锐评
鸡蛋鸭蛋荷包蛋 我的蛋仔什么时候才能上巅峰凤凰蛋?
1. 如何保证数据库数据和redis数据一致性
数据库数据和 redis 数据不一致是在 高并发场景下更新数据的情况
首先我们要根据当前保持数据一致性的策略来决定方案
如果采取的策略是先删除缓存 更新数据库
我们假设现在有一个写线程
如果在更新数据库的时候 读线程进入后 读取了脏数据 并且挂载缓存
之后写线程更新完毕了数据 但是缓存里还是老数据
就会造成数据不一致的问题
这种策略的缓存数据库不一致容易发生
因为 写入数据库的时间往往大于读取数据的时间
所以写线程往往会慢于读线程结束
这种策略的优化方案就是采用延迟双删 即是在写线程在更新数据库 前后 都清空缓存
隔个多少 ms 后再清空缓存
这个时间是有考究是 就是 应该在多长时间后再清除一次缓存
这个时间应该大于 读线程从数据库读取数据更新缓存的时间
我们可以考虑最极端的情况
也就是在更新同步的那一刻 读线程进入 读取脏数据 写入缓存
那么得出结果
T (延迟双删)> T1( 读取数据库 ) + T2 (写入缓存) + T3 (网络延迟等其他因素)
第二种 策略是先更新数据库 再删除缓存
如果按照刚才的思路 也就是说可能会存在先后的问题
我们不难想到 这种策略也会存在问题
时间交叉问题
更新数据库之前 有一个读线程读取到了脏数据
在写线程更新完毕后 删除缓存 读线程再继续进行 写入缓存
但是这种情况一般来说不会出现
因为更新缓存的时间一般来说较短 也就是说读线程的读取时间一般来说是很快的
所以这种情况 很少发生
这跟先删除缓存 再更新数据库相比 问题会小一点
但是从另一方面来说 网络上的博客中最多的探讨是 如果 读线程删除缓存失败了 会怎么办
我们可以删除重试模式
或者我们可以用异步请求的方式,MQ消息队列,Canal 等去解决这种问题
我自己的开源项目 BalloonWords就写了这两套方案的具体实现
一套是延迟双删 一套是使用中间件异步请求
2. 缓存穿透、雪崩、击穿及其解决方案
首先缓存穿透是一个大类
缓存穿透是 数据既不在缓存又不在数据库
造成这么原因可能是数据库数据莫名奇妙丢失
在高并发场景下 数据到来 从缓存到数据库会直接让数据库宕机
对于此 我们可以采用
- 数值到来前进行校验 请求参数是否有非法数值 (在到达 dao 层前进行拦截)
- 在缓存里设置默认数值
- 用布隆过滤器查看数据库里面是否有相关数据
我们首先思考是从缓存雪崩到缓存击穿 这是同一类
缓存雪崩 是指大量数据同时过期
瞬时间的请求就只能全部到达数据库进行请求
通常是 因为 redis 里面的 key 过期时间设置成一样的 或者 是 redis 故障
- 前者 我们可以随机化过期时间
- 后者 我们可以设置 redis 集群
我再想想...
- 我们可以设置互斥锁 多线程请求到来
只让一个请求去更新缓存 其他线程此时阻塞
等到缓存更新完毕了 那个请求释放锁 让其他线程从缓存里面获取数据
在业务上线前 为了防止第一次高并发 我们可以实现进行缓存预热
缓存击穿是 大量请求瞬间到达数据库
- 我们可以设置热点数据永不过期
- 或者是缓存预热
- 同样的我们也可以异步处理 定时任务 使用中间件定期更新缓存
3. springboot和spring的区别
spring 是一种 JavaEE 企业级开发框架
提供了 bean 的定义 核心 IOC AOP 等概念
通过手动配置 bean,手动配置依赖,手动部署到外部 servlet 容器启动
springboot 是一种更快捷开发方式,自动配置 bean,自动引入 maven 管理依赖,内置服务器,内置启动脚手架,集成多种拓展 ,让开发更加方便
springboot 并没有代替 spring
在我们快速开发一个 web 应用的时候我们可以选择 springboot
如果是复杂企业级应用 高定制化应用 还是建议手搓 spring 合成各组件
4. 讲一下 spring 的 bean 的注入方式 三种
分别是
字段注入 如@ Autowired 注解对类的字段进行注入
setter 注入 定义一个 setter 方法 进行 类中依赖的 bean 的初始化
构造器构造方法注入 在构造方法里传入所依赖的 bean 对象进行 bean 的初始化
字段注入是最省事的 但是可能会存在循环依赖的问题 而且字段注入破坏了设计的封装性 并且这种注解的方式是基于 spring 容器实现的,不利于进行单元测试,因为每次都要启动一个 spring 容器
构造器构造方法注入是 spring 官方提供的依赖注入方式,首先就是他在 类 的构造方法里初始化所选的依赖,符合逻辑,确保了依赖在 bean 实例化的时候就已经设置好了,避免了后期缺失的问题,即强制依赖初始化,但是代码冗余,也有可能出现两个 bean 循环依赖在构造器里面等待的循环依赖问题,我在实际开发中遇到过两次,此时我们可以在类的构造方法上加上@ lazy 注解,
setter 注入,我认为是从构造器注入衍生出去的,他的优势是可以允许改变注入的依赖,增加了灵活性,我们可以随时随地调用这个 setter 方法,传入任意符合规范的对象进行初始化,即可选依赖初始化
在实际开发中,建议优先考虑使用构造函数注入,尤其是对于强制依赖的情况。而 Setter 方法注入则适用于可选依赖的场景。至于字段注入,虽然使用起来很方便,但要谨慎使用,避免在需要进行单元测试或者有复杂依赖关系的场景中使用。
5. 讲一下单例模式 饿汉式 懒汉式 bean 的线程安全问题
单例模式是一种方式 类似于一个类只加载一次 一个类只有一个实例
通常在类里面把变量定义出来 每次调用的时候返回这个对象
spring 的 bean 默认就是单例的
而饿汉式 懒汉式是单例模式的实现方式
很形象
饿汉式 就是时刻保持饥饿态 我们会把要用到的类定义成静态的 因为类变量加载是在类初始化的时候就完成 我们就能在 spring 容器启动加载完成后就填充 bean
饿汉式是提前挂载资源 简单而且高效
懒汉式 顾名思义 我们只有在使用 bean 的时候才会进行加载
懒汉式内存资源消耗小 我们通常把在获取单例的时候 先判断一个要返回的单例变量是不是 null,如果是 null 先创建
饿汉式不存在线程安全问题
懒汉式存在线程安全问题 因为可能存在多线程并发创建 bean 创建了多个实例
他们通常使用双重检查锁
public class LazySingleton {
private static volatile LazySingleton instance; // 使用volatile关键字禁止指令重排
private LazySingleton() {}
public static LazySingleton getInstance() {
if (instance == null) { // 第一次检查,避免不必要的同步
synchronized (LazySingleton.class) {
if (instance == null) { // 第二次检查,确保线程安全
instance = new LazySingleton();
}
}
}
return instance;
}
}6. 讲一讲 springboot自动配置
在 spring 时代 我们是在 xml 里面配置 bean 的各种属性信息
springboot 的自动配置在 springboot 中的体现就是在 pom.xml 引入依赖后无需再手搓配置
我们只需要在类似于的 application.yml 配置文件中配置相关信息就行
springboot 的核心注解@ SpringbootApplication 中的子注解
@ EnableAutoConfiguration 注解就是自动配置注解
之后通过 SpringFactoriesLoader 最终加载 jar 包下 META-INF 目录下 spring.factories 中的自动配置类实现自动装配
@ EnableAutoConfiguration 注解是 依靠的 AutoConfigurationImportSelector 类
靠实现的 Selector 接口 先判断自动配置的开关有没有打开
再获取注解中的 exclude 和 excludeName
在获取所有自动配置的全类名 接着扫描 jar 包后从 META-INF / spring.factories 加载
自动配置类实际上就是 @ Conditional 注解按需加载配置类
所以想要其生效必须引入 stater 实现起步依赖
所以在 maven 里面我们选择是先引入 starter 然后再加载自动配置类
也就是我们 @ Conditional 注解 之后才能通过
7. 讲 bean 的初始化流程
bean 的生命周期主要分为五步 实例化 属性赋值 初始化 使用 销毁
初始化是核心
也是我认为的最复杂的
可以分为 5 步
- 检查 aware 相关接口设置依赖

- BeanPostProcessor 前置处理
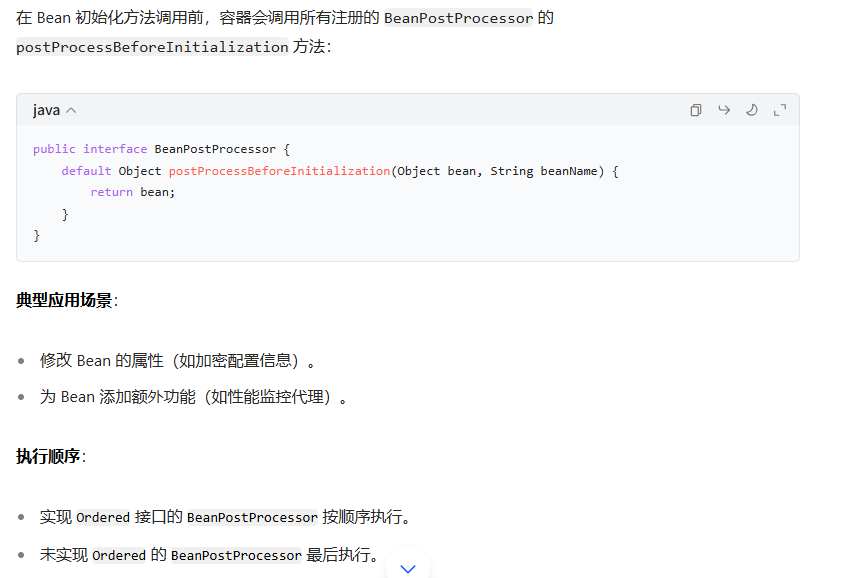
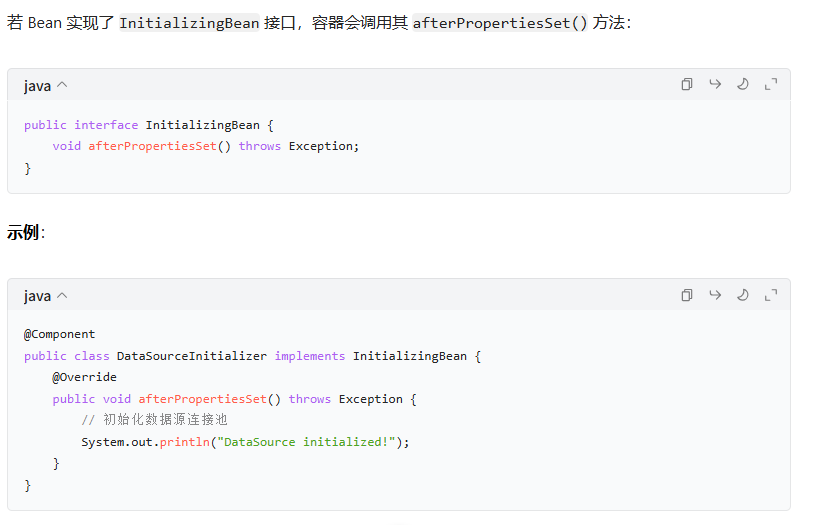
- 若实现 InitlizingBean 接口 调用 afterPropetiesSet()方法
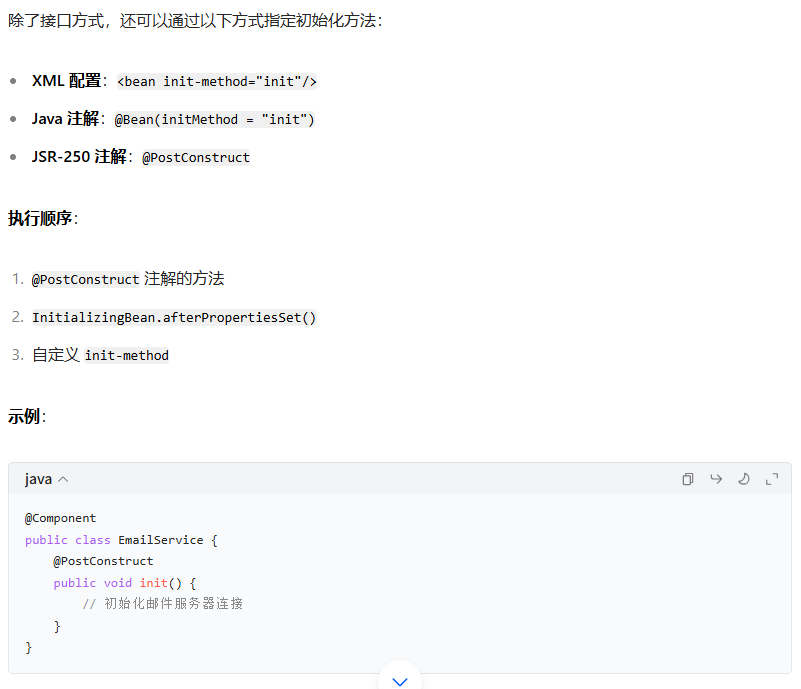
- 执行自定义的 init-method 方法
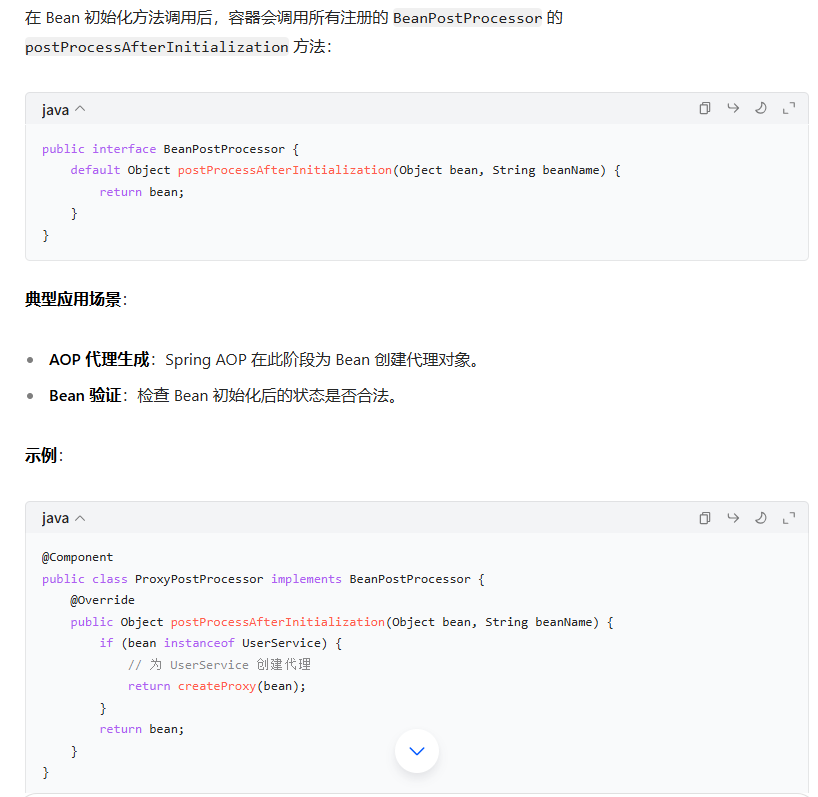
- BeanPostProcessor 后置处理
8. 讲讲 spring的bean
spring 的 bean 是 spring 框架管理的对象实例
spring 容器内有 bean spring 容器 实现了依赖注入,初始化 bean,管理 bean 的生命周期等功能
bean 的作用域可以设置为单例 或者是 全局
spring 定义 bean 最原始的的就是用@ bean 注解 + xml 配置
同样我们也可以基于 Java 的 @ Component 注解声明 可以类路径自动扫描
bean 注入有三种方式 字段 setter 构造器
springboot 实现了 bean 的自动装配 大体上分为两步 一个是获取自动配置类名 另一个是根据 Selector 接口中的@ Conditional 注解 从 spring.factories 里面加载
bean 的生命周期也是 spring 容器管理的 包括实例化 属性赋值 初始化 使用 销毁
9. 循环依赖的解决方法
不同的场景有不同的解决方案
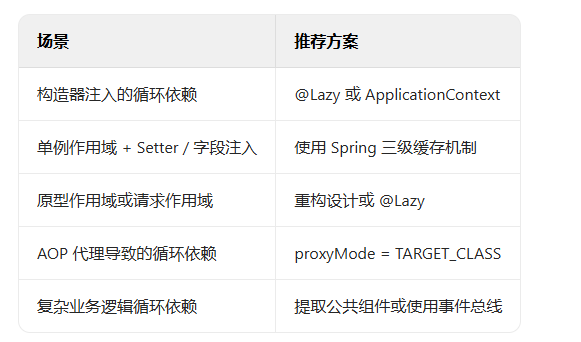
10. set、list、map
- set 是无序唯一集合
set 的常见的实现有 HashSet TreeSet
HashSet 的插入删除查找 速度的 o1
TreeSet 插入删除查找 速度的 o1 基于红黑树 可以传入比较器 o logn 实现排序
TreeSet 优势在于范围查询 查询最大元素 最小元素
- list 是有序不唯一集合
list 集合的底层是数组 每次 list 里面的元素超过一定数值就会进行扩容 10 -> *1.5
所以他类似于数组 拥有下标 索引
list 常见的实现有 ArrayList 基于数组 适合频繁检索 LinkedList 基于链表 适合频繁插入删除
- map 是双列集合
双列集合 key - value
key 相当于一个 set
刚刚讲到的 set
有 HashSet TreeSet
这些键会定义一个 value
检索效率通常是 o1
其他 特性参考 set
11. session cookie token区别
我先讲讲为什么要有这三
http 请求是无状态的 理论上每次通过请求获取到的服务端响应是相同的 也就是每次请求是绝对独立的
cookie 是客户端实际存储的小型文本
英译中为饼干 我们可以在浏览器中右键然后检查后看到他
cookie 同级的一级 二级域名下是共享的 cookie 无法跨域
而且 cooke 的数量有大小限制 通常是 4k
每次客户端向服务端发起请求的时候 是可以带上 cookie 里面的内容的
session 是为了解决 cookie 带来的一系列问题 首先解决的是 cookie 不安全的问题 session 保存在服务端 第一次请求时 服务端生成一个 session 会返回一个 sessionId 然后给客户端 客户端通常会将 sessionId 存储在 cookie 里面(仍然会出现数据不安全的问题) 然后在后续请求时带上 sessionId 发给服务端 服务端进行校验
对于数据不安全的问题 我有自己的思考
在分布式存储系统中 我们对于分布式 session 的存储 有多种方案
- 直接用 cookie (不安全)
- 分布式存储如 redis mysql
- 粘性存储 专门用一台机器存储 session (无法处理单点故障)
- session 复制 session 产生后 每台客户端服务器都加入这个 session (过于暴力 存在延迟)
如果我没记错 spring 是提供了 spring session 以来优雅的管理 session
类似于瑞吉外卖 Spring 提供的 getSession 方法相关的
而黑马点评用的是分布式存储 session 的方式 (redis)
我是不太会使这些玩意的 我信赖 token 是与生俱来的 (
就自动第一次实习后 我从未使用过 session
我学习了 jwt 和 sa-token 后 一直使用的是较为成熟的企业级方案
token 英译中为令牌
是一种校验手段 服务端 根据秘钥签发 token 后返回给客户端
客户端把 token 包含在请求头里面或请求参数里面进行请求
然后服务器再验证解析 token
类比 jwt
jwt 有一定的规则 builder()签发秘钥 parse()解析秘钥
12. 场景题 如何Java用内存200M的情况下读取1G文件,并统计重复内容?
在Java中处理1GB大文件并统计重复内容,需结合流式读取和内存优化技术。根据内存200MB限制,以下是分步骤解决方案及关键技术点:
a. 一、流式读取与内存控制
逐行读取技术
使用
-
BufferedReader或Scanner实现流式处理,避免一次性加载文件。示例代码:try (BufferedReader br = new BufferedReader(new FileReader("large.txt"), 8192)) {
String line;
while ((line = br.readLine()) != null) {
// 处理每行数据
}
}
-
- 内存消耗:仅需约20MB缓冲(取决于缓冲区大小)。
-
字符编码处理
明确指定编码(如UTF-8)避免解析错误:BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8)
);
b. 二、高效去重数据结构
- BitSet去重法
-
-
原理:每个数字对应一个二进制位,若位值为1则表示已存在,否则标记为1。
-
内存优势:9亿数字仅需约112MB内存(9e8 bits ≈ 107MB)。
-
示例代码:
BitSet bitSet = new BitSet();
int num = Integer.parseInt(line);
if (bitSet.get(num)) {
// 统计重复
duplicateCount++;
} else {
bitSet.set(num);
}
-
- 适用条件
-
- 数字范围在整数范围内(0~2^31-1)。
- 若数字范围过大,需分片处理(如哈希分片到多个BitSet)。
c. 三、内存优化补充策略
-
分治处理(可选)
若数字范围超限,采用哈希分片写入临时文件,再逐个处理小文件:int hash = Math.abs(line.hashCode()) % 1000;
writeToTempFile(line, "shard_" + hash + ".tmp"); -
Bloom Filter(允许误判时)
若允许一定误判率,使用布隆过滤器进一步压缩内存:BloomFilter
filter = BloomFilter.create(Funnels.integerFunnel(), 1e9, 0.01);
if (filter.mightContain(num)) {
// 可能重复
}
d. 四、性能与监控
- 垃圾回收调优
-
- 年轻代(Young Generation)设置为较小空间(如50MB),减少Full GC频率。
- JVM参数示例:
-Xmx200m -XX:NewSize=50m。
- 监控工具
使用VisualVM或JConsole观察内存占用,确保老年代(Old Generation)稳定在130MB以内。
e. 五、完整示例代码
public class Deduplicator {
public static void main(String[] args) throws IOException {
BitSet bitSet = new BitSet();
int duplicates = 0;
try (BufferedReader br = new BufferedReader(
new FileReader("large.txt"), 8192)) {
String line;
while ((line = br.readLine()) != null) {
int num = Integer.parseInt(line.trim());
if (bitSet.get(num)) {
duplicates++;
} else {
bitSet.set(num);
}
}
}
System.out.println(" 重复次数: " + duplicates);
}
}f. 引用与扩展
- 关键参考:验证了BitSet方案的实际内存占用,提供了流式读取的优化方法,总结了避免内存溢出的通用原则。
- 扩展场景:若需排序,可结合外排序(External Sort)和归并策略。