
研究背景
随着物联网(IoE)的快速发展,数据量呈爆发式增长,对处理速度和能耗提出了更高要求。传统冯·诺依曼计算机因数据瓶颈和能耗限制,难以满足需求。受生物启发的计算方式因其并行处理能力和适应性,成为解决数据挑战的潜在途径。光子集成电路凭借并行处理、低功耗、大规模集成和低延迟等优势,成为实现神经网络的有力硬件平台。然而,光子平台的可扩展性限制了单次传递中可以执行的总矩阵-向量乘法(MVM)数量,增加了系统的总执行时间和能耗。
核心技术
本文提出了一种基于光频谱切片技术(Optical Spectrum Slicing, OSS)的光子神经形态加速器(OSS-CNN)
1.光域模拟卷积引擎
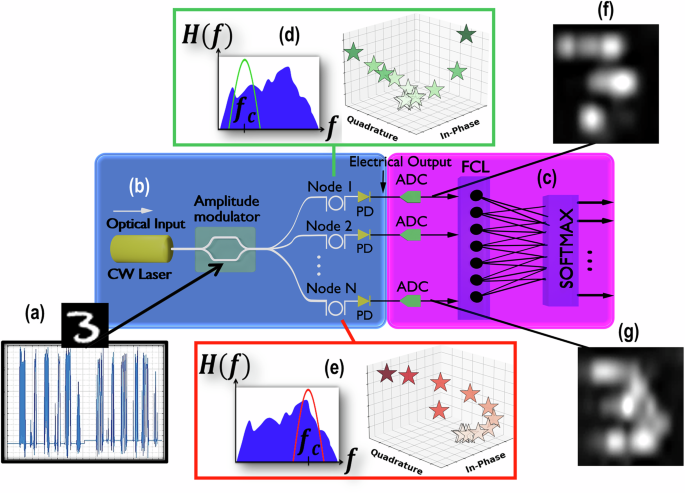
OSS节点设计:将可重构硅光子芯片(如SmartLight)中的微环谐振器(MRR)配置为被动光滤波器节点,通过调节中心频率和带宽,直接在光域实现连续值卷积核操作,替代传统数字卷积层。
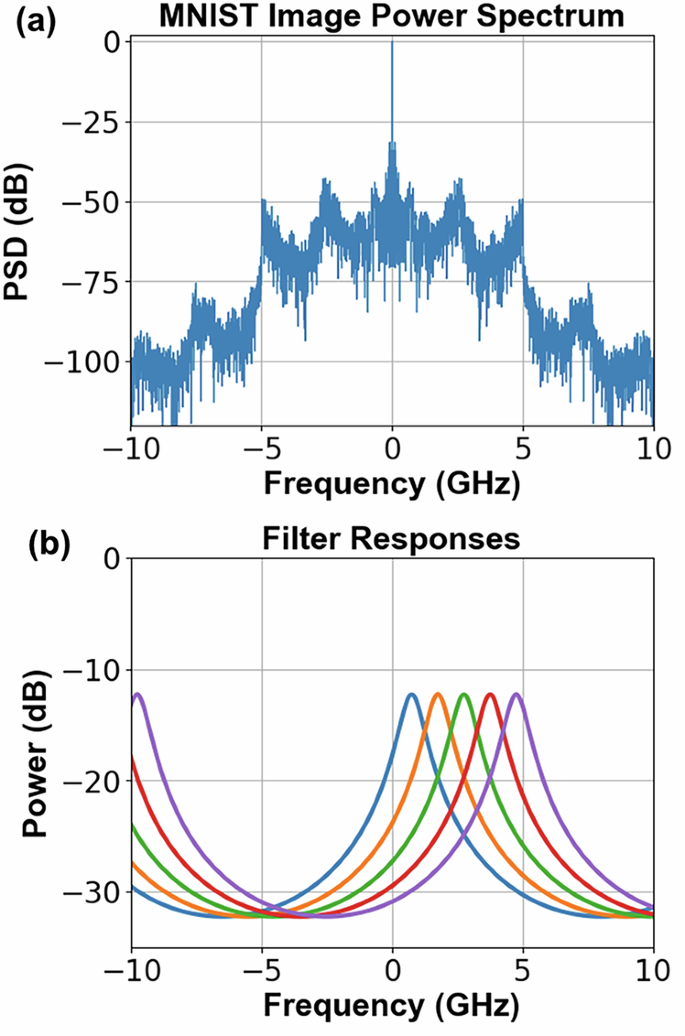
特征提取机制:每个OSS节点通过频谱切片提取输入光信号的不同时空特征,利用光脉冲响应的多样性(如式1-2)完成非线性变换与池化,无需复杂数字计算。
- 硬件友好型架构
低复杂度后端:仅需简单全连接层(FCL)对光处理后的压缩特征进行分类,显著减少数字计算量(实验显示GPU运算量降低92%)。
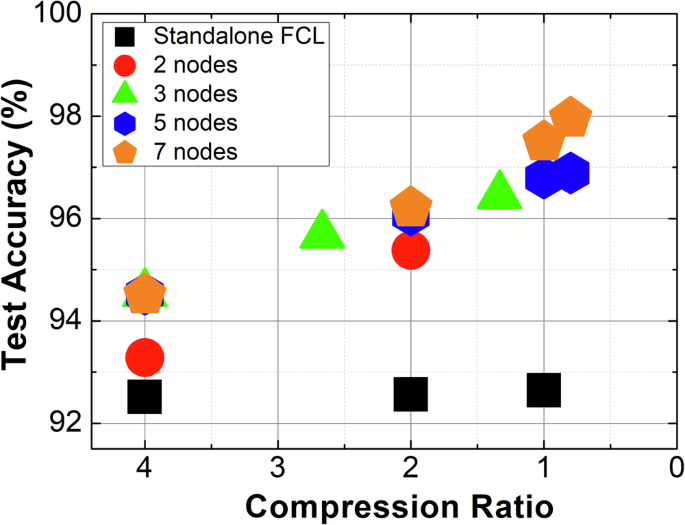
单次处理与高压缩比:通过时间复用编码和光域平均池化,单次通过光子芯片即可完成任意尺寸卷积操作,支持输入数据的维度压缩(压缩比CR可调)。
- 可重构光子集成平台
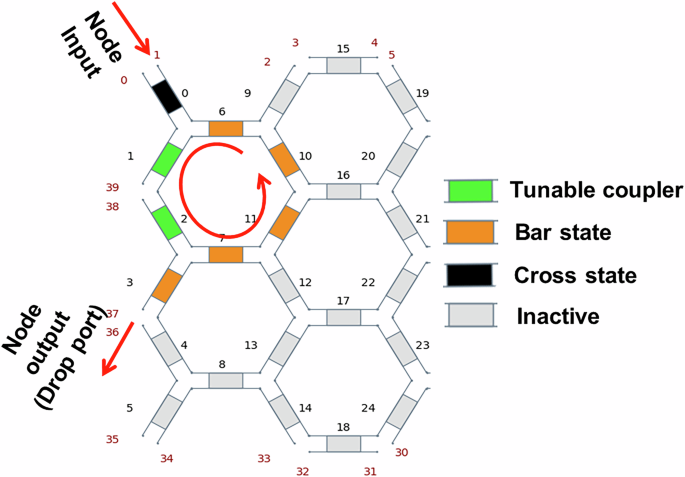
SmartLight芯片实现:利用可编程光子网格(Hexagonal拓扑)动态配置OSS节点,支持中心频率与带宽的灵活调节(如图2),克服固定滤波器带宽限制。
实验验证结果:
高精度:在MNIST数据集上达到97.7%分类准确率(3节点),优于现有光子CNN方案(如文献14-15)。
高能效:相比同规模数字CNN(单层GPU),总功耗降低30%(实验系统功耗36.6Wvs. 数字系统50W)。
- 端到端优化
光-电协同设计:光前端(OSS节点+光电检测)与数字后端(轻量FCL)联合优化,通过超参数搜索(如Optuna框架)平衡带宽、节点数、压缩比与功耗。
抗噪能力:在存在光子芯片损耗(如12dB插入损耗)和放大器噪声(EDFA)的情况下,仍保持高鲁棒性,实验精度仅比理想仿真低1.3%。
OSS-CNN架构的示意图
在可重构光子网格中,将每个光频谱切片(OSS)节点实现为一阶微环谐振器(MRR)
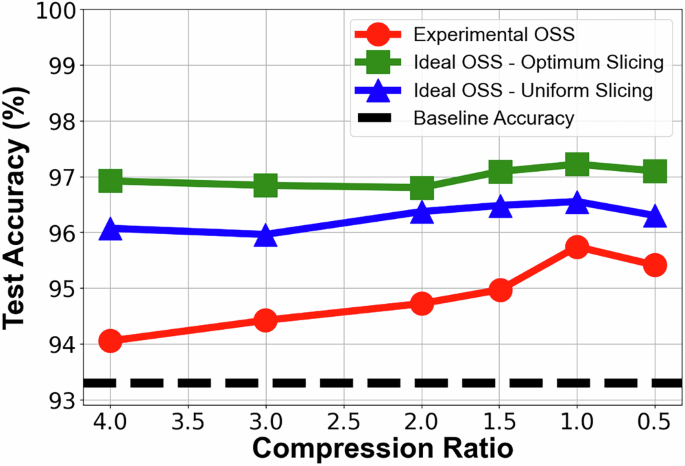
光频谱切片卷积神经网络(OSS-CNN)的分类准确率随压缩比(CR)及所采用OSS节点数量的变化关系
调制MNIST图像的频谱与光频谱切片(OSS)节点响应
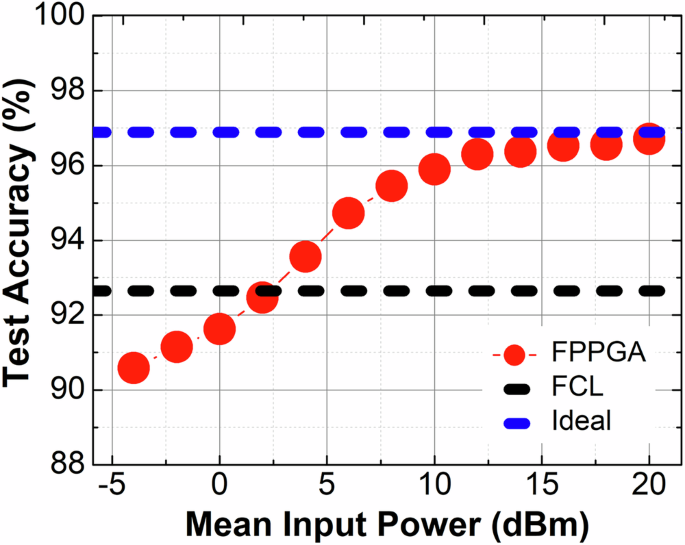
基于SmartLight实现的5节点光频谱切片卷积神经网络(OSS-CNN)分类准确率随平均输入功率的变化关系(采用4×4图像分块和10 GS/s像素速率)
光频谱切片卷积神经网络(OSS-CNN)的实验装置

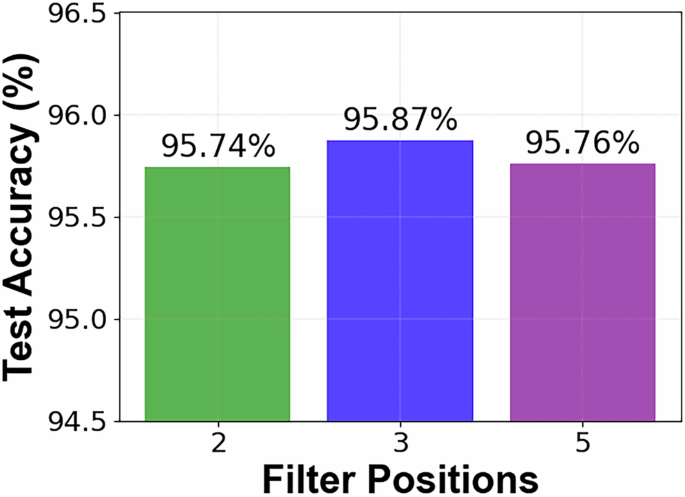
实验性光频谱切片卷积神经网络(OSS-CNN)的精度随节点数量的变化关系
光频谱切片卷积神经网络(OSS-CNNs)实验性与理想化模型的性能对比
原文链接:https://doi.org/10.1038/s44172-025-00416-3
【注】:小编水平有限,若有误,请联系修改;若侵权,请联系删除!