引言
近期,阿里通义千问团队创新性提出了 GSPO 算法,PAI-ChatLearn 框架第一时间支持并复现了GSPO的强化学习训练过程,本文将介绍在 PAI 平台复现 GSPO 的最佳实践。
GSPO 算法介绍
强化学习(Reinforcement Learning, RL)是拓展语言模型、增加其深度推理与问题求解能力的关键技术范式。为了持续拓展 RL,首要前提是确保稳定、鲁棒的训练过程。现有的 RL 算法(如 GRPO)在长期训练中,会暴露出严重的不稳定性问题并招致不可逆转的模型崩溃,阻碍了通过增加计算以获得进一步的性能提升。
针对这个问题,通义团队提出了GSPO(Group Sequence Policy Optimization)算法。GSPO 算法与其他 RL 算法相比,定义了序列级别的重要性比率,并在序列层面执行裁剪、奖励和优化。
相较于 GRPO,GSPO 在以下方面展现出突出优势:
-
强大高效:GSPO 具备显著更高的训练效率,并且能够通过增加计算获得持续的性能提升;
-
稳定性出色:GSPO 能够保持稳定的训练过程,并且根本地解决了混合专家(Mixture-of-Experts,MoE)模型的 RL 训练稳定性问题;
-
基础设施友好:由于在序列层面执行优化,GSPO 原则上对精度容忍度更高,具有简化 RL 基础设施的诱人前景。
PAI-ChatLearn 强化学习框架介绍
ChatLearn是阿里云人工智能平台 PAI 推出高性能一体化强化学习框架,第一时间支持并复现了 GSPO 的强化学习训练过程。PAI-ChatLearn具备如下几个优势:
- 易用性
通过计算图构建的方式,支持用户只需要封装几个函数就可以实现不同种类强化学习算法训练。同时ChatLearn 支持灵活的资源调度机制,支持各模型的资源独占或复用,通过系统调度策略支持高效的串行/并行执行和高效的显存共享。
- 高性能
支持Sequence Packing、Sequence Parallel、Group GEMM等加速技术,极大提升了GPU利用率。
- 支持不同推理和训练引擎
支持vLLM和SGLang推理框架以及FSDP和Megatron作为训练框架进行高效稳定的强化学习训练
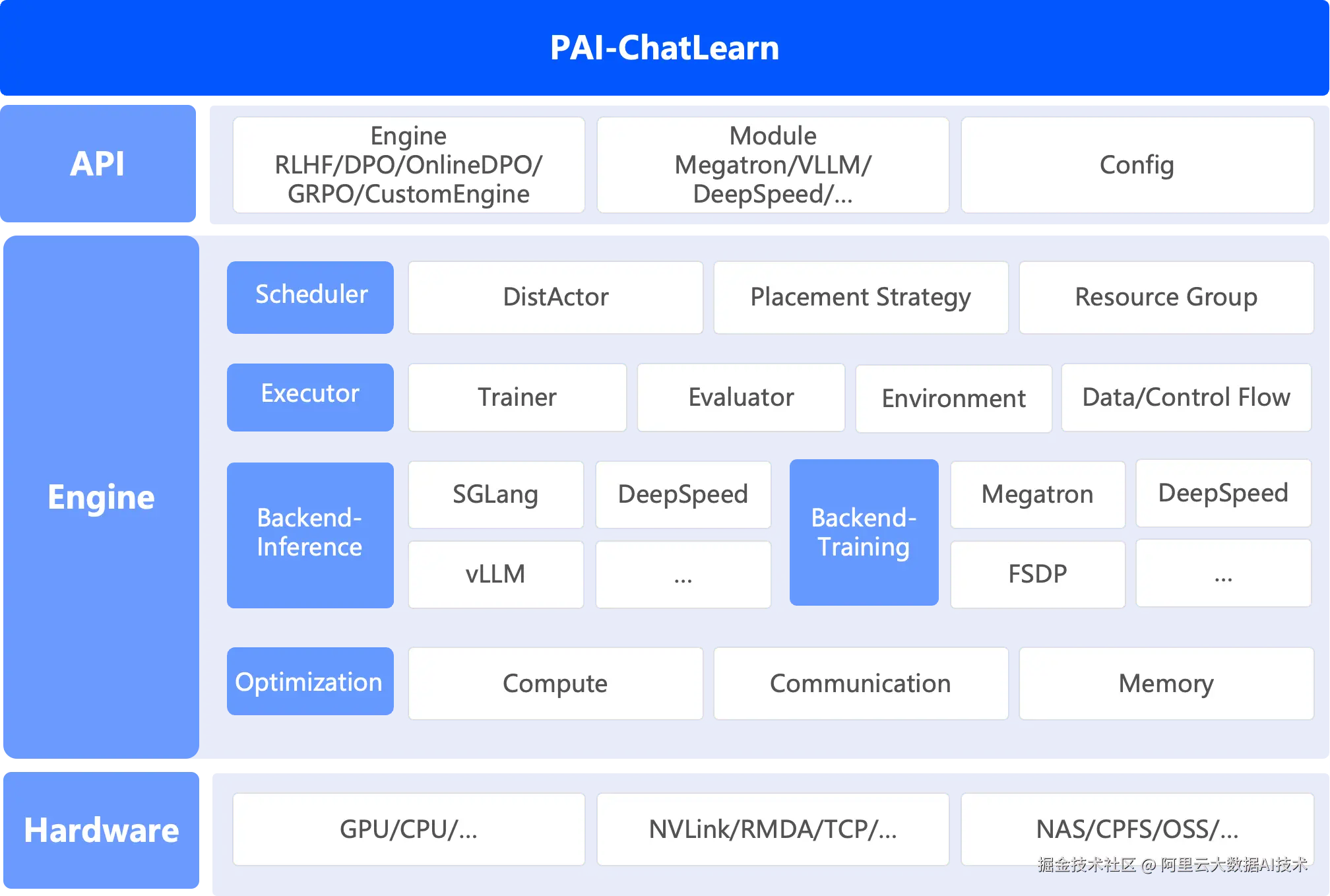
PAI-ChatLearn 整体架构
本文将介绍如何基于 PAI-ChatLearn 框架,在 2机8xH20 上快速开始基于 Megatron-Core 及 vLLM 引擎的GSPO 训练。
端到端流程
GSPO 强化学习训练全过程的复现,将在阿里云人工智能平台 PAI 上完成。PAI 提供云原生的 AI 分布式训练平台 PAI-DLC 和交互式建模 PAI-DSW,为开发者和企业提供灵活、稳定、易用和高性能的大模型开发、训练环境,支持快速完成 GSPO 全过程复现。
Step 1:环境配置
- Docker镜像准备
在 PAI-DLC 或 PAI-DSW 复现 GSPO 全过程,填写如下镜像地址,启动实例:
bash
dsw-registry.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312可以使用 vpc 地址来加速镜像拉取速度,请根据实例所在region修改镜像地址。以上海 Region的 PAI-DSW实例为例,使用如下镜像
dsw-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312
若在非PAI的环境中使用可直接拉取如下公网镜像地址进行实验:
dsw-registry.cn-shanghai.cr.aliyuncs.com/pai-training-algorithm/chatlearn:torch2.6.0-vllm0.8.5-ubuntu24.04-cuda12.6-py312
- 代码准备
bash
git clone https://github.com/alibaba/ChatLearn.git
wget https://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/csrc/Pai-Megatron-Patch.tar
tar -xvf Pai-Megatron-Patch.tarStep 2:数据&模型准备
以MATH-lighteval数据集作为示例,完成数据集下载和模型准备。
css
cd ChatLearn
# download dataset
mkdir -p dataset
modelscope download --dataset AI-ModelScope/MATH-lighteval --local_dir dataset/MATH-lighteval
# preprocess dataset
python chatlearn/data/data_preprocess/math_lighteval.py --input_dir dataset/MATH-lighteval --local_dir dataset/MATH-lighteval
# download model weight
modelscope download --model Qwen/Qwen3-30B-A3B --local_dir pretrained_models/Qwen3-30B-A3BStep 3:模型转换
使用下述脚本,将Qwen3-30B-A3B的Huggingface格式的模型转换到 MCore 格式。
bash
CHATLEARN_ROOT=$(pwd)
cd ../Pai-Megatron-Patch/toolkits/distributed_checkpoints_convertor
bash scripts/qwen3/run_8xH20.sh \
A3B \
${CHATLEARN_ROOT}/pretrained_models/Qwen3-30B-A3B \
${CHATLEARN_ROOT}/pretrained_models/Qwen3-30B-A3B-to-mcore \
false \
true \
bf16Step 4:训练
运行以下命令开始 GSPO 强化学习训练。
bash
cd ${CHATLEARN_ROOT}
bash scripts/train_mcore_vllm_qwen3_30b_gspo.sh实验结果
我们在MATH-lighteval上对比了GRPO与GSPO两种算法的收敛效果。代表 GSPO 和 GRPO 的两条曲线都呈明显的上升趋势,说明随着训练的进行,两种方法在该任务上的性能都在稳步提升。同时,GSPO 的曲线持续位于 GRPO 上方,反映出 GSPO 相对于基线方法在收敛上具有一定优势。
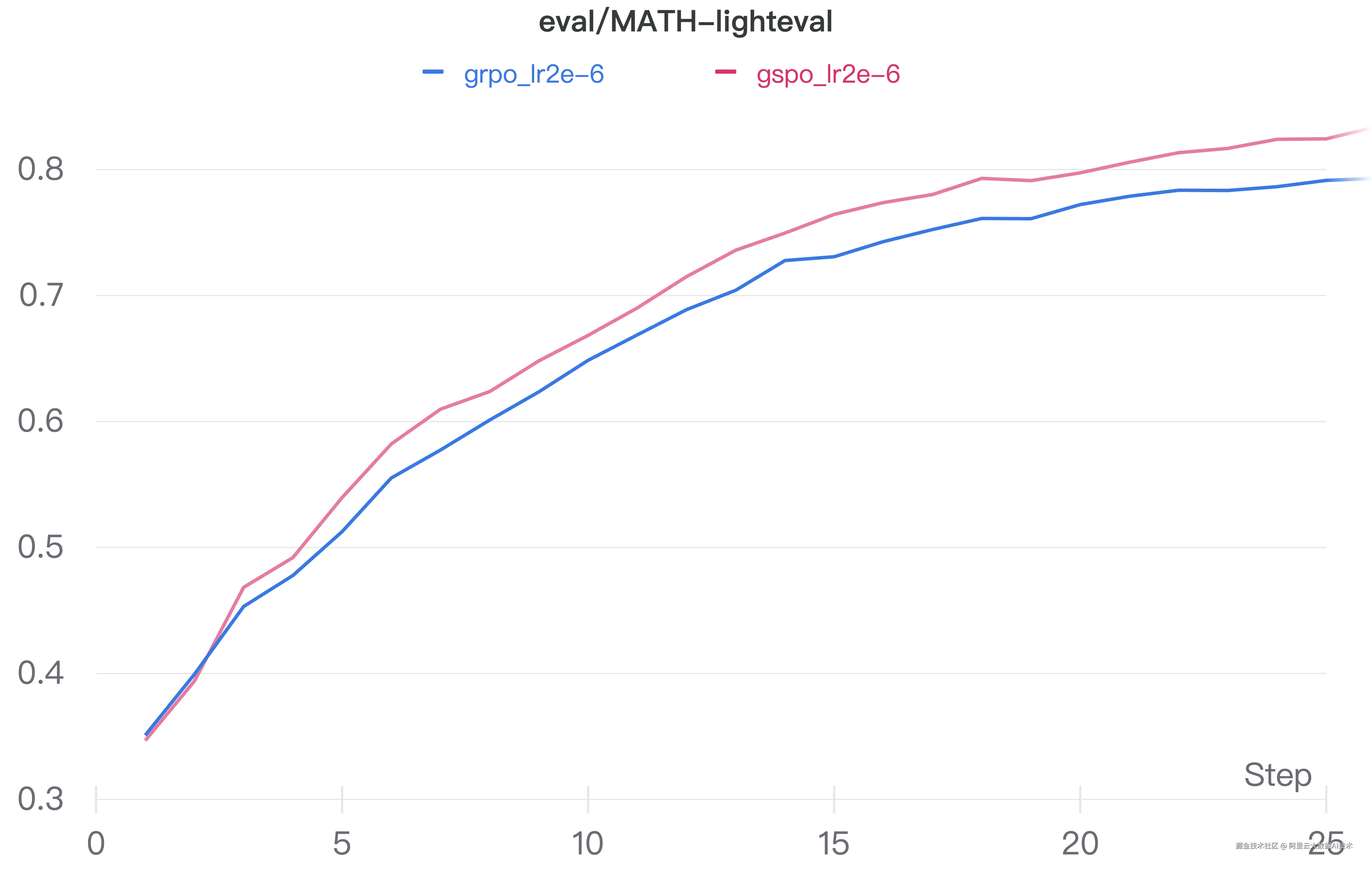
GRPO与GSPO两种算法的收敛效果
对于两组实验的实际clip比例,我们能得到与论文量级接近的结果。
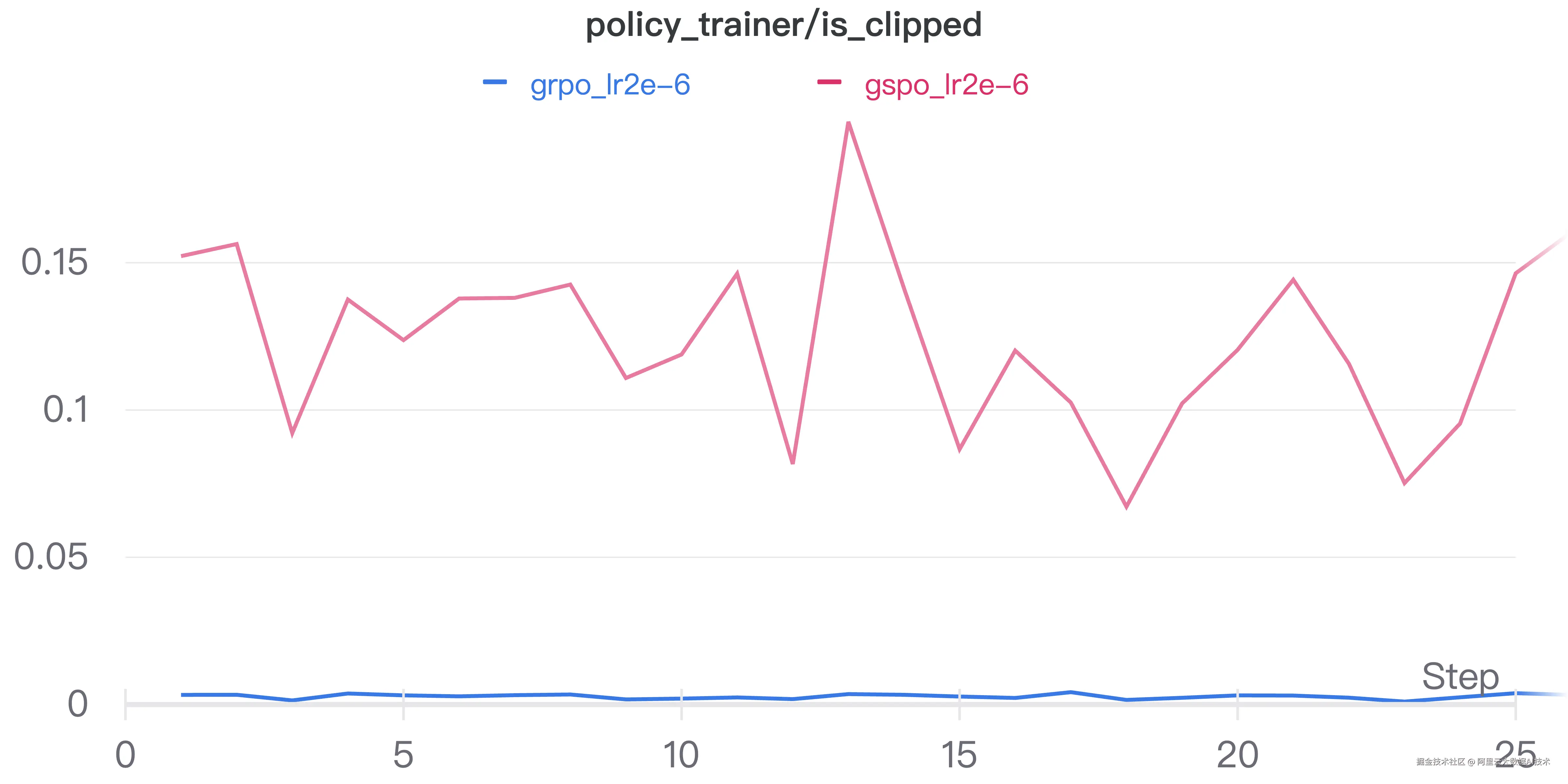
结语
在大模型蓬勃发展的今天,阿里云人工智能平台 PAI 提供围绕大模型全生命周期的平台能力支持,将持续推出在强化学习、模型蒸馏、数据预处理等方向的最佳实践和技术解读。诚邀您共同探索企业级AI工程化的最佳实践,获取智能化转型的核心技术密钥。