25年5月来自UC Berkeley 和 TRI 的论文"Real2Render2Real: Scaling Robot Data Without Dynamics Simulation or Robot Hardware"。
扩展机器人学习需要大量且多样化的数据集。然而,现行的数据收集范式------人类遥操作------仍然成本高昂,且受到手动操作和机器人物理访问的限制。Real2Render2Real (R2R2R),这是一种无需依赖目标动力学模拟或机器人硬件遥操作即可生成机器人训练数据的新方法。输入是智能手机拍摄的一个或多个目标的扫描图像以及一段人类演示的视频。R2R2R 通过重建详细的 3D 目标几何形状和外观并跟踪 6-DoF 目标运动,渲染数千个高视觉保真度、与机器人无关的演示。R2R2R 使用 3D 高斯溅射 (3DGS) 为刚性和铰接式目标实现灵活的资源生成和轨迹合成,将这些表示转换为网格,以保持与 IsaacLab 等可扩展渲染引擎的兼容性,但需关闭碰撞建模。 R2R2R 生成的机器人演示数据可直接与基于机器人本体感受状态和图像观察的模型集成,例如视觉-语言-动作模型 (VLA) 和模仿学习策略。物理实验表明,基于单次人类演示的 R2R2R 数据训练的模型,其性能可媲美基于 150 次人类遥操作演示训练的模型。
机器人技术长期以来受益于计算可扩展性------概率规划、轨迹优化和强化学习等方法推动了敏捷运动的重大进步 1, 2, 3, 4, 5, 6, 7。然而,灵巧操作面临着独特的挑战:它需要与机器人控制和运动学紧密结合的细粒度视觉感知,以便与目标交互并改变环境。许多系统通过明确地将感知与规划和控制分离来解决这个问题,并在结构化环境中实现了强大的性能 8, 9, 10, 11,尤其是在场景几何、目标位置和感知模态假设成立的情况下。然而,此类流程通常依赖于特定于任务的感知模块和严格控制的环境,从而限制了在非结构化、动态或视觉多样化环境中的灵活性。
为了解决开放世界操控任务,受大语言模型 (LLM) 和视觉语言模型 (VLM) 12, 13, 14, 15 的启发,近期研究者们探索了端到端的通用机器人策略 16, 17, 18, 19, 20, 21, 22, 23, 24, 25------这些模型直接从原始感官输入中学习,并有望实现语言指令遵循、任务迁移和上下文学习等功能。然而,大规模训练此类模型仍然受到数据的限制:最大的人类遥操作数据集比用于训练前沿 LLM 和 VLM 的语料库小 10 万倍以上 26, 27,并且受到成本、速度以及人类遥操作数据收集的个体特异性等因素的限制。
其他视觉语言子领域也面临着类似的数据稀缺问题,并通过计算数据生成来克服这一问题。运动结构恢复、检测和深度流程如今通常会生成伪标签来引导大模型;例如,SpatialVLM 合成了 20 亿个空间推理问答对 28,而 RAFT 29、DUSt3R 30、MonST3R 31、Zero-1-to-3 32 和 MVGD 33 均依赖于从多视图几何流程(例如 COLMAP 34)获取的伪真实值来监督密集的 3D 预测任务。这些成功案例为机器人技术提出了一个类似的问题:
能否在不需要动力学模拟或人类遥操作的情况下,以计算方式扩展机器人视觉-动作数据来训练机器人学习模型?
之前的研究转向基于物理的模拟,其中轨迹是通过强化学习或在虚拟环境中进行运动规划来合成的 35, 36, 37。虽然现代模拟器提供高吞吐量并支持大规模并行化,但它们面临着几个根本性的限制:许多常用的模拟器无法满足基本的拉格朗日力学,例如能量或动量守恒 38;准确建模复杂的目标相互作用通常需要大量的参数调整和接触属性的手工设置 39;生成高质量、兼容且无交叉的模拟资产仍然是一项劳动密集型的工作,因为碰撞建模需要仔细处理几何形状、摩擦和变形 40, 41。
机器人数据收集范式。扩展机器人学习传统上依赖于两种范式:来自工业部署的数据和来自人类遥操作的数据。工业机器人日志 43, 44, 45 随着生产吞吐量的增加而扩展,但通常特定于任务和具体实施方式。相比之下,遥操作数据集 46, 47, 48, 49, 50 提供了更丰富的视觉和任务多样性,但仍然受到人力和实时收集的瓶颈制约。与此同时,通用机器人策略 16, 19, 51, 17, 18, 20, 21, 22, 23, 24, 25 的兴起------能够根据原始观察结果执行各种操作任务------放大了对可扩展、多样化和高质量训练数据的需求。然而,当前机器人数据集的规模仍然比视觉和语言数据集 26, 27 低几个数量级。
程序化机器人数据生成。为了应对机器人数据扩展的挑战,许多研究都研究了程序化数据生成,以便自动化机器人数据收集,从而完成预定义任务。许多研究 52、53、54、55、56、57 使用预定义的运动原语(可选搭配感知模块)来实现使用真实机器人的自动化数据收集,并自动重置场景。虽然减少了人为干预,但它们仍然需要机器人硬件进行数据收集,从而限制了可扩展性。最近,模拟数据生成已成为现实世界数据收集的一种可扩展替代方案,它无需物理机器人硬件即可并行生成数据。利用来自模拟器的专有信息,Mahler 10 为机器人抓取生成了大量且多样化的数据。Katara 35 和 Wang 36 使用强化学习、轨迹优化和运动规划在模拟中生成大规模机器人数据。MimicGen 58 结合运动规划和轨迹重放,从单个人类遥操作序列合成各种模拟。尽管人们努力通过域随机化 59、改进的资源和场景生成 35, 36 来弥合模拟与现实之间的差距,但由此产生的模拟数据通常与现实世界的观察结果存在显著的视觉差异,需要使用真实数据进行协同训练才能实现有效的迁移 60。
真实-到-合成的数据生成。为了弥合这种视觉领域的差距,一些研究增强并重新利用真实的 RGB 数据,而不是从头合成。例如,Chen 62 使用生成模型将机器人的具象特征修复到真实图像中,从而实现了不同形态机器人的数据合成。然而,此类方法在初始演示中仍然需要人类遥操作。此外,它们缺乏生成除提供的演示之外的其他多样化轨迹的能力。同样,Lepert 64 和 Duan 66 使用手势追踪来引导从人类演示中修复的机器人末端执行器轨迹。虽然这些方法减少了对直接遥操作的需求,但它们通常每个视频仅生成一条轨迹,并且缺乏对计算规模的轨迹多样性的支持。相比之下,R2R2R 可以从单个人类演示中生成多个不同的机器人轨迹渲染和动作展示。仅使用 R2R2R 生成的数据训练的策略,其真实世界性能与使用人类遥操作数据训练的策略相当。
Real2Sim2Real 数据生成。为了从单个演示生成不同的轨迹,同时弥合模拟与现实之间的差距,许多方法遵循 Real2Sim2Real 范式------使用现实世界的观察结果来构建用于策略学习的模拟环境。先前的研究 67 表明,调整物理参数可以减少动态失配,但较大的视觉域差距仍然需要测试-时感知模块。近期的方法 37, 68, 38, 63 通过从真实扫描中构建数字孪生或"数字表亲"69 来缩小这种视觉差距。这些方法在对遥操作、模拟和轨迹多样性的依赖程度上各不相同,但许多方法仍然依赖于遥操作演示、手动设计的奖励或精确的物理模型,从而限制了可扩展性。例如,DexMimicGen63 使用固定的模拟资源;RoboVerse 38 仅支持刚体;而 RialTo 70 和 CASHER 39 则需要手动标注关节和进行奖励工程。虽然 Video2Policy 37 避免了通过视觉语言模型进行奖励调整,但由于视觉不匹配,它仍然需要测试-时目标检测。这些流程还依赖于物理引擎,这需要高保真网格进行碰撞检查和广泛的调整。RoboGSim 61 避免模拟,但缺乏对单个演示中轨迹多样性的支持。
相比之下,Real2Render2Real (R2R2R) 通过以下方式解决了这些限制:(1)从人类视频中提取目标轨迹,(2)自动分割目标部分,(3)渲染逼真的观察结果以消除对测试-时感知的依赖,(4)消除对碰撞建模和详细网格的需要,以及(5)从单个演示中生成多样化的轨迹。
R2R2R 通过舍弃动力学来避免这些挑战:没有模拟力或接触,而是使用 IsaacLab 包 42 直接设置每帧的目标和机器人姿态,纯粹将其作为一个逼真的并行渲染引擎,将所有目标设置为运动体而非动态体。这种方法尊重机器人运动学,同时避免接触建模的复杂性,自然地与从 RGB 图像和本体感受输入训练的基于视觉的策略保持一致。
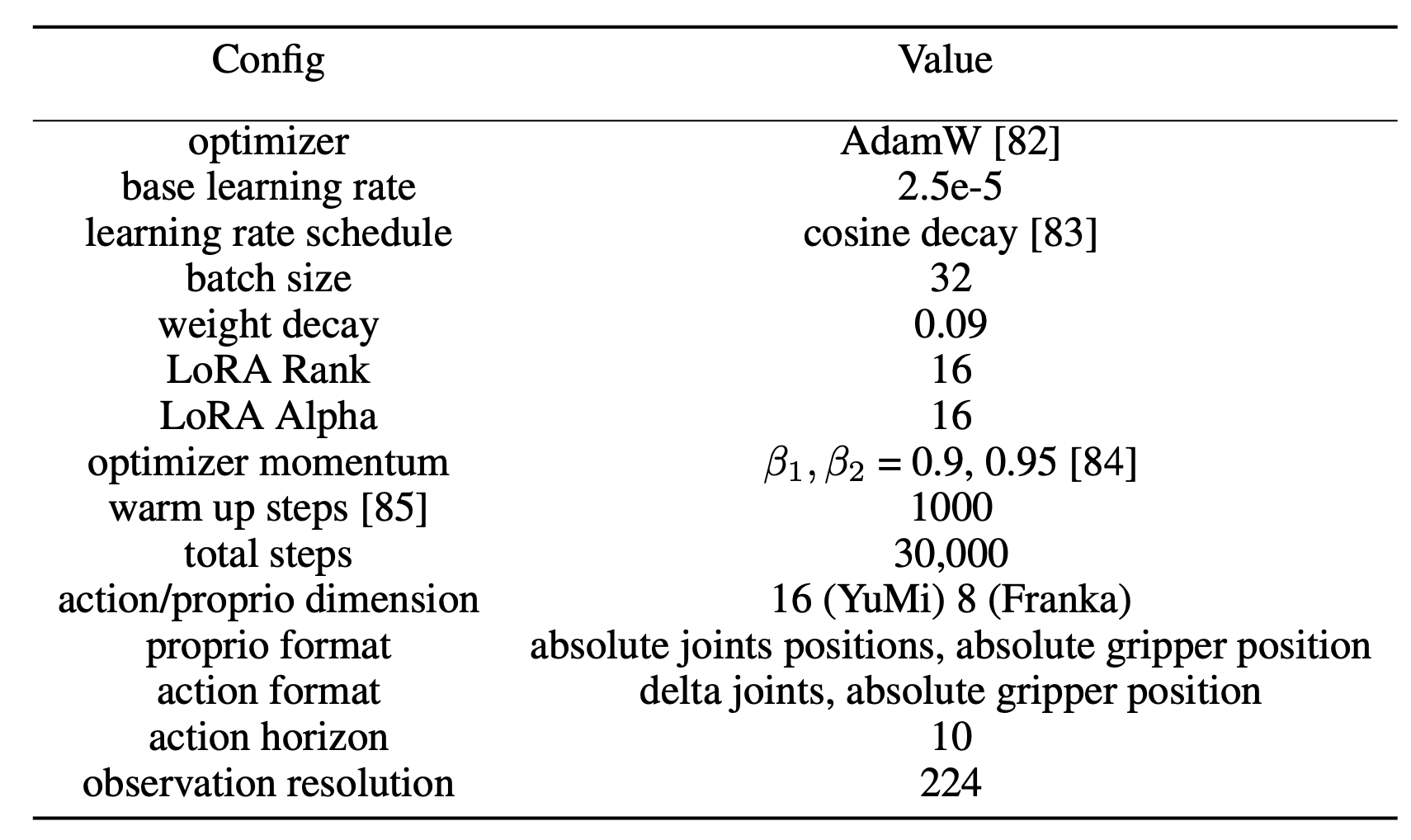
R2R2R 是一种用于从智能手机目标扫描和人类演示视频生成大规模合成机器人训练数据的流程。R2R2R 在保持视觉精度的同时扩展轨迹多样性:它使用目标姿态追踪从视频中提取 6 自由度目标部件轨迹,并在随机目标初始化下通过微分逆运动学(IK)生成相应的机器人执行。从多视角扫描开始,它重建 3D 目标几何形状和外观,通过部件级分解支持刚体和铰接体,并使用 3D 高斯溅射 (Gaussian Splatting) 生成网格资源。生成的轨迹包括机器人本体感受、末端执行器动作以及在不同光照、相机姿态和目标位置下渲染的成对 RGB 观测值,使其与现代模仿学习策略(例如视觉-语言-动作模型和扩散模型)直接兼容。
通过消除对动力学模拟或机器人硬件的需求,R2R2R 实现了可访问且可扩展的机器人数据收集,任何人都可以通过使用智能手机捕捉日常目标交互来做出贡献。
R2R2R 由三个主要阶段组成:(1)真实-到-模拟的资产和轨迹提取,从现实世界的智能手机捕获中提取刚体或铰接式体的几何形状和部分轨迹;(2)增强,其中目标初始化是随机的,并且在适当的情况下插入目标运动轨迹;(3)并行渲染,其中使用 IsaacLab 42 生成各种逼真的机器人执行,并可根据可用的 GPU 内存量和 GPU 数量进行扩展。
如图所示:Real2Render2Real 为"将杯子放在咖啡机上"的任务生成机器人训练数据。R2R2R 将多视角目标扫描和单目人体演示视频作为输入。然后,R2R2R 通过并行渲染合成多样化、域随机化的机器人执行,并输出配对的图像动作数据用于策略训练。该流程无需遥操作或目标动力学模拟,即可实现跨任务和不同场景的可扩展学习。
1. 真实-到-模拟的资产提取
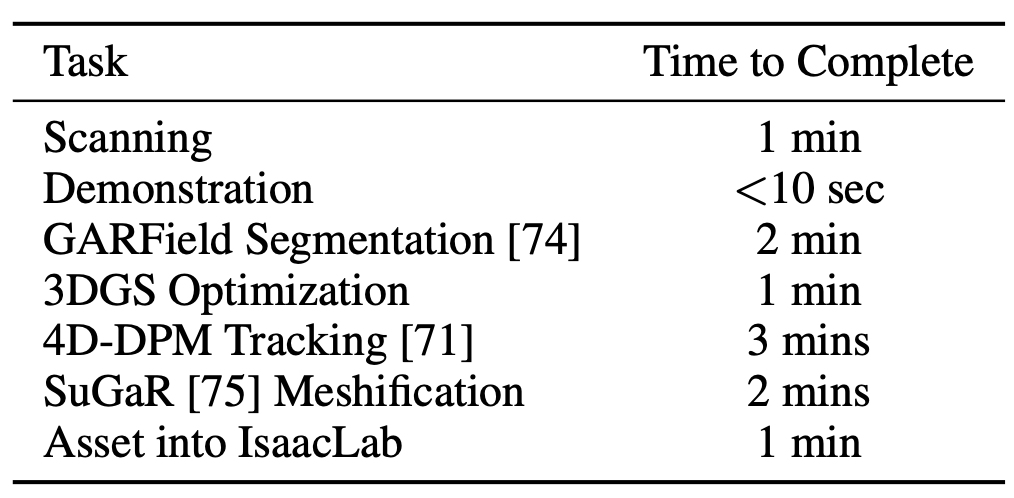
采用受 71, 72 启发的两阶段流程,从智能手机扫描中提取 3D 目标资产。首先,使用 3D 高斯溅射 (3DGS) 73 重建目标的几何形状和外观,然后应用 GARField 74 将场景分割成语义上有意义的部分,即通过将二维掩码提升到三维。这实现了目标级和部件级的分解,包括关节式组件。为了支持基于网格的渲染,生成的高斯组通过 75 的扩展版转换为带纹理的三角形网格。
如图所示 3DGS 的目标重建:

2. 真实-到-模拟轨迹提取
给定一段智能手机上人类操作扫描目标的视频,R2R2R 使用 71 中提出的四维可微分部件建模 (4D-DPM) 提取目标及其部件的 6 自由度部件运动。每个 3DGS 目标部件都嵌入预训练的 DINO 特征,从而能够通过可微分渲染实现部件姿态优化。本文扩展 71 的实现,使其能够跟踪演示视频中的单个或多个刚体以及铰接体。
虽然有许多替代流程可以将真实图像转换为 3D 资源,但本文采用 3DGS -到-网格的转换,主要有两个原因:(1) 它能够通过 3D 分组实现背景-前景分割和部件分解 74,这对于从单目人体演示中提取特定于目标部件的轨迹至关重要; (2) 它兼容 4D-DPM 轨迹重建和基于网格的渲染引擎,可无缝集成到大规模渲染流程中。此过程无需任何基准点或除智能手机摄像头之外的硬件,非常适合用于可扩展且易于访问的真实-到-模拟数据生成。
目标轨迹多样性的插值方法:Real2Render2Real 的一项关键贡献是能够从单个人体演示中合成多个有效的 6-DoF 目标轨迹。对于多个相互作用的刚体(例如,将杯子放在咖啡机上),原始演示仅对特定的初始目标配置有效,而简单地从新的初始姿势重放该演示将失败。为了解决这个问题,本文引入一套轨迹插值和重采样技术,使原始轨迹能够适应新的起始和结束姿势,同时保留其语义意图。
从一条参考轨迹 τ 开始,该轨迹 τ 由演示视频中部件跟踪提供的 T 个航点组成,每个航点编码一个目标方向(四元数)和位置。给定一个新的初始姿态 x_start,以及来自人类演示的期望最终姿态x_end,应用空间归一化,将原始轨迹变换到正则空间。计算原始和目标端点姿态之间的仿射变换,将其应用于轨迹的平移分量,并使用球面线性插值(Slerp)对关键帧方向进行插值。这将生成一条新的轨迹 τ′,其起点和终点均为期望姿态,同时保留原始运动的结构。虽然这些轨迹保留高级语义意图,但它们的生成没有明确的避撞机制,并且在遮挡目标后初始化时可能会导致路径不可行。为了缓解这个问题,应用一种采样启发式方法,使初始位置的分布偏离目标姿态(如图所示)。

抓握姿势采样:R2R2R 使用 76 从演示视频中估算手部 3D 关键点,然后通过计算关键点(食指尖和拇指)与所有分割目标部件质心之间的欧氏距离来确定目标与手的相互作用。这将生成一个随时间和目标部位索引的距离矩阵。将整个轨迹上总距离最小的部位定义为被抓握的部位,从而有效地在整个演示过程中选择最接近手部的目标。为了生成物理上合理的抓握,对 3DGS 均值进行采样以构建更粗的三角形网格(不同于高分辨率渲染网格),应用表面平滑和抽取以获得一致的法线,并使用遵循 10 的解析对映(antipodal)抓握采样器来确定候选抓握轴。对于双手任务,每只手独立应用此过程以推断单独的目标关联和抓握动作,从而支持诸如抬起或稳定等协调动作。
微分逆运动学:对于每个抓取和目标轨迹对,用 PyRoki 77 求解微分逆运动学问题。求解器计算平滑的关节空间轨迹,这些轨迹会在抓取前、抓取中和抓取后阶段诱导出所需的目标运动。至关重要的是,本文方法不需要对目标动力学进行建模或模拟物理相互作用。假设目标在接触过程中严格遵循轨迹运动,而不是像动态模拟那样求解会物理诱导目标运动的关节扭矩。这种运动学假设避免了接触建模、柔顺性或摩擦力估计等挑战。求解器只需确保机器人运动学能够跟踪受关节位置限制的所需目标运动,并且在抓取前和抓取后阶段,额外添加平滑度和速度限制约束,从而生成有效的抓取接近运动。
渲染多样化环境上下文:为了提高鲁棒性,在场景几何和渲染参数方面应用了广泛的域随机化。这包括随机光照条件(例如强度、色温)、相机外参(均匀采样,最多可进行 2 cm 平移和 5° 旋转)以及目标初始姿态(在工作空间相关范围内采样)。通过对以目标为中心的 3D 表示进行建模,可以在渲染过程中直接应用这些增强功能。相机姿态或光照的变化不会影响底层的运动学展开,从而使 R2R2R 能够从单个演示中生成不同的视觉上下文。这些增强功能通过缩小合成演示与实际部署之间的外观差距和协变量漂移来扩展数据分布并提高泛化能力。
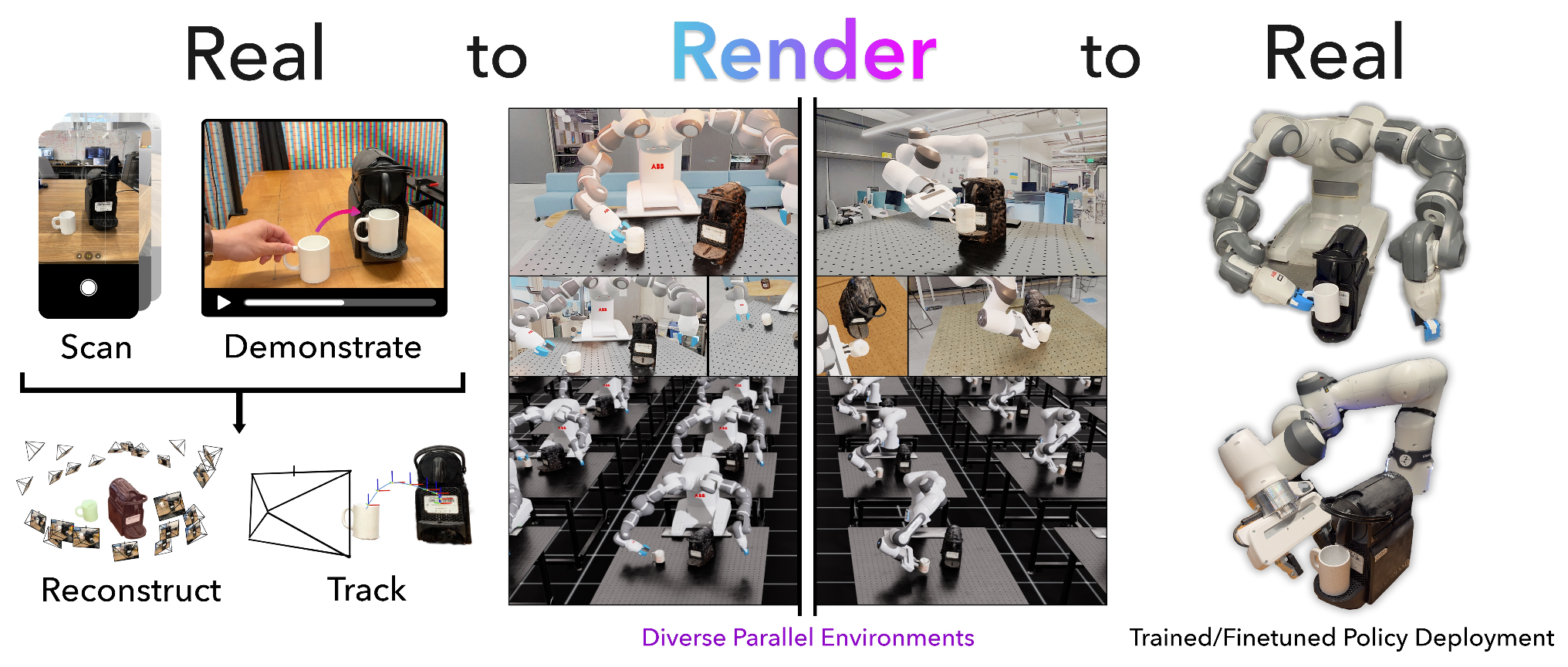
高吞吐量渲染:IsaacLab 42 使用基于 tile 的渲染、深度学习超级采样 (DLSS) 和网格资源实例化,支持 GPU 并行执行多个环境上下文。在单块 NVIDIA RTX 4090 上,R2R2R 使用 IsaacLab 框架以平均每分钟 51 次演示的速度渲染完整的机器人演示(而人类遥操作每分钟仅 1.7 次演示),速度提升超过 27 倍。如图所示,吞吐量与渲染 GPU 的数量呈线性关系。每个任务的数据生成/收集时间见下表。
3. 策略学习
考虑两种现代模仿学习架构:扩散策略20和 π0-FAST 78。以4个时间步长的本体感觉历史和448px的RGB观测数据为条件,从头开始训练扩散策略10万步,以迭代去噪SE(3)中的16个未来绝对末端执行器姿态。用低秩自适应(LoRA)79(秩 = 16)对 π0-FAST 进行3万步微调,该方法采用单张224px的方形图像(以匹配预训练分辨率)并预测10步相对关节角度动作块。在单台NVIDIA GH200上训练扩散策略大约需要3个小时,而π0-FAST微调则需要11个小时。部署时,两个模型均接收原始 RGB 图像和机器人本体感觉------扩散模型中 SE(3) 绝对末端执行器位姿,π0-FAST 模型中为关节位置------并输出相应的动作目标。为了提高不同时间步预测动作之间的时间一致性,在两个模型的执行过程中对预测的动作块应用时间集成 23。
扩散策略的超参:
π0-FAST 的超参: