第一部分:什么是超参数?为什么要调优?
一、参数 vs 超参数(Parameter vs Hyperparameter)
| 类型 | 定义 | 举例 | 是否通过训练自动学习? |
|---|---|---|---|
| 参数(Parameter) | 是模型在训练过程中通过反向传播自动学习到的变量 | 权重(Weights)、偏置(Biases) | 是 |
| 超参数(Hyperparameter) | 是在训练开始前由人工指定的控制模型结构或训练方式的变量 | 学习率、Batch Size、网络层数等 | 否 |
一句话理解:
参数是模型自动"学"的,超参数是你手动"设"的。
二、为什么超参数调优如此重要?
超参数对训练过程的影响巨大。一个合理的超参数组合可能让模型快速收敛、泛化能力强;而不合适的设置可能导致:
-
模型不收敛
-
过拟合 或欠拟合
-
训练速度极慢
-
浪费大量资源与时间
举例说明:
-
学习率太大 ➜ loss 震荡甚至发散
-
学习率太小 ➜ loss 降得极慢,浪费时间
-
网络太深 ➜ 训练困难,可能过拟合
-
Batch Size 太小 ➜ 收敛不稳定;太大 ➜ 内存吃紧
三、超参数调优的目标
调优的目标是找到一组最优超参数组合 ,使得模型在验证集上表现最优(即泛化能力强),而不是仅仅在训练集上表现好。
评估标准可能包括:
-
Accuracy(分类任务)
-
mIoU、Dice(分割任务)
-
Loss 曲线收敛速度
-
参数/资源效率(比如在一定内存限制下的最好结果)
四、超参数分类示意图
超参数
│
┌────────────────────┼─────────────────────┐
│ │ │
模型结构超参数 优化器超参数 训练过程超参数
(例如层数、宽度) (例如学习率、动量) (例如BatchSize、Epoch)五、为什么不能"一次性设好"?
-
模型复杂非线性:超参数之间有复杂的相互作用(例如:Batch Size 和学习率不是独立的)。
-
任务差异:不同任务需要的超参数不同,例如图像分类 vs 图像分割。
-
数据集变化:数据大小、类别不均衡性都会影响超参数效果。
-
计算资源限制:硬件条件约束下无法盲目使用大模型、大Batch。
六、小结
| 重点回顾 |
|---|
| 参数是学出来的,超参数是设出来的 |
| 不同超参数影响训练不同方面(结构、优化、效率) |
| 超参数调优的目标是提升模型泛化性能 |
| 一个合理的超参数组合可能带来质变的性能提升 |
第二部分:常见的超参数类型
深度学习中涉及大量超参数,我们可以从三个维度来进行分类讲解:
| 分类维度 | 包含超参数 |
|---|---|
| 模型结构相关 | 网络层数、每层宽度、激活函数等 |
| 优化器相关 | 学习率、动量、权重衰减、调度器等 |
| 训练过程相关 | Batch Size、Epoch、Dropout、正则化等 |
一、模型结构相关超参数
网络层数(Depth)
-
定义:网络的"深度",即堆叠了多少层神经网络。
-
作用:
-
更深的网络可以学习更复杂的特征。
-
但过深会引发梯度消失/爆炸问题,训练困难。
-
-
经验:
-
小数据集或简单任务,浅网络(如3~5层)更稳妥。
-
大数据集(如ImageNet)上可以使用 ResNet50/101 等深层网络。
-
-
技巧:
-
使用残差连接(ResNet)来训练更深的模型。
-
在医学图像中,U-Net 结构的深度一般设置在4~5层左右。
-
每层宽度(Width)
-
定义:每一层神经元(或卷积通道)的数量。
-
影响:
-
控制模型的表达能力。
-
太少容易欠拟合,太多可能过拟合且计算成本大。
-
-
经验调节:
-
卷积神经网络中,宽度通常从浅层的 64 逐渐加倍(如 64→128→256)。
-
分类问题中,全连接层常用如 512、1024 等神经元。
-
激活函数(Activation Function)
-
常见选项:
-
ReLU:目前最常用,简单高效。 -
Leaky ReLU/PReLU:解决 ReLU 死亡问题。 -
Sigmoid:饱和慢,较少使用。 -
Tanh:比 Sigmoid 好些,但仍有梯度问题。
-
-
实践建议:
-
默认使用 ReLU 或 Leaky ReLU。
-
对于输出层:
-
分类:Softmax(多类),Sigmoid(二分类)
-
分割:Sigmoid(二类掩膜),Softmax(多类掩膜)
-
-
二、优化器相关超参数
学习率(Learning Rate)
-
训练中最关键的超参数,影响每一步参数更新的"幅度"。
-
通常是调优的第一优先项。
-
值设得不合适可能:
-
太小 → 训练慢,陷入局部最优;
-
太大 → Loss 震荡甚至发散。
-
-
典型值:
-
SGD:1e-2 ~ 1e-3
-
Adam:1e-3 ~ 1e-4
-
-
建议:
- 使用学习率调度器(如StepLR、CosineAnnealing)。
动量(Momentum / β1 / β2)
-
用于平滑梯度更新,防止震荡。
-
在不同优化器中的形式:
-
SGD + Momentum:动量系数通常为 0.9。
-
Adam:β1 一般为 0.9,β2 一般为 0.999。
-
-
不建议轻易更改,除非你很熟悉优化器行为。
权重衰减(Weight Decay / L2 正则化)
-
作用:防止过拟合,引入对权重大小的惩罚项。
-
常设值:1e-5 ~ 1e-4。
-
默认建议加上,可以提高泛化能力。
学习率调度器(LR Scheduler)
-
作用:在训练过程中动态调整学习率。
-
常用策略:
-
StepLR: 每隔N个epoch乘以一个γ -
CosineAnnealingLR: 余弦退火 -
ReduceLROnPlateau: 根据验证集Loss下降情况自动调整
-
-
建议:
- 推荐使用
CosineAnnealingLR+ warmup 起步。
- 推荐使用
三、训练过程相关超参数
Batch Size
-
决定每次梯度更新使用多少样本。
-
大小影响:
-
小 Batch(如 16、32):更噪声,收敛稳定性差但泛化强。
-
大 Batch(如 128+):训练快但容易过拟合。
-
-
实践建议:
-
根据显存能力尽量调大,但通常不超过 256。
-
注意学习率要跟 Batch Size 协调调整(比如大 Batch → 可增大学习率)。
-
Epoch 数
-
控制整个数据集被"看过"的轮数。
-
太小 → 欠拟合,太大 → 过拟合。
-
通常结合 EarlyStopping 或验证集监控动态决定训练时长。
Dropout 比例
-
防止过拟合的一种策略。
-
建议值:0.3 ~ 0.5(不要超过0.7)
-
不建议在卷积层用 Dropout(会破坏局部特征结构),常用于全连接层。
正则化强度(L1 / L2)
-
L2(权重衰减)更常见,L1 可用于稀疏建模。
-
多数情况下,设置一个小的 L2(如1e-4)即可。
四、数据增强和预处理相关超参数
-
例如图像翻转概率、亮度变化范围、裁剪尺寸等。
-
合适的数据增强不仅能提升泛化能力,还能防止过拟合。
-
医学图像中,增强不能过强,要考虑语义一致性。
小结
| 超参数类别 | 推荐调优顺序 |
|---|---|
| 学习率 | 最重要,优先调 |
| Batch Size | 次优先,影响显存 |
| 网络结构 | 先简单→复杂,逐步加深 |
| Dropout / 正则化 | 防过拟合常用手段 |
| LR Scheduler | 搭配学习率共同调整 |
第三部分:超参数调优方法论(策略、流程与工具)
一、手动调参的经典策略(适合初期模型开发)
原则:单变量控制 + 分阶段调优
不要一次改多个超参数。保持其他不变,逐个尝试,观察其对训练过程和验证集效果的影响。
推荐调优顺序:
| 步骤 | 优先级 | 超参数类型 | 说明 |
|---|---|---|---|
| ① | 高 | 学习率 | 首先确定模型是否能正常收敛 |
| ② | 高 | Batch Size | 尽可能大,但不爆显存为宜 |
| ③ | 中 | 优化器选择 | 如 Adam、SGD+Momentum |
| ④ | 中 | LR Scheduler | 控制收敛速度和效果 |
| ⑤ | 低 | 网络结构 | 小到大试试(层数/通道数) |
| ⑥ | 低 | Dropout、正则化 | 控制过拟合 |
实战技巧举例:
-
判断学习率设得好不好:
-
Loss 快速下降 → ✅
-
Loss 抖动大或直接发散 → 学习率太大 ❌
-
Loss 降得慢、像"爬坡"一样缓慢 → 学习率太小 ❌
-
-
调整 Batch Size 后需要改学习率!
-
经验公式:
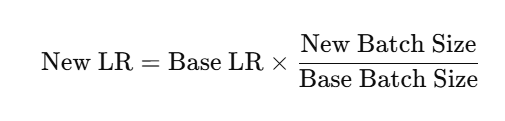
-
二、网格搜索(Grid Search)与随机搜索(Random Search)
这两个是传统的自动化调参策略,适用于搜索空间不大的情况。
网格搜索(Grid Search)
-
穷举式搜索所有组合,例如:
learning_rates = [0.01, 0.001, 0.0001] batch_sizes = [32, 64, 128] optimizers = [SGD, Adam] -
总共要跑 3×3×2 = 18 次实验。
-
优点:简单直接,能找出局部最优组合。
-
缺点:计算资源消耗大,不适合维度高或范围广的超参数。
随机搜索(Random Search)
- 在设定的搜索范围内随机采样组合,减少计算量。
研究表明,在高维空间中,随机搜索通常比网格搜索更高效(Bergstra & Bengio, 2012)。
- 举例:随机采样 10 组学习率+Batch组合,而不是穷举全部组合。
三、贝叶斯优化(Bayesian Optimization)
原理简介:
-
构建一个超参数 → 验证效果之间的"代理模型",如高斯过程回归(Gaussian Process),预测某组合的效果。
-
然后在代理模型中选择最可能带来提升的超参数组合继续试验。
-
是一种智能搜索策略,相比随机或网格更节省时间与资源。
工具推荐:
-
Optuna
-
支持分布式、多目标优化、可视化。
-
非常适合深度学习超参数调优。
-
后面我可以手把手教你用它调 UNet 或 CNN。
-
四、学习率自动查找(Learning Rate Finder)
让模型自动找到最适合的学习率区间!
PyTorch 中的实现(如 fastai 的 lr_find()):
-
从一个极小学习率开始,指数增长;
-
绘制 Learning Rate vs Loss 曲线;
-
选取 loss 急剧下降前的最小值处作为起始学习率。
五、一周期学习率策略(One Cycle Policy)
学习率不是越低越好,而是在训练初期升高、中期降低,能获得更好泛化效果。
-
论文:Super-Convergence(2018) by Leslie Smith
-
支持:
torch.optim.lr_scheduler.OneCycleLR -
特别适合图像分类、分割等任务。
六、逐步调优流程总结图(推荐收藏)
python
↓ 定义模型结构
↓
设置初始学习率、Batch Size
↓
↻ 调整学习率找收敛区间(LR Finder)
↓
↻ 调整 Batch Size + 学习率联动
↓
↻ 调整优化器参数(Momentum、Decay)
↓
↻ 调度器(Cosine / Step)选择
↓
↻ 网络结构细节优化(层数/通道数)
↓
↻ 加入 Dropout、正则化、EarlyStopping
↓
↻ 自动搜索工具(Optuna / Ray Tune)小结:调参三大黄金建议
-
控制变量法永不过时: 每次只改一个,效果才可解释。
-
调参顺序讲策略: 先优化能显著提升效果的(学习率、Batch)。
-
自动化工具是加速器: 用得好能帮你节省大量资源。
代码部分
学习率查找器(LR Finder)
python
# 先安装:pip install torch-lr-finder
from torch_lr_finder import LRFinder
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=1e-7, momentum=0.9)
lr_finder = LRFinder(model, optimizer, criterion, device=device)
lr_finder.range_test(train_loader, end_lr=1, num_iter=100)
lr_finder.plot() # 画出Loss随LR变化曲线
lr_finder.reset() # 恢复模型参数通过观察曲线,找到 loss 降得最快且开始发散前的那个学习率,作为训练起始学习率。
Batch Size与学习率联动调节
python
base_batch_size = 64
base_lr = 0.01
new_batch_size = 128
new_lr = base_lr * (new_batch_size / base_batch_size)
print(f"当 batch_size={new_batch_size} 时,建议学习率设置为 {new_lr}")一周期学习率策略(One Cycle Policy)
python
from torch.optim.lr_scheduler import OneCycleLR
optimizer = optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = OneCycleLR(optimizer, max_lr=0.1, steps_per_epoch=len(train_loader), epochs=10)
for epoch in range(10):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
scheduler.step() # 学习率自动调整
if batch_idx % 100 == 0:
print(f"Epoch {epoch} Batch {batch_idx} Loss: {loss.item():.4f} LR: {scheduler.get_last_lr()[0]:.6f}")网格搜索(Grid Search)
python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 简单CNN模型定义(同前)
class SimpleCNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, 3, padding=1)
self.pool = nn.MaxPool2d(2)
self.fc = nn.Linear(16*16*16, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 数据加载
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 网格搜索超参数空间
learning_rates = [0.01, 0.001]
momentums = [0.8, 0.9]
batch_sizes = [32, 64]
best_loss = float('inf')
best_params = {}
for lr in learning_rates:
for momentum in momentums:
for batch_size in batch_sizes:
print(f"训练参数: LR={lr}, Momentum={momentum}, Batch Size={batch_size}")
# 重新加载数据集以调整batch size
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
model.train()
total_loss = 0
batches = 0
for batch_idx, (data, target) in enumerate(train_loader):
if batch_idx > 50: # 为节约时间,只训练部分batch
break
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
batches += 1
avg_loss = total_loss / batches
print(f"平均损失: {avg_loss:.4f}")
if avg_loss < best_loss:
best_loss = avg_loss
best_params = {'lr': lr, 'momentum': momentum, 'batch_size': batch_size}
print(f"最佳参数组合: {best_params},最优平均损失: {best_loss:.4f}")随机搜索(Random Search)
python
import random
learning_rates = [0.01, 0.001, 0.0001, 0.005]
momentums = [0.7, 0.8, 0.9, 0.95]
batch_sizes = [32, 64, 128]
num_trials = 10 # 随机尝试次数
best_loss = float('inf')
best_params = {}
for _ in range(num_trials):
lr = random.choice(learning_rates)
momentum = random.choice(momentums)
batch_size = random.choice(batch_sizes)
print(f"训练参数: LR={lr}, Momentum={momentum}, Batch Size={batch_size}")
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
model.train()
total_loss = 0
batches = 0
for batch_idx, (data, target) in enumerate(train_loader):
if batch_idx > 50:
break
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
batches += 1
avg_loss = total_loss / batches
print(f"平均损失: {avg_loss:.4f}")
if avg_loss < best_loss:
best_loss = avg_loss
best_params = {'lr': lr, 'momentum': momentum, 'batch_size': batch_size}
print(f"随机搜索最佳参数组合: {best_params},最优平均损失: {best_loss:.4f}")贝叶斯优化(Bayesian Optimization)
python
import optuna
def objective(trial):
lr = trial.suggest_loguniform('lr', 1e-5, 1e-1)
momentum = trial.suggest_uniform('momentum', 0.7, 0.99)
batch_size = trial.suggest_categorical('batch_size', [32, 64, 128])
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model = SimpleCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=momentum)
model.train()
total_loss = 0
batches = 0
for batch_idx, (data, target) in enumerate(train_loader):
if batch_idx > 50:
break
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
batches += 1
avg_loss = total_loss / batches
return avg_loss
study = optuna.create_study(direction='minimize')
study.optimize(objective, n_trials=20)
print("贝叶斯优化最佳参数:", study.best_params)
print("最佳平均损失:", study.best_value)| 方法 | 优缺点 | 代码复杂度 |
|---|---|---|
| 网格搜索 | 简单、完全搜索;计算资源消耗大 | 最简单 |
| 随机搜索 | 计算资源节省;随机覆盖;适合高维参数 | 简单 |
| 贝叶斯优化 | 智能高效搜索;适合复杂空间 | 需要库支持,稍复杂 |
关于贝叶斯优化我自己的理解:经过多次训练后,软件库中的方法 会记录不同参数的效果, 形成一个类似曲线的形式, 观察参数变化和模型性能之间的关系后 有选择的选择下一次测试的参数组合,最终选择出最优的参数组合。