文章目录
- 一、摘要
- 二、Method
-
- [2.1 现象(问题)](#2.1 现象(问题))
- [2.2 基本框架](#2.2 基本框架)
- [2.3 结构设计](#2.3 结构设计)
-
- [2.3.1 时空数据增强Space-Time Data Augmentation](#2.3.1 时空数据增强Space-Time Data Augmentation)
- [2.3.2 视频感知条件化Video-Aware Conditioning](#2.3.2 视频感知条件化Video-Aware Conditioning)
- 三、实验设置
-
- [3.1 数据](#3.1 数据)
- 四、总结贡献
论文全称:VEnhancer: Generative Space-Time Enhancement for Video Generation
代码路径: https://github.com/Vchitect/VEnhancer
更多RealWolrd VSR整理在 https://github.com/qianx77/Video_Super_Resolution_Ref
一、摘要
我们提出了VEnhancer,这是一种生成时空增强框架,通过在空间领域中添加更多细节以及在时间领域中合成详细的运动,从而改善现有的文本到视频的结果。针对生成的低质量视频,我们的方法可以通过统一的视频扩散模型同时提高其空间和时间分辨率,支持任意的上采样空间和时间尺度。此外,VEnhancer有效地去除了生成视频中的空间伪影和时间闪烁现象。为此,我们基于预训练的视频扩散模型,训练一个视频控制网络,并将其作为低帧率和低分辨率视频的条件注入到扩散模型中。为了有效训练这个视频 ControlNet,我们设计了时空数据增强(space-time data augmentation)和视频感知条件(video-aware conditioning)。得益于上述设计,VEnhancer在训练过程中表现出稳定性,并采用优雅的端到端训练方式。大量实验表明,VEnhancer在增强人工智能生成视频方面超越了现有的最先进的视频超分辨率和时空超分辨率方法。此外,借助VEnhancer,现有的开源最先进文本到视频方法VideoCrafter-2在视频生成基准VBench中达到了第一名。
二、Method
2.1 现象(问题)
1、现有的时间超分辨率(temporal super-resolution)和空间超分辨率(spatial super-resolution)很多采用的是级联的操作,这样其实是很低效而且次优,因为两个要推理两次,而且两者可能是耦合的。
2、现有方法仅支持固定的放大倍数做时空超分辨率,在实际使用中很难使用
3、现有模型在生成质量与逼真度之间的良好平衡方面存在困难(即去除伪影或闪烁)。
2.2 基本框架
基于Video Diffusion Models(阿里在23年的论文(I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models)) ,其本质是基于Stable Diffusion 2.1的空间特征,然后加上时序模块。
其最基本原理就是正向加噪,反向去噪, 使用UNet预测V,不过多了一个帧的维度,

2.3 结构设计
高质量生成视频源于强大的生成模型,而逼真度则要求算法保留输入中的视觉信息。在生成式模型研究中,平衡视觉质量和逼真度始终是一项挑战。作者们遵循ControlNet 49,以保持预训练的视频扩散模型不变,从而保留其生成能力,额外创建一个可训练的复制网络以有效地注入condition。架构如图2所示。
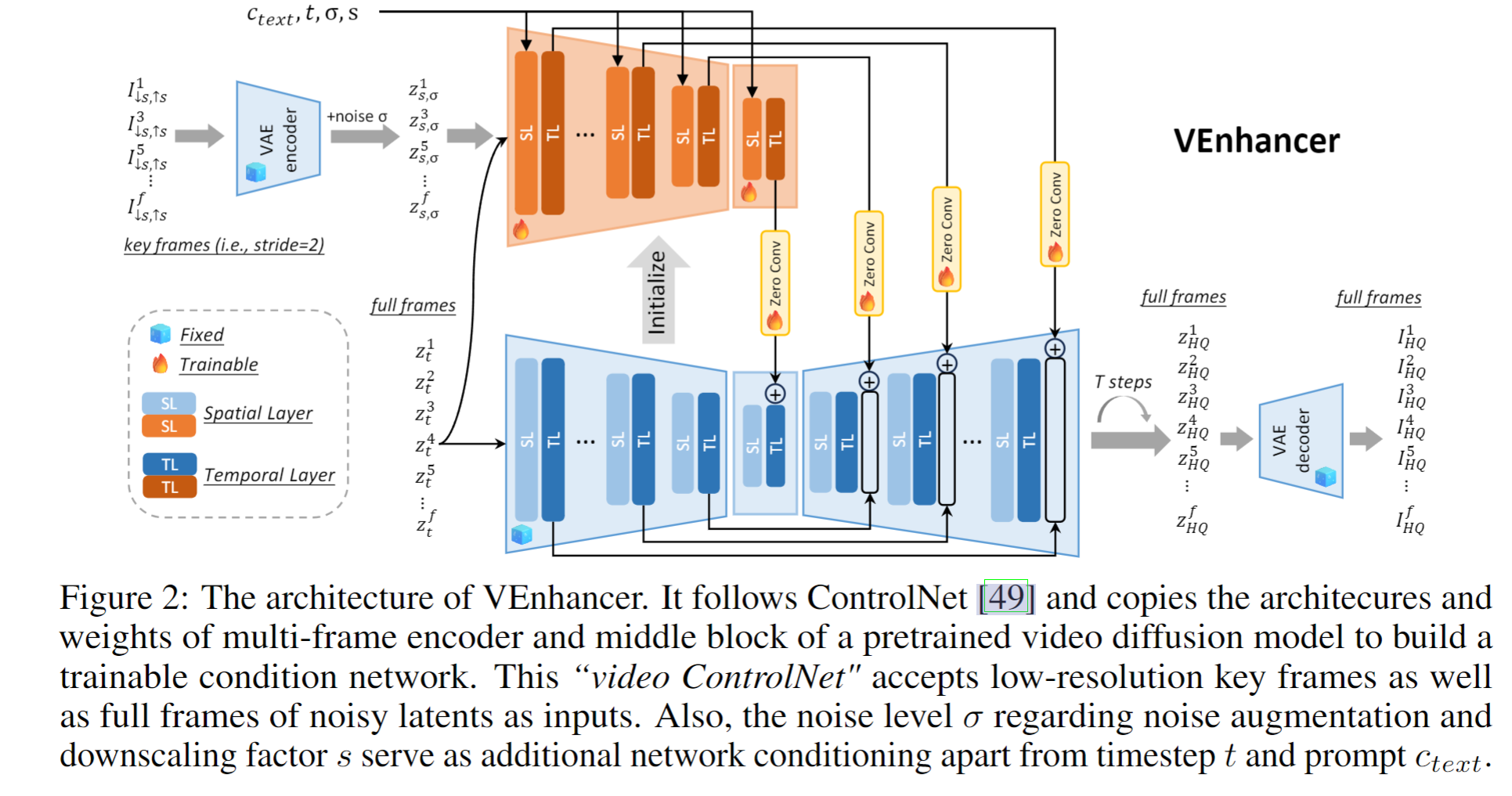
1、主要结构用到3D-UNet ,3D-UNet是由一堆空间和时间层(spatial and temporal layers)堆叠而成,
其中空间层SL 是和SD2.1一样的,包括ResBlocks、self-attention、cross-attention 层,
时间层TL是由核为3的一维卷积构成,初始化为0,经过video datasets微调得到参数。
在3D-UNet中,视频特征在编码器encoder中的TL层中对齐,然后skip到解码器decoder,使用concat连接到decoder的特征。
2、构建condition network: 复制了3D-UNet 中的编码器encoder和中间块middle block的结构和权重,使用加噪的latent作为输入,输出多尺度时空特征,然后通过新添加的零卷积(zero convolution)注入到原始3D-UNet如图2黄色所示。条件网络中间块的输出特征将被加回到3D-UNet中间块的特征中。而对于条件网络中的编码器块的输出特征,它们的特征将被添加到3D-UNet中跳过的视频特征中,这些特征也是由编码器块产生的。这种架构设计与原始的ControlNet是一致的。
2.3.1 时空数据增强Space-Time Data Augmentation
如何实现在空间尺度和时间尺度任意的上采样?数据增强
**时间维度:**其实就是设定1-8的随机数,随机跳帧。

空间维度:
随机下采样+上采样回原来尺度。没啥特别,有个需要注意的是:每个空间或时间尺度对应不同的难度级别,因此采样并不均匀。特别地,作者基于1 : 2的比例设置了4×和8×尺度的采样概率,这一比例由它们各自的尺度值决定。这个没太看懂是什么操作?随机数好像直接就指定这个比例了吧,不用特别设置。
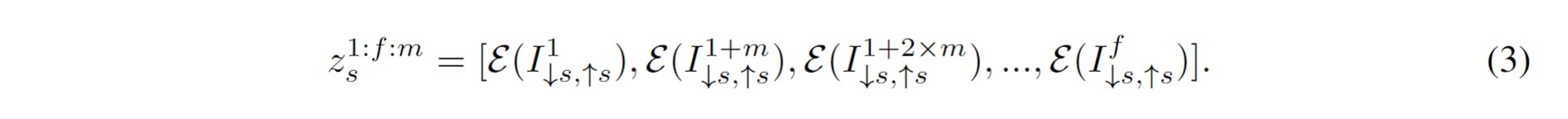
潜在空间中的噪声增强(Noise augmentation in latent space.):
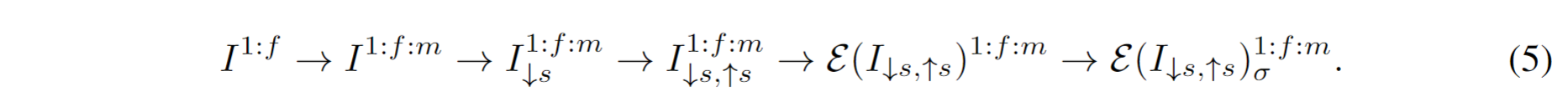
没啥特别的,就是总结下整体流程而已
2.3.2 视频感知条件化Video-Aware Conditioning
除了数据增强之外,还应设计相应的条件机制,以提升模型训练效果,并避免在不同的空间或时间尺度和噪声增强下的性能平均化。
在实际应用中,条件潜在序列,相应的降尺度因子以及增强噪声 σ 都被视为条件。有关更直观的演示,请参见图 3。
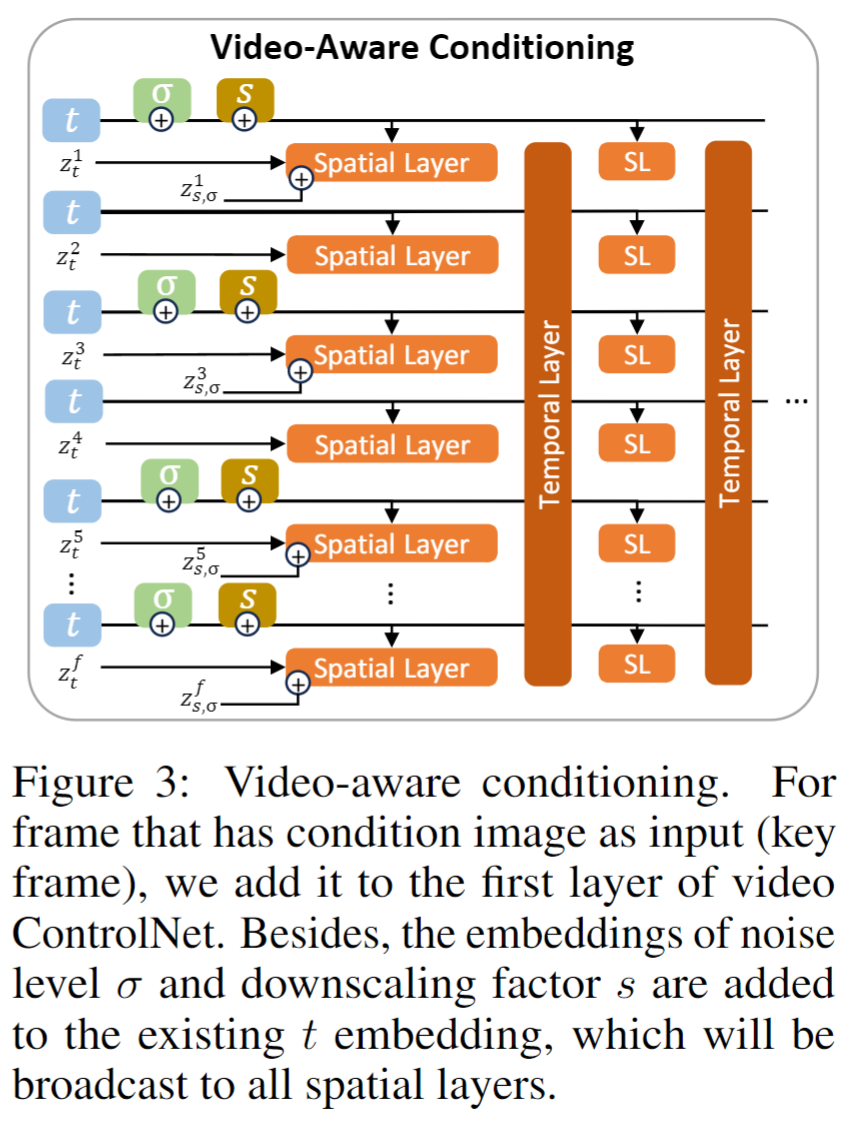
整体特征的输出可以用式6、7所示,有个预训练特征+controlNEt的零卷积
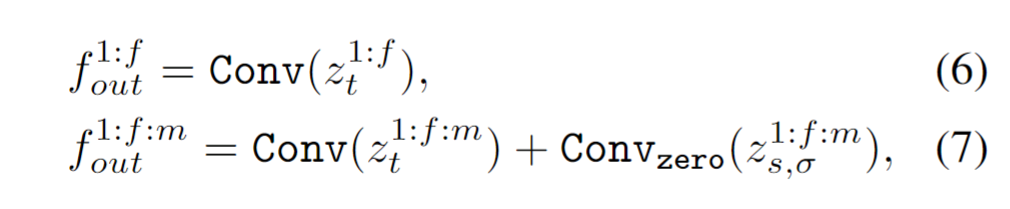
由于加上了下采样因子s和噪声增强σ进行条件处理,需要将它们纳入时间嵌入。
这是原本的时间嵌入
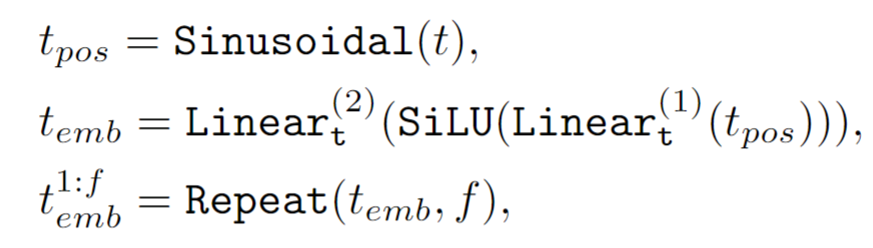
这是加上噪声σ的时间嵌入

这是加上下采样因子的时间嵌入
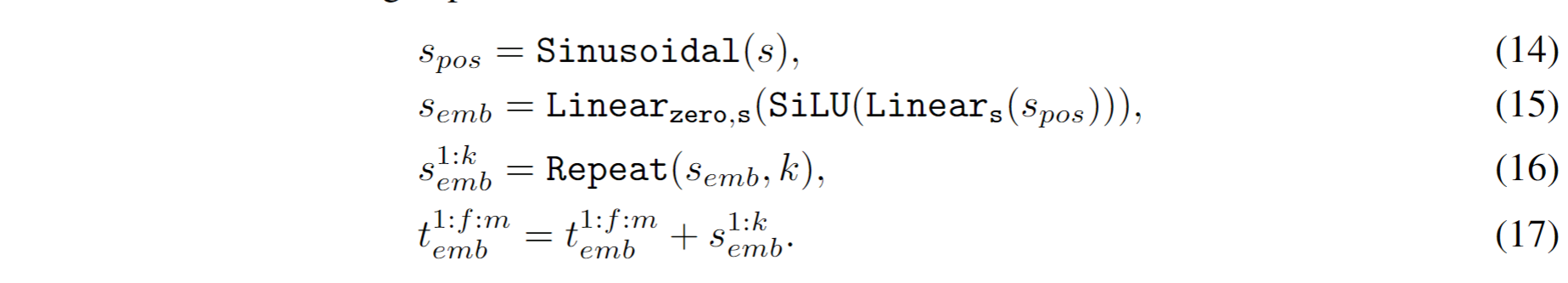
三、实验设置
3.1 数据
350k high-quality and high-resolution video clips from the Internet,We train VEnhancer on resolution 720 × 1280 with center cropping, and the target FPS is fixed to 24
四、总结贡献
1、统一的扩散模型中实现生成性时空超分辨率,设计用于多帧条件注入的视频ControlNet,既保真又有高质量生成
2、提出数据增强和条件方案,来实现端到端模型的训练。
3、可以使用随意的上采样因子,以实现空间或时间超分辨率