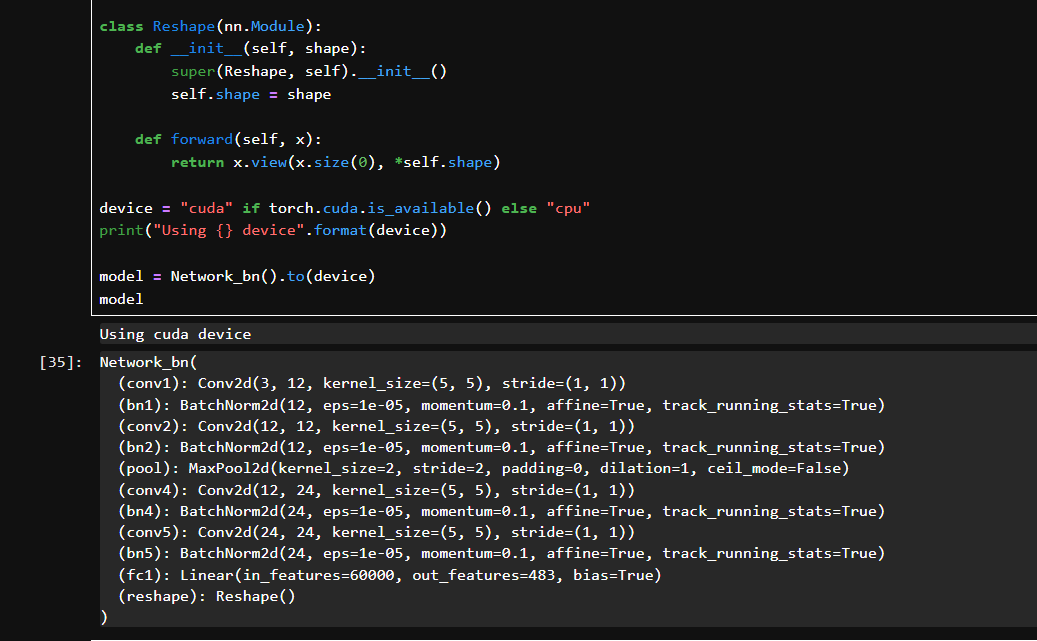
self.conv1 → conv5:5层卷积,每层带 BatchNorm
self.pool:2次 MaxPooling
self.fc1:全连接层,输出为 label_name_len * char_set_len
self.reshape:将扁平输出 reshape 为多字符 one-hot 格式
输入图像尺寸是 3×224×224
卷积层参数:kernel=5, stride=1, padding=0
MaxPool 参数:kernel=2, stride=2
最终扁平后尺寸是 24×50×50
用于将 batch_size, 483 reshape 为 batch_size, 7, 69,每张图预测7个字符,每个字符是69类分类问题。
训练时输出 shape 和标签一致(batch_size, 7, 69)
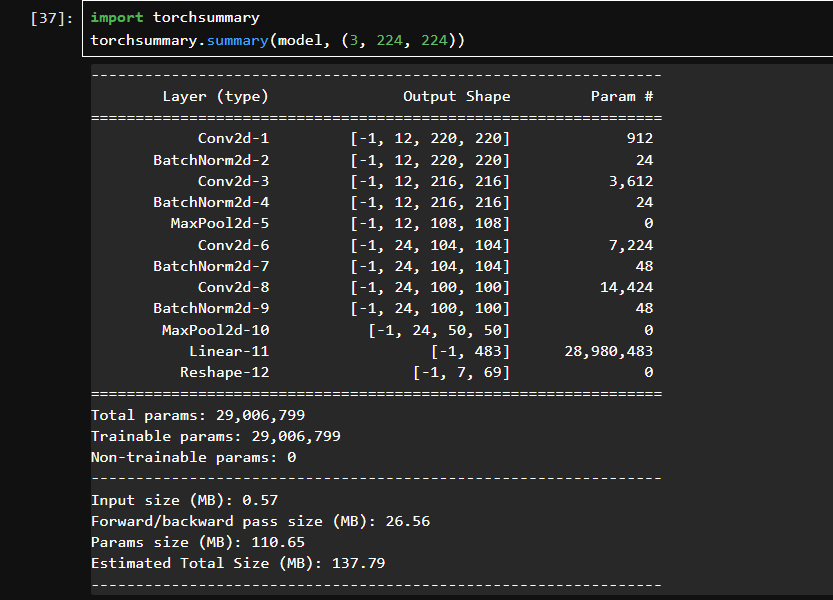
输入图像尺寸为 (3, 224, 224),使用 torchsummary 可视化每一层的输出 shape 和参数数目。
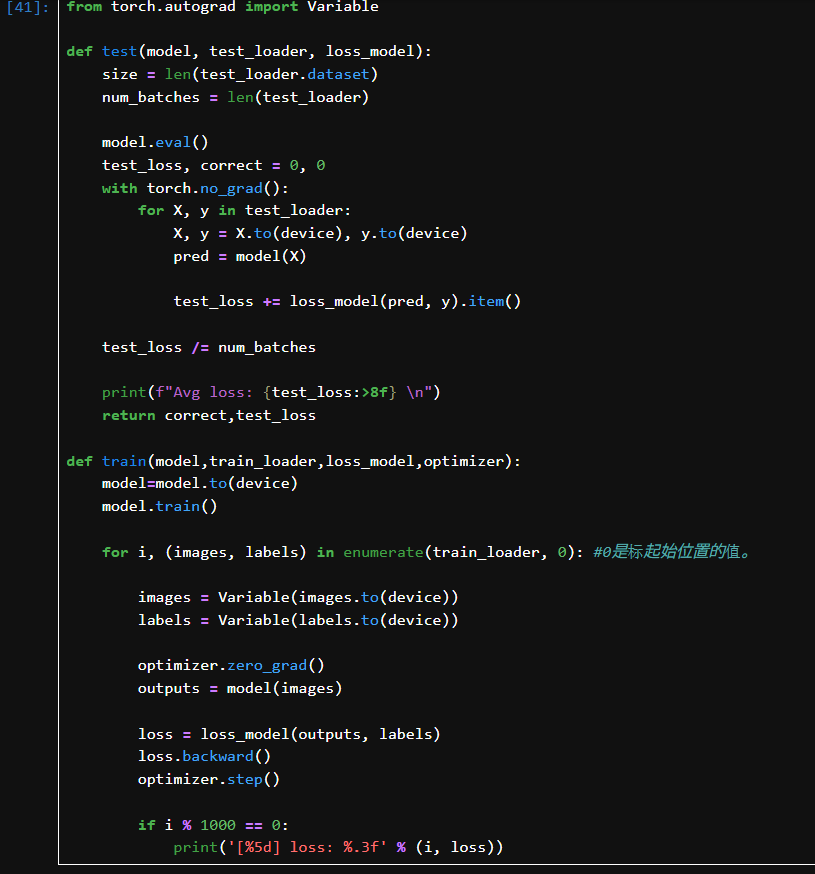
test():用于评估模型在测试集上的平均 loss。
model.eval():进入评估模式。
torch.no_grad():测试时不记录梯度,节省显存。
loss_model(pred, y):计算损失。
test_loss /= num_batches:输出平均损失。
train():训练一个 epoch。
model.train():切换到训练模式。
zero_grad():梯度清零
outputs = model(images):前向传播
loss.backward():反向传播
optimizer.step():更新权重
每1000步打印一次当前 loss。
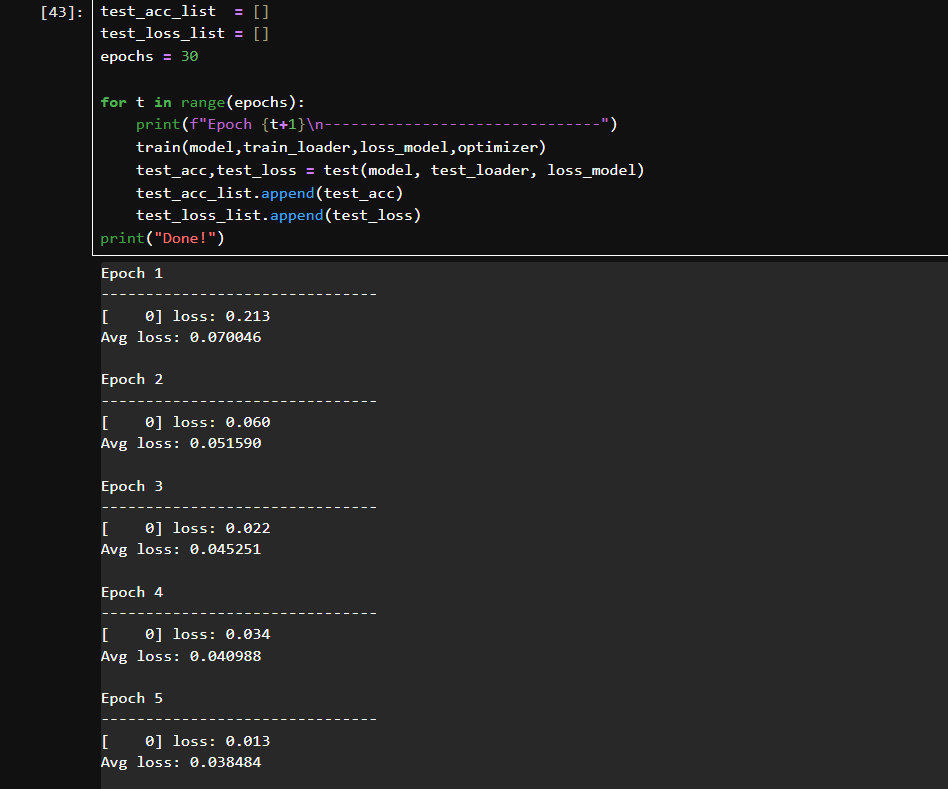
train():每个 epoch 执行一次训练。
test():每个 epoch 后评估模型。
test_acc_list:存储每轮的准确率。
test_loss_list:存储每轮的平均 loss。
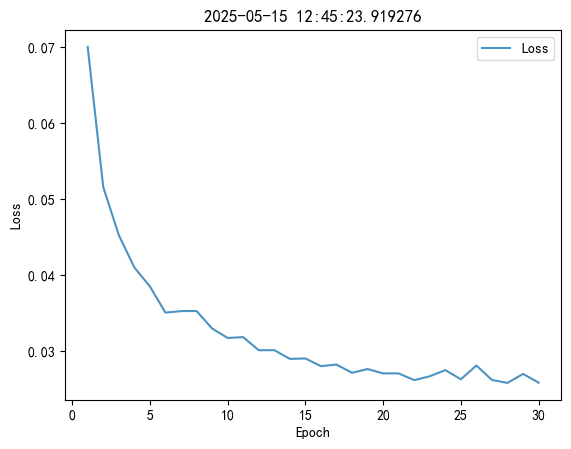
从 Epoch 1 到 Epoch 30,Loss 稳定下降,在 Epoch 20 之后趋于平稳,说明模型未过拟合。