2025.12.11
这篇文章 2026 年发表于《Medical Image Analysis》期刊,由慕尼黑工业大学、帝国理工学院等多机构团队联合完成,核心是对医学图像配准中的正则化方法进行全面综述,提出统一分类体系并指明研究方向。
Title 题目
01
From model based to learned regularization in medical image registration:A comprehensive review
医用图像配准中从基于模型到学习正则化的综合综述
文献速递介绍
02
图像配准在放射治疗和疾病监测等临床应用中至关重要,旨在准确识别图像间的形变。近年来,基于学习的配准方法已成为主流,利用神经网络学习形变模型。然而,配准固有的病态性是一个主要挑战,需要正则化来确保生成的形变具有解剖学和生理学上的合理性。尽管已提出多种正则化方法,但缺乏全面且结构化的综述,这阻碍了不同图像配准应用间方法的潜在转移并限制了领域进展。本综述旨在填补这一空白,首次全面概述了传统和深度学习图像配准中的正则化技术,并提出了基于模型、问题特定和学习型三种主要类别,以期为研究人员提供结构化视图,促进方法转移,并激励对学习型配准中正则化的进一步探索。
Aastract摘要
02
图像配准在医学成像应用中至关重要,例如疾病进展分析或放射治疗计划。其主要目标是通过最小化优化问题来精确捕捉两幅或多幅图像之间的形变。由于其固有的病态性,正则化是推动解决方案趋向解剖学上有意义形变的关键组成部分。本文通过引入一种新颖的分类法,系统地将所提出的正则化方法划分为基于模型、问题特定和学习型三类,从而填补了现有综述的空白。它强调了新兴的学习型正则化领域,该领域利用数据驱动技术自动从数据中推导出形变属性。此外,本综述还探讨了正则化方法从传统配准到基于学习的配准的转移,识别了开放性挑战,并概述了未来的研究方向。通过强调正则化在图像配准中的关键作用,我们希望能激发研究界重新思考现代配准算法中的正则化策略,并进一步探索这一快速发展的领域。
Method 方法
03
本综述详细阐述了医学图像配准中的正则化技术,配准过程通常通过最小化一个包含相似性度量和正则化项的优化问题来实现。正则化项用于约束解空间,确保形变具有所需的属性,如平滑性。正则化可分为显式正则化(作为损失项作用于形变)和隐式正则化(由形变模型参数化产生)。
本文将正则化方法系统地分为三类:第一类是基于模型的正则化,它施加了用户定义的形变先验假设,如平滑性、可逆性、逆一致性、微分同胚、体积保持以及基于物理原理的约束,这些方法通常全局统一应用。第二类是问题特定的正则化,它结合了数据的先验知识,如空间信息(分割图)或生理信息,从而使正则化具有空间适应性,能够处理多结构、器官特定运动(如滑动和周期性运动)以及拓扑变化等特殊配准问题。第三类是学习型正则化,它通过数据驱动技术,利用机器学习或深度学习模型直接从训练数据中学习形变属性,常具有空间适应性,包括学习局部平滑性、可行形变空间和测试时间自适应正则化。这三类方法所包含的先验信息量从基于模型到学习型逐渐增加。
Discussion讨论
04
基于模型的正则化是配准技术的基础,旨在确保全局平滑性、防止折叠和保持拓扑。然而,过度平滑可能损害精度,微分同胚在实践中仍可能因数值误差出现轻微折叠,物理启发式方法常依赖于理想化的组织特性和随意参数选择。问题特定的正则化通过整合数据知识和局部形变特性,提供了更真实的建模能力,但其成功应用往往依赖于精确的先验分割图或边界定义,且其为特定场景定制的性质限制了泛化能力。学习型正则化在灵活性和自动适应性方面具有优势,能自动调整局部正则化强度,有效缓解过度平滑,但需要大量高质量的训练数据,且其泛化能力受限于训练数据所捕获的形变模式。此外,神经网络的"黑箱"性质带来了可解释性挑战。
文章指出,未来研究应解决从传统方法到学习型方法转移的空白,尤其是在物理启发和问题特定正则化方面。应减少对全局平滑正则化的过度依赖,转向更灵活、问题特定的策略,以适应现实世界的复杂形变和拓扑变化。评估应扩大解剖学多样性,开发更复杂的评估指标来衡量局部形变属性。同时,问题特定的正则化向临床实践的转化仍面临挑战,如对线性滑动边界、单一刚性区域等简化条件的假设,以及对个体特异性因素的适应。因此,开发能够自动适应个体配准问题的鲁棒且可泛化的正则化方法至关重要。作者鼓励社区在算法开发中仔细评估应用背景、下游任务、解剖区域、数据和辅助信息的可用性以及计算限制,选择最合适的正则化策略。
Conclusion结论
05
正则化是图像配准的根本组成部分,确保导出的形变符合物理和解剖合理性。本综述系统地将文献中提出的正则化方法分为三类:(i) 基于模型的正则化,使用先验假设;(ii) 问题特定的正则化,整合先验数据知识;(iii) 学习型正则化,从训练数据中推导形变属性。每类方法都解决了配准中不同的挑战,并推动了医学图像配准的持续发展。
基于模型的正则化仍然是传统和基于学习的配准算法的基础。其手工设计的性质虽有利于解释性,但全局假设常限制其对临床数据中复杂异质形变的建模能力。问题特定的正则化通过利用空间和上下文知识解决了这些限制,适用于滑动运动、拓扑变化和器官特异性形变等具有挑战性的场景。然而,其对高质量空间信息的依赖和针对特定配准问题的设计会限制其可伸缩性和泛化能力。学习型正则化利用数据驱动技术从训练数据中学习形变属性,提供了更灵活的解决方案,例如学习低维可行形变空间和在测试时利用高级架构进行正则化自适应。其主要挑战在于可解释性有限以及需要额外的训练数据集。
展望未来,结合基于模型的解释性和鲁棒性与学习型方法的适应性的混合正则化方法特别有前景。同时,全自动化正则化适应和通用方法在未来可能变得日益重要。本综述强调,亟需(i) 更多样化的开放获取配准数据集,以代表更广泛的解剖和病理条件,以及(ii) 改进的评估指标,以评估局部形变属性,这些对于推动领域发展同样至关重要。通过解决这些研究空白,正则化可以在提高临床实践中图像配准的准确性、可靠性和适用性方面发挥更大的作用。
Results结果
06
本综述系统地概述了医学图像配准中三种主要类别的正则化方法及其特点:
-
基于模型的正则化:这类方法通过预设假设来强制形变属性,如平滑性(通过扩散正则化或B样条隐式实现)、可逆性(通过惩罚负雅可比行列式来防止折叠)、逆一致性(确保正向和反向形变互为逆)、循环一致性(确保组合形变后图像与原始图像相似)、微分同胚(保证形变平滑、可逆且保持拓扑结构)、体积保持(通过惩罚雅可比行列式偏离1)和物理启发式方法(将图像建模为弹性或粘性流体)。这些方法在全球范围内统一应用,构成了许多配准技术的基础。
-
问题特定的正则化:这类方法利用数据特异性知识(如分割图、器官生理或临床背景)来适应局部形变特征,通常是空间自适应的。主要应用于:多结构配准(通过结构特异性平滑、物理属性或局部刚性来保持拓扑结构),器官特异性配准(如处理滑动运动通过各向异性扩散或区域配准,以及处理周期性运动通过确保循环一致性),和拓扑变化配准(应对病变区域的增长/收缩或缺失区域,通过成本函数掩膜或变态配准框架)。
-
学习型正则化:这类方法通过数据驱动技术直接从训练数据中学习形变属性,旨在减少手动设计和参数调整。具体包括:学习局部平滑性和不连续性(利用神经网络学习自适应平滑核或电视正则化),学习可行形变空间(通过PCA模型学习线性子空间或通过自编码器/GANs学习非线性流形),以及学习测试时间自适应正则化(通过超网络在测试时动态调整正则化权重)。这些方法提供了更高的灵活性和自动适应性,代表了医学图像配准领域的一个快速发展方向。
Figure 图
07
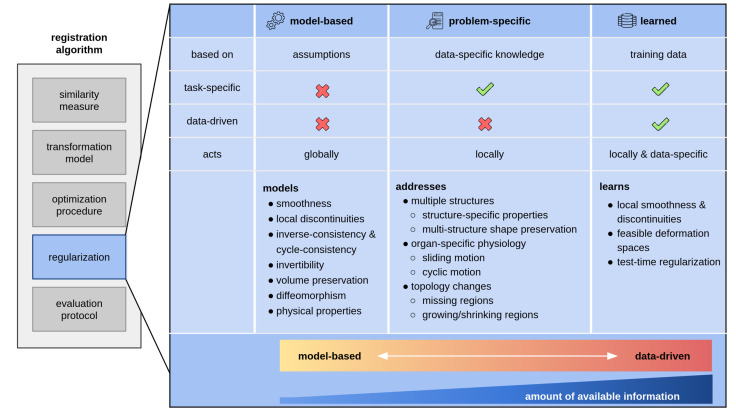
图1. 正则化是成功配准算法的重要组成部分。我们识别出三类主要的正则化方法:(I)基于模型的正则化,对形变施加先验假设;(II)问题特定正则化,考虑额外的数据知识,例如分割图或生理信息形式的空间信息;(III)学习型正则化,通过机器学习或深度学习模型从训练数据中获取形变属性。正则化中包含的先验信息量从类别I到III增加。大多数问题特定和学习型正则化方法都源于基于模型的正则化。
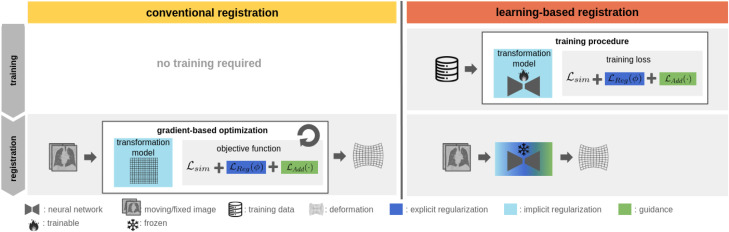
图2. 显式与隐式正则化:在传统(左)和基于学习的(右)医学图像配准中整合正则化方法的概述。在这两种情况中,正则化都可以通过正则化损失项(深蓝色)显式实现,或者通过变换模型的参数化(浅蓝色)隐式实现。此外,引导损失项(绿色)可以推动配准达到期望的解决方案。对于基于学习的配准,在训练期间应用的正则化在推理时固有地捕获在网络参数中。
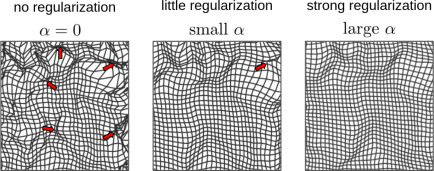
图3.于模型的正则化------平滑性和折叠:不同程度的平滑正则化,由正则化参数α(见式1)控制。粉色箭头表示折叠区域。随着α的增加,应用更多的平滑,观察到的折叠减少。
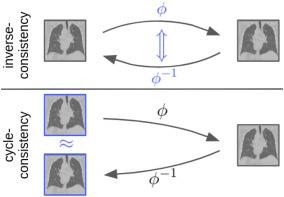
图4.基于模型的正则化------逆一致性与循环一致性:逆一致性确保正向和反向形变互为逆。循环一致性确保正向-反向形变后的图像与原始图像相似。
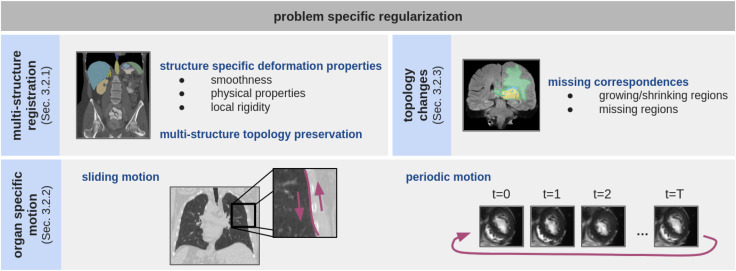
图5.问题特定正则化:根据配准问题和数据,可能会出现不同的形变属性。通过数据特定信息,例如分割图,正则化可以在局部考虑合适的形变属性。图像取自Learn2Reg腹部CT Xu et al., 2016、NLST(National Lung Screening Trial Research Team 2011)、BraTS Baid et al., 2021和ACDC Bernard et al., 2018数据集。
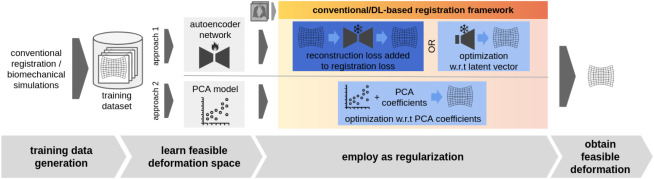
图6.学习型正则化------学习形变空间:可以从训练数据集中学习代表可行形变集合的低维形变空间。文献中发现两种学习型形变空间的方法:(i) PCA模型和(ii) 自编码器网络。一旦训练完成,正则化模型就会嵌入配准框架中,作为显式(深蓝色)或隐式(浅蓝色)正则化。
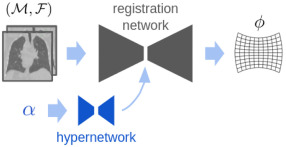
图7.学习型正则化------测试时间正则化:超网络可以允许用户在测试时调整正则化权重。在训练期间,权重是随机采样的。
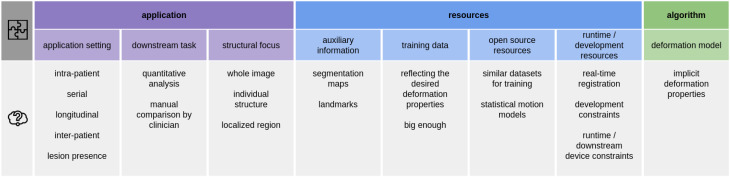
图8.许多因素都会影响正则化方法的选择。对于每个配准问题,都应仔细评估这些因素。选择合适的方法应被视为配准算法开发不可或缺的一部分。