
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
博主简介:努力学习的22级本科生一枚 🌟;探索AI算法,C++,go语言的世界;在迷茫中寻找光芒🌸
博客主页:羊小猪~~-CSDN博客
内容简介:GAN入门案例二(DCGAN),人脸图片 生成为例。
GAN入门简介:GAN难度不小,本文打算更新三篇文章入门GAN,第一篇以知道什么是GAN(判别器、生成器),以手写生成字体为例;第二篇是GAN人脸生成(DCGAN),第三篇是GAN论文精度;
文章目录
简介
🉑 深度卷积对抗网络(Deep Convolutional Generative Adversarial Networks,简称DCGAN)是一种深度学习模型,由生成器(Generator)和判别器(Discriminator)两个神经网络组成。DCGAN结合了卷积神经网络(ConvolutionalNeuralNetworks,简称CNN)和生成对抗网络(Generative Adversarial Networks,简称GAN)的思想,用于生成逼真的图像。
与GAN不同的是,GAN使用的是MLP,而DCGAN使用的是卷积神经网络。
DCGAN原理
DCGAN是GAN的一种改进,核心不同是使用了卷积网络,其模型特点如下:
- 生成器中采用转置卷积扩大了数据维度;
- 出克生成器模型的输出层和判别器模型的输入层,整个对抗网络的其它层上都使用是BN层进行标准化;
- 整个网络由卷积 + 全连接层 组成,且生成器,判别器的输出层也是用了卷积层;
- 在生成器的输出层使用Tanh激活函数 ,其他层使用了ReLU激活函数 ;在判别器上使用了LeakyReLU激活函数。
模型结构
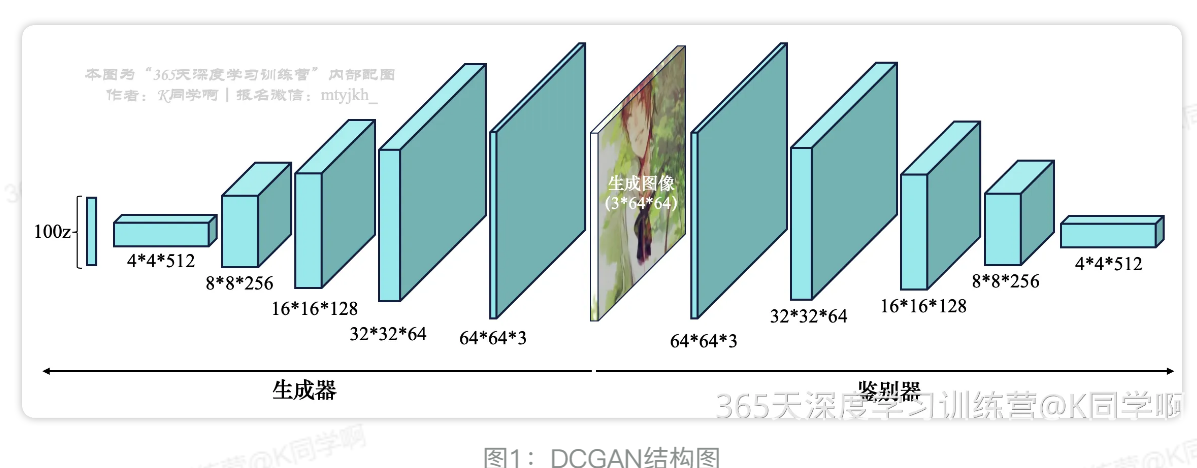
⬅️ 图左边:
- 包含生成器部分;
- 结构:四个转置卷积;
➡️ 图右边:
- 包含判别器;
- 结构:四个卷积层;
⭕️ 部分细节:
4 * 4 * 5代表有 512 个4 * 4的特征图;- 在卷积层和卷积之后分别使用了BN层激活函数ReLU或者LeakyReLU
训练过程简介
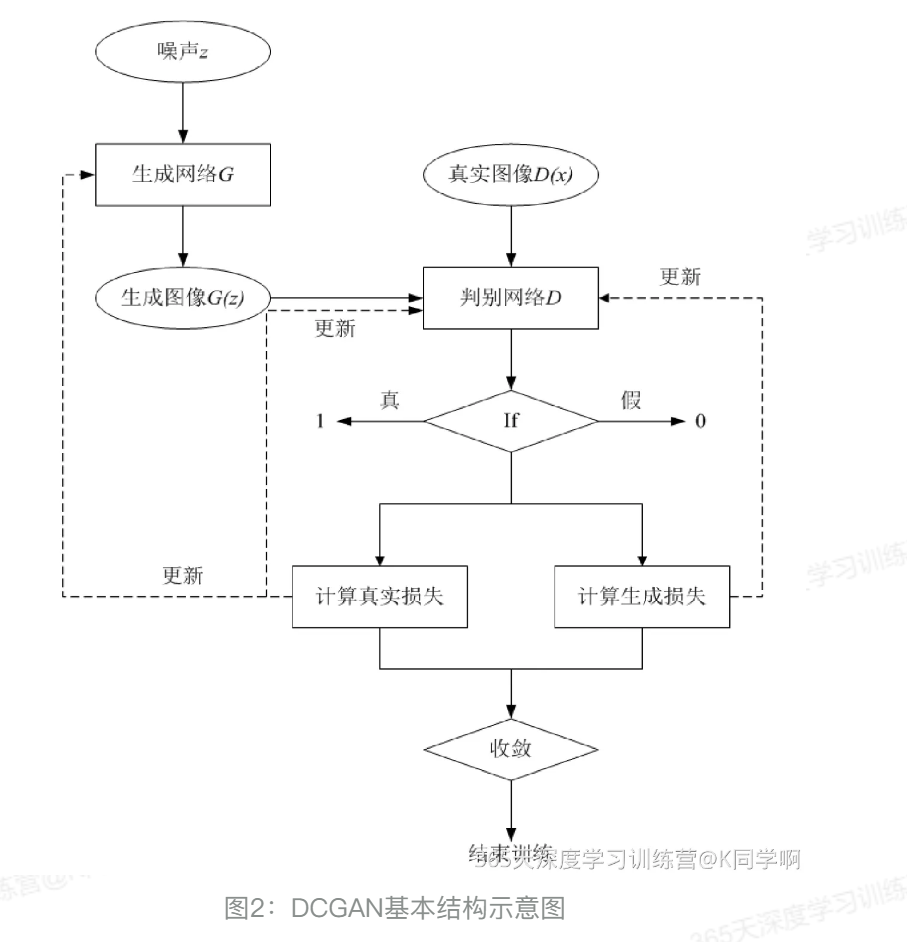
首先接受一个随机噪声,通过该噪声生产图像(G(z) ),判别网络D鉴别这个图片是真的,还是生成器G生成的网络,是真的输出为1,不是输出为0 ,之后鉴别器D和生成器G分别进行净化(原理是:对f期望求导等于对f求导),直到判别器D(G(z)) == 0.5时候停止。
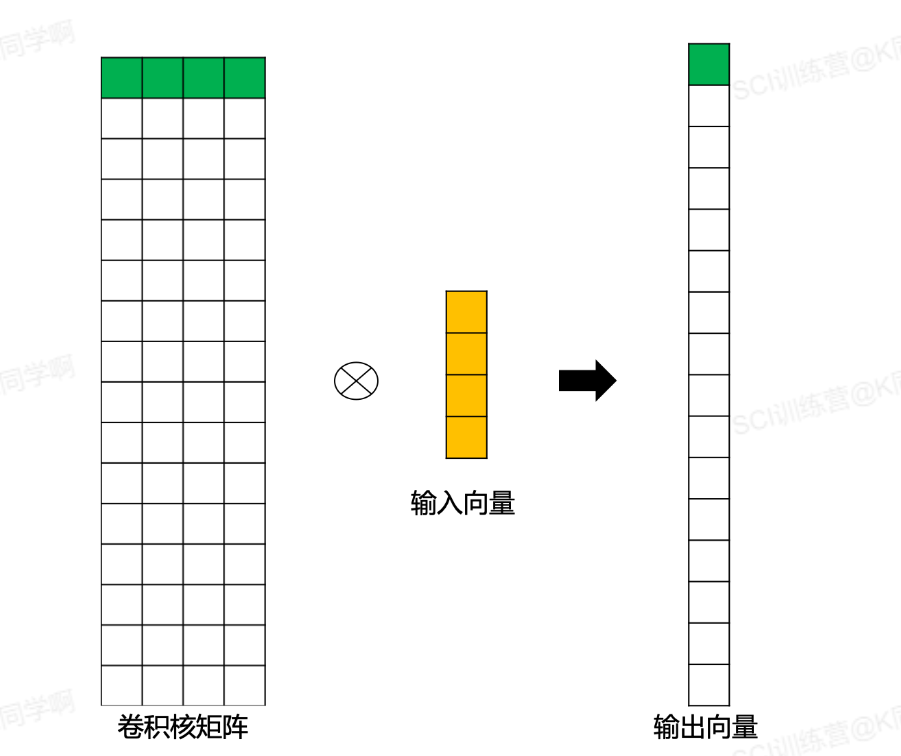
转置卷积
概念
在DCGAN上使用了转置卷积的概念。
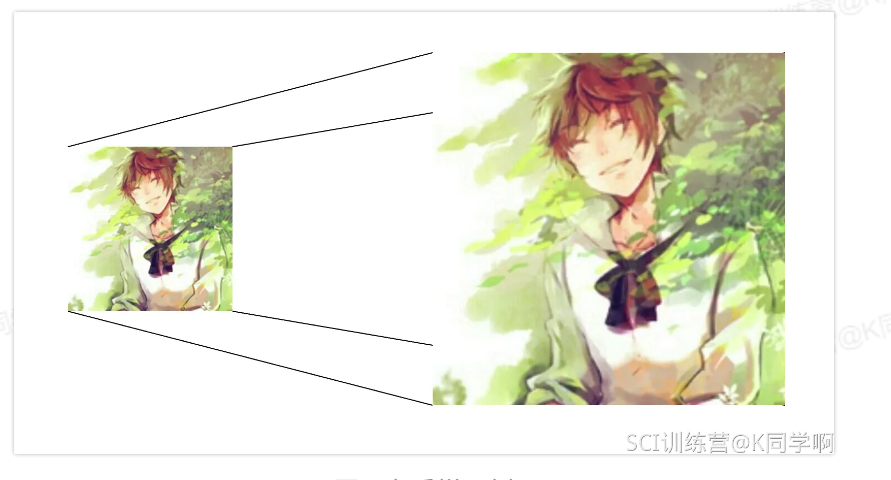
🔖 背景 :在对图像进行卷积的时候,经过多层卷积运算后,输出图片尺寸会变得很小,但是对于GAN这样的模型来说,需要对图片恢复到原来的尺寸大小,这个恢复过程的操作是:由小分辨率到大分辨率映射的操作,也叫做上采样,图如下:
与标准卷积的区别
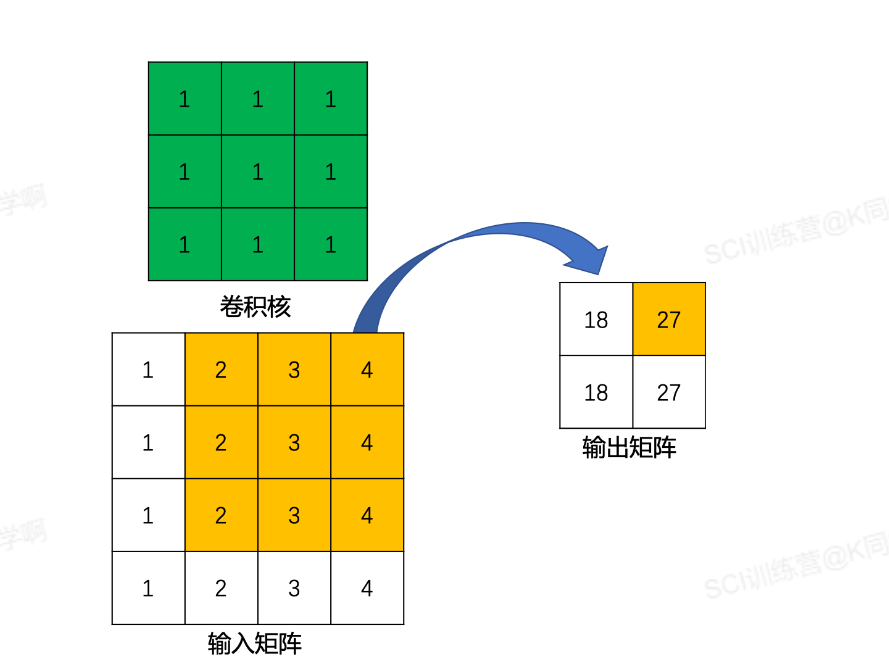
1️⃣ 标准卷积:
以输入4 * 4的矩阵,使用3 * 3卷积核进行卷积运算,步长为1,则用标准卷积运行如下:
👁 数据库的从属关系来看,这个其实就多对一的关系。
2️⃣ 转置卷积:
就是标准卷积的逆过程,如图所示:
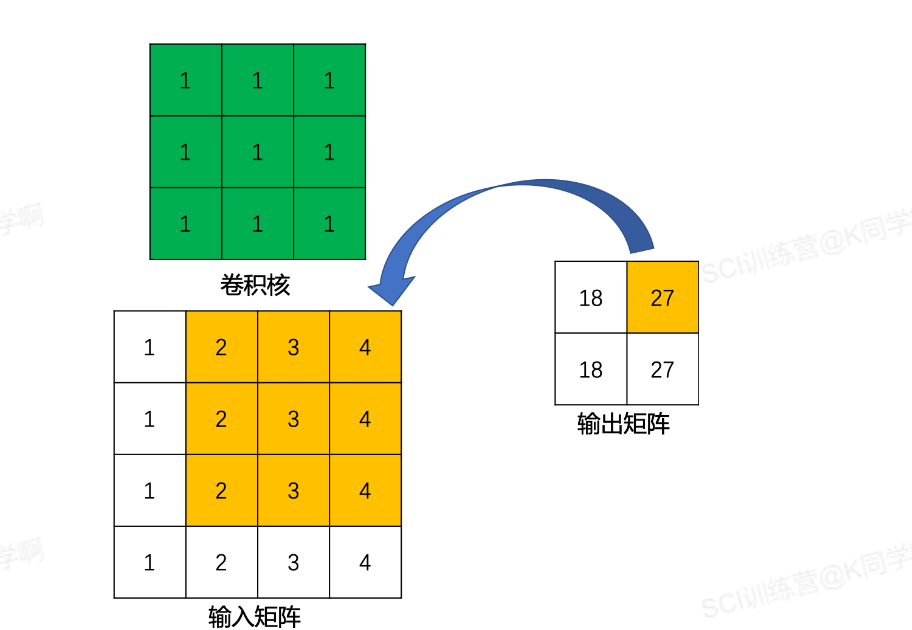
🚯 注意: 卷积操作是不可逆的,所以转置卷积后的卷积不是原来的矩阵,只是保留了相对位置关系。
矩阵运算简介
输入4 * 4 矩阵:
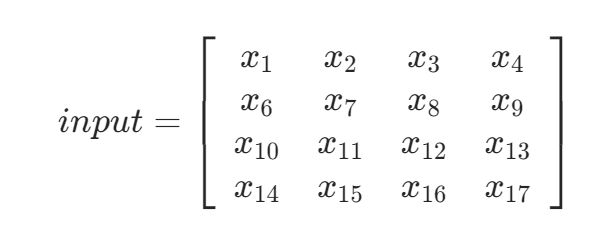
卷积核:
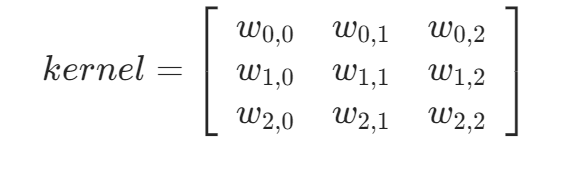
输出:
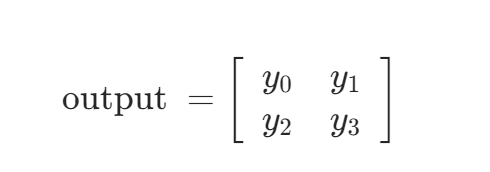
换个表达式:
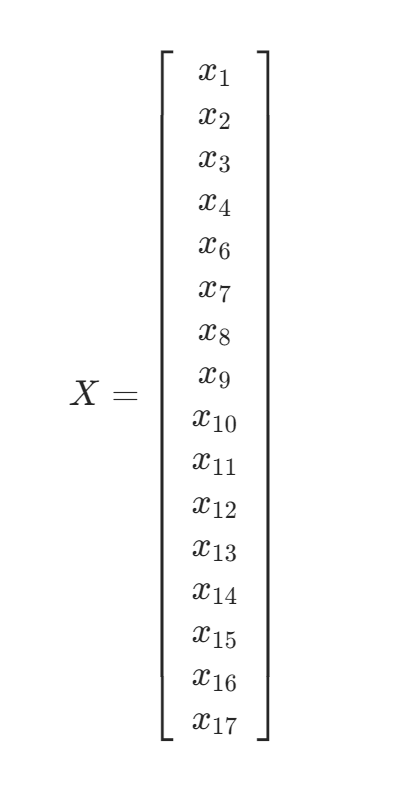
采用公式Y = CX进行运算,得到:

转置卷积就是:
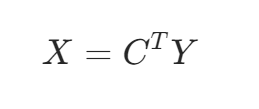
输出:
🚯 注意:这里只是权重形状与原来一致。
具体运算公式参考:卷积操作总结(二)------ 转置卷积(transposed convolution) - 知乎
模型实验
以生成人脸为例。
1、准备工作
1、导入库
python
import torch, random, random, os
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
manualSeed = 999 # 随机种子
random.seed(manualSeed)
torch.manual_seed(manualSeed)
torch.use_deterministic_algorithms(True) # 设置 PyTorch 操作是否必须使用"确定性"算法。也就是说,给定相同的输入,并在相同的软件和硬件上运行时,始终产生相同输出的算法
# 选择设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
devicedevice(type='cuda')2、设置超参数
python
dataroot = "./data/" # 数据路径
batch_size = 128 # 训练过程中的批次大小
image_size = 64 # 图像的尺寸(宽度和高度)
nz = 100 # z潜在向量的大小(生成器输入的尺寸)
ngf = 64 # 生成器中的特征图大小
ndf = 64 # 判别器中的特征图大小
num_epochs = 100 # 训练的总轮数
lr = 0.0002 # 学习率
beta1 = 0.5 # Adam优化器的Beta1超参数3、数据处理定义
python
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.CenterCrop(image_size), # 中心裁剪图,起到数据增强作用
transforms.ToTensor(),
transforms.Normalize( # 数据标准化
(0.5, 0.5, 0.5),
(0.5, 0.5, 0.5),
)
])4、导入数据
python
dataset = dset.ImageFolder(
root = dataroot,
transform=transform
)5、动态加载数据
python
dataloader = torch.utils.data.DataLoader(dataset,
batch_size=batch_size,
shuffle=True,
num_workers=5)6、展示加载图片
python
real_batch = next(iter(dataloader))
plt.figure(figsize=(8, 8))
plt.axis("off")
plt.title("Image")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:24],
padding=2,
normalize=True).cpu(), (1, 2, 0)))<matplotlib.image.AxesImage at 0x7f5c90f0ffb0>

二、定义模型
1、初始化权重
python
# 一般神经网络初始化的权重是随机生产的,这里采用正态分布初始化权重
def weight_init(m):
classname = m.__class__.__name__ # 获取当前层名字
# 卷积层
if classname.find('Conv') != -1:
# 初始化卷积层参数
nn.init.normal_(m.weight.data, 0.0, 0.02) # 均值为0, 标准差为0.02
elif classname.find('BatchNorm') != -1:
# 采用均值1.0, 标准差为0.02
nn.init.normal_(m.weight.data, 1.0, 0.02)
# 偏置数设置为0
nn.init.constant_(m.bias.data, 0)
2、定义生存器
python
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
# 输出为z,经过转置卷积
nn.ConvTranspose2d(nz, ngf * 8, 4, 1, 0, bias=False), # kernel_size:4, stride: 1, padding:0
nn.BatchNorm2d(ngf * 8),
nn.ReLU(inplace=True),
# 输出 (ngf * 8) * 4 * 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 输出 (ngf * 4) * 8 * 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 输出 (ngf * 2) * 16 * 16
nn.ConvTranspose2d(ngf * 2, ngf * 1, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 输出 (ngf) * 32 * 32
nn.ConvTranspose2d(ngf, 3, 4, 2, 1, bias=False),
# 最后通过Tanh激活函数输出
nn.Tanh() # 输出 3 * 64 * 64
)
def forward(self, x):
return self.main(x)
python
# 创建生成器
netG = Generator().to(device)
# 权重出事阿虎
netG.apply(weight_init)
print(netG)Generator(
(main): Sequential(
(0): ConvTranspose2d(100, 512, kernel_size=(4, 4), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): ConvTranspose2d(512, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU(inplace=True)
(9): ConvTranspose2d(128, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(10): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(11): ReLU(inplace=True)
(12): ConvTranspose2d(64, 3, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(13): Tanh()
)
)3、定义判别器
python
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 输入大小为3 x 64 x 64
nn.Conv2d(3, ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出大小为(ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() # 最后通过Sigmoid输出(0, 1)
)
def forward(self, input):
# 将输入通过判别器的主要结构进行前向传播
return self.main(input)
python
netD = Discriminator().to(device)
netD.apply(weight_init)
print(netD)Discriminator(
(main): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(6): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1), bias=False)
(9): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), bias=False)
(12): Sigmoid()
)
)三、模型训练
模型超参数
python
# 损失函数
criterion = nn.BCELoss()
# 创建随机噪声
fixed_noise = torch.randn(64, nz, 1, 1, device=device)
# 定义标签
real_label = 1
fake_label = 0
# 优化器
optimizerD = optim.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))定义模型
这个训练思想和GAN一样:【GAN网络入门系列】一,手写字MINST图片生成-CSDN博客
python
img_list = [] # 用于存储生成的图像列表
G_losses = [] # 用于存储生成器的损失列表
D_losses = [] # 用于存储判别器的损失列表
iters = 0 # 迭代次数
print("Starting Training Loop...") # 输出训练开始的提示信息
# 对于每个epoch(训练周期)
for epoch in range(num_epochs):
# 对于dataloader中的每个batch
for i, data in enumerate(dataloader, 0):
############################
# (1) 更新判别器网络:最大化 log(D(x)) + log(1 - D(G(z)))
###########################
## 使用真实图像样本训练
netD.zero_grad() # 清除判别器网络的梯度
# 准备真实图像的数据
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device) # 创建一个全是真实标签的张量
# 将真实图像样本输入判别器,进行前向传播
output = netD(real_cpu).view(-1)
# 计算真实图像样本的损失
errD_real = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_real.backward()
D_x = output.mean().item() # 计算判别器对真实图像样本的输出的平均值
## 使用生成图像样本训练
# 生成一批潜在向量
noise = torch.randn(b_size, nz, 1, 1, device=device)
# 使用生成器生成一批假图像样本
fake = netG(noise)
label.fill_(fake_label) # 创建一个全是假标签的张量
# 将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake.detach()).view(-1)
# 计算判别器对生成图像样本的损失
errD_fake = criterion(output, label)
# 通过反向传播计算判别器的梯度
errD_fake.backward()
D_G_z1 = output.mean().item() # 计算判别器对生成图像样本的输出的平均值
# 计算判别器的总损失,包括真实图像样本和生成图像样本的损失之和
errD = errD_real + errD_fake
# 更新判别器的参数
optimizerD.step()
############################
# (2) 更新生成器网络:最大化 log(D(G(z)))
###########################
netG.zero_grad() # 清除生成器网络的梯度
label.fill_(real_label) # 对于生成器成本而言,将假标签视为真实标签
# 由于刚刚更新了判别器,再次将所有生成的图像样本输入判别器,进行前向传播
output = netD(fake).view(-1)
# 根据判别器的输出计算生成器的损失
errG = criterion(output, label)
# 通过反向传播计算生成器的梯度
errG.backward()
D_G_z2 = output.mean().item() # 计算判别器对生成器输出的平均值
# 更新生成器的参数
optimizerG.step()
# 输出训练统计信息
if i % 400 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# 保存损失值以便后续绘图
G_losses.append(errG.item())
D_losses.append(errD.item())
# 通过保存生成器在固定噪声上的输出来检查生成器的性能
if (iters % 500 == 0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding=2, normalize=True))
iters += 1Starting Training Loop...
[0/100][0/36] Loss_D: 1.8869 Loss_G: 2.5819 D(x): 0.3308 D(G(z)): 0.3682 / 0.1056
[1/100][0/36] Loss_D: 0.2266 Loss_G: 28.6840 D(x): 0.8953 D(G(z)): 0.0000 / 0.0000
[2/100][0/36] Loss_D: 0.2565 Loss_G: 8.6221 D(x): 0.9336 D(G(z)): 0.0921 / 0.0004
[3/100][0/36] Loss_D: 0.4643 Loss_G: 10.5051 D(x): 0.9456 D(G(z)): 0.2812 / 0.0001
[4/100][0/36] Loss_D: 0.6451 Loss_G: 6.8870 D(x): 0.8453 D(G(z)): 0.2374 / 0.0028
[5/100][0/36] Loss_D: 0.5269 Loss_G: 4.6675 D(x): 0.6969 D(G(z)): 0.0248 / 0.0181
[6/100][0/36] Loss_D: 0.8375 Loss_G: 6.1946 D(x): 0.7593 D(G(z)): 0.3039 / 0.0062
[7/100][0/36] Loss_D: 0.4509 Loss_G: 4.3686 D(x): 0.8115 D(G(z)): 0.1417 / 0.0258
[8/100][0/36] Loss_D: 0.4969 Loss_G: 4.9082 D(x): 0.9155 D(G(z)): 0.2950 / 0.0159
[9/100][0/36] Loss_D: 0.3689 Loss_G: 5.2474 D(x): 0.9276 D(G(z)): 0.2301 / 0.0095
[10/100][0/36] Loss_D: 0.4230 Loss_G: 3.3024 D(x): 0.8301 D(G(z)): 0.1659 / 0.0585
[11/100][0/36] Loss_D: 0.2979 Loss_G: 3.1328 D(x): 0.8981 D(G(z)): 0.1340 / 0.0825
[12/100][0/36] Loss_D: 0.5203 Loss_G: 4.1130 D(x): 0.8386 D(G(z)): 0.2314 / 0.0253
[13/100][0/36] Loss_D: 1.0478 Loss_G: 5.3357 D(x): 0.7259 D(G(z)): 0.4084 / 0.0101
[14/100][0/36] Loss_D: 0.7836 Loss_G: 7.4181 D(x): 0.9172 D(G(z)): 0.4382 / 0.0019
[15/100][0/36] Loss_D: 0.5579 Loss_G: 3.7570 D(x): 0.7360 D(G(z)): 0.0961 / 0.0508
[16/100][0/36] Loss_D: 0.5410 Loss_G: 2.7464 D(x): 0.6822 D(G(z)): 0.0505 / 0.1036
[17/100][0/36] Loss_D: 0.4263 Loss_G: 4.1063 D(x): 0.8128 D(G(z)): 0.1205 / 0.0289
[18/100][0/36] Loss_D: 0.4739 Loss_G: 4.0065 D(x): 0.7164 D(G(z)): 0.0410 / 0.0291
[19/100][0/36] Loss_D: 0.7239 Loss_G: 4.5481 D(x): 0.9182 D(G(z)): 0.3653 / 0.0222
[20/100][0/36] Loss_D: 0.5631 Loss_G: 5.0077 D(x): 0.8747 D(G(z)): 0.2846 / 0.0137
[21/100][0/36] Loss_D: 0.6499 Loss_G: 7.1636 D(x): 0.9443 D(G(z)): 0.3872 / 0.0020
[22/100][0/36] Loss_D: 0.2616 Loss_G: 4.2298 D(x): 0.8964 D(G(z)): 0.1206 / 0.0252
[23/100][0/36] Loss_D: 0.4847 Loss_G: 3.9369 D(x): 0.7611 D(G(z)): 0.0745 / 0.0594
[24/100][0/36] Loss_D: 0.2661 Loss_G: 4.3276 D(x): 0.8885 D(G(z)): 0.1072 / 0.0239
[25/100][0/36] Loss_D: 0.3685 Loss_G: 2.9731 D(x): 0.7833 D(G(z)): 0.0602 / 0.0895
[26/100][0/36] Loss_D: 0.4165 Loss_G: 4.0029 D(x): 0.8167 D(G(z)): 0.1559 / 0.0348
[27/100][0/36] Loss_D: 0.2300 Loss_G: 5.0579 D(x): 0.8658 D(G(z)): 0.0565 / 0.0142
[28/100][0/36] Loss_D: 0.3922 Loss_G: 4.5723 D(x): 0.8222 D(G(z)): 0.1141 / 0.0270
[29/100][0/36] Loss_D: 0.2843 Loss_G: 3.6327 D(x): 0.8901 D(G(z)): 0.1251 / 0.0531
[30/100][0/36] Loss_D: 0.9409 Loss_G: 6.0902 D(x): 0.9569 D(G(z)): 0.4925 / 0.0057
[31/100][0/36] Loss_D: 0.1615 Loss_G: 5.1803 D(x): 0.9514 D(G(z)): 0.0843 / 0.0142
[32/100][0/36] Loss_D: 0.7846 Loss_G: 2.3989 D(x): 0.6010 D(G(z)): 0.0478 / 0.1501
[33/100][0/36] Loss_D: 0.4915 Loss_G: 7.4607 D(x): 0.9538 D(G(z)): 0.3103 / 0.0017
[34/100][0/36] Loss_D: 1.0211 Loss_G: 2.3844 D(x): 0.6222 D(G(z)): 0.2632 / 0.1614
[35/100][0/36] Loss_D: 0.4165 Loss_G: 4.5241 D(x): 0.7586 D(G(z)): 0.0482 / 0.0220
[36/100][0/36] Loss_D: 0.4283 Loss_G: 3.0024 D(x): 0.7725 D(G(z)): 0.0999 / 0.0794
[37/100][0/36] Loss_D: 0.5809 Loss_G: 5.6079 D(x): 0.8320 D(G(z)): 0.2599 / 0.0062
[38/100][0/36] Loss_D: 0.8135 Loss_G: 6.6960 D(x): 0.9783 D(G(z)): 0.4404 / 0.0033
[39/100][0/36] Loss_D: 0.2105 Loss_G: 4.4340 D(x): 0.9234 D(G(z)): 0.1037 / 0.0201
[40/100][0/36] Loss_D: 0.3889 Loss_G: 4.5842 D(x): 0.9535 D(G(z)): 0.2487 / 0.0222
[41/100][0/36] Loss_D: 0.4751 Loss_G: 3.6829 D(x): 0.6941 D(G(z)): 0.0359 / 0.0546
[42/100][0/36] Loss_D: 0.4309 Loss_G: 4.2780 D(x): 0.8851 D(G(z)): 0.2236 / 0.0297
[43/100][0/36] Loss_D: 0.5258 Loss_G: 3.0439 D(x): 0.6636 D(G(z)): 0.0304 / 0.0754
[44/100][0/36] Loss_D: 0.5854 Loss_G: 5.9916 D(x): 0.9200 D(G(z)): 0.3456 / 0.0046
[45/100][0/36] Loss_D: 0.4485 Loss_G: 4.7093 D(x): 0.9180 D(G(z)): 0.2377 / 0.0202
[46/100][0/36] Loss_D: 0.5049 Loss_G: 2.9327 D(x): 0.6890 D(G(z)): 0.0589 / 0.0926
[47/100][0/36] Loss_D: 0.7456 Loss_G: 7.1529 D(x): 0.9342 D(G(z)): 0.4422 / 0.0012
[48/100][0/36] Loss_D: 0.2600 Loss_G: 3.8421 D(x): 0.8626 D(G(z)): 0.0770 / 0.0368
[49/100][0/36] Loss_D: 0.4656 Loss_G: 3.1547 D(x): 0.8227 D(G(z)): 0.1840 / 0.0715
[50/100][0/36] Loss_D: 0.2630 Loss_G: 3.5536 D(x): 0.8393 D(G(z)): 0.0586 / 0.0476
[51/100][0/36] Loss_D: 0.4449 Loss_G: 3.6026 D(x): 0.8140 D(G(z)): 0.1685 / 0.0466
[52/100][0/36] Loss_D: 0.6741 Loss_G: 6.2384 D(x): 0.9302 D(G(z)): 0.3959 / 0.0033
[53/100][0/36] Loss_D: 0.5875 Loss_G: 2.6721 D(x): 0.6714 D(G(z)): 0.0750 / 0.1141
[54/100][0/36] Loss_D: 1.9704 Loss_G: 0.6795 D(x): 0.2418 D(G(z)): 0.0070 / 0.6081
[55/100][0/36] Loss_D: 0.3145 Loss_G: 2.9540 D(x): 0.8570 D(G(z)): 0.1265 / 0.0761
[56/100][0/36] Loss_D: 0.6630 Loss_G: 4.9153 D(x): 0.8334 D(G(z)): 0.2983 / 0.0148
[57/100][0/36] Loss_D: 0.3285 Loss_G: 3.1676 D(x): 0.8303 D(G(z)): 0.1033 / 0.0617
[58/100][0/36] Loss_D: 0.3947 Loss_G: 3.1483 D(x): 0.7713 D(G(z)): 0.0708 / 0.0733
[59/100][0/36] Loss_D: 0.5209 Loss_G: 4.1749 D(x): 0.7374 D(G(z)): 0.1002 / 0.0333
[60/100][0/36] Loss_D: 0.3054 Loss_G: 3.6824 D(x): 0.8604 D(G(z)): 0.1185 / 0.0424
[61/100][0/36] Loss_D: 0.2549 Loss_G: 4.0670 D(x): 0.8902 D(G(z)): 0.1145 / 0.0302
[62/100][0/36] Loss_D: 3.7419 Loss_G: 6.9565 D(x): 0.9940 D(G(z)): 0.9472 / 0.0043
[63/100][0/36] Loss_D: 0.3488 Loss_G: 3.2862 D(x): 0.7781 D(G(z)): 0.0533 / 0.0582
[64/100][0/36] Loss_D: 0.3696 Loss_G: 3.9398 D(x): 0.9231 D(G(z)): 0.2289 / 0.0284
[65/100][0/36] Loss_D: 0.8004 Loss_G: 2.1983 D(x): 0.6810 D(G(z)): 0.2147 / 0.2004
[66/100][0/36] Loss_D: 0.6264 Loss_G: 2.5097 D(x): 0.6260 D(G(z)): 0.0661 / 0.1207
[67/100][0/36] Loss_D: 0.5226 Loss_G: 3.2257 D(x): 0.8381 D(G(z)): 0.2517 / 0.0588
[68/100][0/36] Loss_D: 0.2972 Loss_G: 3.3192 D(x): 0.8948 D(G(z)): 0.1531 / 0.0488
[69/100][0/36] Loss_D: 0.5186 Loss_G: 2.0395 D(x): 0.6698 D(G(z)): 0.0418 / 0.1917
[70/100][0/36] Loss_D: 0.9923 Loss_G: 2.2803 D(x): 0.4902 D(G(z)): 0.0667 / 0.1865
[71/100][0/36] Loss_D: 0.3894 Loss_G: 3.7895 D(x): 0.9063 D(G(z)): 0.2224 / 0.0349
[72/100][0/36] Loss_D: 0.3234 Loss_G: 3.3587 D(x): 0.8781 D(G(z)): 0.1607 / 0.0469
[73/100][0/36] Loss_D: 0.5022 Loss_G: 3.9006 D(x): 0.9003 D(G(z)): 0.2935 / 0.0323
[74/100][0/36] Loss_D: 0.3554 Loss_G: 3.7080 D(x): 0.8879 D(G(z)): 0.1913 / 0.0375
[75/100][0/36] Loss_D: 0.3596 Loss_G: 3.2965 D(x): 0.7743 D(G(z)): 0.0685 / 0.0542
[76/100][0/36] Loss_D: 0.6495 Loss_G: 5.5194 D(x): 0.9705 D(G(z)): 0.4091 / 0.0073
[77/100][0/36] Loss_D: 0.3999 Loss_G: 3.1584 D(x): 0.8490 D(G(z)): 0.1801 / 0.0648
[78/100][0/36] Loss_D: 0.4701 Loss_G: 4.1525 D(x): 0.9083 D(G(z)): 0.2750 / 0.0238
[79/100][0/36] Loss_D: 0.5758 Loss_G: 2.3029 D(x): 0.6666 D(G(z)): 0.0939 / 0.1473
[80/100][0/36] Loss_D: 0.4008 Loss_G: 2.4218 D(x): 0.7713 D(G(z)): 0.1041 / 0.1148
[81/100][0/36] Loss_D: 0.5403 Loss_G: 3.8739 D(x): 0.9449 D(G(z)): 0.3256 / 0.0347
[82/100][0/36] Loss_D: 0.3511 Loss_G: 3.0281 D(x): 0.8293 D(G(z)): 0.1331 / 0.0684
[83/100][0/36] Loss_D: 0.4054 Loss_G: 2.8194 D(x): 0.7406 D(G(z)): 0.0715 / 0.0984
[84/100][0/36] Loss_D: 0.5076 Loss_G: 3.0213 D(x): 0.7831 D(G(z)): 0.1943 / 0.0749
[85/100][0/36] Loss_D: 0.4454 Loss_G: 3.4294 D(x): 0.9062 D(G(z)): 0.2570 / 0.0508
[86/100][0/36] Loss_D: 0.2162 Loss_G: 3.6412 D(x): 0.9456 D(G(z)): 0.1343 / 0.0423
[87/100][0/36] Loss_D: 0.5604 Loss_G: 2.5750 D(x): 0.7493 D(G(z)): 0.1736 / 0.1138
[88/100][0/36] Loss_D: 0.2981 Loss_G: 2.5630 D(x): 0.8673 D(G(z)): 0.1273 / 0.1011
[89/100][0/36] Loss_D: 0.5659 Loss_G: 3.0466 D(x): 0.7905 D(G(z)): 0.2383 / 0.0757
[90/100][0/36] Loss_D: 0.2977 Loss_G: 2.6143 D(x): 0.8484 D(G(z)): 0.1122 / 0.0975
[91/100][0/36] Loss_D: 2.8834 Loss_G: 0.0756 D(x): 0.1008 D(G(z)): 0.0075 / 0.9404
[92/100][0/36] Loss_D: 0.5175 Loss_G: 3.9297 D(x): 0.9030 D(G(z)): 0.3078 / 0.0320
[93/100][0/36] Loss_D: 0.4225 Loss_G: 3.9847 D(x): 0.9286 D(G(z)): 0.2641 / 0.0271
[94/100][0/36] Loss_D: 0.6281 Loss_G: 2.6493 D(x): 0.7092 D(G(z)): 0.1737 / 0.1067
[95/100][0/36] Loss_D: 0.3733 Loss_G: 3.0146 D(x): 0.9437 D(G(z)): 0.2377 / 0.0687
[96/100][0/36] Loss_D: 0.7968 Loss_G: 4.7354 D(x): 0.9856 D(G(z)): 0.4777 / 0.0133
[97/100][0/36] Loss_D: 1.0690 Loss_G: 4.0340 D(x): 0.9066 D(G(z)): 0.5240 / 0.0307
[98/100][0/36] Loss_D: 0.5371 Loss_G: 2.0981 D(x): 0.7367 D(G(z)): 0.1680 / 0.1635
[99/100][0/36] Loss_D: 0.2682 Loss_G: 3.0591 D(x): 0.8766 D(G(z)): 0.1157 / 0.0671四、模型效果
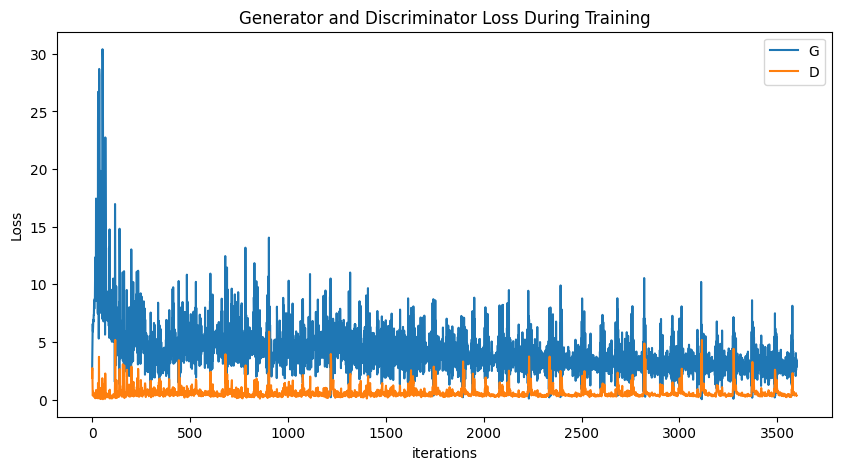
python
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G")
plt.plot(D_losses,label="D")
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
五、生成图片动态展示
python
# 创建一个大小为8x8的图形对象
fig = plt.figure(figsize=(8, 8))
# 不显示坐标轴
plt.axis("off")
# 将图像列表img_list中的图像转置并创建一个包含每个图像的单个列表ims
ims = [[plt.imshow(np.transpose(i, (1, 2, 0)), animated=True)] for i in img_list]
# 使用图形对象、图像列表ims以及其他参数创建一个动画对象ani
ani = animation.ArtistAnimation(fig, ims, interval=1000, repeat_delay=1000, blit=True)
# 将动画以HTML形式呈现
HTML(ani.to_jshtml())这一部分生成的内存比较大,无法展示到这里。部分动态截图如下:

六、真假图片对比
python
# 从数据加载器中获取一批真实图像
real_batch = next(iter(dataloader))
# 绘制真实图像
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# 绘制上一个时期生成的假图像
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()

看起来假的还是假的,但是人的模样出来了