目录
[概率建模(如贝叶斯建模、马尔可夫过程、MDP/POMDP) 等](#概率建模(如贝叶斯建模、马尔可夫过程、MDP/POMDP) 等)
[1.离散时间马尔可夫链(Discrete-Time Markov Chain, DTMC)](#1.离散时间马尔可夫链(Discrete-Time Markov Chain, DTMC))
[2.连续时间马尔可夫链(Continuous-Time Markov Chain, CTMC)](#2.连续时间马尔可夫链(Continuous-Time Markov Chain, CTMC))
[HMM 的局限性](#HMM 的局限性)
[有限状态机(Finite State Machine, FSM)](#有限状态机(Finite State Machine, FSM))
[FSM V.S. BT](#FSM V.S. BT)
数学建模
微分方程
动态系统建模
时间序列分析
概述
时间序列分析是统计学和信号处理领域的一个重要分支,专门用于分析按时间顺序排列的数据点序列 。参考统计学13------时间序列分析
根据观察时间的不同,时间序列的时间可以是年份、季度、月份等。根据观测值的分布情况时间序列可以分为平稳序列和非平稳序列:
- 平稳序列就是观察值在某一固定水平上下波动,这种波动的程度可能不同但不存在明显的规律,也就可以看成是随机的。
- 非平稳序列是包含趋势、季节性、周期性的序列,他可能只含有一种成分,也可能含有多种。
于是时间序列的成分便可以分为随机性波动(I)、趋势(T)、季节性(S)、周期性(C)。传统时间序列分析的一项主要内容就是把这些成分从时间序列中分离出来。按照乘法模型,它的形式为:
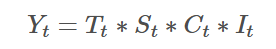
指数衰减
指数衰减是一种数学现象,描述了一个量以与当前值成比例的速度持续减小的过程。在时间序列分析中,它通常用来建模某些效应或影响随时间逐渐减弱的现象,或者作为一种平滑或权重分配机制。


随机漂移
随机漂移 (或称随机游走)是一种特殊的随机过程,其中未来的位置或数值是当前位置或数值加上一个随机扰动。它没有固定的趋势,而是无偏地在数值空间中"漂移"。



总结
指数衰减 描述了系统效应随时间有规律地、逐渐地减弱 ,是一种确定性或平稳性的衰减模式,常用于平滑和建模短期记忆。
随机漂移 描述了系统数值在随机冲击下无偏地累积 ,是一种典型的非平稳过程,其方差随时间增加,且预测结果主要依赖于当前值。
曲线拟合
最优化方法
梯度下降法
概率建模(如贝叶斯建模、马尔可夫过程、MDP/POMDP) 等
贝叶斯建模
贝叶斯定理
贝叶斯建模的核心是**贝叶斯定理,**它是基于统计来告诉我们如何在获得新证据后更新我们对某个假设的信念,其是一种思维方式。
贝叶斯定理的数学公式如下:

P(A) 在观察到结果B之前,我们对假设A成立的初始信念。它反映了我们已有的知识或经验(先验概率)。
P(B|A) 在假设 A 成立的条件下,观察到证据 B 的概率。它衡量了我们的模型在给定假设下与数据的一致性。(基于前提条件去看结果)
P(B) 观察到证据 B 的总概率。
P(A|B) 在观察到证据 B 之后,假设 A 成立的概率。
即思路就像是目前有很多理论,你认为它们的出发点有问题,因此提出了一个假设,然后那你根据这个假设去处理对应的问题,然后分析这个假设在处理对应问题时的结果,如果你的结果比其他理论好,那么结论可以有效反哺你这个假设,因此证明你假设的有效性。
假设,目前一个超市要统计奶爸在买啤酒(事件A)后会不会买尿裤(事件B)。那现在如果统计出来奶爸买啤酒( P (A), 样本1,2,3,4,5中的1,3,5 )的概率是0.6,然后在买完啤酒后再买尿裤( P(B|A) )(样本1,3,5的1, 5)的概率是 2/3。那么现在要调用在买尿裤和买啤酒的关联性,如果关联性强的话,超市后续可以基于此推出活动来促进这二者的消费。那买了尿裤后会买啤酒( P(A|B),样本1,2,4,5的1,5 )是0.5,买尿裤的概率( P(B) )是0.8。因此, 可以得出
|--------------------------------------|-----|
| | 0.6 |
| | 0.8 |
| | 2/3 |
| | 0.5 |
那根据贝叶斯定理,在未知啤酒和尿裤的关联性前提下,我们基于已有数据P(A), P(B), P(B|A)可以计算得出= 2/3 * 0.6 / 0.8 = 0.5。那这样的话我们就知道了在奶爸中买尿裤后买啤酒的概率是0.5。这样的话,我们知道了结果 尿裤 跟我开始 买啤酒 的关联性,关联性高的话,那我商场是不是以后可以将尿裤摆放在显眼的位置,这样的话当奶爸买了尿裤之后,由于尿裤与啤酒关联性高,那相对应的在购买玩尿裤其就会去倾向于去购买啤酒,从而通过尿裤来提升啤酒的销售量。
如下图,统计数据中事件A买啤酒的概率是0.6,买啤酒后再买尿裤即啤酒 → 尿裤的概率是0.4,其他类推..
|---|----|----|
| | A | B |
| 1 | 啤酒 | 尿裤 |
| 2 | 面包 | 尿裤 |
| 3 | 啤酒 | 香肠 |
| 4 | 香肠 | 尿裤 |
| 5 | 啤酒 | 尿裤 |
在贝叶斯定理中,后验概率是我们最关心的目标。它衡量的是我这个结果与我所引导的因之间的关联性。
在机器学习中,可以通过用贝叶斯建模来证明当前结果与你当前诱因之间的关系。比如在二分类指标中,pre就是衡量你在预测所有正确的样本中,实际为正确的样本,从后往前的思路;又如时间序列分析中,你要衡量是时间上的哪个事件极大影响了我当前的结果。
优势
- 量化不确定性: 贝叶斯方法自然地提供了对参数和预测的不确定性量化。它输出的是概率分布,而不是单一的点估计,这使得我们能够更好地理解模型的可靠性。
- 融入先验知识: 贝叶斯建模允许我们显式地纳入已有的领域知识或专家经验作为先验。这在数据稀疏或噪声较大的情况下尤为重要。
- 模型解释性: 贝叶斯模型通常比某些黑箱模型更具解释性,因为我们能够清晰地看到每个参数的后验分布,从而理解其对结果的影响。
- 从小数据中学习: 在数据量较少时,先验信息的重要性凸显出来,贝叶斯方法可以在有限数据下做出更稳健的推断。
- 层次化建模: 贝叶斯方法非常适合构建层次化模型,处理嵌套数据结构(例如,来自不同地区的学生成绩),使得信息可以在不同层级之间共享。
马尔可夫过程
马尔可夫过程(Markov Process)是一种随机过程,它的核心特点是马尔可夫性(Markov Property) 。马尔可夫性可以简单概括为:"未来只依赖于现在,而与过去无关。",更严谨地说,给定现在(当前状态),未来的条件概率分布与过去(之前的所有状态)是独立的。
用数学语言表达就是:

马尔可夫过程的分类
根据状态空间是离散还是连续,可将马尔可夫过程分为两种:
1.离散时间马尔可夫链(Discrete-Time Markov Chain, DTMC)
- 时间是离散的(例如 t=0,1,2,...)。
- 状态空间是离散的(例如 {1,2,3}, {晴天, 阴天, 雨天})。
- 这是最常见的马尔可夫过程类型,也是我们通常首先学习的。
- 例子,每次比较上当前天气跟上一个小时天气的区别。
2.连续时间马尔可夫链(Continuous-Time Markov Chain, CTMC)
- 时间是连续的(例如 t≥0)。
- 状态空间是离散的。
- 例子,分析我当前天气跟过去两小时内天气的区别。
离散时间马尔可夫链详述
DTMC的几个要素定义:
- 状态空间 (State Space) S: 所有可能状态的集合。它必须是离散的,可以是有限的也可以是无限的。如S ={1,2,3,...,N} (有限状态),S={晴天,阴天,雨天}
- **转移概率(Transition Probabilities):**从一个状态转移到另一个状态的概率。

- 转移概率矩阵 (Transition Probability Matrix) P: 如果状态空间是有限的,我们可以用一个矩阵来表示所有转移概率。

- 初始分布 (Initial Distribution)
: 在时刻 n=0 时,系统处于各个状态的概率分布。
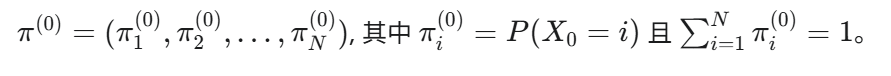
初始值为当前初始状态的值,因为没有初始状态不存在有上一个状态。
隐马尔可夫模型(HMM)
隐马尔可夫模型是在马尔克夫过程的基础上添加了一个状态,在马尔可夫过程中,你自变量x可以通过函数,直接获得状态空间;而隐马尔可夫模型相当于是自变量x输入后,需要经过隐含函数
,得到隐含空间表示g(x),而后再基于隐含空间表示得到最终的状态空间 f( g(x) )。当然这个隐含空间可能不止一个。
隐马尔可夫模型定义
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
隐马尔可夫模型是一个双重随机过程,它包含两个层面:
- 隐藏的马尔可夫链 (Hidden Markov Chain): 这是一个我们无法直接观测到的状态序列。这个隐藏的状态序列满足马尔可夫性,即在任意时刻,隐藏状态的转移只依赖于前一个隐藏状态。
- 可观测的输出序列 (Observable Sequence): 在每个隐藏状态下,系统会以一定的概率发出一个可观测的符号。我们只能观测到这些符号,而不能直接看到隐藏状态。
案例分析,案例源于简单易懂的隐马尔可夫模型(HMM)讲解
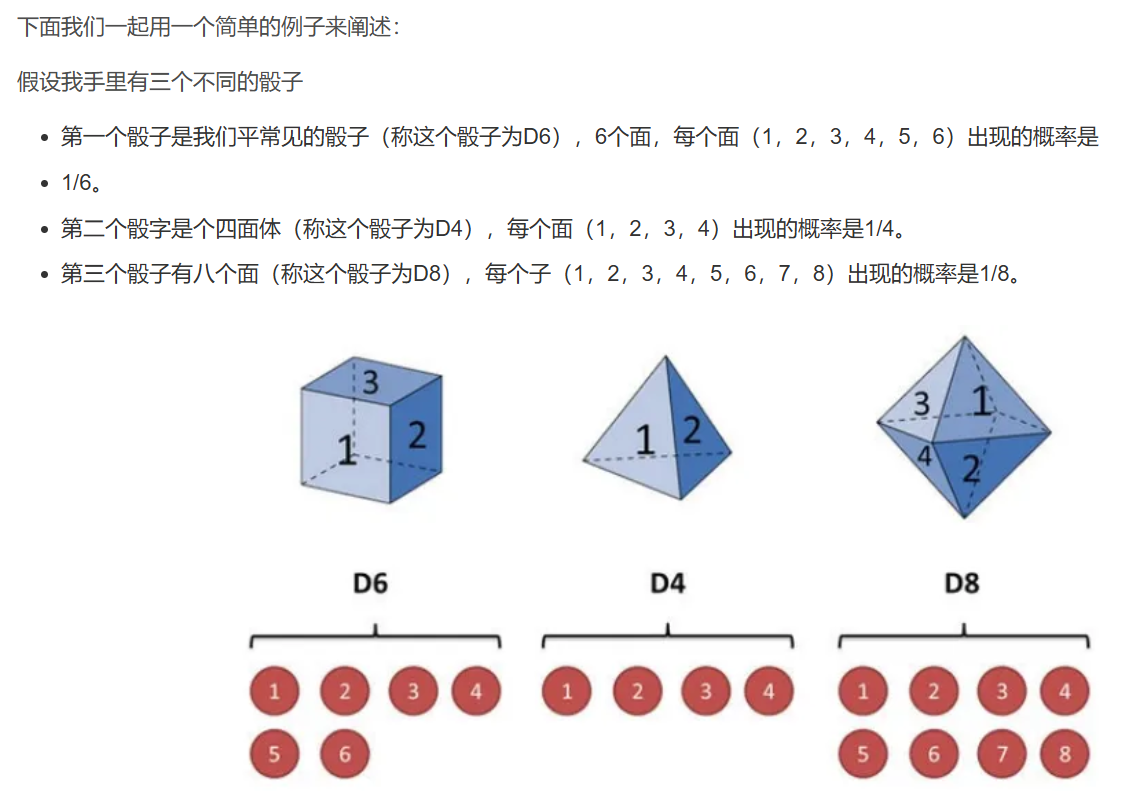

在这个例子中,可以明显感觉到与马尔可夫过程的区别了,丢骰子 → 骰子序列 是马尔可夫过程, 丢骰子 → 使用什么骰子 → 骰子序列 是隐马尔可夫过程,相当于出现中间商了。
其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的。
- 有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;
相当于知道x,知道g(),不知道f() - 有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。
相当于只知道f( g(x) ),但不知道g(),也不知道x是什么。
如何应用算法去估计这些缺失的信息,就成了一个很重要的问题。
HMM相关算法
x → g(x) → f( g(x) )。HMM的相关算法取决于其要解决的三个基本问题,假如A是输入,B是隐含变量,C是最终结果。那三个基本问题分别为1. 求出C是A输入导致得来的概率。 2.求出A得到C的过程中的B。3.给定C和A,才使得A的生成结果能尽可能趋近于C。

HMM 的局限性
尽管 HMM 强大且灵活,但它也有一些局限性:
- 马尔可夫假设: HMM 严格遵守马尔可夫性,即当前状态只依赖于前一个状态。这可能无法捕捉到更长期的依赖关系。
- 观测独立性假设: HMM 假设给定隐藏状态时,当前的观测只依赖于当前状态,而与过去的观测或状态无关。这在某些真实场景中可能不成立。
- 局部最优解: Baum-Welch 算法收敛到局部最优解,而不是全局最优解。模型的初始化对结果有影响。
- 模型参数过多: 对于大型状态空间和观测空间,HMM 的参数数量可能非常庞大,需要大量数据进行训练。
机器决策人建模
有限状态机(Finite State Machine, FSM)
有限状态机,顾名思义,是一种只有有限个状态 的离散数学模型 。它在任何给定时刻都处于这些有限状态中的一个,并且根据输入事件,它可以从一个状态转移(transition)到另一个状态,描述了一个对象在有限个状态之间切换的行为。
在FSM中:
- 角色(或 AI)在一个时间点只能处于一个状态。
- 特定条件 触发状态变化(状态转换)。
- 不同状态 控制 AI 或角色的行为。
示例:敌人 AI 可能有以下状态:
[巡逻] → 发现玩家 → [追踪] → 接近玩家 → [攻击] → 玩家死亡 → [返回巡逻]FSM 通过状态切换,使 AI 具有逻辑性和可控性。
FSM的基本组成
- 状态(States): 定义角色当前所处的状态,每个状态对应不同的行为。
- 事件(Events): 触发状态变化的外部刺激或内部条件。
- 转移(Transitions): 在特定事件发生时,从一个状态移动到另一个状态的规则, 决定当前状态如何切换到下一个状态。
- 初始状态(Initial State): FSM 需要一个初始状态,它是角色进入游戏时的默认状态。
需要区别的是事件 和**转移,**事件描述的是状态发生了变换,转移描述状态怎么变换。一个描述的是改变了没,一个描述的是怎么改变。
FSM中的初始状态可以对应马尔可夫定理的初始状态;状态可以对应马尔可夫定理在某个离散时间点的时候的状态;事件可以对应马尔可夫定理中下未来状态转变由当前状态触发;转移可以对应马尔可夫定理中未来状态在被当前状态触发后,我要如何基于当前状态去修改未来状态。
FSM在游戏开发中的应用
FSM 适用于各种场景,例如:
① AI 角色行为
-
敌人 AI 在巡逻、追踪、攻击、死亡等状态间切换。
-
例如:
[巡逻] → 发现敌人 → [追踪] → 靠近敌人 → [攻击]
②动画系统(Animation FSM)
-
动画状态机(Animator State Machine)用于管理角色动画。
-
例如:
[Idle] → 玩家按下 "W" → [Run] → 松开 "W" → [Idle]
③ 任务和游戏流程管理
任务状态机用于管理任务进度
[未接受] → 任务触发 → [进行中] → 任务完成 → [完成]行为树(BT)
行为树 (Behavior Tree, BT)是一种控制结构,通过组合不同的行为节点,能够定义复杂的行为逻辑,使自主体能够根据当前的环境状态和目标做出决策并执行相应的动作。常用于游戏中AI逻辑的实现。参考行为树基础实现。
基本概念
- 节点: 行为树由多个节点构成每个节点代表一个行为或决策步骤。节点根据其在树中的位置和功能可以分为不同类型的节点,如根节点、内部节点(控制流节点)、叶节点(执行节点)等。
- 状态: 每个节点在执行时都会返回三种状态之一,即成功(Success)、失败(Failure)和运行(Running)。成功和失败状态会通知其父节点其操作结果,而运行状态表示节点仍在执行中。
- 根节点: 作为行为树的入口,根节点是AI的起点。每个行为树只有一个根节点,且根节点通常只有一个子节点。
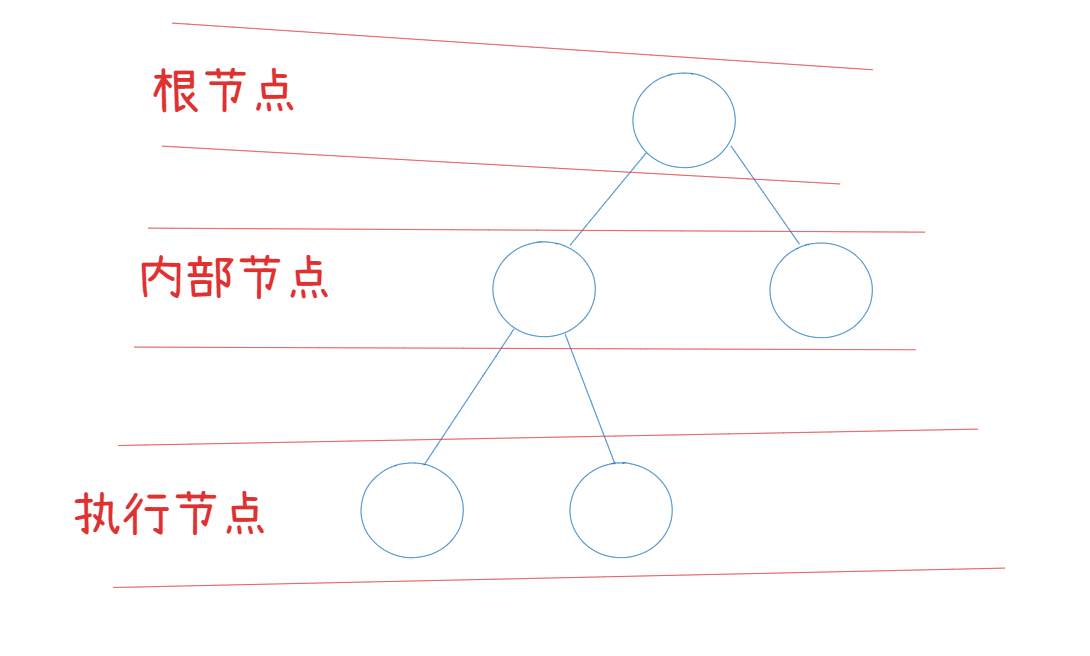
- 逻辑的判断是从上到下的,状态的传递是从下往上的。
- 具体的执行逻辑体现在叶子节点中。
节点类型
- 任务节点(TaskNode): 任务节点也叫执行节点(ActionNode) 它是叶节点,是行为树中最底层的节点,负责执行具体的行为或任务。它们不会拥有子节点,而是直接返回成功、失败或运行状态。。
- 复合节点(CompositeNode): 内部节点,也称为组合节点。它们可以有一个或多个子节点,并控制子节点的执行顺序和方式。常见的控制流节点包括选择器(Selector)、序列器(Sequence)等。
- 装饰节点(DecoratorNode): 一种特殊的控制流节点,它们通常只有一个子节点,并对子节点的执行结果进行修饰或改变。例如,反转装饰器可以反转子节点的成功或失败状态
工作原理
行为树通过从上至下、从左到右 的顺序遍历节点来执行AI的行为。当行为树运行到终结状态时,会回到根节点重新开始运行。在遍历过程中,每个节点都会根据其类型和功能执行相应的行为或决策,并返回状态给其父节点。父节点根据子节点的返回状态来决定下一步的执行计划。
- 前序遍历执行AI行为
- 遇到终结节点,退回根节点
- 节点返回状态给父节点,从下往上进行上传。
- 父节点收到信息后,决定下一步怎么做。
FSM V.S. BT

- FSM 适合简单行为(如角色动画、UI 交互)。
- 行为树适合复杂 AI 逻辑(如敌人 AI、多任务管理)。