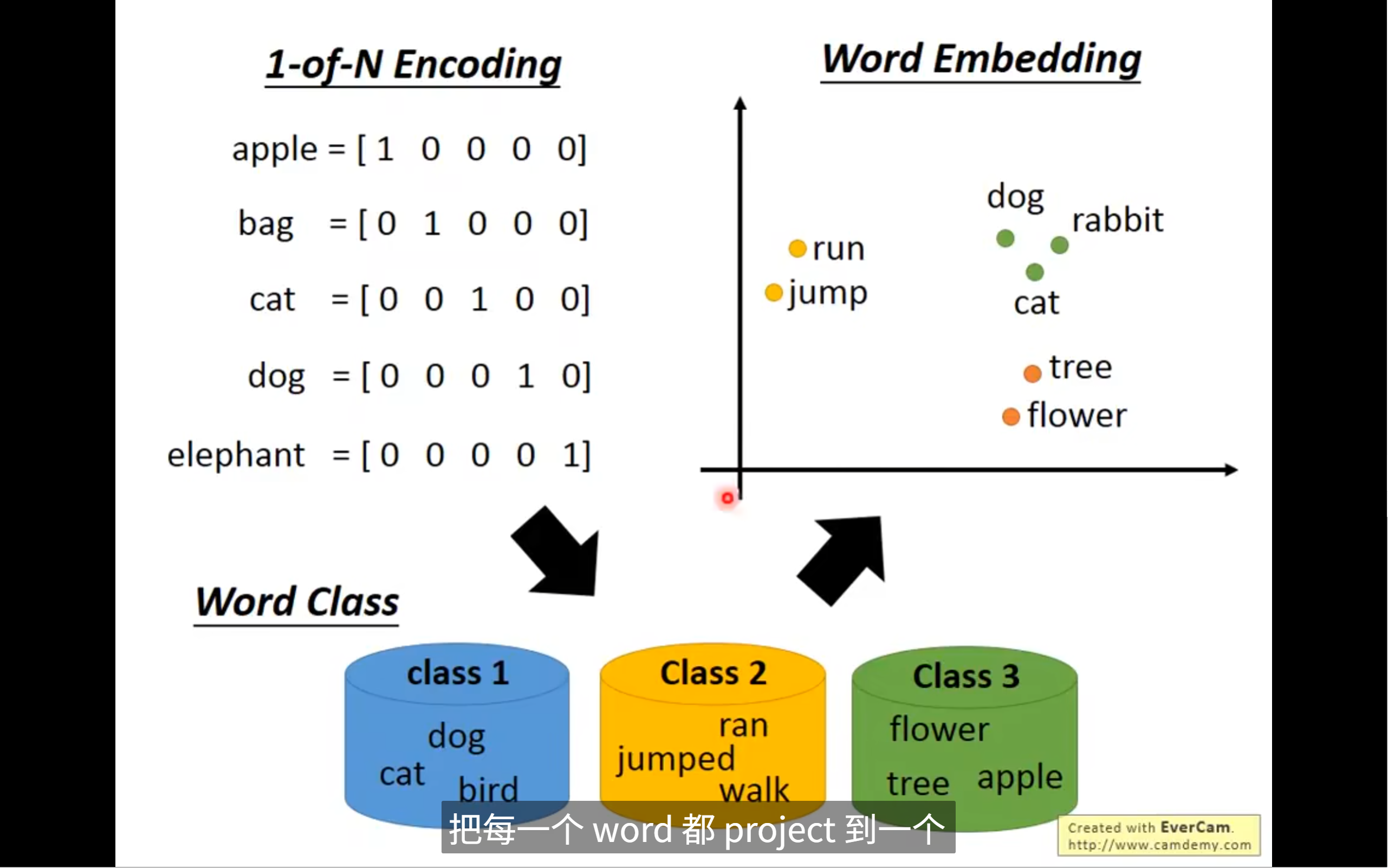
传统的1 of N 的encoding无法让意义相近的词汇产生联系,word class可以将相近的词汇放到一起
但是word class不能表示class间的关系,所以引入了word embedding(词嵌入)
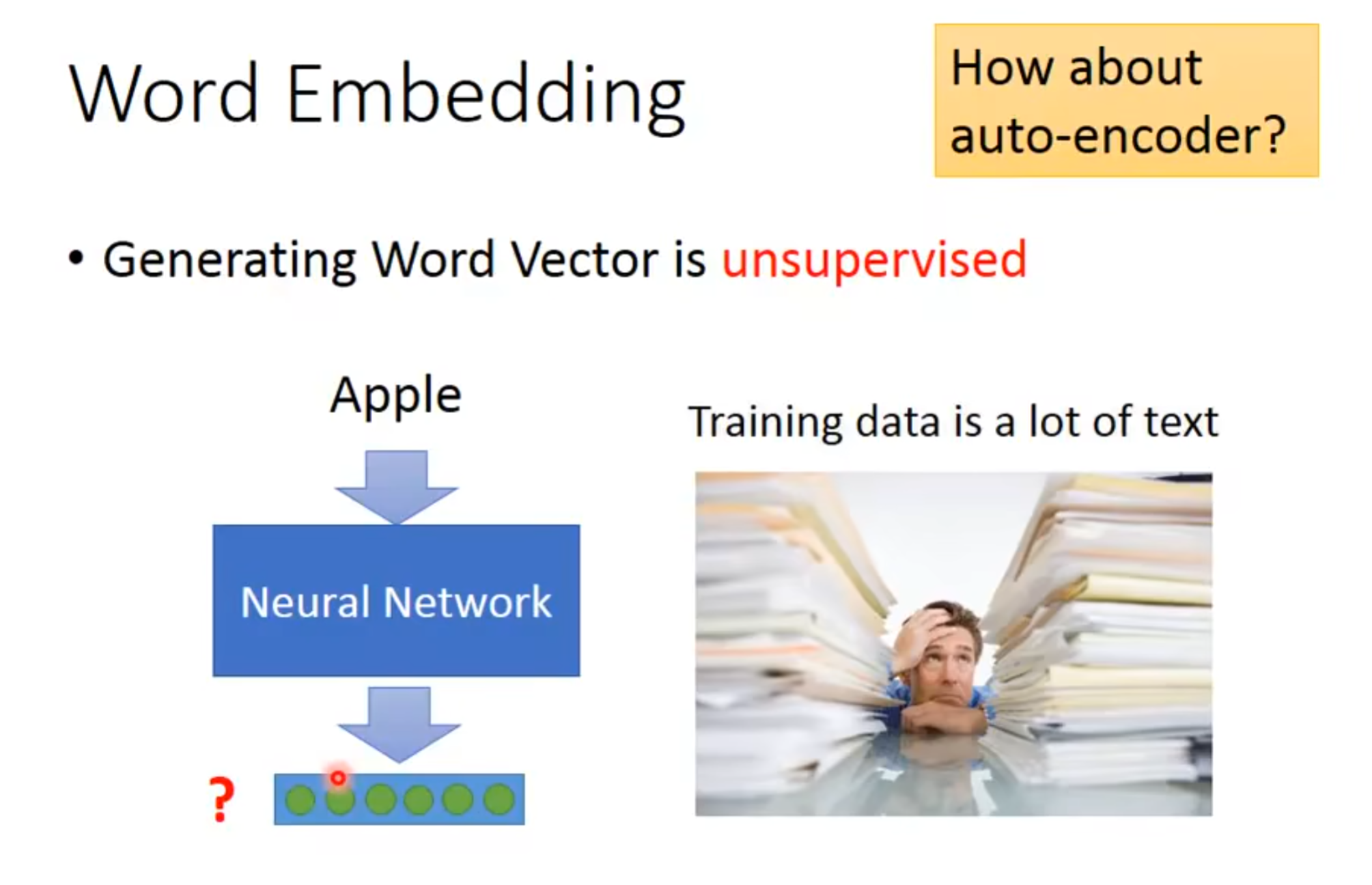
我们生成词向量是一种无监督的过程(没有label
自编码器 是一种人工神经网络,主要用于无监督学习 ,它的目标是学习一种"压缩"数据的方式,然后再"还原"数据。
简单来说,自编码器可以把高维数据压缩成低维的"编码",再从这个编码还原出原始数据。
通过这个过程,网络学会了如何用更少的信息表达原始数据的主要特征
count based
- 如果两个词(比如 (w_i) 和 (w_j))经常一起出现在同一个上下文中(比如同一句话、同一段落),那么它们的词向量 (V(w_i)) 和 (V(w_j)) 应该在向量空间中距离较近。
- 这种方法的核心是共现矩阵(co-occurrence matrix):统计每对词在同一上下文中出现的次数 (N_{i,j})。

- 不是直接统计词与词的共现次数,而是通过神经网络模型,用一个词去预测它的上下文 ,或者用上下文去预测中心词。
- 通过训练神经网络,让词向量在预测任务中不断优化,最终得到能表达语义的词向量。
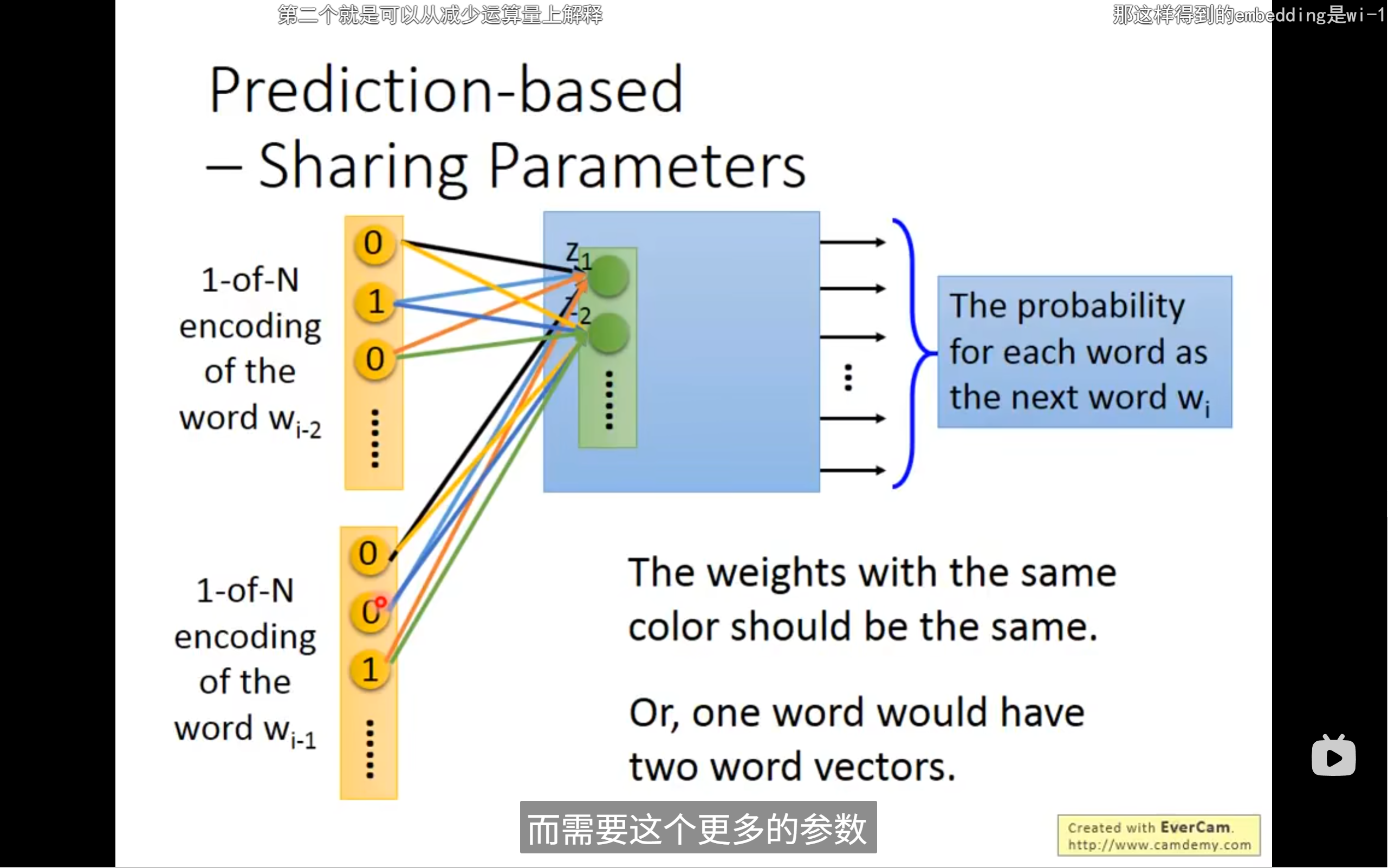
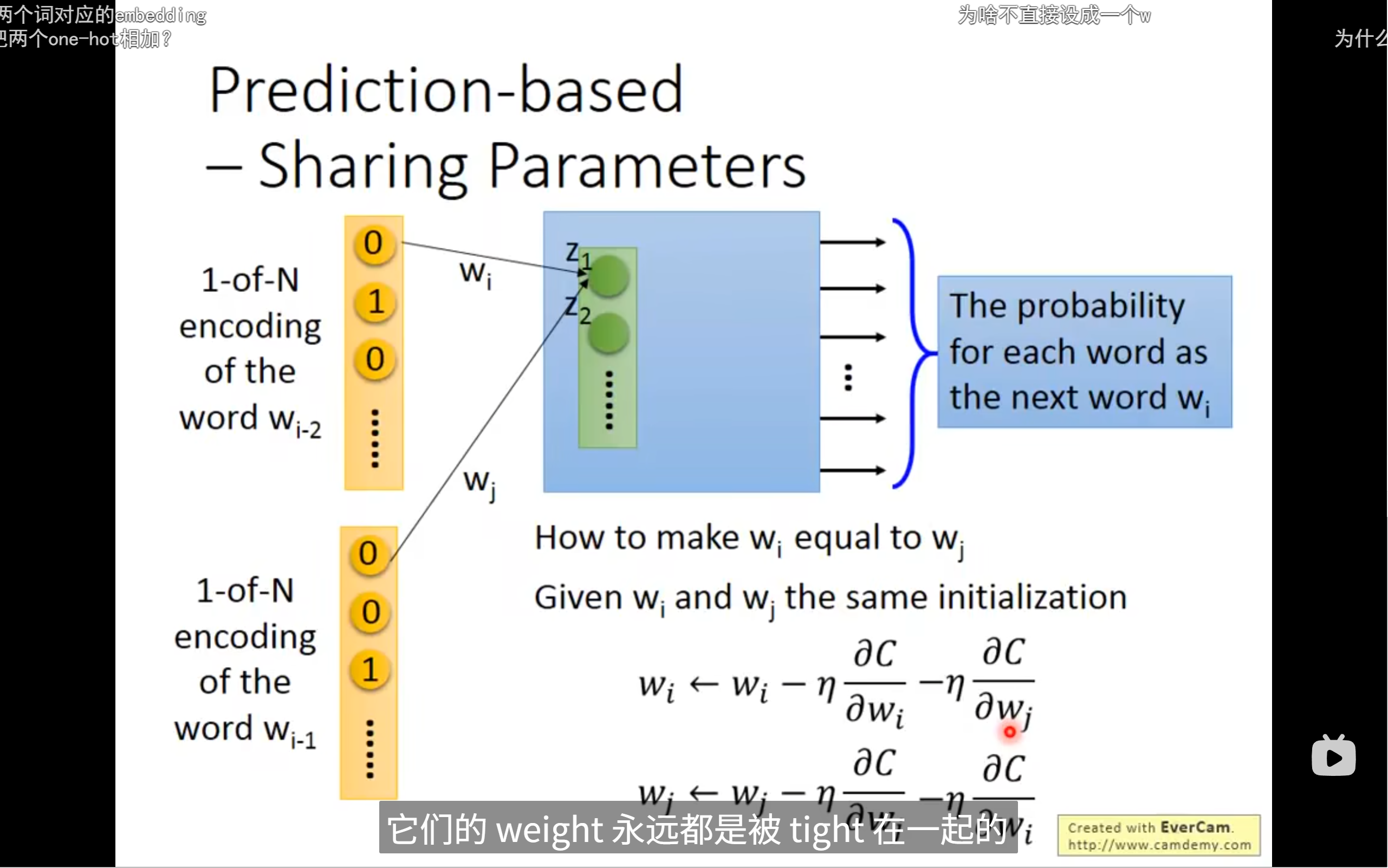
我们想要将input的后一个词是一样的,我们就要将input的两个词放置在同一空间的相邻位置,我们就要通过w来调整,第一个隐藏层的权重矩阵就是我们要的词向量(word embedding)

我们input可以不止一个词,因为都是one hot,所以可以连在一起丢进去就行
- 假设你有一个词表,每个词都有一个词向量(比如300维)。
- 不管这个词出现在输入的哪个位置(比如上下文的第一个词、第二个词),它的词向量都是同一组参数,不会因为位置不同而变成不同的向量。
- 这就是参数共享(parameter sharing),如图中不同输入(w_{i-2}、w_{i-1})连到隐藏层的线条有相同颜色,表示用的是同一组权重。
- 对于同一个词,比如"蔡英文",它的词向量(比如第1维、第2维......第300维)在所有输入位置都是一样的。
- 也就是说,不管"蔡英文"出现在w_{i-2}还是w_{i-1},它的第1维、第2维......第300维的值都一样。
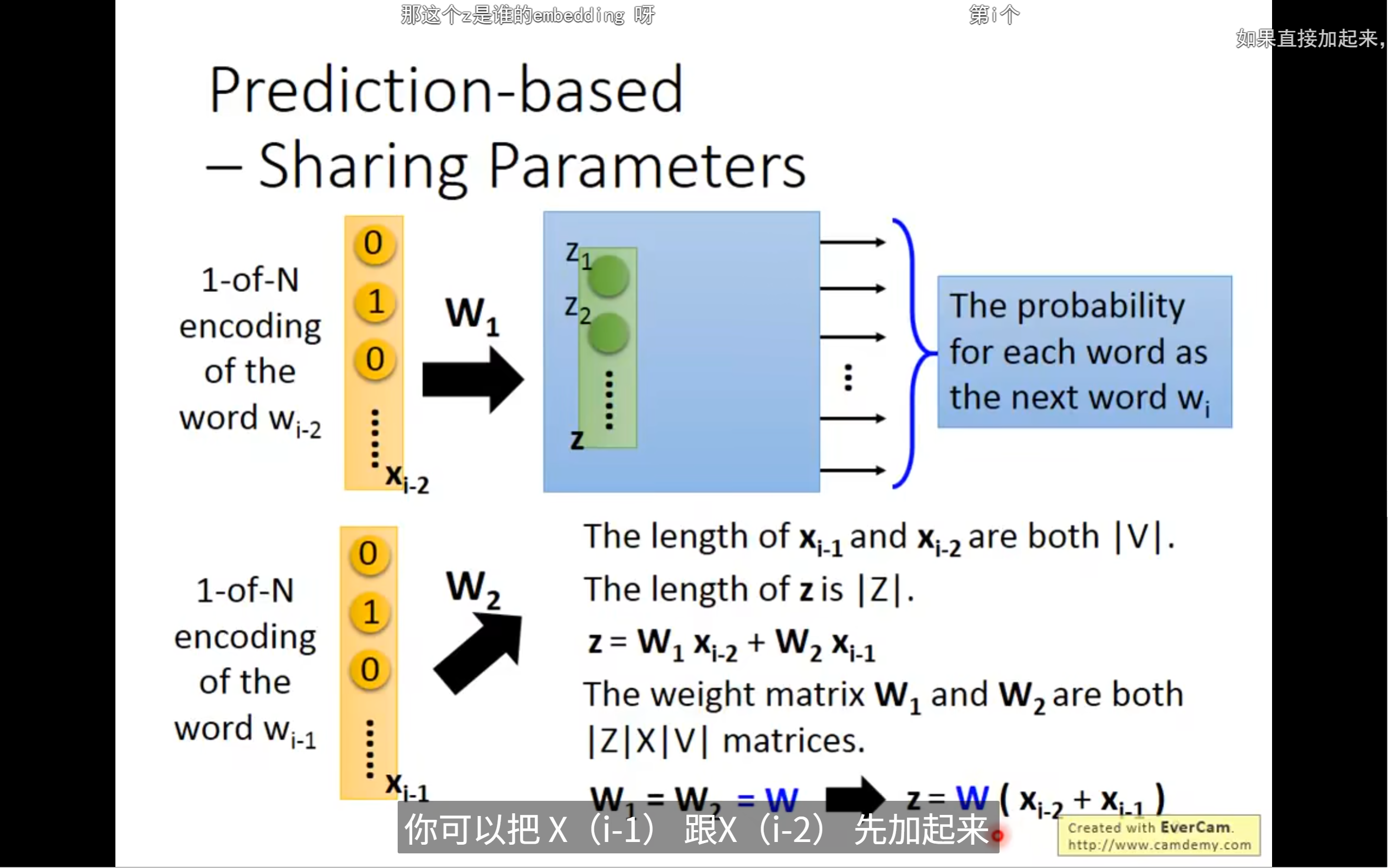
- w 在这里就是词向量(word embedding),也是embedding层的权重。
- 每个词都有自己的词向量,不是所有词共享一个向量。
- 词向量矩阵的每一行对应一个词,内容不同,结构相同。
z 不是预测的词本身,也不是预测词的词向量,而是"上下文的综合表示",也就是用来预测下一个词的"隐藏层输出"或"上下文向量"。
-
每个 one-hot 向量(比如 (x_{i-2}))
乘以权重矩阵 (W_1) 后,实际上就是"选中"了 (W_1) 的某一行,这一行就是 (x_{i-2}) 这个词的词向量(在 (W_1) 这个矩阵里的表示)。
-
同理,(x_{i-1}) 乘以 (W_2)
就是选中 (W_2) 的某一行,这一行就是 (x_{i-1}) 这个词的词向量(在 (W_2) 这个矩阵里的表示)。
-
z = W1 * x_{i-2} + W2 * x_{i-1}
就是把这两个词的词向量加起来,作为上下文的综合表示。
-
实际应用中,通常所有上下文词共享同一个权重矩阵(embedding table)。
那我们怎么让wi和wj一样呢
- 每个词都需要有自己独立的词向量,不能只用一个w。(除非是usa和美国这种实际上是一样的词
- 参数共享的是结构,不是内容。
- 分别更新每个词的向量,才能让模型学到丰富的语义信息。
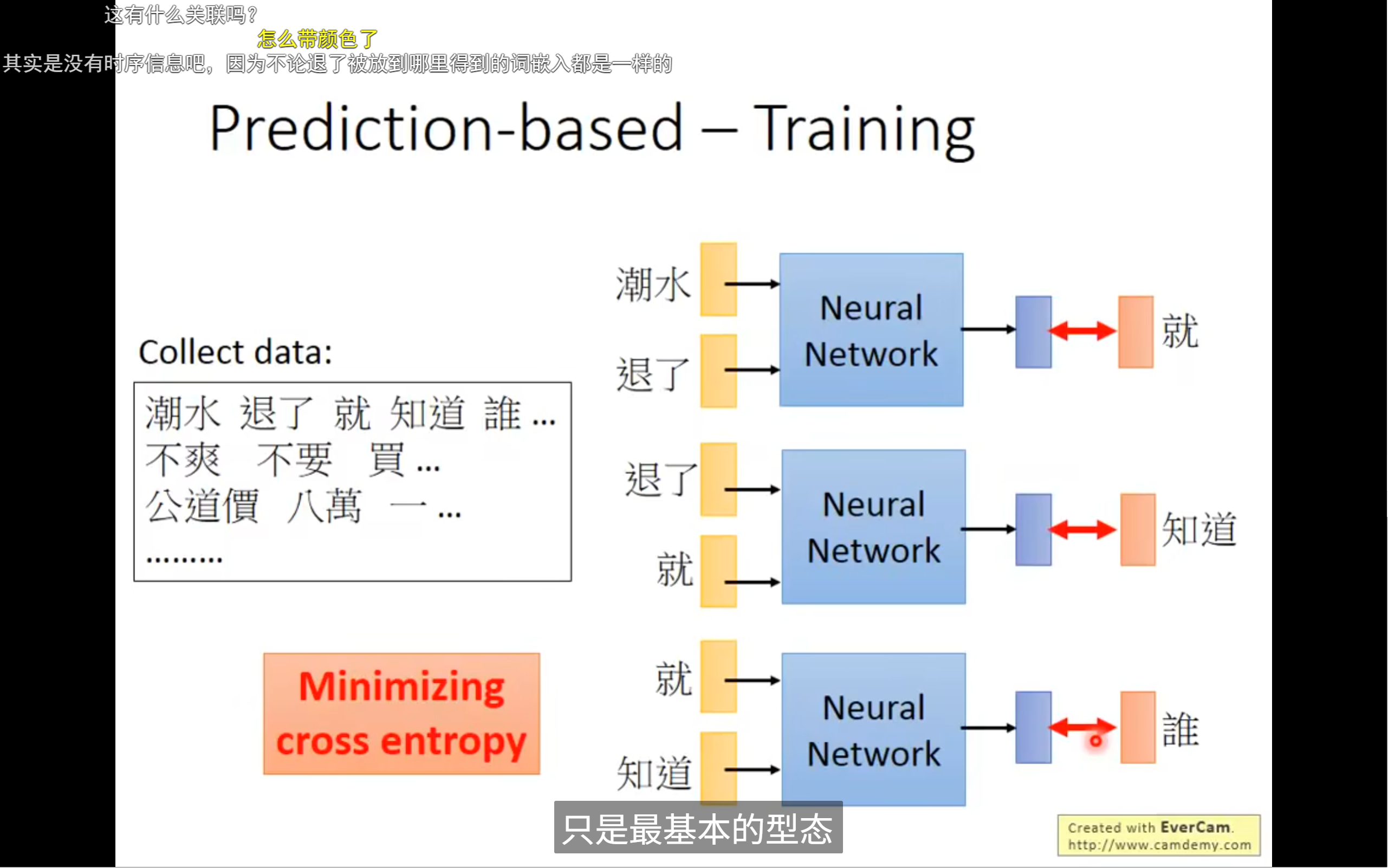
例子
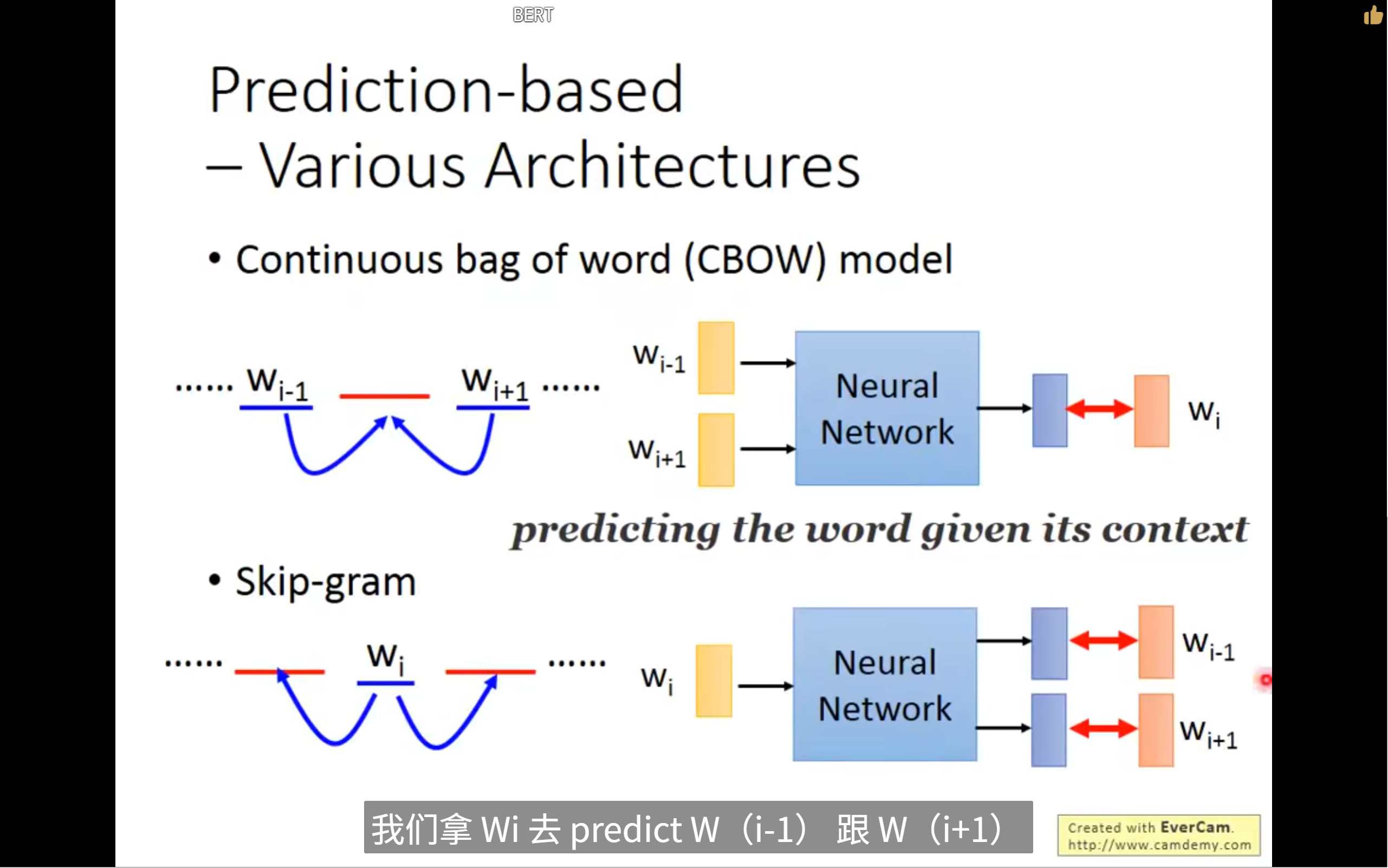
还有其他的prediction based
其实这些network不是deep的,只有一个network
word embedding处理相关联的词

但是如果project的是中文context,我们是无法知道对应英文的,只有将中文和英文分别project到空间中的同一点才行