今天我们来拆下切片的实现。
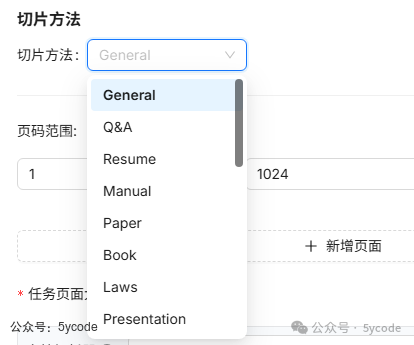
我们在设置的时候,可以选择切片方法。这个参数是parser_id
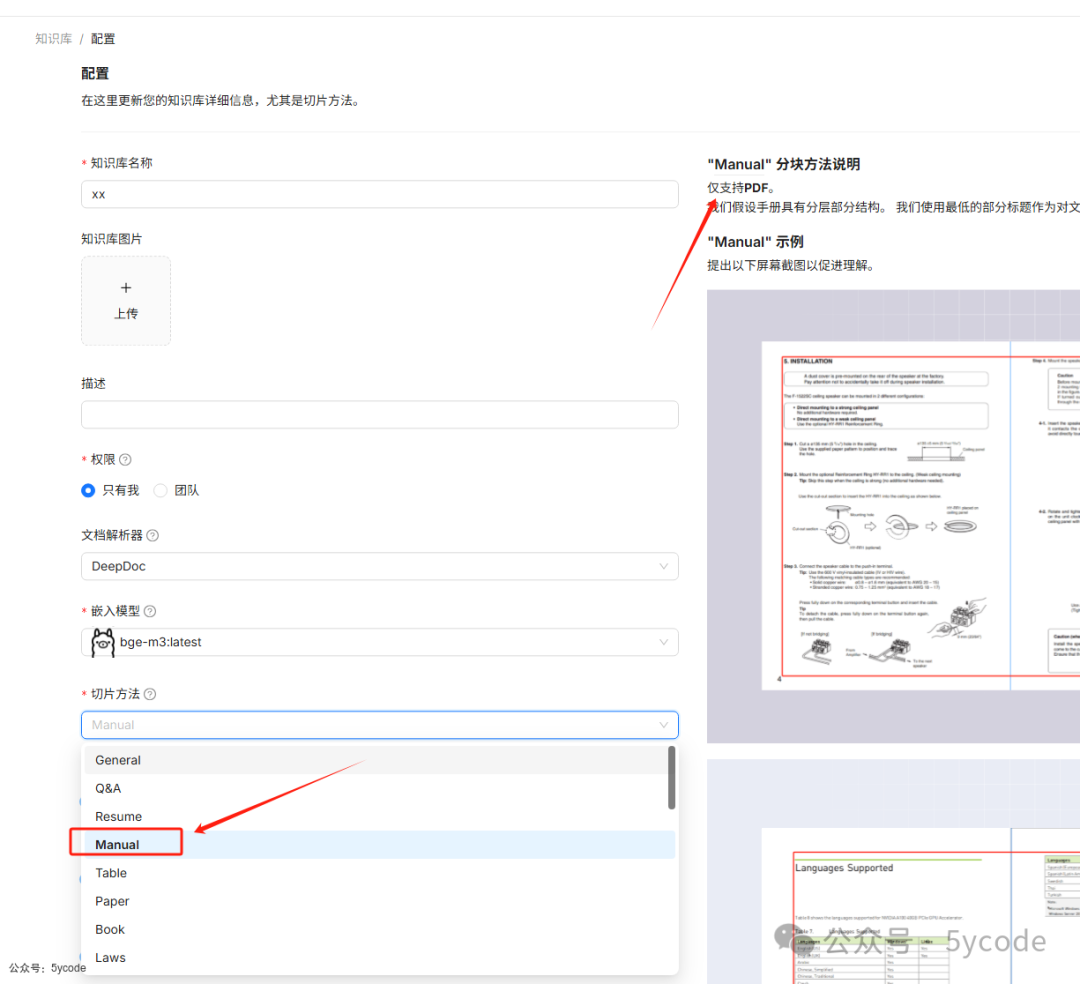
在创建知识库的时候,选择对应的切片方法以后,我们可以看到右侧的切片介绍。
async def build_chunks(task, progress_callback):
# 根据配置获取到切片实现(策略)
chunker = FACTORY[task["parser_id"].lower()]
async with chunk_limiter:
cks = await trio.to_thread.run_sync(lambda: chunker.chunk(task["name"], binary=binary, from_page=task["from_page"],
to_page=task["to_page"], lang=task["language"], callback=progress_callback,
kb_id=task["kb_id"], parser_config=task["parser_config"], tenant_id=task["tenant_id"]))-
• 在上面的代码里根据配置
parser_id从FACTORY中获取到对应的实现文件 -
• 注意
chunker.chunk调用对应实现文件中的chunk方法from rag.app import laws, paper, presentation, manual, qa, table, book, resume, picture, naive, one, audio, email, tag
策略注册(隐式接口)
FACTORY = {
"general": naive, # 基础文本处理器
ParserType.NAIVE.value: naive,
ParserType.PAPER.value: paper, # 学术论文处理器
ParserType.BOOK.value: book,
ParserType.PRESENTATION.value: presentation,
ParserType.MANUAL.value: manual,
ParserType.LAWS.value: laws,
ParserType.QA.value: qa,
ParserType.TABLE.value: table, # 表格专用处理器
ParserType.RESUME.value: resume,
ParserType.PICTURE.value: picture,
ParserType.ONE.value: one,
ParserType.AUDIO.value: audio,
ParserType.EMAIL.value: email,
ParserType.KG.value: naive,
ParserType.TAG.value: tag
} -
•
FACTORY对应的 实现,就是一个配置映射,根据前端的配置,然后映射到对应的方法 -
• 我们可以看到对应的是从
rag.app导入的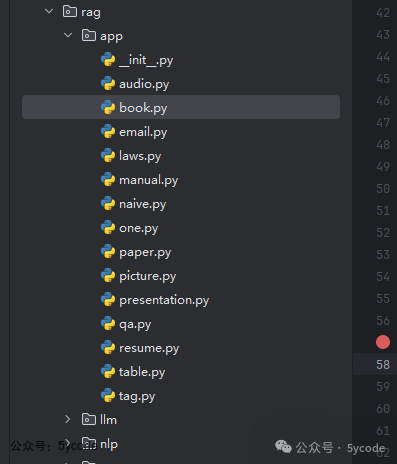
看下代码结构,都是对应的类文件。引入的类文件每个都有一个相同的
chunk方法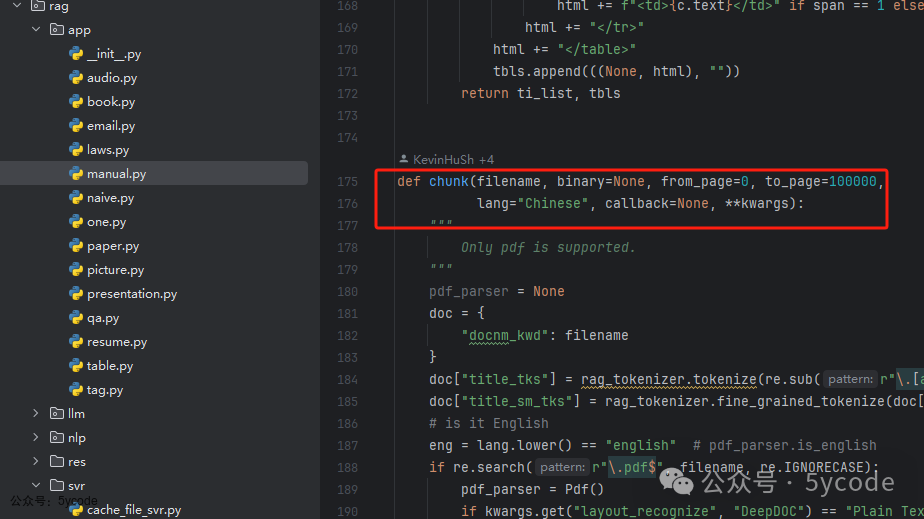
这块代码就是一个典型的策略模式实现。
这里要吐槽下python的隐式接口,不是自己写的代码,一不小心得来回翻几遍代码。等我过两天给它接口显式实现。
整块代码逻辑如下:
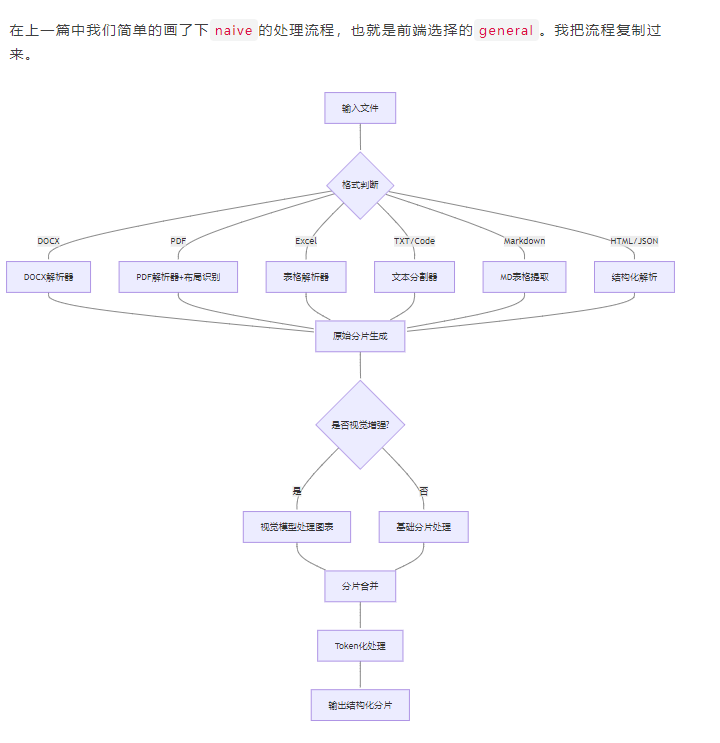
通用方法里,针对不同的文件类型,有对应的实现。
接下来,我们拆解几个定向的分片实现。
Manual
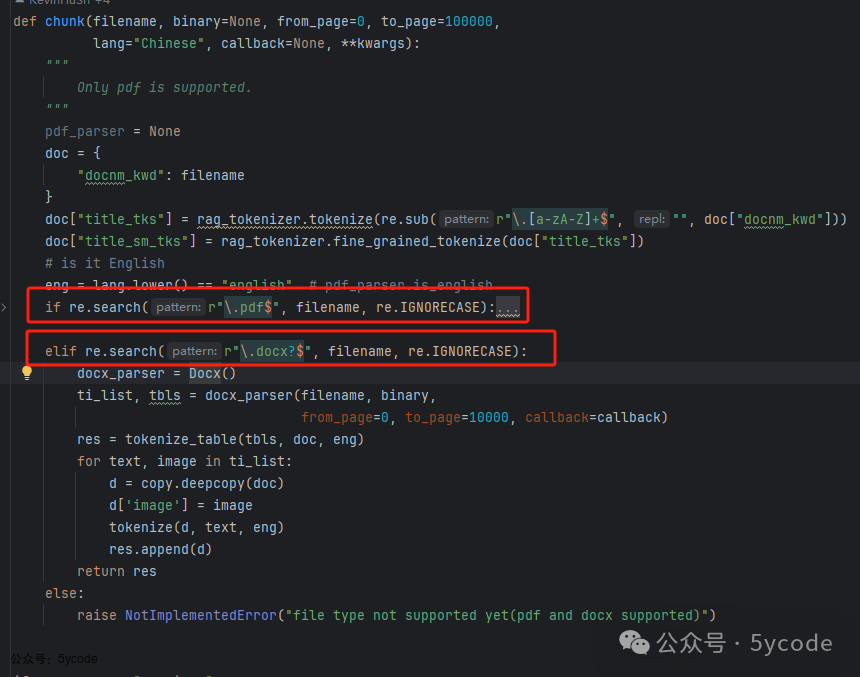
前端显示仅支持pdf,后端代码支持pdf和docx。这块代码的整体处理逻辑如下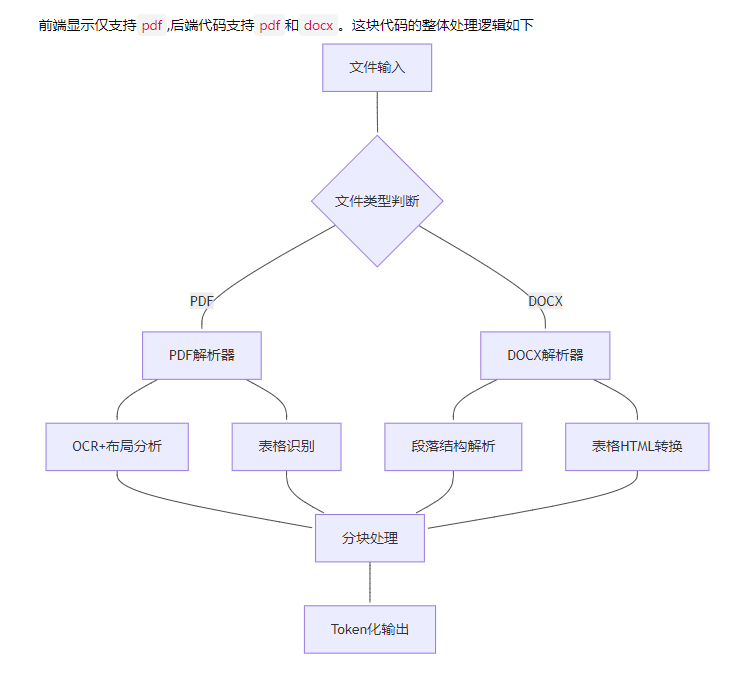
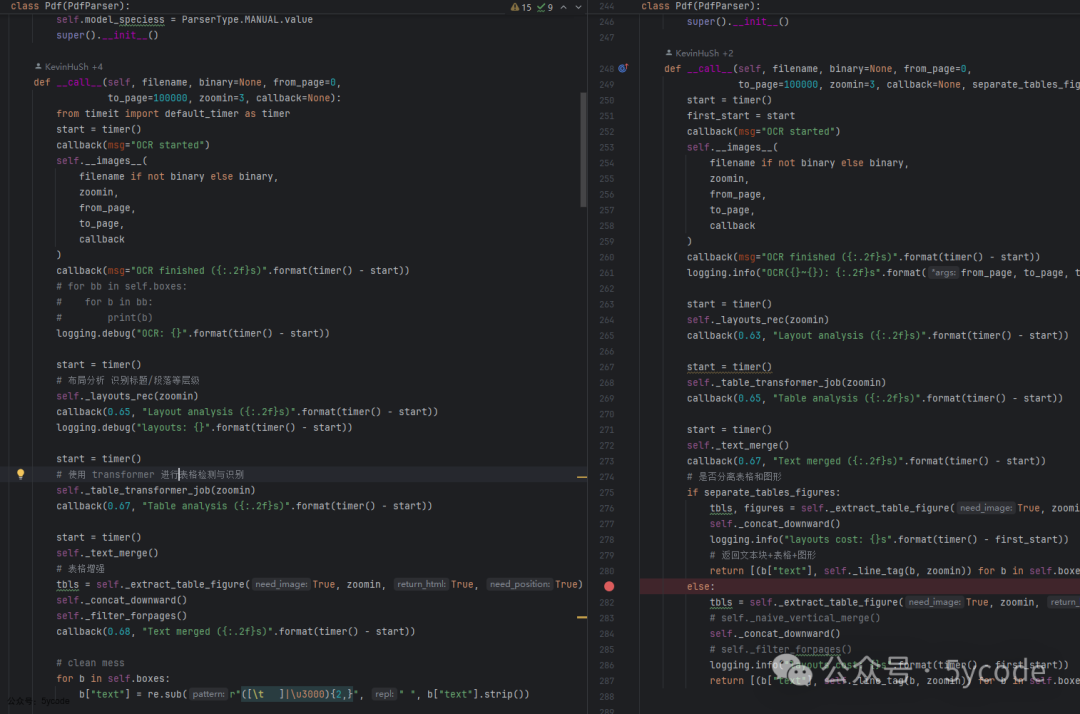
在manual中,并没有抽取图片,只抽取了表格,而且类似的代码写了两遍。
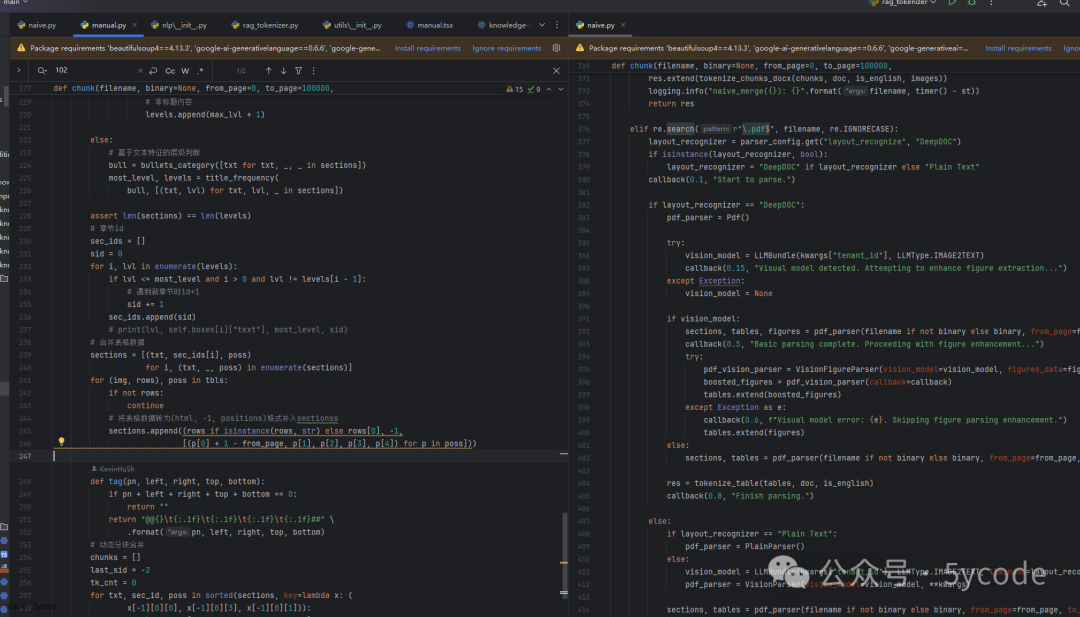
我又对比了manual和naive下pdf的处理代码。
-
•
manual中注重的是文档结构化,其他的并没有增强 -
• 反而在
naive模式下,通过视觉模型对图片进行了增强 -
• 所以
manual只适合没有图片的,有表格的pdf
laws
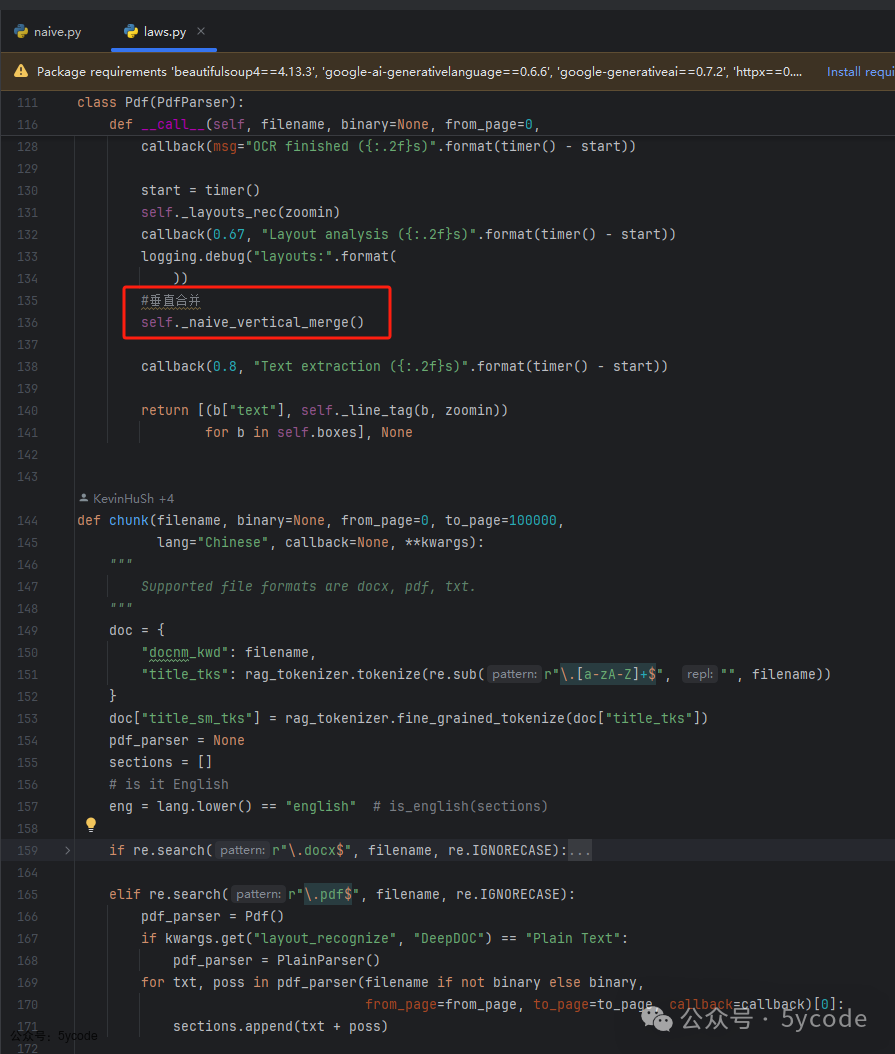
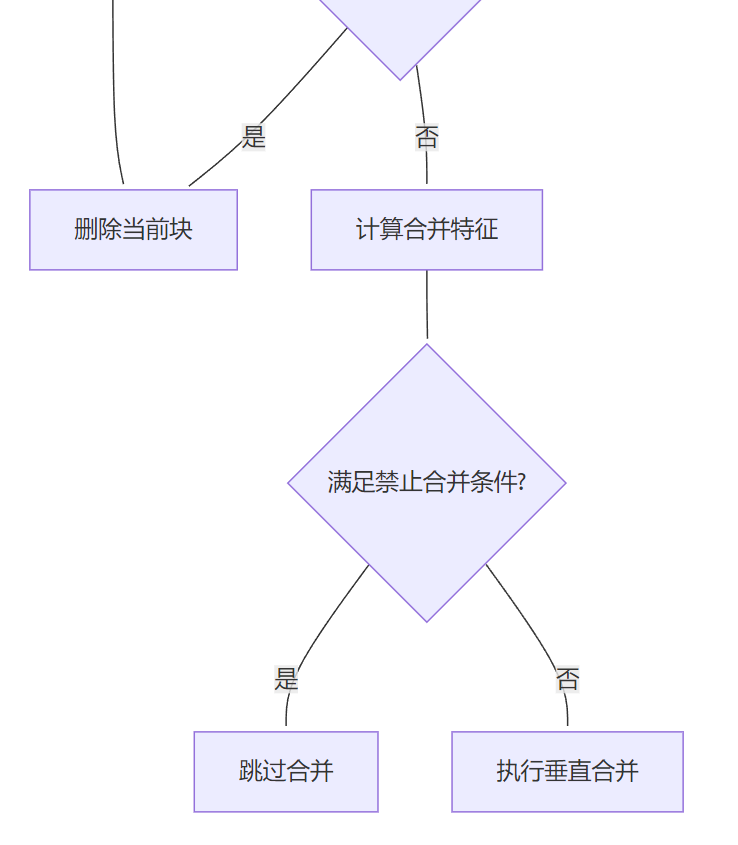
- • 法律文本的处理,在pdf上 处理上,唯一特殊的地方只有一个垂直合并
合并逻辑如下:
book
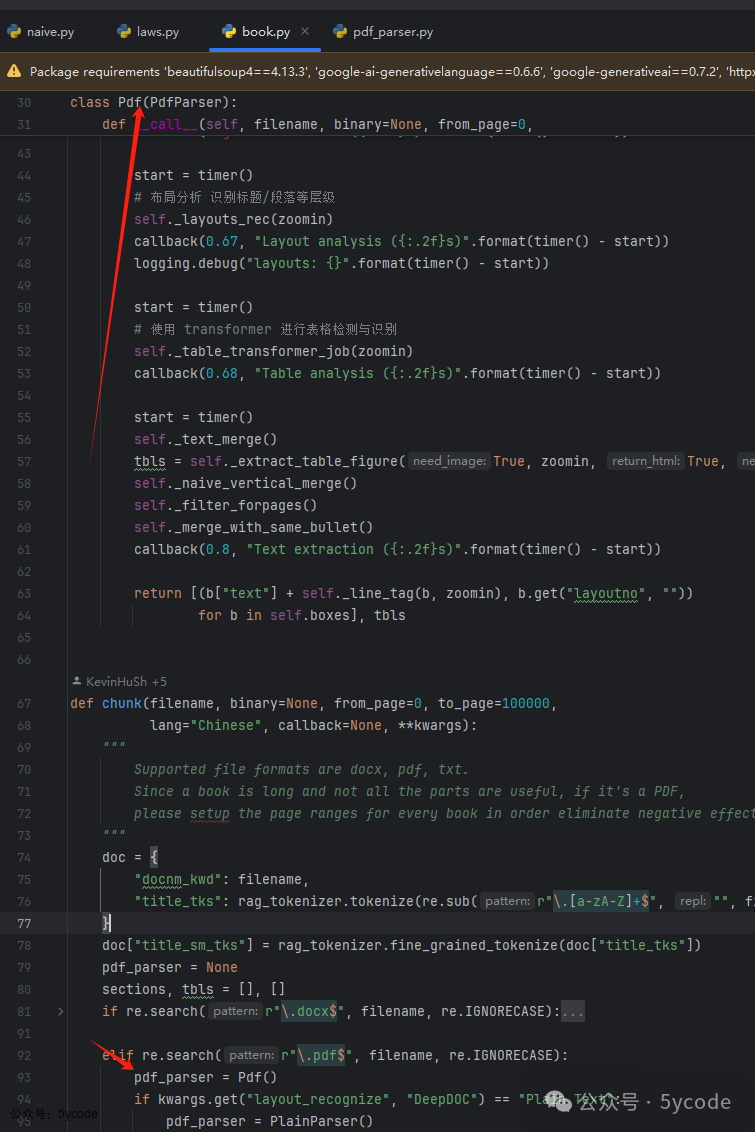
我们看了几个,特殊场景的处理,其实最后都是通过pdf的差异化处理实现的。
resume 简历
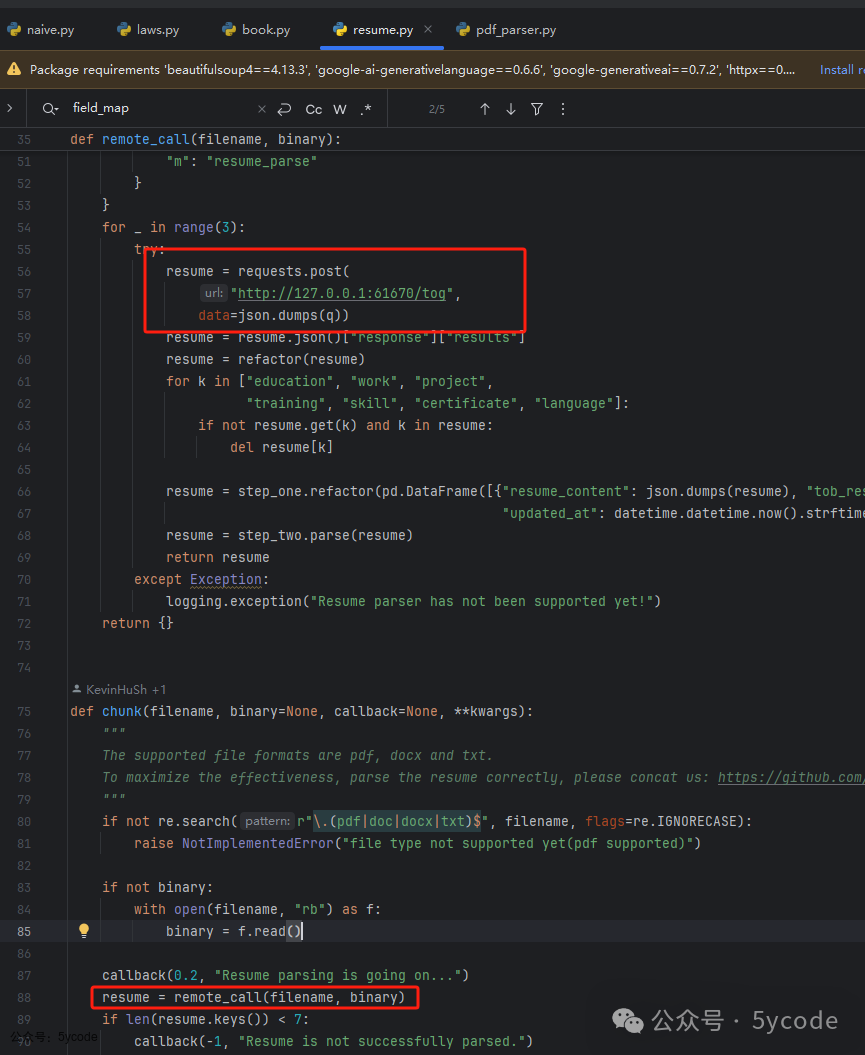
- • 首先通过内部服务,会进行简历的处理,通过上下文,可以看到是对简历进行了结构化处理。 这个需要注意下,如果你源码部署,一定要注意这个,否则就趟坑了。
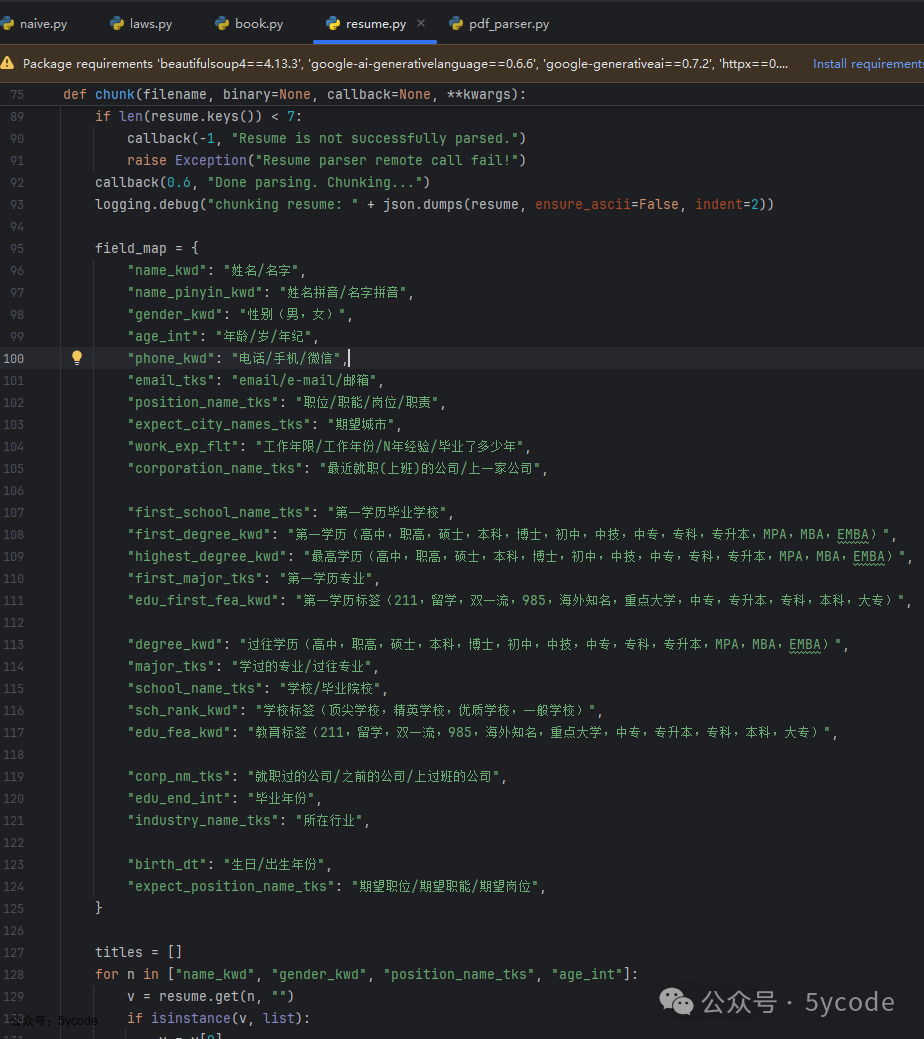
然后通过结构化的关键词,构建一个分片的数据结构。
qa
def rmPrefix(txt):
return re.sub(
r"^(问题|答案|回答|user|assistant|Q|A|Question|Answer|问|答)[\t:: ]+", "", txt.strip(), flags=re.IGNORECASE)
def beAdocPdf(d, q, a, eng, image, poss):
qprefix = "Question: " if eng else "问题:"
aprefix = "Answer: " if eng else "回答:"
d["content_with_weight"] = "\t".join(
[qprefix + rmPrefix(q), aprefix + rmPrefix(a)])
d["content_ltks"] = rag_tokenizer.tokenize(q)
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
d["image"] = image
add_positions(d, poss)
return d
def beAdocDocx(d, q, a, eng, image, row_num=-1):
qprefix = "Question: " if eng else "问题:"
aprefix = "Answer: " if eng else "回答:"
d["content_with_weight"] = "\t".join(
[qprefix + rmPrefix(q), aprefix + rmPrefix(a)])
d["content_ltks"] = rag_tokenizer.tokenize(q)
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
d["image"] = image
if row_num >= 0:
d["top_int"] = [row_num]
return d
def beAdoc(d, q, a, eng, row_num=-1):
qprefix = "Question: " if eng else "问题:"
aprefix = "Answer: " if eng else "回答:"
d["content_with_weight"] = "\t".join(
[qprefix + rmPrefix(q), aprefix + rmPrefix(a)])
d["content_ltks"] = rag_tokenizer.tokenize(q)
d["content_sm_ltks"] = rag_tokenizer.fine_grained_tokenize(d["content_ltks"])
if row_num >= 0:
d["top_int"] = [row_num]
return d
我们可以看到qa就是根据不同的结构解析出来问答对。
audio
def chunk(filename, binary, tenant_id, lang, callback=None, **kwargs):
doc = {
"docnm_kwd": filename,
"title_tks": rag_tokenizer.tokenize(re.sub(r"\.[a-zA-Z]+$", "", filename))
}
doc["title_sm_tks"] = rag_tokenizer.fine_grained_tokenize(doc["title_tks"])
# is it English
eng = lang.lower() == "english" # is_english(sections)
try:
callback(0.1, "USE Sequence2Txt LLM to transcription the audio")
seq2txt_mdl = LLMBundle(tenant_id, LLMType.SPEECH2TEXT, lang=lang)
ans = seq2txt_mdl.transcription(binary)
callback(0.8, "Sequence2Txt LLM respond: %s ..." % ans[:32])
tokenize(doc, ans, eng)
return [doc]
except Exception as e:
callback(prog=-1, msg=str(e))
return []这块的代码更简单,直接通过语音模型转成了文本,然后再进行处理。
picture
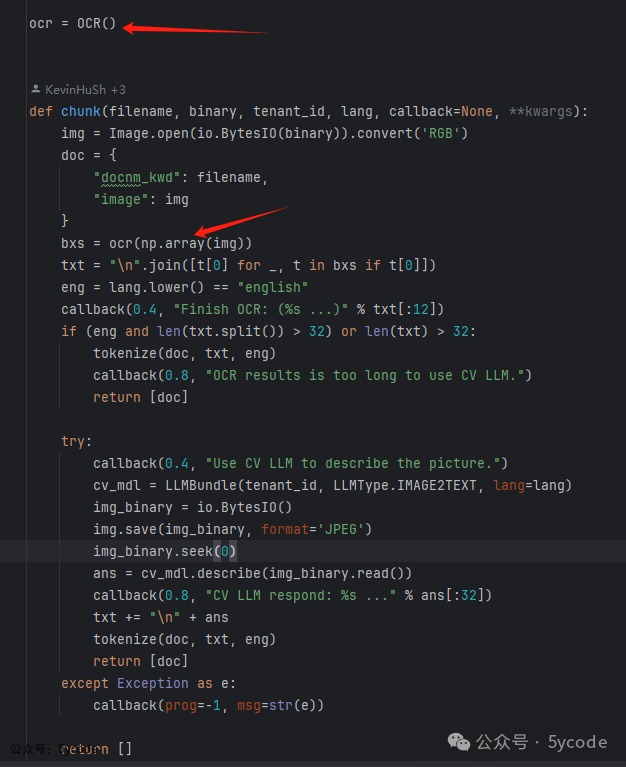
图片的解析是使用OCR处理,所以识别到的是图片上的文本内容。使用的是deepdoc之前测试,识别效果很一般。
图片识别有两种,一种是识别图片中的文本内容,一种是通过图片描述这个图片是什么。我们可以通过扩展,ocr+图片描述构建一个图片检索系统。
两种实现方案:
-
• 直接改这块的源码,添加图片理解反推
-
• 在外面将图片反推后,构建图片描述,后续我基于这个写个案例
后记
通过代码发现,专用处理有时候也蛮鸡肋的,如果我们在外面将文档都结构化了,很多通过一些分片策略,我们可以忽略一些专用类型。
底层的处理最后都是deepdoc中的几个文件。后续会针对这个再做一些源码分析。
rag玩的是对文档的了解,怎么能拆解出合适的分片,这个是关键。
市面上应该有一些处理文档的专有模型,到时候找下看看。