1
5 步实现 etcd 精确恢复
-
将快照恢复到本地 etcd 数据目录。
-
使用恢复的数据启动本地 etcd 实例。
-
使用 etcdctl 查询特定键(例如,ConfigMap)。
-
使用 auger 解码以提取干净的 YAML。
-
使用 kubectl 申请恢复到您的实时集群。
本指南将指导您从 etcd 快照中精准地恢复资源,而无需触发完整的集群恢复。无论您是要排除意外删除故障,还是进行取证调试,这种轻量级且有针对性的方法都能最大程度地减少停机时间。#Kubernetes
2
引言:🩺Kubernetes 操作里的紧急情况
etcd 是 Kubernetes 集群的核心,它是一个分布式键值存储系统,忠实地维护系统内每个对象的状态。但是,如果某个资源(例如 ConfigMap、Secret 或 Deployment)被删除或损坏,会发生什么情况呢?
启动完整的集群恢复就像进行心脏手术来修复纸张划伤一样。它具有破坏性、风险性,而且通常没有必要。
这就是手术精度发挥作用的地方。
想象一下,您的生产环境陷入危机------一个重要的 ConfigMap 消失了,Pod 崩溃了,用户只能盯着错误页面。完全回滚会比问题本身造成更大的损失。您需要的是一个"外科医生"式的方案:只修复损坏的部分,其他部分一概不做。
在本博客中,您将了解如何:
-
从 etcd 快照中隔离并提取特定资源
-
仅将所需内容直接恢复到实时 Kubernetes 集群中
-
避免不必要的停机并保持集群稳定性
-
非常适合重视最小影响恢复的 DevOps、SRE 和 Kubernetes 管理员。
3
先决条件🔧
为了继续操作,请确保您已具备:
-
etcd v3.4+ --- etcd 服务器二进制文件可在此处获取
-
etcdctl --- 与 etcd 交互的 CLI
-
auger --- CLI 工具,用于将 etcd 的二进制有效负载解码为 YAML
-
kubectl --- CLI 用于将资源应用于 Kubernetes 集群
-
快照文件--- 例如 live-cluster-snapshot.db
始终先在暂存环境中工作。从干净的快照开始:
etcdctl snapshot save live-cluster-snapshot.db
4
恢复过程🏥
假设 production 命名空间中一个关键的 ConfigMap app-config 被意外删除了。以下是如何将其恢复:
4.1
🧬 步骤 1:准备快照
如果压缩,请解压缩快照:
gunzip live-cluster-snapshot.db.gz
然后恢复它:
etcdctl snapshot restore live-cluster-snapshot.db --data-dir=recovery-etcd
4.2
🩻 第 2 步:启动本地 etcd 实例
etcd --data-dir=recovery-etcd --listen-client-urls=http://localhost:2379
核实:
javascript
etcdctl --endpoints=localhost:2379 endpoint status4.3
🔍 步骤 3:定位并提取资源
Kubernetes 将 ConfigMap 存储在类似 /registry/configmaps//的键中。列出生产命名空间中的键:
etcdctl --endpoints=localhost:2379 get --prefix "/registry/configmaps/production" --keys-only你会看到类似这样的内容:
/registry/configmaps/production/app-config提取并解码 ConfigMap:
etcdctl --endpoints=localhost:2379 get /registry/configmaps/production/app-config --print-value-only | auger decode > app-config.yaml
生成的 app-config.yaml 可能如下所示:
javascript
apiVersion: v1 kind: ConfigMap metadata: name: app-config namespace: production data: api-url: "https://api.example.com" log-level: "debug"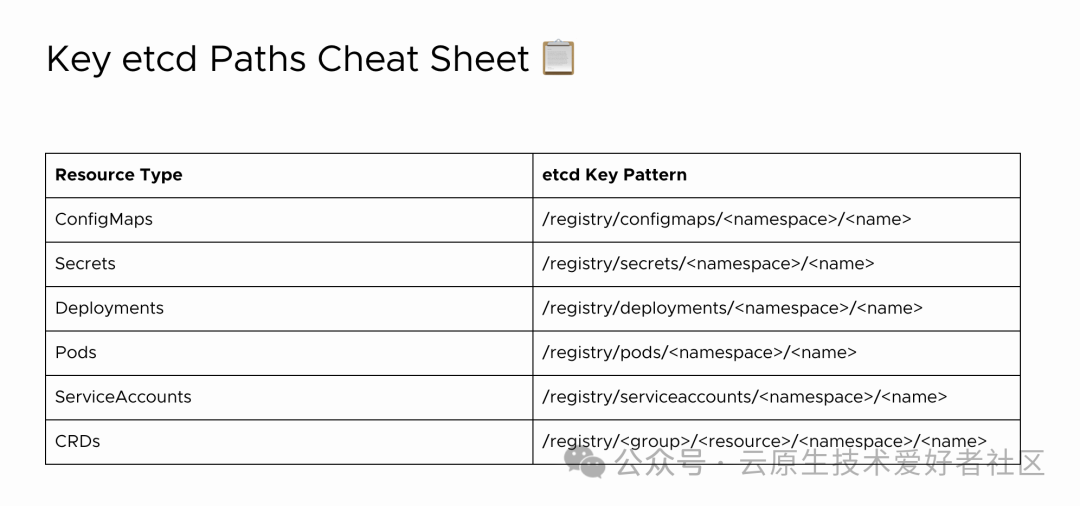
4.4
步骤 4:恢复到集群
通过试运行来测试修复效果:
kubectl apply -f app-config.yaml --dry-run=server
如果一切检查无误,则应用它:
kubectl apply -f app-config.yaml
输出:
configmap/app-config created
4.5
🧹 步骤 5:清理
javascript
pkill etcdrm -rf recovery-etcd app-config.yaml5
高级场景🔍
5.1
💠 跨命名空间恢复
cat app-config.yaml | yq eval '.metadata.namespace = "dev"' | kubectl apply -f -
5.2
🔐 加密集群 (KMS)
使用 etcdctl 并根据 etcd 加密指南配置解密密钥。📦批量恢复
javascript
etcdctl --endpoints=localhost:2379 get --prefix "/registry/configmaps/production" --print-value-only | auger decode > all-cm.yaml6
总结
最后的想法💡Kubernetes 管理员经常为灾难性故障做准备,但忽略了精确恢复的价值。能够精准地提取和恢复资源,并减少停机时间、防止附带损害、增强对事件响应的信心。当下次灾难来临时,您不会手忙脚乱,而是会采取行动。
随手关注或者"在看",诚挚感谢!