实现基本排序算法
- [1. 常用的排序算法简介](#1. 常用的排序算法简介)
- [2. 上机要求](#2. 上机要求)
- [3. 上机环境](#3. 上机环境)
- 4.程序清单(写明运行结果及结果分析)
-
- [4.1 程序清单](#4.1 程序清单)
-
- [4.1.1 头文件 sort.h 内容如下:](#4.1.1 头文件 sort.h 内容如下:)
- [4.1.2 实现文件 sort.cpp 内容如下:](#4.1.2 实现文件 sort.cpp 内容如下:)
- [4.1.3 源文件 main.cpp 内容如下:](#4.1.3 源文件 main.cpp 内容如下:)
- [4.2 实现展效果示](#4.2 实现展效果示)
- 5.上机体会
1. 常用的排序算法简介
- 冒泡排序
冒泡排序是一种简单的排序算法,通过重复地遍历要排序的列表,比较相邻的元素并交换它们的位置,直到没有需要交换的元素为止。冒泡排序的时间复杂度为 O(n²),适用于小规模数据。 - 选择排序
选择排序通过每次从未排序的部分中选择最小(或最大)的元素,将其放到已排序部分的末尾。选择排序的时间复杂度为 O(n²),适用于小规模数据。 - 插入排序
插入排序通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序的时间复杂度为 O(n²),适用于小规模或部分有序的数据。 - 快速排序
快速排序是一种分治算法,通过选择一个"基准"元素,将数组分为两部分,一部分小于基准,另一部分大于基准,然后递归地对这两部分进行排序。快速排序的平均时间复杂度为 O(n log n),适用于大规模数据。 - 归并排序
归并排序也是一种分治算法,通过将数组分成两半,分别对它们进行排序,然后将排序后的两半合并。归并排序的时间复杂度为 O(n log n),适用于大规模数据。 - 堆排序
堆排序利用堆这种数据结构进行排序,通过构建最大堆或最小堆,将堆顶元素与末尾元素交换,然后调整堆,重复此过程直到排序完成。堆排序的时间复杂度为 O(n log n),适用于大规模数据。
..................
2. 上机要求
编写一个程序,实现排序的相关运算,并完成如下功能:
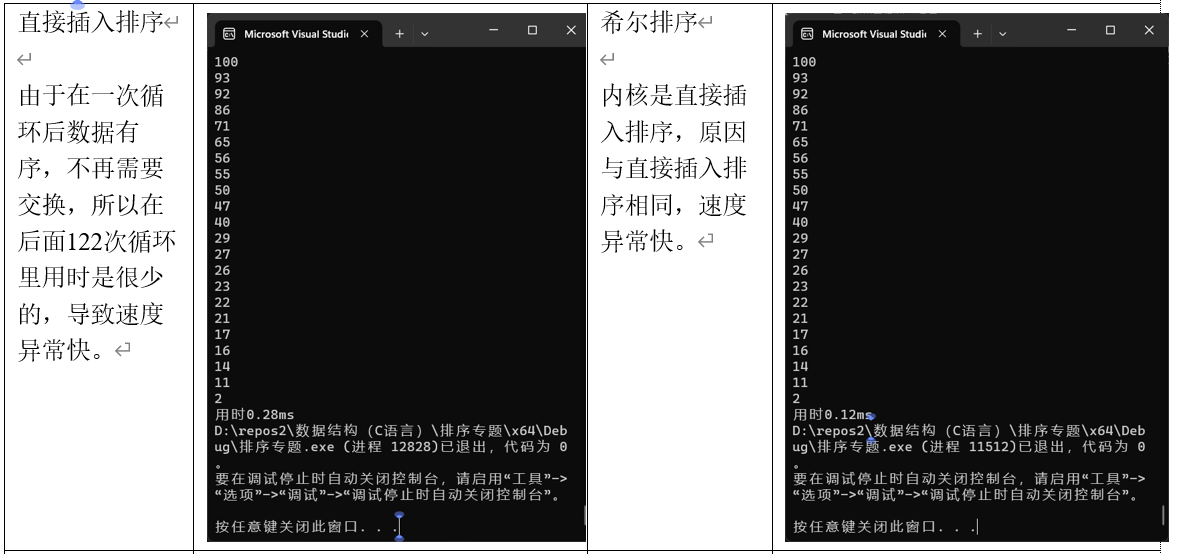
(1)直接插入排序
(2)希尔排序
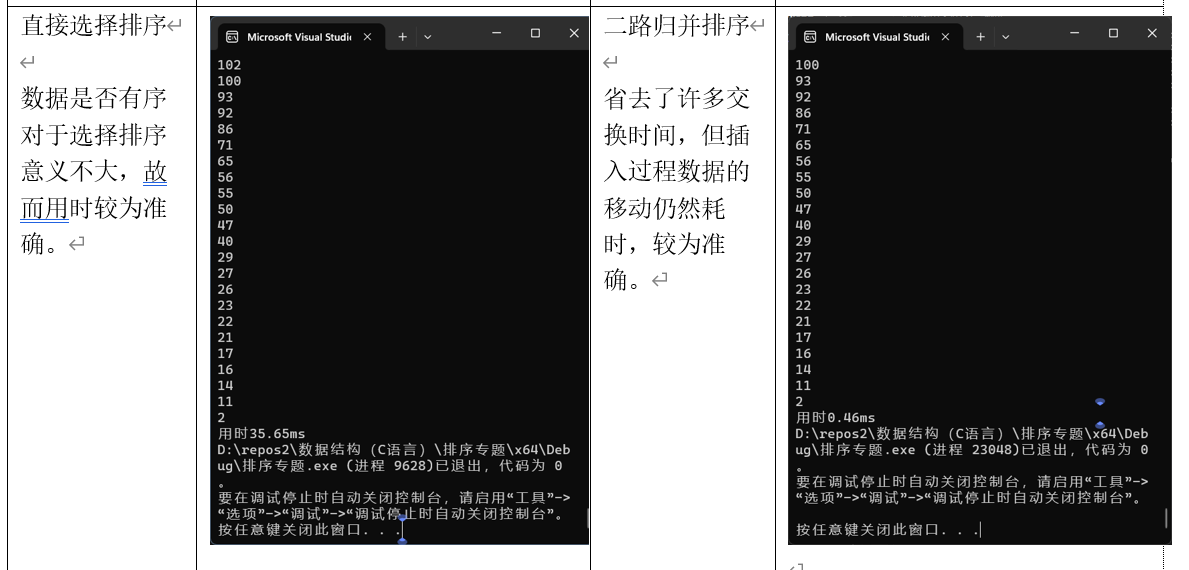
(3)直接选择排序
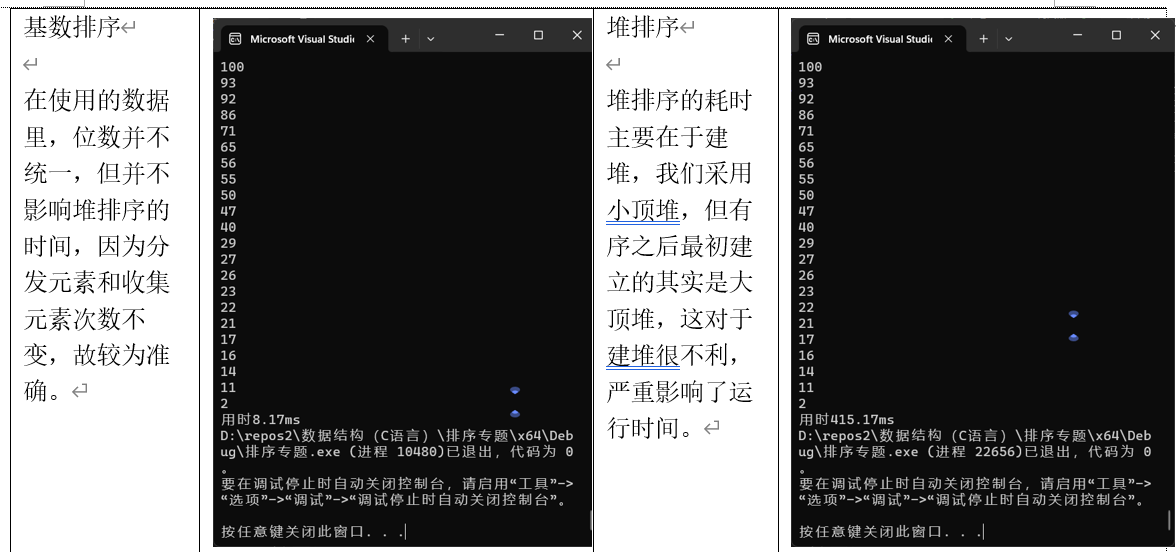
(4)堆排序
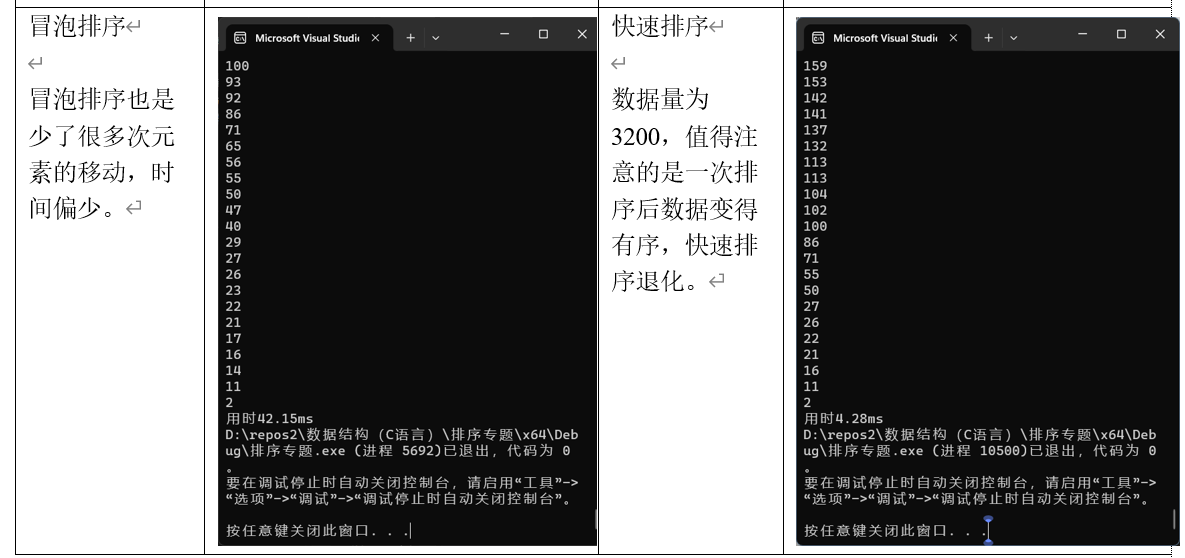
(5)冒泡排序
(6)快速排序
(7)二路归并排序
(8)基数排序
3. 上机环境
visual studio 2022
Windows11 家庭版 64位操作系统
4.程序清单(写明运行结果及结果分析)
4.1 程序清单
4.1.1 头文件 sort.h 内容如下:
cpp
#pragma once
#include<stdio.h>
#include<malloc.h>
#include<stdlib.h>
#include<iostream>
//采用从大到小的顺序
typedef int Data;
//交换两个元素(值交换)
void swap(Data* a, Data* b);
//直接插入排序
void Sort_insert(Data* arr,int len);
//希尔排序
void Sort_shell(Data* arr,int len,int* way,int size);
void Sort_jump(Data* arr, int len, int jump); //shell sort 内置函数
//直接选择排序,每次确定两个元素
void Sort_choose(Data* arr, int len);
//堆排序
void Sort_heap(Data* arr, int len);
void min_down(Data* arr, int index); //一次遍历 arr 数组 将最小元素放在index中
int Lcd(int index); //index 节点"左子树"
int Rcd(int index); //index 节点"右子树"
int Pat(int index); //index 节点"双亲"
//冒泡排序
void Sort_bubble(Data* arr, int len);
//快速排序
void Sort_quick(Data* arr, int low,int high);
//利用二路归并排序的想法将一个数组排序
void Sort_merge(Data* arr,Data* tmp, int low, int high);
void Merge(Data* arr, Data* tmp, int start, int mid, int end); //Sort_merge内置函数
//基数排序,需要用链表结构以提升时间,节约空间
void Sort_bucket(Data* arr, int len,int exp);
void distribute_collect(Data* arr, int len,int exp); //发到筒里去,收回去
typedef struct Node {
Data data;
struct Node* next;
}node, * pnode;
void push(node* aim, Data data);
Data pop(node* aim);4.1.2 实现文件 sort.cpp 内容如下:
cpp
#include"sort.h"
#include<math.h>
void swap(Data* a, Data* b) {
Data c = *a;
*a = *b;
*b = c;
}
void Sort_insert(Data* arr, int len){
for (int i = 1; i < len; i++) {
int tmp = arr[i];
for (int j = i-1; j >=0; j--) {
if (arr[j] < tmp) arr[j + 1] = arr[j];
else { arr[j+1] = tmp; break; }
if (j == 0)arr[j] = tmp;
}
}
}希尔排序实现:
希尔排序(Shell Sort)是一种基于插入排序的算法,通过将数组分成多个子序列进行排序,逐步减少子序列的长度,最终完成整个数组的排序。以下是希尔排序的实现步骤:
- 选择增量序列
希尔排序的核心是选择一个增量序列(gap sequence),用于将数组分成多个子序列。常见的增量序列有希尔原始序列(n/2, n/4, ..., 1)或更高效的序列如Hibbard序列、Sedgewick序列等。
cpp
void Sort_shell(Data* arr, int len, int* way, int size){
for (int i = 0; i < size; i++) {
Sort_jump(arr, len, way[i]);
}
}
//arr 就是选择的序列- 分组插入排序
根据选定的增量序列,将数组分成若干子序列,对每个子序列进行插入排序。随着增量逐渐减小,子序列的长度逐渐增加,最终当增量为1时,整个数组被当作一个子序列进行插入排序。
cpp
void Sort_jump(Data* arr, int len, int jump){
for (int i = 1; i < len; i++) {
int tmp = arr[i];
for (int j = i - jump; j >= 0; j-=jump) {
if (arr[j] < tmp) arr[j + jump] = arr[j];
else { arr[j + jump] = tmp; break; }
if (j <jump)arr[j] = tmp;
}
}
}选择排序
cpp
void Sort_choose(Data* arr, int len){
int maxflag = 0;
int minflag = 0;
for (int i = 0; i < len; i++) {
maxflag = i;
minflag = len - 1 - i;
for (int j = i; j <= len - 1 - i; j++) {
if (arr[maxflag] < arr[j])maxflag = j;
if (arr[minflag] > arr[j])minflag = j;
}
swap(&arr[i], &arr[maxflag]);
if (i == minflag) minflag = maxflag;
swap(&arr[len - 1 - i], &arr[minflag]);
}
}堆排序
堆排序通过构建一个最大堆或最小堆,将堆顶元素(最大或最小)与堆的最后一个元素交换,然后调整剩余元素使其重新满足堆的性质,重复这一过程直到所有元素有序。
- Sort_heap 函数:这是堆排序的主函数,负责对整个数组进行排序。它从数组的最后一个元素开始,逐个调用 min_down 函数来调整堆。
cpp
void Sort_heap(Data* arr, int len){
for (int i = len - 1; i >= 0; i--) {
min_down(arr, i);
}
}- min_down 函数:该函数用于调整堆,确保从指定索引开始的子树满足最小堆的性质。它通过比较父节点和子节点的值,并在必要时交换它们的位置。
cpp
void min_down(Data* arr, int index) {
if (Pat(index) >= 0) {
int pos = Pat(index);
while (pos>=-1) {
if (arr[Lcd(pos)] < arr[pos]&&Lcd(pos)<=index) swap(&arr[Lcd(pos)], &arr[pos]);
if (arr[Rcd(pos)] < arr[pos]&&Rcd(pos)<=index) swap(&arr[Rcd(pos)], &arr[pos]);
pos--;
}
swap(&arr[index], &arr[0]);
}
}- Lcd 和 Rcd 函数:这两个函数分别用于计算给定索引的左子节点和右子节点的索引。
cpp
int Lcd(int index){
return 2 * index + 1;
}
int Rcd(int index){
return 2 * index + 2;
}- Pat 函数:该函数用于计算给定索引的父节点索引。
cpp
int Pat(int index){
return (index - 1) / 2;
}冒泡排序
cpp
void Sort_bubble(Data* arr, int len){
for (int i = 0; i < len; i++) {
for (int j = i + 1; j < len; j++) {
if (arr[i] < arr[j])swap(&arr[i], &arr[j]);
}
}
}快速排序
快速排序是一种高效的排序算法,采用分治法策略。其基本思想是通过选择一个"标杆"元素(通常称为"pivot"),将数组分为两部分:一部分小于标杆,另一部分大于标杆。然后递归地对这两部分进行排序。
cpp
void Sort_quick(Data* arr, int low, int high){
int flag = low; //标杆元素下标
if (low == high) return;
for (int i = flag + 1; i <= high; i++) {
if (arr[flag] >= arr[i])continue;
if (arr[flag] < arr[i]) {
swap(&arr[flag + 1], &arr[i]);
swap(&arr[flag], &arr[flag + 1]);
flag++;
}
}
if (flag > low) Sort_quick(arr, low, flag - 1);
if (flag < high) Sort_quick(arr, flag + 1, high);
}归并排序
Sort_merge 函数是归并排序的递归部分。它将数组 arr 从 start 到 end 的部分分成两个子数组,分别对这两个子数组进行排序,然后调用 Merge 函数将两个有序的子数组合并。
Merge 函数负责将两个有序的子数组合并成一个有序的数组。它使用两个指针 i 和 j 分别指向两个子数组的起始位置,比较两个指针所指向的元素,将较小的元素放入临时数组 tmp 中。最后,将临时数组中的内容复制回原数组 arr。
cpp
void Sort_merge(Data* arr, Data* tmp, int start, int end){
int mid;
if (start < end) {
mid = (start + end) / 2;
Sort_merge(arr, tmp, start, mid);
Sort_merge(arr, tmp, mid+1, end);
Merge(arr, tmp, start, mid, end);
}
}
void Merge(Data* arr, Data* tmp,int start, int mid, int end){
int move = start;
int i = start;
int j = mid + 1;
while (i!=mid+1 && j!= end+1) {
if (arr[i] > arr[j]) {
tmp[move++] = arr[i++];
}
else {
tmp[move++] = arr[j++];
}
}
while (i != mid + 1) { tmp[move++] = arr[i++]; }
while (j != end + 1) { tmp[move++] = arr[j++]; }
for (i = start; i <= end; i++) {
arr[i] = tmp[i];
}
}桶排序
桶排序(Bucket Sort)是一种分布式排序算法,它将元素分配到有限数量的桶中,然后对每个桶中的元素进行排序,最后将桶中的元素按顺序合并。以下是对代码的详细解析和优化建议。
Sort_bucket函数通过循环调用 distribute_collect 函数,对数组进行多次排序。exp 参数表示排序的轮数,通常与数据的位数相关。
cpp
void Sort_bucket(Data* arr, int len, int exp){
for (int i = 1; i <= exp; i++) {
//printf("exp=%d: \n", i);
distribute_collect(arr, len, i);
}
}
void distribute_collect(Data* arr, int len,int exp){
pnode bucket = (pnode)malloc(10 * sizeof(node));
for (int i = 0; i < 10; i++) {
bucket[i].next = NULL;
}
int lab = 0;
for (int i = len-1; i >=0; i--) { //对到每个元素 从大到小排序就要从小到大塞进去 反之反之
lab = arr[i];
for (int j = 0; j < exp - 1; j++) lab /= 10;
lab %= 10; //找到桶的下标
push(&bucket[lab], arr[i]); //塞到桶里去
//printf("push %d to lab %d\n", arr[i],lab);
}
//收回来
int index = 0;
for (int i = 9; i >= 0; i--) {
while (bucket[i].next != NULL) {
arr[index++] = pop(&bucket[i]);
}
}
}
void push(node* aim, Data data){
node* fresh = (node*)malloc(sizeof(node));
fresh->next = NULL;
fresh->data = data;
fresh->next = aim->next;
aim->next = fresh;
}
Data pop(node* aim){
pnode tmp = aim->next;
Data ret = aim->next->data;
aim->next = tmp->next;
free(tmp);
return ret;
}4.1.3 源文件 main.cpp 内容如下:
cpp
#include"sort.h"
//#define size 10000
#define size 3200
#define filename "testdata.txt"
#define tm 123
//注意,在进行快速排序的时候,由于递归深度限制,对于给出的数据量有一个限制
//对于我自己生成的数据,Sort_quick极端情况为3218个数据。
//在实际操作中,Sort_quick数据量应控制在3200以下以确保运行稳定。
//在多次重复排序过程中,由于在后续重复中数据已经排好顺序,快速排序尚且不占优势。
int main() {
FILE* fp;
fopen_s(&fp, filename, "r");
Data* arr = new Data[size];
for (int i = 0; i < size; i++) {
if (fp)fscanf_s(fp, "%6d", &arr[i]);
}
clock_t start = clock();
Data* ret = NULL;
for (int i = 0; i < tm; i++) {
//Sort_insert(arr, size);
//int way[7] = { 203,101,47,23,7,3,1 };
//Sort_shell(arr, size, way, 7);
//Sort_choose(arr, size);
//Sort_quick(arr, 0, size-1);
//Data* tmp = new Data[size];
//Sort_merge(arr, tmp, 0, size - 1);
//Sort_bucket(arr, size, 5);
//Sort_heap(arr, size);
}
clock_t end = clock();
double during = difftime(end, start) / tm;
for (int i = 0; i < size; i++) {
printf_s("%d\n", arr[i]);
}
printf_s("用时%.2fms", during);
return 0;
}4.2 实现展效果示
取消注释对应的代码段,将size 定义成10000(快速排序除外),对排序时间进行考察,给出一些现象产生的原因。
5.上机体会
我的收获主要包括:在上理论课之前,我对于排序算法的理解尚且不到位,就写了一些相关的排序算法,然而在很多地方都忽视了优化问题,直到理论课上完,才重新审视了代码的不足,实现了可读性的增强和基本原理的改进。同样的,对于堆排序时间为什么这么长也是在理论课之后才找到了答案,这也提醒我,不同的排序算法在不同的情况下具有不同的性能。通过实验,可以比较不同算法在处理相同数据集时的执行时间和效率,从而了解它们的相对性能,通过对关键参数的选取,例如枢轴量,增量数组,也更体会到好的算法应当由良好的数学分析而得到。数据结构也会对对算法性能产生影响:排序算法通常需要使用一些数据结构来辅助操作,如数组、链表等。不同的数据结构对算法的性能也会有影响。