
笔记整理:郭浩文,东南大学硕士,研究方向为水下域专项知识图谱构建
论文链接:https://aclanthology.org/2024.findings-emnlp.769.pdf
发表会议:EMNLP 2024
1. 动机
近年来,LLM在自然语言处理领域取得了显著进展,特别是在zero-shot learning方面,零样本关系抽取的目标是无需通过大量的标注数据,从文本中识别实体之间的关系。利用zero-shot能力有利于减少人工标注成本和提高模型的泛化能力,但是尽管LLM在零样本关系抽取任务中表现出色,但现有方法仍存在一些问题。首先,缺乏详细的上下文提示(prompts),导致模型无法充分理解句子和关系的复杂性。而且由于样本多样性和覆盖范围不足,直接从LLMs生成的样本往往存在实体分布不均匀的问题。最后,现有方法未能充分利用LLMs自身的生成能力来创建针对特定关系的合成样本,导致模型在面对未见过的关系时表现不佳。
2. 贡献
****(1)提出了一种新的自我提示框架(****Self-Prompting framework):该框架通过一个三阶段的多样化方法生成合成样本,这些样本包含特定的关系类型,并作为上下文示例(in-context demonstrations)来指导模型进行关系抽取。
(2)通过实验验证了该框架的有效性:在多个基准数据集上,该框架显著优于现有的基于LLMs的零样本RE方法。
(3)展示了合成样本生成策略的重要性:通过消融实验,证明了关系同义词生成、实体过滤和句子重述等策略对提升模型性能的重要作用。
3. 方法
自我提示框架(Self-Prompting framework)通过一个三阶段的多样化方法来生成合成样本,这些样本用于为大型语言模型(LLMs)提供更具体、更丰富的上下文指导,从而提升其在零样本关系抽取(Zero-shot Relation Extraction)任务中的表现。
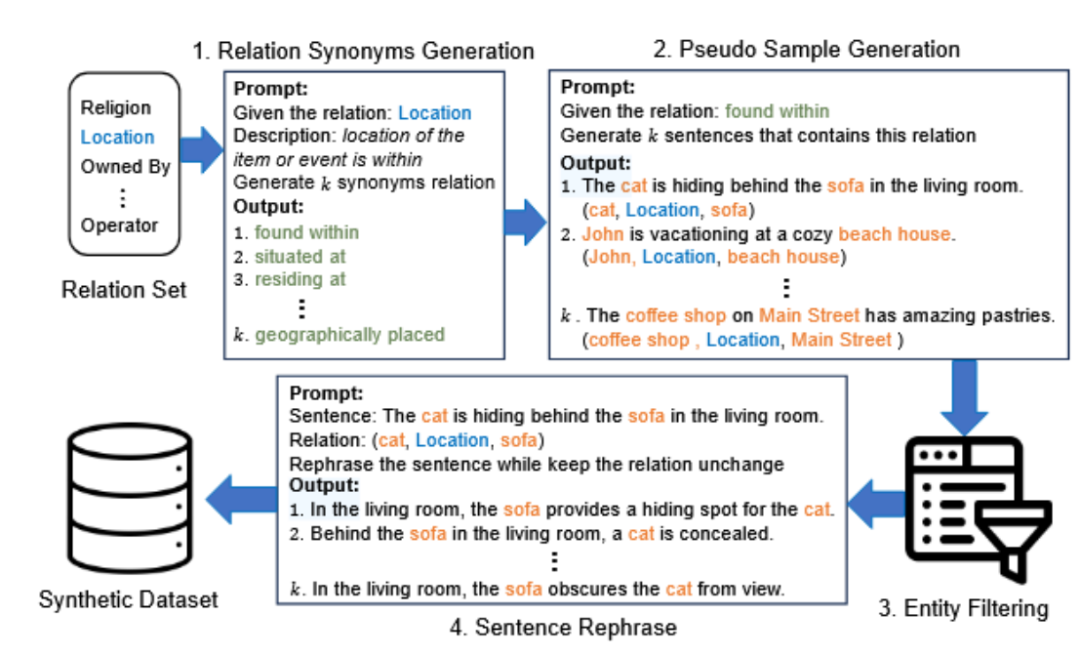
图1 模型框架图
3.1 关系同义词生成( Relation Synonyms Generation)
在关系抽取任务中,一个关系可能有多种表达方式。例如,"location"关系可以用"situated at"、"found within"或"residing at"等短语来表达。为了扩展关系的语义覆盖范围,认识到数据集的关系的广泛的概念,自我提示框架首先让LLMs为每个目标关系生成多个同义词(synonyms)。对于每个预定义的目标关系,框架提供关系的描述,以帮助LLM更好地理解关系的语义,接着根据关系描述生成一组同义词,这些同义词可以是单个词汇或者是短语,但是都必须与原始的关系语义保持一致,最后整合同义词,生成的同义词与原始关系一起构成一个语义群组(semantic group),用于后续sentence样本的生成,这一步的目的是为了确保模型能理解关系的多种表达方式。
3. 2 合成样本生成与实体过滤(Synthetic Sample Generation with Entity Filtering)
在生成了关系同义词后,框架利用这些同义词生成包含特定关系的合成样本。每个合成样本包含一个句子和对应的关系三元组(relation triple),例如:(实体1,关系,实体2)LLM根据语义群组生成包含一个关系的句子,并标关系三元组,为了避免生成的样本中实体分布不均匀(例如某些高频实体反复出现),框架引入了一个过滤机制。具体来说:移除包含高频实体的样本(实体出现次数超过设定阈值n/保留包含低频实体的样本,并更新这些实体的出现次数)这一步为了确保合成样本的多样性和平衡性。
3. 3 句子重述(Sentence Rephrase)
为了进一步增加合成样本的多样性,框架让LLM对生成的句子进行重述(rephrase),生成结构不同但语义相似的句子变体,将生成的句子及其关系三元组输入LLM,要求其根据输入生成多个语义相似但结构不同的重述版本,重述后的句子必须保留原始的关系,但是可以对句子结构和表达方式进行调整。这一步的目的是增加样本的语义多样性和语言复杂性。
3. 4 zero - shot推理阶段
在给定测试句子的推理阶段,论文的方法检索d个语义相似的样本作为上下文示例。使用句子嵌入模型对测试句子进行编码,并使用余弦相似度从生成的样本集中选择最相似的示例。为了有效地组织检索到的样本,使用了基于相似性分数的排名策略:kNN-augmented Example Selection(KATE)(Liu et al., 2022a),从最低分到最高分排列样本。该方法将最相关的样本放置在最靠近测试句子的位置,从而优化上下文样本对 LLM 推理过程的影响,是模型更好的进行指令跟随。
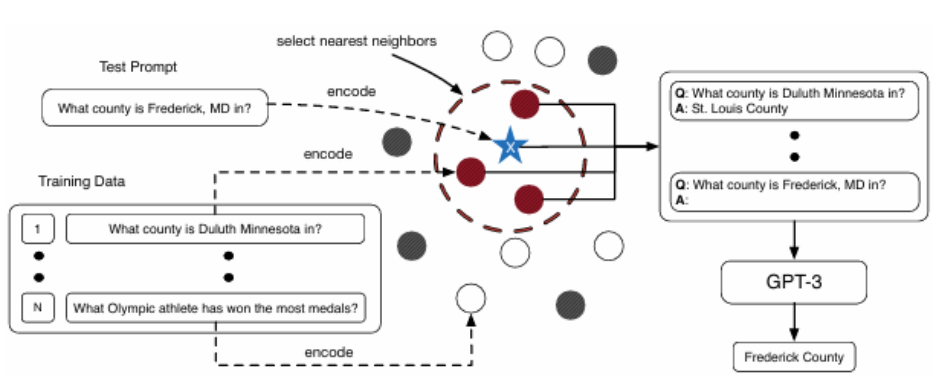
图2 KATE架构图
4. 实验
4 . 1 主要结果
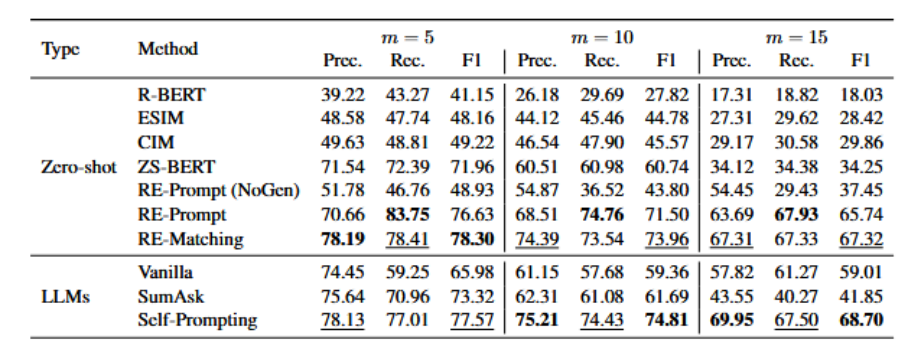
本文在多个基准数据集上进行了实验,包括FewRel、Wiki-ZSL、TACRED和SemEval。
- 在Wiki-ZSL数据集上,当未见关系数量为10时,Self-Prompting框架的F1分数达到了77.57%,显著高于其他方法。
- 在FewRel数据集上,Self-Prompting框架在不同数量的未见关系设置下均取得了优异的性能。
- 在TACRED和SemEval数据集上,Self-Prompting框架也展现了强大的性能,分别取得了57.1%和52.7%的F1分数。
表1 Wiki-ZSL 上的主要结果
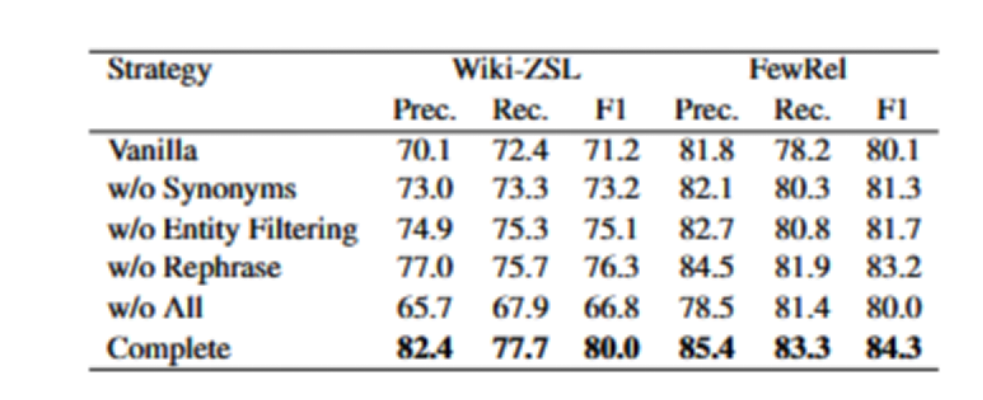
4 . 2 消融实验
- **移除句子重述(**Sentence Rephrase)会导致精度(Precision)和F1分数略有下降。
- 移除关系同义词生成(Relation Synonyms Generation)则会导致性能显著下降。
- 移除实体过滤(Entity Filtering)会显著影响召回率(Recall),表明实体多样性对关系抽取的重要性。
表2 不同策略在 FewRel 和 Wiki-ZSL 数据集上的性能比较 (m = 10)
5. 总结
论文通过自我提示框架(Self-Prompting framework)提出了一种新的方法,通过关系同义词生成、实体过滤和句子重述等策略,生成高质量、多样化的合成样本。这些样本作为上下文示例,为LLMs提供了更具体、更丰富的指导,从而显著提升了零样本关系抽取的性能。
但是论文还有一些问题:在选择合适的上下文示例时,如果选择不当可能会引入噪声,从而影响LLM的性能。此外,该方法并不能保证也没有验证生成样本的正确性,特别是在特定领域数据上的表现未得到验证,而特定领域的数据生成本身就是一个挑战。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文 ,进入 OpenKG 网站。