paper :IEEE Xplore Full-Text PDF:
摘要
本文提出了一种名为DeepDeSRT的端到端文档图像表格理解系统。该研究的主要贡献体现在两个方面:首先,提出了基于深度学习的文档图像表格检测方案;其次,开发了创新的深度学习表格结构识别方法(即识别检测表格中的行、列及单元格位置)。与现有依赖启发式规则或额外PDF元数据(如打印指令、字符边界框或线段)的基于规则方法不同,本系统完全由数据驱动,无需任何启发式规则或元数据即可完成文档图像中表格结构的检测与识别。此外,相较于多数仅适用于PDF格式的现有方法,DeepDeSRT直接处理文档图像,使其不仅适用于可自动转换为图像的原生数字PDF文档,还能应对更具挑战性的扫描文档场景。
为评估系统性能,我们在包含67个文档(共238页)的公开数据集ICDAR 2013表格竞赛数据集上进行了测试。实验结果表明,DeepDeSRT在表格检测与结构识别任务上均超越现有最优方法,分别达到96.77%和91.44%的F1值。此外,在欧洲某大型航空公司的真实案例数据集(其文档特征与ICDAR 2013差异显著)中,DeepDeSRT对随机抽样样本仍展现出高精度的表格检测能力,验证了系统优异的泛化性能。
一、引言
处理数字文档中的表格问题自结构化文档分析之初便已存在1。尽管已有多种方法可用于文档图像中的表格检测及其结构分解2--5,但这些任务对现代文档处理系统仍具挑战性。
表格检测的核心难点源于显著的类内差异性:由于表格布局的多样性、分隔线使用的随意性以及内容的高度异构性1,难以给出形式化的表格定义标准。此外,表格与文档中其他元素(如图形、代码段或流程图3)存在类间相似性,这使人工设计有效的表格特征描述符尤为困难。鉴于纸质文档在商业场景中的持续使用及其内含的丰富表格数据,文档处理流程亟需高精度的表格理解机制。
现有表格处理方法多依赖特定场景的启发式规则及PDF元数据(如字符定位信息)。虽然利用PDF元数据可降低原始图像处理的复杂度,但在纯图像场景下的表格检测与结构识别仍面临更大挑战。为此,我们提出了一种不依赖脆弱辅助机制的系统化解决方案。
本文提出的DeepDeSRT系统实现了文档图像中表格检测与结构识别的端到端处理。该方法基于深度学习的数据驱动范式,无需预设规则即可完成表格检测及结构解析,适用于图像与原生数字文档(如PDF、Word及网页文档,因其可被转换为图像格式)。
针对深度学习所需大规模标注数据缺失的问题,DeepDeSRT通过迁移学习与域适应策略实现模型优化。本研究的核心贡献包括:
• 表格检测模型 :将通用目标检测器(Faster R-CNN6)通过精细调参迁移至文档图像域,解决了跨域差异问题
• 表格结构识别模型 :基于FCN语义分割模型7,通过数据增强与模型微调实现行列单元格识别,源模型在Pascal VOC 20118预训练
• 验证深度迁移有效性:证明当源域与目标域差异显著且目标训练集较小时,深度神经网络微调仍具显著效果
二、相关工作
针对表格理解的研究已有大量成果,相关领域综述文献1-5系统梳理了该领域技术发展脉络。为避免冗余,本节重点评述近期机器学习方法进展,传统基于视觉线索、启发式规则与固定模板的方法详见上述综述。
2.1 表格检测技术演进
Cesarini等人于2002年率先将机器学习引入表格检测领域。其提出的Tabfinder方法9首先将文档转换为MXY树结构,随后搜索被水平或垂直线包围的区块,通过深度优先遍历生成候选表格。
Silva10提出的另一早期数据驱动方法构建多层隐马尔可夫模型(HMMs),通过联合概率分布建模页面元素的时序观测特征与表格线段的隐含状态。在其博士论文11中,Silva进一步验证了概率模型相较于脆弱启发式规则的优势,强调多方法融合的重要性。
Kasar等人12通过手工设计特征训练SVM分类器。尽管无需预设规则,但该方法严重依赖可视分隔线,导致应用场景受限。Fan与Kim13创新性地结合文档行级弱标签无监督学习与区域语言特征,成功训练生成式与判别式分类器集成模型。
近年来深度学习开始渗透该领域,Hao等人14首次将深度特征与PDF元数据结合应用于表格检测。非机器学习方法方面,Tran团队16基于文本块空间布局的方法在ICDAR 2013数据集15表现优异。但因其未公开具体数据划分方案,结果难以直接横向对比。
2.2 表格结构识别进展
较之表格检测,结构识别研究更为稀缺。Kieninger与Dengel提出的T-RECS系统17通过水平重叠分析构建词级列结构,继而基于边距特征划分单元格,成为该领域奠基性工作。
Wang等人18开发七步概率优化流程,其概率参数通过训练语料统计获得,形成数据驱动的类X-Y切割算法。Shigarov团队19提出可配置阈值与规则集的系统,但严重依赖PDF字体元数据与特定启发式规则,泛化能力受限。
三、方法
3.1 基于深度学习的表格检测
表格理解的首要任务是定位文档中的表格区域。该问题在概念上类似于自然场景图像中的目标检测,因此我们通过域适应与迁移学习策略,将自然场景目标检测框架迁移至文档图像领域。基于其卓越性能与开源代码优势,选择Faster R-CNN(简称FRCNN)6作为基础检测框架。尽管FRCNN架构问世已久,但其检测性能仍处于前沿水平,且被众多现代体系20-22作为核心组件继承。
文档图像中的表格与自然场景目标具有重要共性:视觉上易与背景区分,但存在类间相似干扰元素(如流程图等)。这种相似性表明,现有目标检测系统在表格检测中可能表现良好但受限于固有缺陷,后文实验结果将验证该假设。
FRCNN模型由两个模块构成:
-
区域建议网络(RPN):基于输入图像生成候选区域
-
Fast R-CNN分类网络23:对候选区域进行分类
两模块共享参数,支持端到端训练6。实验采用两种骨干网络:
-
Zeiler与Fergus提出的轻量级ZFNet24
-
Simonyan与Zisserman开发的深层VGG-1625
选用不同深度的基础网络可评估网络复杂度对检测性能的影响。Ren等人提供了两种网络的预训练模型,便于进行微调实验。
3.2 基于深度学习的表格结构识别
成功检测表格位置后,理解其内容的核心挑战在于识别构成表格物理结构的行与列。此任务与表格检测存在本质差异:表格图像中行列数量显著多于文档中的表格总数,且结构元素空间分布高度密集,这导致传统FRCNN架构难以胜任,需采用新型解决方案。
受深度学习语义分割技术启发,我们采用Shelhamer等人7提出的FCN-Xs架构。该架构结合三大核心技术:
-
全卷积网络:支持任意尺寸输入
-
跳跃连接(跨层融合):整合浅层高分辨率特征与深层语义特征
-
反卷积操作:提升分割掩模分辨率
基于VGG-16骨干网络25的标准FCN-8s架构虽融合pool3与pool4层特征,但文献7表明融合更浅层特征对性能提升有限。我们通过实验发现:浅层网络(如pool1/pool2层)提取的基础特征(边缘、色变等)可显著优化行列边界检测。据此提出改进型FCN-2s架构(该架构在边缘检测领域28曾有简略提及),新增pool1与pool2层跳跃连接。
初始实现中沿用Shelhamer团队的固定缩放因子策略:每加深一个池化层,特征缩放因子递减两个数量级(pool1层缩放因子达10^-8)。该方案在列分割表现良好,但行检测性能欠佳。为解决此问题,引入Liu等人29提出的可学习缩放机制------将固定缩放层替换为带可训练参数的正规化层(采用其改进版SSD实现方案30)。通过端到端训练自动优化各层特征融合权重,有效提升了行列检测的均衡性。
四、实验
4.1 表格检测
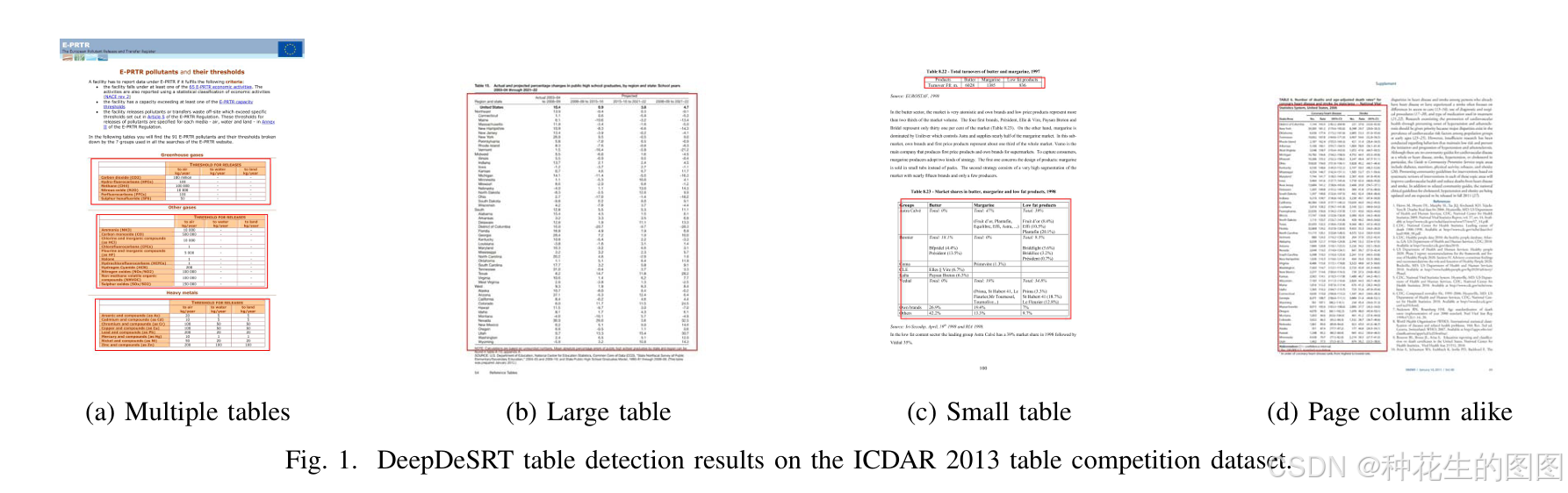
由于DeepDeSRT采用数据驱动方法,需构建大规模训练数据集。我们选用北京大学计算机科学技术研究所发布的Marmot表格识别数据集31(当前最大公开数据集)。鉴于该数据集未预设划分方案,我们按8:2比例随机拆分为训练集(1,600图像)与验证集(399图像),正负样本比例均保持1:1。通过人工修正标注错误,得到优化版数据集Marmot clean(简称MarmotC)。为避免深度网络从头训练的样本不足问题,采用迁移学习与域适应技术优化模型参数。需特别说明:模型训练与验证阶段均未使用ICDAR 2013竞赛数据集15的任何数据。
基于III-A节所述骨干网络架构,训练多组FRCNN模型。微调采用6提供的预训练模型(基于ImageNet32/Pascal VOC8/COCO33数据集)。其余超参数遵循6设定:批量大小为2,迭代30,000次(约28个epoch)。训练过程中持续监控验证集性能以防过拟合。最终选择MarmotC验证集表现最优的模型进行全量训练,所得模型应用于DeepDeSRT系统及ICDAR 2013测试。
性能评估采用文档处理领域通用指标:
-
召回率(Recall)
-
精确率(Precision)
-
F1值(F1-measure)
-
平均精确率(AP)与平均召回率(AR)
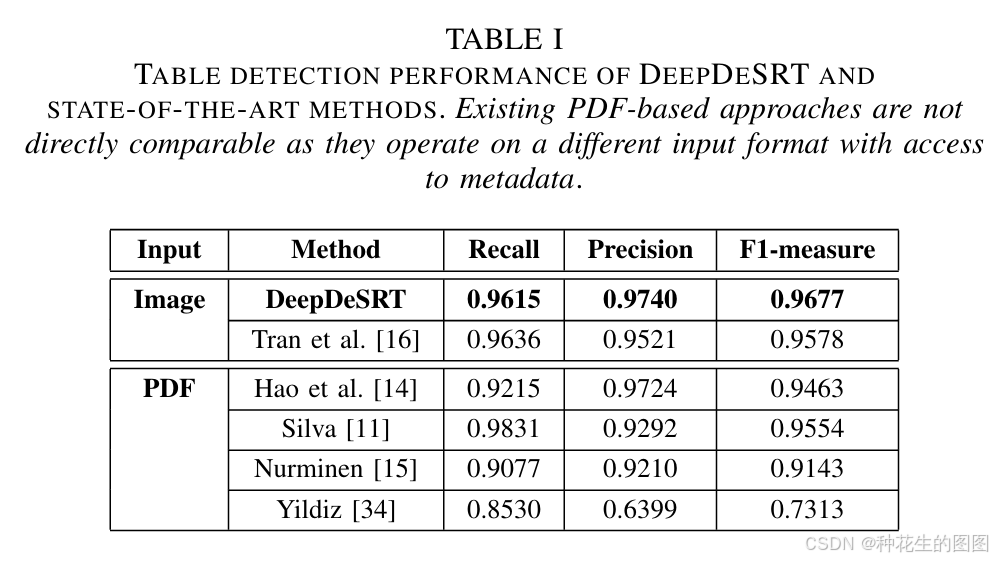
计算方式遵循15规范:先逐文档计算指标,再取全局平均值。当检测置信度阈值设为99%时,DeepDeSRT在ICDAR 2013数据集上仅出现1例非表格误检,各项指标均达最优水平(详见表I)。需注意:基于PDF元数据的系统(表I中对比方法)因可获取额外结构化信息,其性能与仅处理原始图像的DeepDeSRT不具直接可比性。
4.2 结构识别
我们首先尝试沿用基于FRCNN的技术进行表格结构识别。该方法在列检测中表现尚可,但在行检测中性能严重不足。深入分析发现,结构识别的核心难点源于两个因素:密集空间内目标数量庞大以及结构元素极端的长宽比特征。FRCNN模型在conv5_3层16像素的有效步长可能导致网络忽略关键视觉特征,特别是行实例的区分特征。
为解决此问题,我们转向语义分割方法。采用III-B节描述的架构后,性能较FRCNN显著提升,但初期结果仍不理想:尽管语义分割指标表面良好,实际行检测数量极少。分割掩模分析表明,行间背景像素间隙过小,导致训练过程中模型未能充分学习行边界特征。为此,我们引入垂直拉伸预处理(优化行分离)与水平拉伸预处理(强化列边界识别),这种非侵入式操作符合视觉认知规律。
通过III-B节所述的规范化层替换缩放层后,发现矛盾现象:未使用预处理时,可学习缩放参数优于固定缩放;但结合类特异性预处理后,优势减弱甚至逆转,且行列模型呈现相反行为模式。
系统加入轻量级后处理模块以解决三类问题:虚假检测碎片、断裂结构与粘连结构。具体措施包括:
-
滤除覆盖面积小于输入图像0.5%的检测框
-
基于显著垂直重叠度水平合并断裂行结构
-
基于显著水平重叠度垂直合并断裂列结构
-
采用形态学开运算分离粘连结构
所有阈值均通过非训练/验证集图像的视觉分析实验确定。
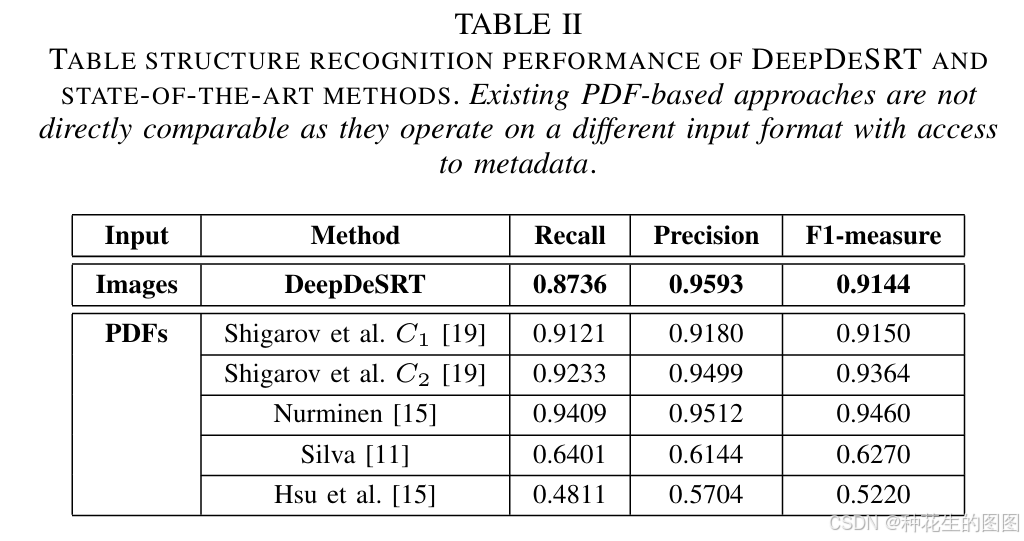
基于FCN的分割模型采用标准SGD优化器(固定学习率10^-10,动量0.99)训练60,000次,批量大小为1(遵循原文7建议)。如表II所示,系统在ICDAR 2013随机测试子集(34张图像)上取得当前最优结构识别结果。需特别说明:所列方法中仅DeepDeSRT处理原始图像,其余均依赖PDF元数据,且因测试集规模限制,结果不可直接对比。未来将通过专用训练集解决此问题。
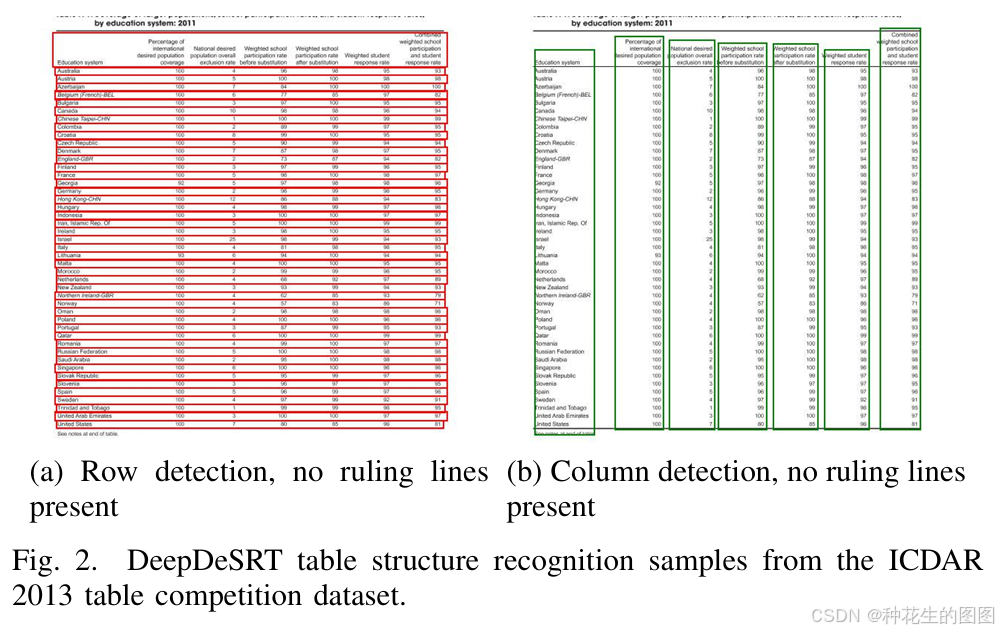
图2展示了DeepDeSRT的典型成功案例,证明其能有效处理无分隔线表格及密集行列场景。图3则揭示了现存缺陷:嵌套行层级识别失效与极端邻近行误判。这些案例表明,尽管系统达到前沿性能,复杂结构识别仍存改进空间。