本文是实验设计与分析(第6版,Montgomery著傅珏生译)第10章拟合回归模型第10.4节的python解决方案。本文尽量避免重复书中的理论,着于提供python解决方案,并与原书的运算结果进行对比。您可以从Detail 下载实验设计与分析(第6版,Montgomery著傅珏生译)电子版。本文假定您已具备python基础,如果您还没有python的基础,可以从Detail 下载相关资料进行学习。
在多元线性回归问题中,对模型参数的假设检验有助于度量模型的有效性,本节将介绍几种重要的假设检验方法。这些方法要求模型误差εi服从均值为零,方差为σ2的独立的正态分布,简记为ε~NID(0,σ2)。由此可知,观测yi服从均值为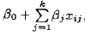 ,方差为σ2的独立的正态分布。
,方差为σ2的独立的正态分布。
10.4.1回归的显著性检验(略)
10.4.2 回归系数的个别检验和分组检验
大多数回归的计算机程序对每个模型参数给出t检验。例如,考虑表10.4,它是例10.1的Minitab输出。输出的上面部分给出了每个参数的最小二乘估计、标准误、t统计量以及对应的P值。对此模型,我门的结论是两个变量(温度和进料速率)都是显著的。
例10.6 考虑例10.1中的黏度数据。假定要研究变量x2(进料速率)对模型的作用。即所要检验的假设是
Ho:β2=0,H1: β2≠0
这需要求出β2的附加平方和
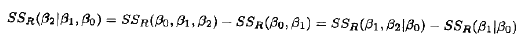
由检验了回归显著性的表10.4,我们有
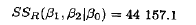
在表中它被称为模型平方和。这个平方和有2个自由度
简化模型是
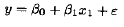
此模型的最小二乘拟合为
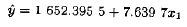
其(自由度为1的)回归平方和是
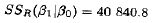
注意,这个SSR(β1|β0)显示在表10.4中Mintab输出的底部的"Seq SS项中。因此,
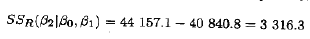
其自由度为2一1=1。这是向已包含了x1的模型中添加x2而引起的回归平方和的增加量,己显示在表10.4中Mintab输出的底部。为了检验H0: β2=0,由检验统计量可得
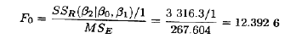
注意,F0的分母为全模型中的MSE(表10.4)。由F0.05,1,13=4.67,我们拒绝H0: β2=0,并认为x2(进料速率)对模型有显著影响。
这个偏F检验仅涉及单一回归变量,此时它等价于t检验,因为自由度为ν的t统计量的平方就是自由度为1和ν的F统计量。为了理解这一点,查看表10.4中对H0: β2=0检验的t统计量t0=3.5203,因此t02=(3.5203)2=12.3925≈F0。
P324例10.1
Viscosity=2256,2340,2426,2293,2330,2368,2250,2409,2364,2379,2440,2364,2404,2317,2309,2328
Temperature =80,93,100,82,90,99,81,96,94,93,97,95,100,85,86,87
Catalyst =8,9,10,12,11,8,8,10,12,11,13,11,8,12,9,12
data= {"Viscosity":Viscosity,"Temperature":Temperature,"Catalyst":Catalyst}
df =pd.DataFrame(data)
#model = smf.ols('df.Viscosity ~ C(df.Temperature) + C(df.Rate)', data=df).fit()
model = smf.ols('df.Viscosity ~df.Temperature +df.Catalyst', data=df).fit()
#model = smf.ols('df.Yield ~pd.get_dummies(df.Temperature) +pd.get_dummies(df.Pressure)+pd.get_dummies(df.Conc)', data=df).fit()
#model = smf.ols('df.Viscosity ~ df.Temperature + df.Rate + df.Temperature:df.Rate', data=df).fit()
print(model.summary2())
print(model.params)
anovatable=sm.stats.anova_lm(model)
ax = sns.residplot(x=model.predict(df.Temperature), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
ax = sns.residplot(x=model.predict(df.Rate), y=df.Viscosity, lowess=False, color='black')
ax.set_xlabel('Fitted value')
ax.set_ylabel('Residuals')
plt.show()
>>> print(model.summary2())
C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\site-packages\scipy\stats\_stats_py.py:1736: UserWarning: kurtosistest only valid for n>=20 ... continuing anyway, n=16
warnings.warn("kurtosistest only valid for n>=20 ... continuing "
Results: Ordinary least squares
====================================================================
Model: OLS Adj. R-squared: 0.916
Dependent Variable: df.Viscosity AIC: 137.5159
Date: 2024-03-14 10:31 BIC: 139.8337
No. Observations: 16 Log-Likelihood: -65.758
Df Model: 2 F-statistic: 82.50
Df Residuals: 13 Prob (F-statistic): 4.10e-08
R-squared: 0.927 Scale: 267.60
Coef. Std.Err. t P>|t| 0.025 0.975
Intercept 1566.0778 61.5918 25.4267 0.0000 1433.0167 1699.1388
df.Temperature 7.6213 0.6184 12.3236 0.0000 6.2853 8.9573
df.Catalyst 8.5848 2.4387 3.5203 0.0038 3.3164 13.8533
Omnibus: 1.215 Durbin-Watson: 2.607
Prob(Omnibus): 0.545 Jarque-Bera (JB): 0.779
Skew: -0.004 Prob(JB): 0.677
Kurtosis: 1.919 Condition No.: 1385
====================================================================
Notes:
1 Standard Errors assume that the covariance matrix of the errors
is correctly specified.
2 The condition number is large, 1.38e+03. This might indicate
that there are strong multicollinearity or other numerical
problems.
>>> print(model.params)
Intercept 1566.077771
df.Temperature 7.621290
df.Catalyst 8.584846
dtype: float64
>>> anovatable=sm.stats.anova_lm(model)
>>> anovatable
df sum_sq mean_sq F PR(>F)
df.Temperature 1.0 40840.842466 40840.842466 152.616757 1.473645e-08
df.Catalyst 1.0 3316.244074 3316.244074 12.392360 3.764806e-03
Residual 13.0 3478.850960 267.603920 NaN NaN