一、安装langchain
安装依赖
bash
python -m venv env
.\env\Scripts\activate
pip3 install langchain
pip3 install langchain-core
pip3 install langchain-openai
pip3 install langchain-community
pip3 install dashscope
pip3 install langchain_postgres
pip3 install "psycopg[binary]"导入库函数
bash
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.messages import HumanMessage,SystemMessage
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_core.documents import Document二、知识库转换向量
使用通义千问的向量模型将私域知识库的数据转化为制定维度的向量,并将向量存入向量数据库pgvector中
python
COLLECTION_NAME = "t_rag"
CONNECTION = "postgresql+psycopg://postgres:12346@server200:5432/postgres_db"
#实例化千问的向量模型
embedding = DashScopeEmbeddings(model="text-embedding-v3",dashscope_api_key="sk-xxx")
#**创建向量数据库
vector_store = PGVector(
connection = CONNECTION,
collection_name = COLLECTION_NAME,
embeddings = embedding
)准备文本转化向量存储
python
def save_vector():
print("save_vector start .....")
documents = [
Document(page_content="段一凡出生东川县一个农民工家庭,毕业于江南大学,成绩优异",metadata={"source":"brief"},id=1),
Document(page_content="现任吉南市环保局局长,曾任市共青团副书记,此前还担任过回龙乡乡长、党委书记等职务",metadata={"source":"brief"},id=2),
Document(page_content="肖素素、王雪莹、吴晓恙、刘淼淼这四个大美女与他都有着千丝万缕的关系",metadata={"source":"brief"},id=3),
Document(page_content="肖素素某国开国将军的曾孙女,美丽智慧,某国企总经理,与段一凡生死患难,互生情愫,但二人身份差距悬殊",metadata={"source":"brief"},id=4),
Document(page_content="王雪莹省战略策划室副主任王庆支之女,段一凡学妹,喜欢段一凡",metadata={"source":"brief"},id=5),
Document(page_content="吴晓恙商人之家,典型富二代,喜欢段一凡",metadata={"source":"brief"},id=6),
Document(page_content="刘淼淼冰冷美女,前县委书记刘海龙之女,刘海龙整治过段一凡,刘淼淼自杀,被段一凡救过,对段一凡产生爱意",metadata={"source":"brief"},id=7),
]
uuids = [str(uuid4()) for _ in range(len(documents))]
try:
vector_store.add_documents(documents=documents, ids=uuids)
print("save_vector successful.")
except Exception as e:
print(f"save_vector failed: {e}")
python
def main():
save_vector()

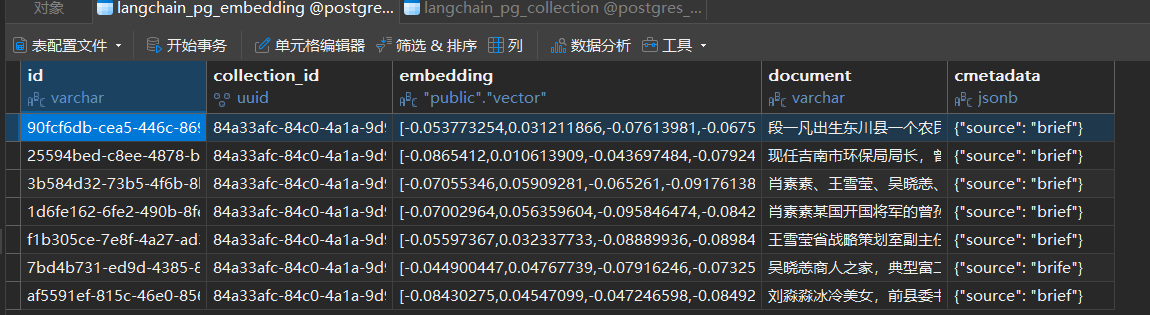
文本数据库成功存入向量数据库
三、检索增强
将提示词和匹配向量一起发给大模型进行提问
python
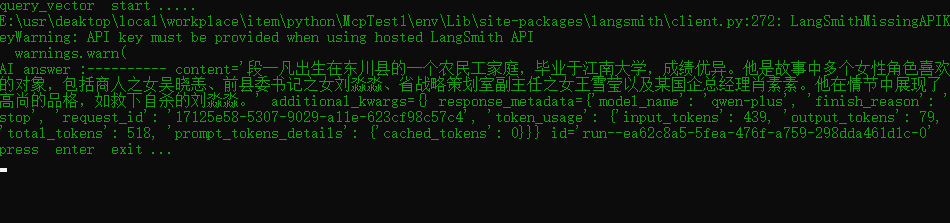
def rag_vector(query):
print("query_vector start .....")
#results = vector_store.similarity_search(query = query,k=5,filter={"source": "brief"})
#通过向量生成检索器
retriever = vector_store.as_retriever(search_type="mmr", search_kwargs={"k": 5})
prompt = hub.pull("rlm/rag-prompt")
messages = prompt.invoke({
"question": query,
"context": retriever.invoke(query)
})
llm = ChatTongyi(
streaming = False,
model = "qwen-plus",
api_key = "sk-xxxx",
)
ai_message = llm.invoke(messages)
print("AI answer :----------",ai_message)
python
def main():
rag_vector("段一凡是谁?")大模型的回答基于上下文向量信息进行学习