推荐系统里真的存在"反馈循环"吗?
许多人说,推荐算法不过是把用户早已存在的兴趣挖掘出来,你本来就爱听流行歌、买潮牌玩具,系统只是在合适的时间把它们端到你面前,再怎么迭代,算法也改变不了人的天性,反馈循环像是研究者们的学术噱头。
我第一次认真思考这个问题的时候,是为了搞清楚推荐系统里的偏差放大(Bias Amplification)效应。
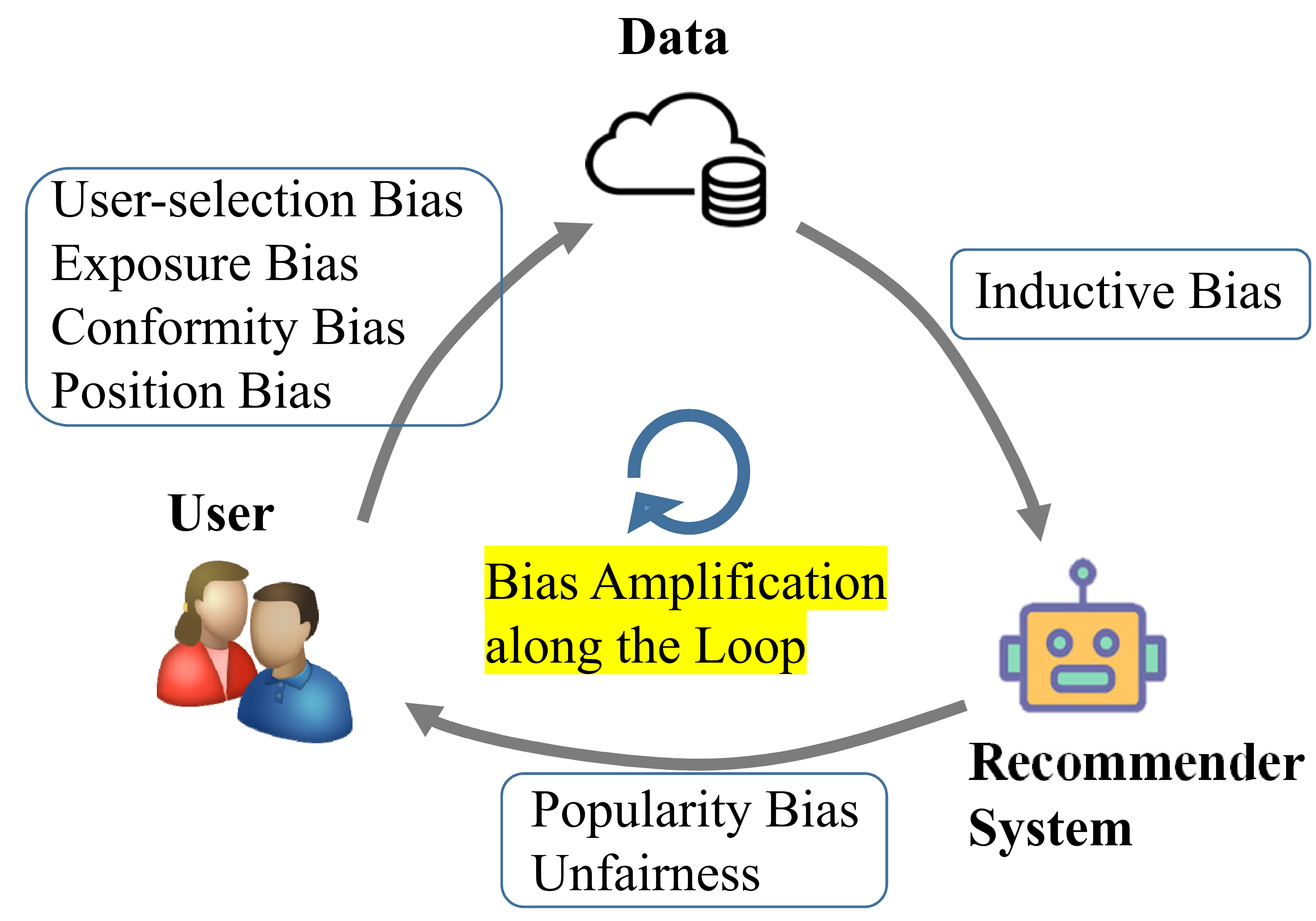
何向南的这个图示强调了推荐系统的偏差(曝光偏差、流行度偏差等)会在后续迭代中被连锁放大,最终表现为热门更热门、冷门愈冷门的马太效应,或其他不公平问题。
若不打破偏差的循环放大机制,推荐系统的性能就会持续恶化。
不少研究都认识到,在推荐服务阶段通过强化学习平衡探索与利用,以避免流行度偏差过度积累。
"试错"是强化学习探索与利用权衡中的一个核心理念,描述了推荐系统与用户进行交互并迭代更新策略的过程。
试错时,推荐策略会进行探索性的推荐,根据用户反馈来评判探索效果。随着时间的推移,探索行为能够试验出哪些项目能给带来更高的用户满意度,作为推荐策略更新的依据。
这是强化推荐算法与传统推荐算法相比的主要优势之一,它考虑到了推荐问题的交互性。
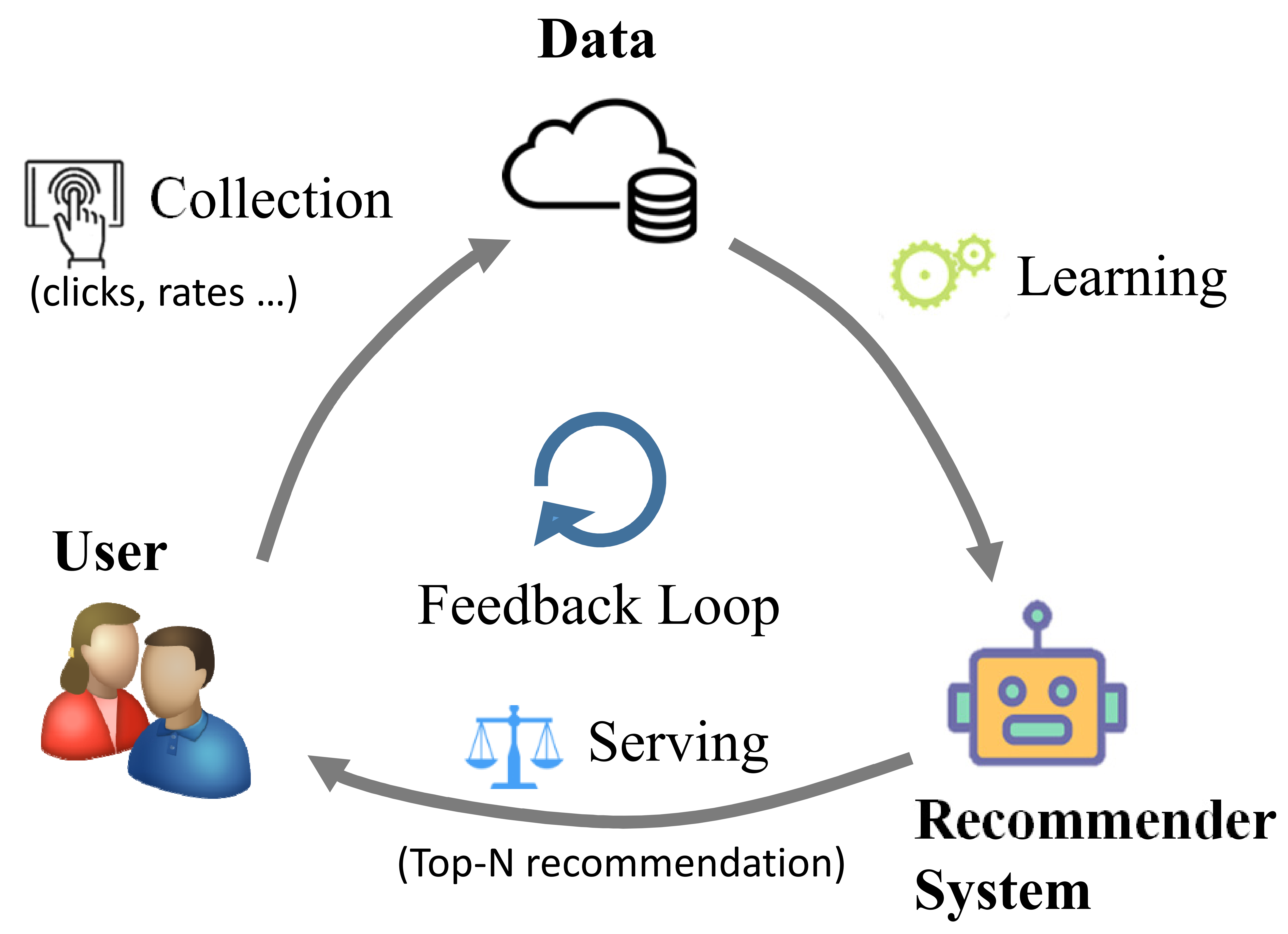
我们可以提炼出,在试错过程中,用户和推荐模型之间存在着一个反馈循环(Feedback Loop)。还是用何向南的图例来说明,推荐系统中的反馈循环包括三个阶段。
- 从用户到数据集。这一阶段系统收集用户与推荐系统的交互数据,例如点击行为、用户对项目的评分等等。
- 从数据集到推荐系统。这一阶段基于收集到的交互数据,从用户的交互历史中提炼用户偏好,然后学习推荐策略用来根据偏好预测用户可能采用的项目。
- 从推荐系统到用户。这一阶段推荐策略会将推荐结果以Top-N的形式展示给用户,以满足用户的信息需求。
用户和推荐系统在每个反馈循环中相互促进,用户的个人兴趣和行为通过推荐不断转移。对反馈循环进行建模,是强化学习推荐系统的重要基础之一。