目录
[一、ETL 代表什么](#一、ETL 代表什么)
[1. ETL 的含义](#1. ETL 的含义)
[2. ETL 的核心作用](#2. ETL 的核心作用)
[3. ETL 在数据生态系统中的地位](#3. ETL 在数据生态系统中的地位)
[二、ETL 开发主要做什么?](#二、ETL 开发主要做什么?)
[1. 数据提取(Extract)](#1. 数据提取(Extract))
[2. 数据转换(Transform)](#2. 数据转换(Transform))
[3. 数据加载(Load)](#3. 数据加载(Load))
[三、ETL 开发的挑战与应对策略](#三、ETL 开发的挑战与应对策略)
[1. 数据质量问题](#1. 数据质量问题)
[2. 性能问题](#2. 性能问题)
[3. 数据安全问题](#3. 数据安全问题)
[4. 技术更新换代快](#4. 技术更新换代快)
你的 ETL 流程真的高效可靠吗?
数据清洗不彻底导致分析结果偏差、转换规则混乱引发数据矛盾、加载失败造成业务延误...... 这些潜在隐患你都妥善解决了吗?
在《数据管理能力成熟度评估模型》等行业规范的严格要求下,企业如何既能高效完成数据处理,又能保障 ETL 全流程稳定运行?
答案在于弄清楚ETL 开发主要做什么,从而打造从数据源接入→数据清洗转换→目标存储加载的全流程标准化体系,并借助专业开发工具实现 "流程透明、质量可控、异常可查"。
今天,我们就从ETL代表什么出发,来系统讲解如何构建专业的 ETL 及开发体系,帮你快速排查流程漏洞,让数据处理真正成为驱动业务发展的引擎。
一、ETL 代表什么
1. ETL 的含义
ETL 是 Extract(提取)、Transform(转换)、Load(加载)三个英文单词首字母的缩写。它是一种将数据从源系统(如各种业务数据库、文件系统等)中提取出来,经过一系列的转换处理,使其符合目标系统的要求,最后加载到目标系统(如数据仓库、数据集市等)中的过程。简单来说,ETL 就是将数据从一个地方搬到另一个地方,并在搬运的过程中对数据进行清洗、转换和整合。
2. ETL 的核心作用
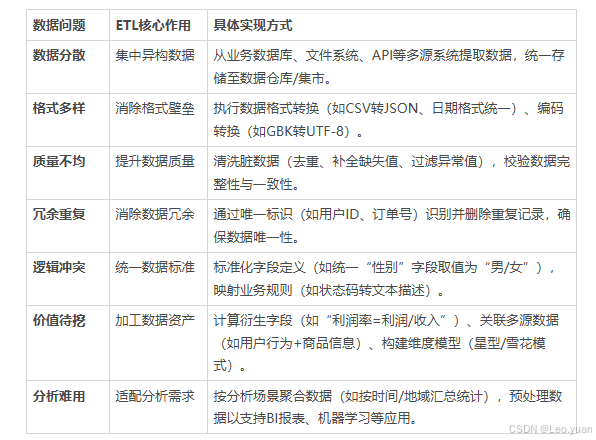
以下是关于ETL核心作用的表格化呈现,从数据问题、具体作用、实现方式三方面拆解说明:
3. ETL 在数据生态系统中的地位
在整个数据生态系统中,ETL 处于数据采集和数据存储之间的关键环节。它是连接数据源和数据仓库、数据集市等目标系统的桥梁,为后续的数据分析、数据挖掘和决策支持提供了必要的数据准备。没有 ETL,大量的数据将无法得到有效的整合和利用,数据分析和决策也就成了无源之水、无本之木。
二、ETL 开发主要做什么?
1. 数据提取(Extract)
1.1 数据源的识别与连接
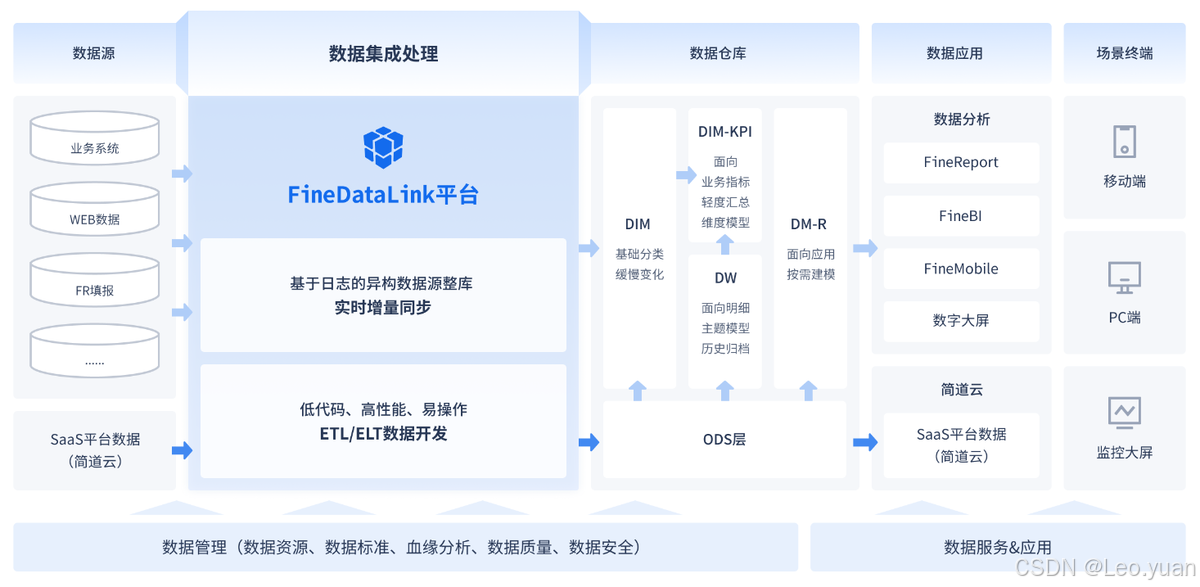
ETL 开发的第一步是识别数据源,即确定需要从哪些系统中提取数据。数据源可以是各种类型的数据库,如关系型数据库(Oracle、MySQL、SQL Server 等)、非关系型数据库(MongoDB、Redis 等),也可以是文件系统(如 CSV 文件、Excel 文件等)、日志文件、Web 服务等。开发人员需要根据数据源的类型和特点,选择合适的连接方式和工具,建立与数据源的连接。在此过程中,通过引入ETL工具FineDataLink,让用户仅通过单一平台,即可实现实时数据传输、数据调度、数据治理等各类复杂组合场景的能力,为企业业务的数字化转型提供支持。FineDataLink以数据为基础,以全链路加工为核心,提供数据汇聚、研发、治理等多种功能,满足平台用户的数据需求。
1.2 数据提取策略的制定
在建立连接后,需要制定数据提取策略。根据业务需求和数据特点,选择合适的提取方式,如全量提取、增量提取等。全量提取是指将数据源中的所有数据一次性提取到目标系统中,适用于数据量较小、数据更新不频繁的情况;增量提取则是只提取数据源中新增或修改的数据,适用于数据量较大、数据更新频繁的情况。开发人员还需要考虑数据提取的频率,如每天、每周、每月等,以确保目标系统中的数据是最新的。
1.3 数据提取脚本的编写
根据数据提取策略,开发人员需要编写相应的脚本或程序来实现数据的提取。对于关系型数据库,通常使用 SQL 语句来查询和提取数据;对于非关系型数据库和文件系统,可能需要使用特定的编程语言和工具来进行数据提取。在编写脚本时,需要考虑数据的安全性和性能,避免对数据源造成过大的压力。
2. 数据转换(Transform)
2.1 数据清洗
数据清洗是数据转换的重要环节,其目的是去除数据中的噪声、错误和不一致性,提高数据的质量。常见的数据清洗操作包括去除重复数据、处理缺失值、修正错误数据、标准化数据格式等。例如,在处理客户数据时,可能会存在重复的客户记录,需要通过一定的算法将其去除;对于缺失的客户年龄数据,可以根据其他相关信息进行估算或填充。
2.2 数据转换与计算
除了数据清洗,还需要对数据进行转换和计算,以满足分析的需求。数据转换包括数据类型转换、数据编码转换、数据格式转换等。例如,将日期数据从字符串格式转换为日期类型,以便进行日期计算和分析。数据计算则包括对数据进行汇总、统计、排序等操作。例如,计算每个客户的总消费金额、每个地区的平均销售额等。
2.3 数据关联与整合
在实际业务中,数据往往分散在不同的表或文件中,需要将这些数据进行关联和整合,以形成完整的数据集。数据关联是指通过共同的字段将不同表中的数据连接起来,如通过客户 ID 将客户表和订单表关联起来。数据整合则是将关联后的数据进行合并和整理,去除冗余信息,形成一个统一的数据集。
3. 数据加载(Load)
3.1 目标系统的选择与连接
数据加载的第一步是选择目标系统,即确定将处理后的数据加载到哪个系统中。目标系统可以是数据仓库、数据集市、数据湖等。开发人员需要根据业务需求和数据特点,选择合适的目标系统,并建立与目标系统的连接。
3.2 数据加载策略的制定
在建立连接后,需要制定数据加载策略。根据目标系统的特点和数据量的大小,选择合适的加载方式,如批量加载、实时加载等。批量加载是指将处理后的数据一次性加载到目标系统中,适用于数据量较大、对实时性要求不高的情况;实时加载则是在数据处理完成后立即将其加载到目标系统中,适用于对实时性要求较高的情况。
3.3 数据加载脚本的编写
根据数据加载策略,开发人员需要编写相应的脚本或程序来实现数据的加载。对于关系型数据库,通常使用 SQL 语句来插入或更新数据;对于非关系型数据库和文件系统,可能需要使用特定的编程语言和工具来进行数据加载。在编写脚本时,需要考虑数据的一致性和完整性,确保加载到目标系统中的数据是准确无误的。
三、ETL 开发的挑战与应对策略
1. 数据质量问题
数据质量是 ETL 开发中面临的最大挑战之一。由于数据源的多样性和复杂性,数据中往往存在大量的噪声、错误和不一致性。为了保证数据质量,需要在 ETL 过程中进行严格的数据清洗和验证。可以建立数据质量监控机制,对数据进行实时监测和分析,及时发现和解决数据质量问题。
2. 性能问题
随着企业数据量的不断增长,ETL 过程的性能成为了一个关键问题。如果 ETL 过程的性能不佳,将导致数据处理时间过长,影响数据分析和决策的及时性。为了提高 ETL 过程的性能,可以采用并行处理、分布式计算等技术,优化 ETL 流程和算法,减少数据处理时间。
3. 数据安全问题
数据安全是 ETL 开发中不可忽视的问题。在数据提取、转换和加载的过程中,需要确保数据的安全性和保密性。可以采用数据加密、访问控制等技术,对数据进行保护,防止数据泄露和滥用。
4. 技术更新换代快
随着信息技术的不断发展,ETL 相关的技术和工具也在不断更新换代。开发人员需要不断学习和掌握新的技术和工具,以适应市场的需求。企业可以为开发人员提供培训和学习机会,鼓励他们不断提升自己的技术水平。
总结
Q:ETL 开发和简单的数据导入工具在功能上有什么区别? A:当企业只需将单一数据源(如一个 Excel 表格)快速导入到数据库,且不涉及数据格式调整和逻辑处理时,简单的数据导入工具即可完成任务,例如使用数据库自带的导入功能将员工信息表导入到指定表中。但如果企业需要从多个业务系统(销售系统、库存系统、财务系统)提取数据,对数据进行深度处理(如关联不同系统数据生成客户消费画像、对数据进行聚合统计),并实现数据的定期自动更新,那么 ETL 开发通过构建完整的提取---转换---加载流程,结合调度工具实现任务自动化,同时具备完善的错误处理和日志监控机制,能够满足复杂数据处理场景的需求,远超简单数据导入工具的能力范畴。
综上所述,ETL 代表 Extract(提取)、Transform(转换)、Load(加载),是数据处理和分析中不可或缺的环节。ETL 开发主要包括数据提取、数据转换和数据加载三个方面的工作,需要使用各种工具和技术来实现。